Azure Data Factory での Power Query アクティビティ
Power Query アクティビティを使用すると、Data Factory パイプラインで大規模なデータ ラングリングを実行するために、Power Query マッシュアップをビルドして実行できます。 新しい Power Query マッシュアップを作成するには、[New resources](新しいリソース) メニュー オプションを使用するか、パイプラインに Power アクティビティを追加します。
Power Query マッシュアップ エディターの内部で直接操作を行い、対話型データ探索を実行して、作業内容を保存できます。 完了後、Power Query アクティビティを取得して、パイプラインに追加できます。 Azure Data Factory は、Azure Data Factory のデータ フロー Spark 環境を使用して、これを自動的にスケールアウトし、データ ラングリングを運用可能にします。
UI で Power Query アクティビティを作成する
パイプラインで Power Query アクティビティを使用するには、次の手順を実行します。
[パイプライン アクティビティ] ウィンドウで Power Query を検索し、Power Query アクティビティをパイプライン キャンバスにドラッグします。
キャンバス上の新しい Power Query アクティビティが選択されていない場合は、その [設定] タブを選択して、詳細を編集します。
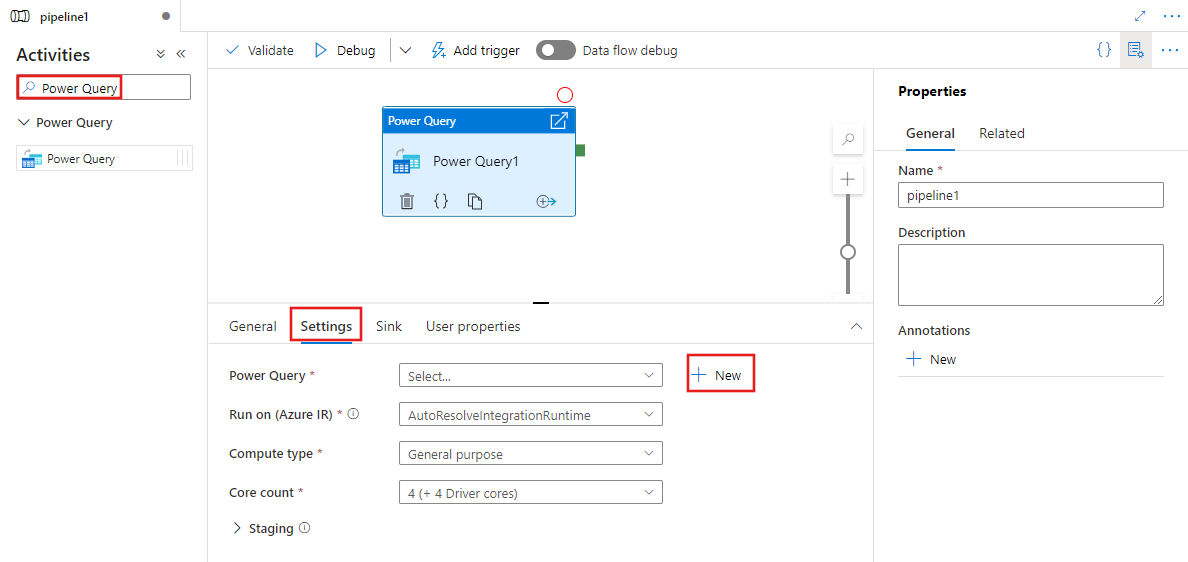
既存の Power Query を選択して [オープン] を選択するか、[New (新規)] ボタンをクリックして新しい Power Query を作成し、Power Query エディターを開きます。
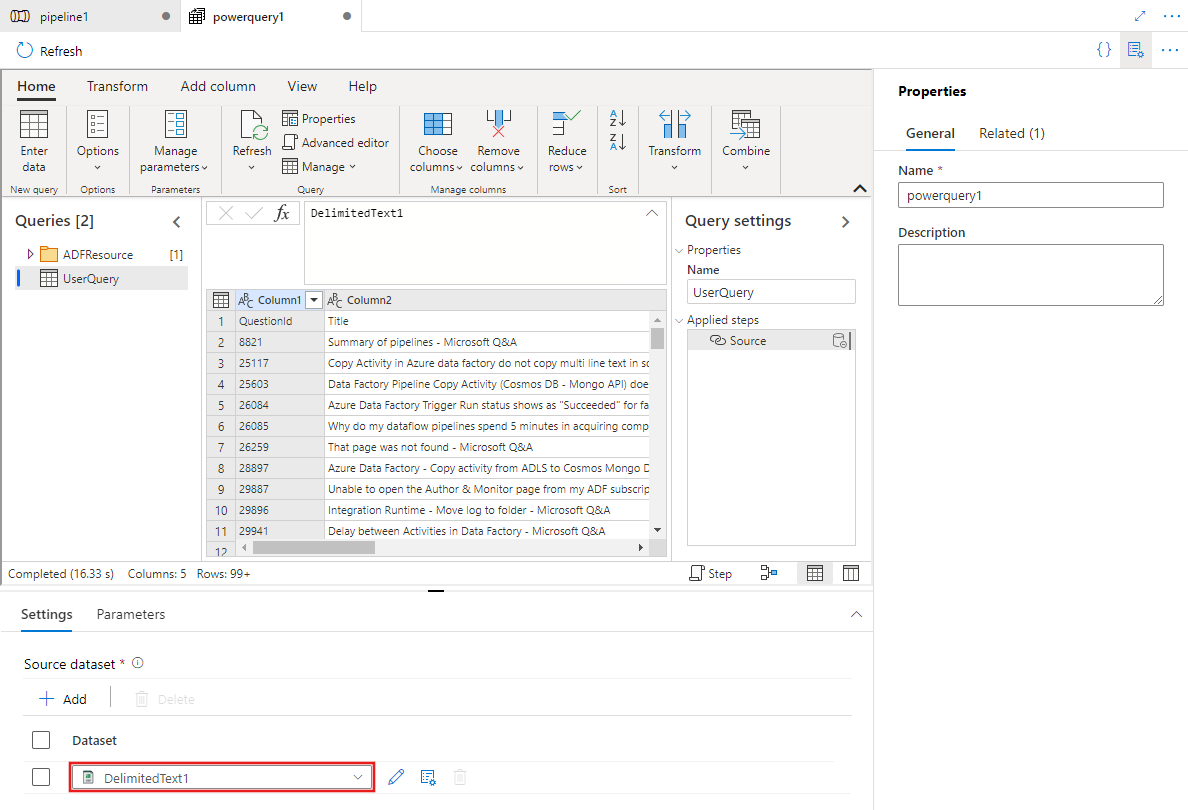
既存のデータセットを選択するか、[New (新規)] を選択して新しいデータセットを定義します。 パイプライン編集エクスペリエンス内で Power Query の豊富な機能を直接使用して、必要なデータセットを変換します。 エディターで複数のデータセットから複数のクエリを追加して、後で使用できます。
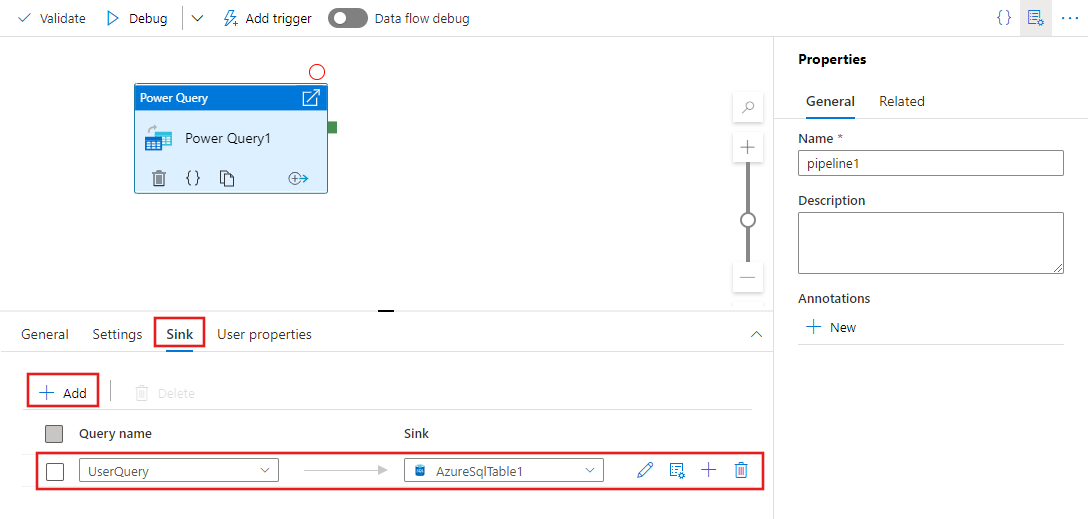
前の手順で 1 つ以上の Power Query を定義した後、Power Query アクティビティの [シンク] タブで、これらのいずれかまたはすべてのシンクの場所を指定することもできます。
また、Power Query アクティビティの出力を他のアクティビティへの入力として使用することもできます。 次は、Items プロパティに対して以前に定義した Power Query の出力を参照する各アクティビティの例です。 その Items は動的なコンテンツをサポートします。ここでは、入力として使用される Power Query からの出力を参照できます。
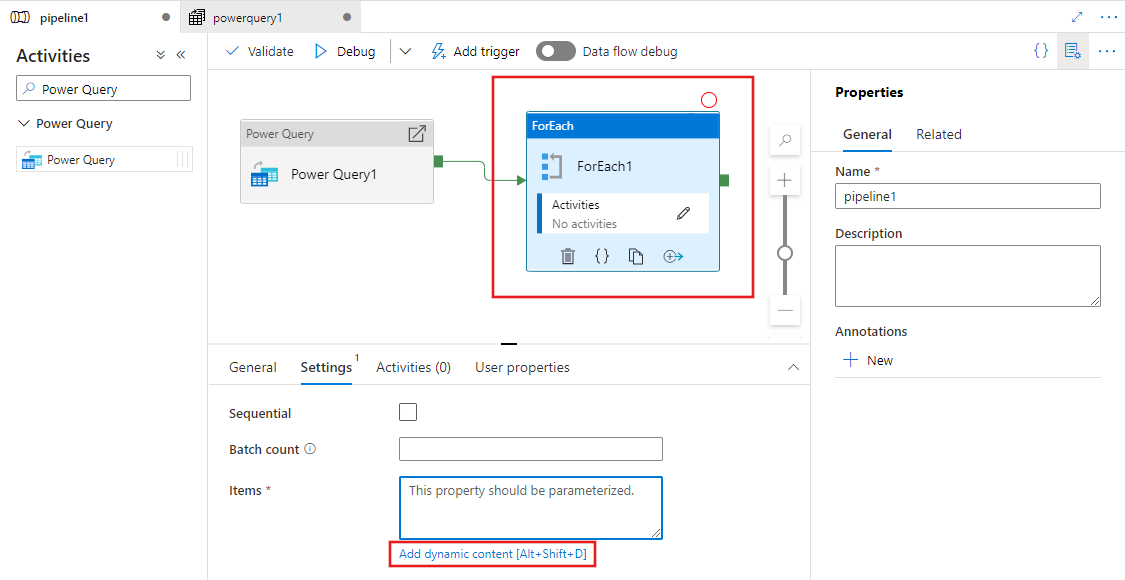
アクティビティの出力はすべて表示され、動的なコンテンツを定義するときに、[パイプライン式ビルダー] ウィンドウで選択して使用できます。
データ フロー スクリプトへの変換
Power Query アクティビティを使用したスケーリングを実現するために、Azure Data Factory は、M スクリプトをデータ フロー スクリプトに変換します。これにより、Azure Data Factory のデータ フロー Spark 環境を使用して Power Query を大規模に実行できます。 コーディング不要のデータ準備を使用して、ラングリング データ フローを作成します。 使用できる関数の一覧については、変換関数に関するページを参照してください。
設定
- Power Query: 既存の Power Query を選択して実行するか、新しいものを作成します。
- Run on Azure IR (Azure IR 上で実行する): 既存の Azure Integration Runtime を選択して Power Query のコンピューティング環境を定義するか、新しいものを作成します。
- コンピューティングの種類: 既定の自動解決の統合ランタイムを選択した場合は、Power Query の実行に使用する Spark クラスターのコンピューティングに適用するコンピューティングの種類を選択できます。
- コア数: 既定の自動解決の統合ランタイムを選択した場合は、Power Query の実行に使用する Spark クラスターのコンピューティングに適用するコア数を選択できます。
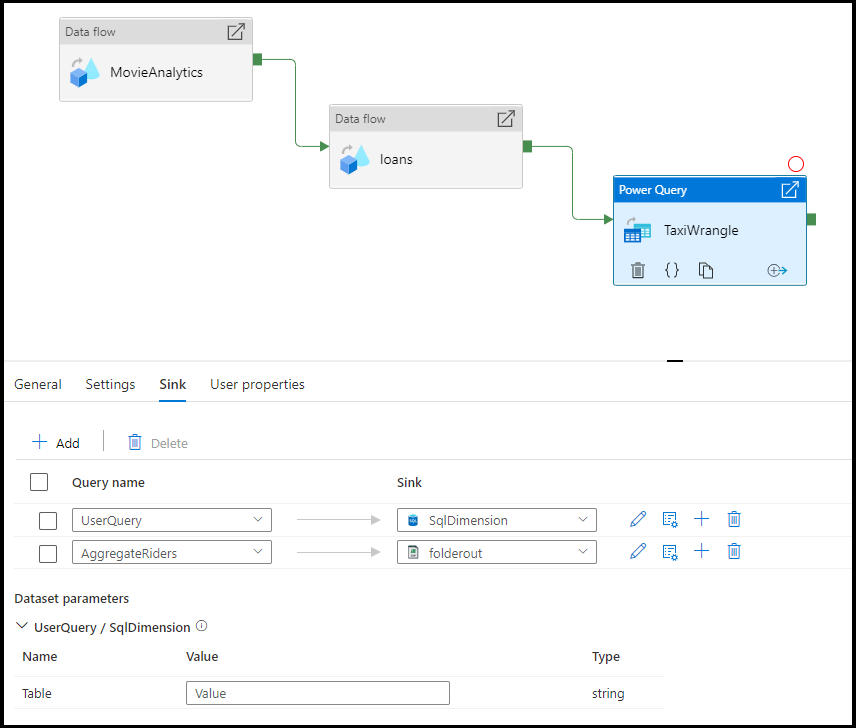
シンク
Spark 上で Power Query M スクリプトが実行された後、変換されたデータのランディングに使用するデータセットを選択します。 シンクの構成の詳細については、データ フロー シンクのドキュメントを参照してください。
出力を複数の変換先にシンクするオプションがあります。 [+ (プラス)] ボタンをクリックして、クエリにシンクを追加します。 また、収集した Power Query アクティビティから、個々のクエリ出力を異なる変換先に転送することもできます。
マッピング
[マッピング] タブでは、Power Query アクティビティの出力から、選択したシンクのターゲット スキーマへの列マッピングを構成することができます。 列マッピングの詳細については、データ フロー シンクのマッピングのドキュメントを参照してください。
関連するコンテンツ
Azure Data Factory で Power Query を使用するデータ ラングリングの概念について詳しく学習してください。