Apache Spark 用の Azure Data Explorer コネクタ
Apache Spark は、"大規模なデータ処理のための統合された分析エンジン" です。 Azure Data Explorer は、大量のデータのリアルタイム分析を実現するフル マネージドの高速データ分析サービスです。
Spark 用の Kusto コネクタは、任意の Spark クラスターで実行できるオープンソース プロジェクトです。 Azure Data Explorer と Spark クラスター間でデータを移動するためのデータ ソースとデータ シンクを実装します。 Azure Data Explorer と Apache Spark を使用して、データ ドリブン シナリオをターゲットとする、高速でスケーラブルなアプリケーションを作成することができます。 たとえば、機械学習 (ML)、ETL (抽出 - 読み込み - 変換)、および Log Analytics などです。 このコネクタにより、Azure Data Explorer は、書き込み、読み取り、writeStream などの標準的な Spark のソースおよびシンク操作に有効なデータ ストアになります。
キューに登録されたインジェストまたはストリーミング インジェストを使用して、Azure Data Explorer に書き込むことができます。 Azure Data Explorer からの読み取りでは、列の排除と述語のプッシュダウンがサポートされています。これにより、Azure Data Explorer でデータがフィルター処理されるため、転送されるデータの量が減ります。
注記
Azure Data Explorer 用の Synapse Spark コネクタを使用する方法については、「Apache Spark for Azure Synapse Analytics を使用して Azure Data Explorer に接続する」を参照してください。
このトピックでは、Azure Data Explorer Spark コネクタをインストールして構成し、Azure Data Explorer と Apache Spark クラスター間でデータを移動する方法について説明します。
注釈
下の例のいくつかでは Azure Databricks Spark クラスターが登場しますが、Azure Data Explorer Spark コネクタは、Databricks やその他の Spark ディストリビューションに直接依存しません。
前提条件
- Azure サブスクリプション。 無料の Azure アカウントを作成します。
- Azure Data Explorer クラスターとデータベース。 クラスターとデータベースを作成します。
- Spark クラスター。
- コネクタ ライブラリをインストールします。
- Spark 2.4 と Scala 2.11 または Spark 3 と Scala 2.12 向けに事前構築されたライブラリ
- Maven リポジトリ
- Maven 3.x がインストールされていること
ヒント
Spark 2.3.x バージョンもサポートされていますが、pom.xml の依存関係の変更が必要になる場合があります。
Spark コネクタのビルド方法
バージョン 2.3.0 以降では、spark-kusto-connector に代わる新しい成果物 ID として、Spark 3.x と Scala 2.12 を対象とする kusto-spark_3.0_2.12 が導入されています。
メモ
2.5.1 より前のバージョンでは、既存のテーブルへの取り込みは機能しなくなったため、新しいバージョンに更新してください。 このステップはオプションです。 Maven などの事前構築されたライブラリを使用する場合は、「Spark クラスターの設定」を参照してください。
構築の前提条件
Spark コネクタの構築については、こちらのソースを参照してください。
Maven プロジェクトの定義を使う Scala と Java のアプリケーションの場合は、アプリケーションを最新の成果物にリンクしてください。 最新の成果物は Maven Central にあります。
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).ビルド済みのライブラリを使っていない場合は、次の Kusto Java SDK ライブラリなど、「依存関係」に記載されているライブラリをインストールする必要があります。 インストールする適切なバージョンを確認するには、関連するリリースの POM を確認します。
Jar をビルドして、すべてのテストの実行するには:
mvn clean package -DskipTestsJar をビルドし、すべてのテストを実行し、ローカルの Maven リポジトリに jar をインストールするには:
mvn clean install -DskipTests
詳細については、コネクタの使用に関するページを参照してください。
Spark クラスターの設定
注
次の手順を実行するときは、最新の Kusto Spark コネクタ リリースを使うことをお勧めします。
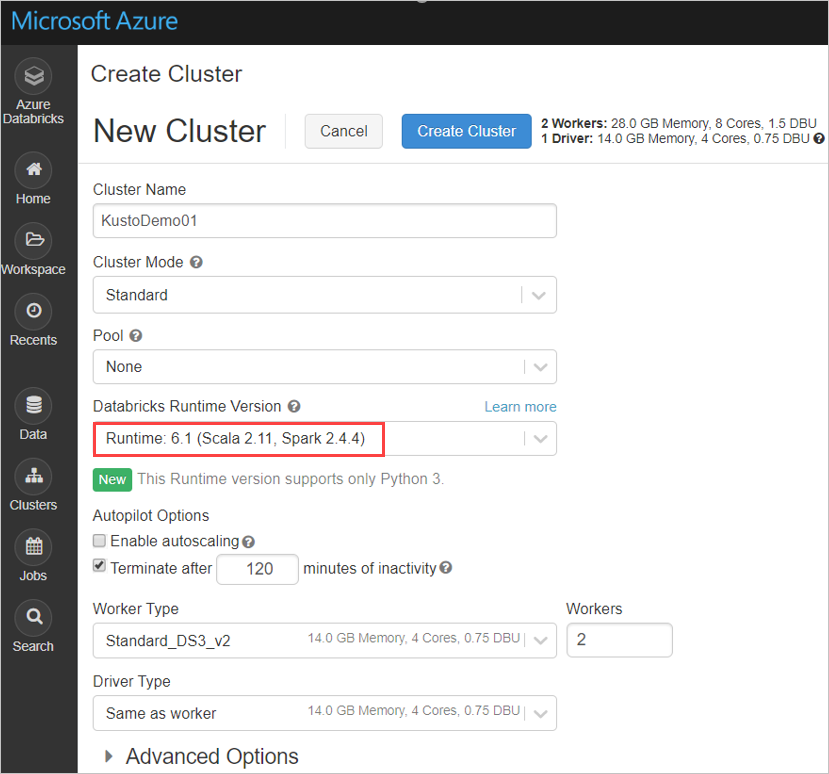
Azure Databricks クラスター Spark 3.0.1 と Scala 2.12 に基づいて、Spark クラスターの次の設定を構成します。
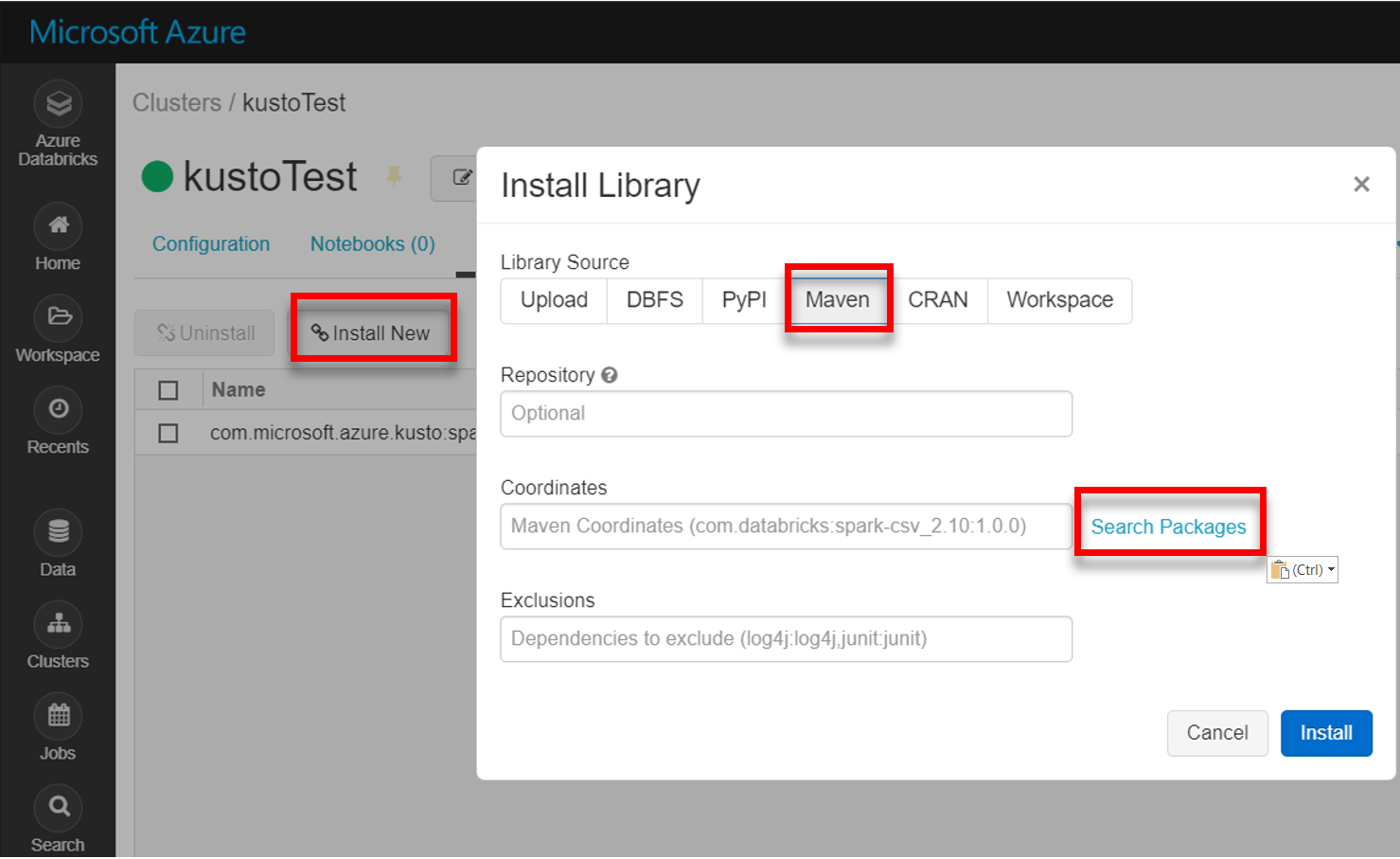
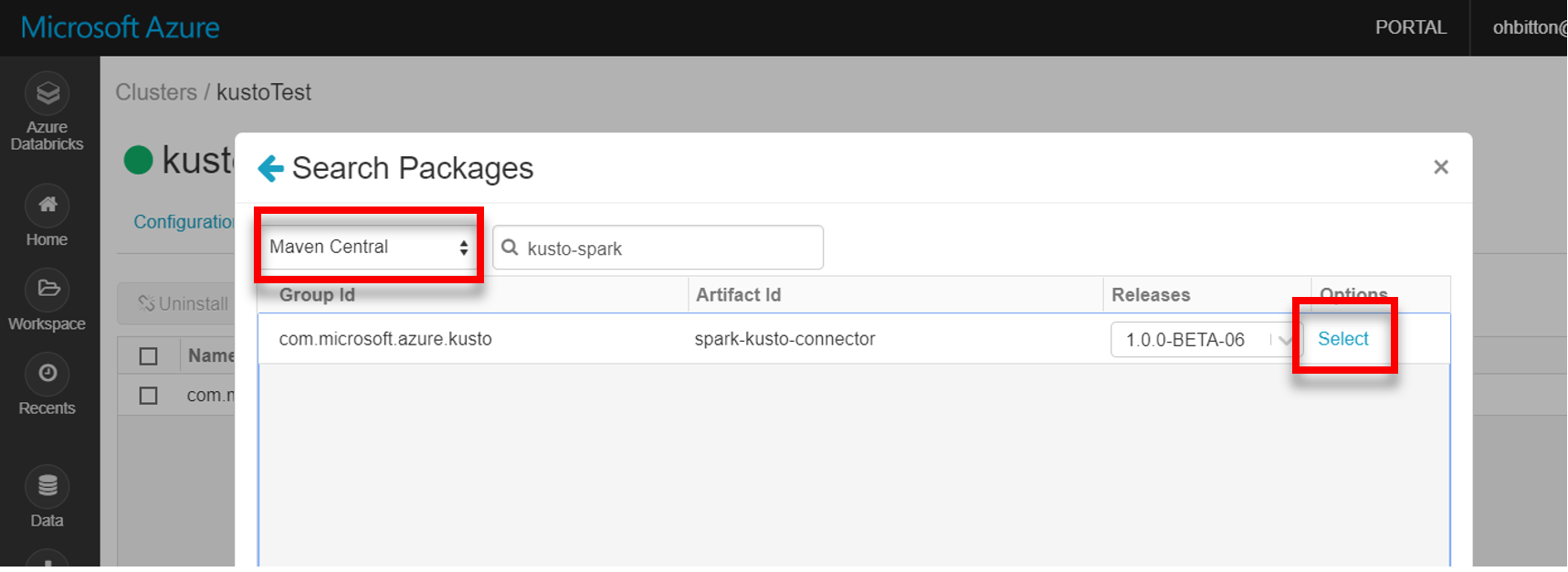
Maven から最新の spark-kusto-connector ライブラリをインストールします。
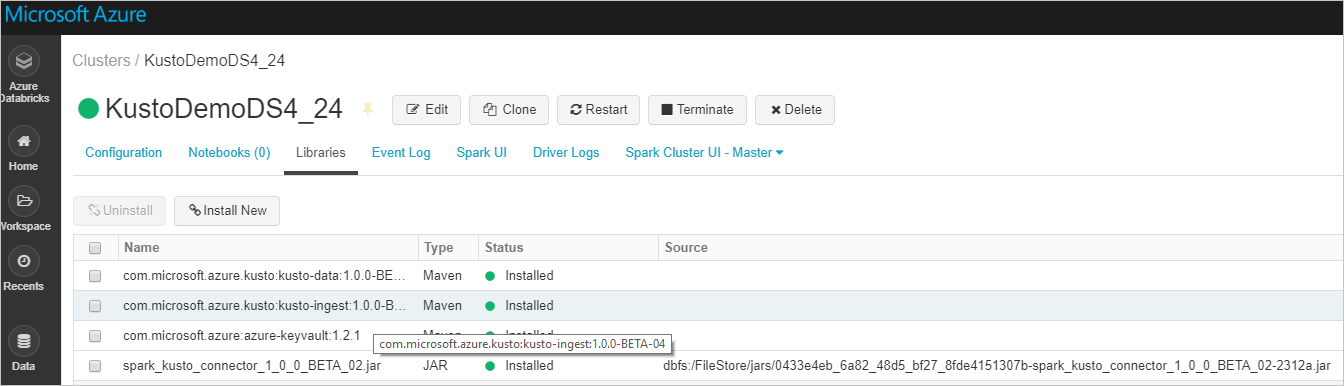
必要なライブラリがすべてインストールされていることを確認します。
JAR ファイルを使うインストールの場合は、他の依存関係がインストールされたことを確認します。
認証
Kusto Spark コネクタを使うと、次のいずれかの方法を使って、Microsoft Entra ID での認証を行うことができます。
- Microsoft Entra アプリケーション
- Microsoft Entra アクセス トークン
- デバイス認証 (運用環境以外のシナリオの場合)
- Azure Key Vault。Key Vault リソースにアクセスするには、azure-keyvault パッケージをインストールし、アプリケーションの資格情報を提供します。
Microsoft Entra アプリケーション認証
Microsoft Entra アプリケーション認証は、最も単純で最も一般的な認証方法であり、Kusto Spark コネクタにはこの方法をお勧めします。
Azure CLI 経由で Azure サブスクリプションにサインインします。 次に、ブラウザーで認証します。
az loginプリンシパルをホストするサブスクリプションを選択します。 この手順は、複数のサブスクリプションがある場合に必要です。
az account set --subscription YOUR_SUBSCRIPTION_GUIDサービス プリンシパルを作成します。 この例では、サービス プリンシパルを
my-service-principalと呼びます。az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}返された JSON データから、
appId、password、およびtenantを後で使用のためにコピーします。{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Microsoft Entra アプリケーションとサービス プリンシパルを作成しました。
Spark コネクタは、認証に次の Entra アプリ プロパティを使います。
| プロパティ | オプション文字列 | 説明 |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra アプリケーション (クライアント) 識別子。 |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra 認証機関。 Microsoft Entra ディレクトリ (テナント) ID。 (省略可能) 既定値は microsoft.com です。 詳細については、Microsoft Entra 機関に関する記事を参照してください。 |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | クライアントの Microsoft Entra アプリケーション キー。 |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Kusto にアクセスできる accessToken を既に作成してある場合は、それをコネクタに渡して認証に使うこともできます。 |
注
以前の API バージョン (2.0.0 未満) には、"kustoAADClientID"、"kustoClientAADClientPassword"、"kustoAADAuthorityID" という名前が付けられています。
Kusto の特権
実行する Spark 操作に基づいて、kusto 側で次の特権を許可します。
| Spark の操作 | 特権 |
|---|---|
| 読み取り - 単一モード | 閲覧者 |
| 読み取り – 強制分散モード | 閲覧者 |
| 書き込み - CreateTableIfNotExist テーブル作成オプションを使用したキュー モード | 管理者 |
| 書き込み - FailIfNotExist テーブル作成オプションを使用したキュー モード | 取り込み者 |
| 書き込み – トランザクショナルモード | 管理者 |
プリンシパルのロールについて詳しくは、ロールベースのアクセス制御に関する記事をご覧ください。 セキュリティ ロールの管理については、「security roles management」(セキュリティ ロールの管理) を参照してください。
Spark シンク: Kusto に書き込む
シンクのパラメーターの設定:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Spark DataFrame を Kusto クラスターにバッチとして書き込みます。
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()または、簡略化された構文を使用します。
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ // Optional, for any extra options: val conf: Map[String, String] = Map() val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)ストリーミング データを書き込む:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // As an alternative to adding .option by .option, you can provide a map: val conf: Map[String, String] = Map( KustoSinkOptions.KUSTO_CLUSTER -> cluster, KustoSinkOptions.KUSTO_TABLE -> table, KustoSinkOptions.KUSTO_DATABASE -> database, KustoSourceOptions.KUSTO_ACCESS_TOKEN -> accessToken) // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark ソース: Kusto から読み取る
少量のデータを読み込む場合は、データ クエリを定義します。
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)省略可能: (Kusto ではなく) ユーザーが一時的な BLOB ストレージを提供する場合は、作成される BLOB は呼び出し元の責任になります。 これには、ストレージのプロビジョニング、アクセス キーのローテーション、および一時的な成果物の削除が含まれます。 KustoBlobStorageUtils モジュールには、アカウントとコンテナーの座標およびアカウントの資格情報、または書き込み、読み取り、リストの権限を持つ完全な SAS URL のいずれかに基づいて、BLOB を削除するためのヘルパー関数が含まれています。 対応する RDD が不要になると、トランザクションごとに一時的な BLOB 成果物が別のディレクトリに格納されます。 このディレクトリは、Spark ドライバー ノードで報告される読み取りトランザクション情報ログの一部としてキャプチャされます。
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")上記の例では、コネクタ インターフェイスを使用して Key Vault にアクセスすることはできません。より簡単な Databricks シークレットを使用する方法が使用されます。
Kusto から読み取ります。
あなたが一時的な BLOB ストレージを提供する場合、次の手順で Kusto から読み取ってください。
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Kusto が一時的な BLOB ストレージを提供する場合は、次のように Kusto から読み取ります。
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)