K2Bridge オープンソース コネクタを使用して Kibana で Azure Data Explorer のデータを視覚化する
K2Bridge (Kibana-Kusto Bridge) では、データソースとして Azure Data Explorer を使用し、Kibana でそのデータを視覚化することができます。 K2Bridge はオープンソースのコンテナー化されたアプリケーションです。 Kibana インスタンスと Azure Data Explorer クラスター間のプロキシとして機能します。 この記事では、K2Bridge を使用してその接続を作成する方法について説明します。
K2Bridge では、Kibana クエリが Kusto Query Language (KQL) に変換されて、Azure Data Explorer の結果が Kibana に送り返されます。
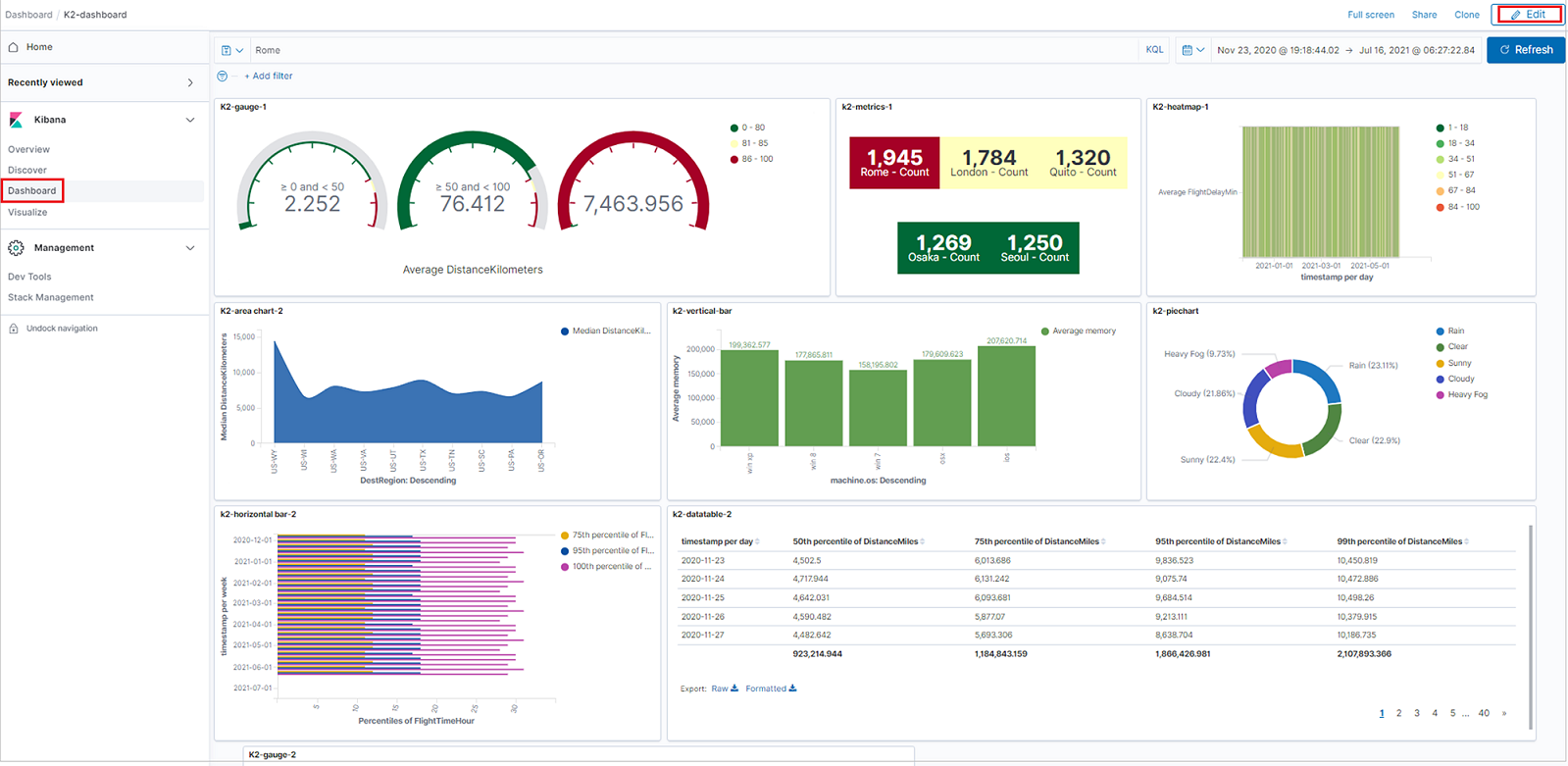
K2Bridge は、Kibana の [検出]、[視覚化]、[ダッシュボード] タブをサポートしています。
[検出] タブでは、次のことができます。
- データの検索と探索。
- 結果のフィルター処理。
- 結果グリッドでのフィールドの追加または削除。
- レコードの内容の表示。
- 検索の保存と共有。
[視覚化] タブでは、次のことができます。
- 横棒グラフ、円グラフ、データ テーブル、ヒート マップなど、視覚化を作成します。
- 視覚化を保存する
[ダッシュボード] タブでは、次のことができます。
- 新規または保存した視覚化を使用して、パネルを作成します。
- ダッシュボードを保存します。
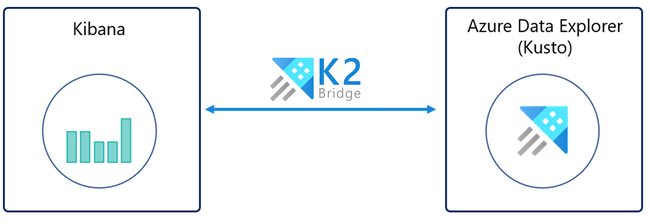
次の図は、K2Bridge によって Azure Data Explorer にバインドされた Kibana インスタンスを示しています。 Kibana のユーザー エクスペリエンスは変更されません。

前提条件
Kibana で Azure Data Explorer のデータを視覚化するには、事前に次の準備をしておく必要があります。
- Azure サブスクリプション。 無料の Azure アカウントを作成します。
- Azure Data Explorer クラスターとデータベース。 クラスターの URL とデータベース名が必要です。
- Helm v3。これは Kubernetes パッケージ マネージャーです。
- Azure Kubernetes Service (AKS) クラスターまたはその他の Kubernetes クラスター。 少なくとも 3 つの Azure Kubernetes サービス ノードで、バージョン 1.21.2 以降を使用してください。 バージョン 1.21.2 のテストと検証が完了しました。 AKS クラスターが必要であれば、Azure CLI を使用して、または Azure portal を使用して、AKS クラスターをデプロイする方法を参照してください。
- クライアント ID とクライアント シークレットを含む、Azure Data Explorer でデータを表示する権限を持つ Microsoft Entra サービス プリンシパル。 また、システム割り当てマネージド ID を使用することもできます。
Microsoft Entra サービス プリンシパルを使用する場合は、Microsoft Entra サービス プリンシパルを 作成する必要があります。 インストールには、ClientID とシークレットが必要です。 サービス プリンシパルに表示アクセス許可を設定することを推奨します。より高いレベルのアクセス許可は使用しないことをお勧めします。 アクセス許可を割り当てるには、「Azure portal でのデータベースの管理アクセス許可」を参照するか、管理コマンドを使用してデータベース セキュリティ ロールを 管理します。
システム割り当て ID を使用する場合は、エージェント プールのマネージド ID ClientID (生成された "[MC_xxxx]" リソース グループにあります) を取得する必要があります。
Azure Kubernetes Service (AKS) で K2Bridge を実行する
既定では、K2Bridges の Helm チャートでは、Microsoft の Container Registry (MCR) にある公開されているイメージが参照されます。 MCR は資格情報を必要としません。
必要な Helm チャートをダウンロードします。
Elasticsearch 依存関係を Helm に追加します。 K2Bridge は内部 Elasticsearch のスモール インスタンスを使用するため、依存関係が必要です。 インスタンスは、インデックス パターン クエリや保存されたクエリなどの、メタデータ関連の要求を処理します。 この内部インスタンスは、ビジネス データを保存しません。 このインスタンスは実装の詳細情報であると考えることができます。
Elasticsearch 依存関係を Helm に追加するには、次のコマンドを実行します。
helm repo add elastic https://helm.elastic.co helm repo updateK2Bridge チャートを GitHub リポジトリの charts ディレクトリから取得するには、以下を実行します。
GitHub からリポジトリを複製します。
K2Bridges ルート リポジトリ ディレクトリに移動します。
次のコマンドを実行します。
helm dependency update charts/k2bridge
K2Bridge をデプロイします。
環境に合わせて変数に正しい値を設定します。
ADX_URL=[YOUR_ADX_CLUSTER_URL] #For example, https://mycluster.westeurope.kusto.windows.net ADX_DATABASE=[YOUR_ADX_DATABASE_NAME] ADX_CLIENT_ID=[SERVICE_PRINCIPAL_CLIENT_ID] ADX_CLIENT_SECRET=[SERVICE_PRINCIPAL_CLIENT_SECRET] ADX_TENANT_ID=[SERVICE_PRINCIPAL_TENANT_ID]Note
マネージド ID を使用する場合、ADX_CLIENT_ID 値はマネージド ID のクライアント ID であり、生成された "[MC_xxxx]" リソース グループにあります。 詳細については、「MC_ リソース グループ」を参照してください。 ADX_SECRET_IDは、Microsoft Entra サービス プリンシパルを使用する場合にのみ必要です。
必要に応じて、Application Insights テレメトリを有効にします。 Application Insights を初めて使用する場合は、Application Insights リソースを作成します。 変数にインストルメンテーション キーをコピーします。
APPLICATION_INSIGHTS_KEY=[INSTRUMENTATION_KEY] COLLECT_TELEMETRY=trueK2Bridge チャートをインストールします。 視覚化とダッシュボードは、Kibana 7.10 バージョンでのみサポートされています。 最新のイメージ タグは、6.8_latest と7.16_latest であり、それぞれ Kibana 6.8 と Kibana 7.10 をサポートしています。 ' 7.16_latest ' のイメージでは Kibana OSS 7.10.2 がサポートされており、その内部 Elasticsearch インスタンスは 7.16.2 です。
Microsoft Entra サービス プリンシパルが使用された場合:
helm install k2bridge charts/k2bridge -n k2bridge --set settings.adxClusterUrl="$ADX_URL" --set settings.adxDefaultDatabaseName="$ADX_DATABASE" --set settings.aadClientId="$ADX_CLIENT_ID" --set settings.aadClientSecret="$ADX_CLIENT_SECRET" --set settings.aadTenantId="$ADX_TENANT_ID" [--set image.tag=6.8_latest/7.16_latest] [--set image.repository=$REPOSITORY_NAME/$CONTAINER_NAME] [--set privateRegistry="$IMAGE_PULL_SECRET_NAME"] [--set settings.collectTelemetry=$COLLECT_TELEMETRY]マネージド ID が使用された場合は、次のようになります。
helm install k2bridge charts/k2bridge -n k2bridge --set settings.adxClusterUrl="$ADX_URL" --set settings.adxDefaultDatabaseName="$ADX_DATABASE" --set settings.aadClientId="$ADX_CLIENT_ID" --set settings.useManagedIdentity=true --set settings.aadTenantId="$ADX_TENANT_ID" [--set image.tag=7.16_latest] [--set settings.collectTelemetry=$COLLECT_TELEMETRY]「構成」では、構成オプションの完全なセットを見つけることができます。
前のコマンドの出力では、Kibana をデプロイする次の Helm コマンドが提案されます。 必要に応じて、次のコマンドを実行します。
helm install kibana elastic/kibana --version 7.17.3 -n k2bridge --set image=docker.elastic.co/kibana/kibana-oss --set imageTag=7.10.2 --set elasticsearchHosts=http://k2bridge:8080ポート フォワーディングを使用して、localhost 上の Kibana にアクセスします。
kubectl port-forward service/kibana-kibana 5601 --namespace k2bridgehttp://127.0.0.1:5601 に移動して、Kibana に接続します。
Kibana をユーザーに公開します。 そのためには複数の方法があります。 使用する方法は、ユース ケースによって大きく異なります。
たとえば、サービスをロード バランサー サービスとして公開できます。 これを行うには、--set service. type = LoadBalancer パラメーターを以前の Kibana Helm インストール コマンドに追加します。
その後、次のコマンドを実行します。
kubectl get service -w -n k2bridge出力は次のように表示されます。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana-kibana LoadBalancer xx.xx.xx.xx <pending> 5601:30128/TCP 4m24s生成され表示された EXTERNAL-IP 値を使用できます。 これを使用して Kibana にアクセスするには、ブラウザーを開き、<EXTERNAL-IP>:5601 に移動します。
データにアクセスするためのインデックス パターンを構成します。
新しい Kibana インスタンスで次のようにします。
- Kibana を開きます。
- [Management]\(管理\) を参照します。
- [Index Patterns]\(インデックス パターン\) を選択します。
- インデックス パターンを作成します。 インデックスの名前は、テーブル名または関数名と完全に一致している必要があります。アスタリスク (*) は使用できません。 リストから関連する行をコピーできます。
Note
K2Bridge を他の Kubernetes プロバイダーで実行するには、Elasticsearch の values.yaml の storageClassName 値を、プロバイダーによって提案されたものに合うように変更します。
データの検出
Azure Data Explorer が Kibana のデータ ソースとして構成されている場合は、Kibana を使用してデータを探索できます。
![Kibana の [検出] タブのスクリーンショット。](media/k2bridge/discover-tab-kibana.png)
Kibana で、[検出] タブを選択します。
[インデックス パターン] のリストから、探索するデータ ソースを定義するインデックス パターンを選択します。 この場合、インデックス パターンは Azure Data Explorer テーブルです。
データに時間フィルター フィールドがある場合は、時間の範囲を指定できます。 [Discover]\(検出\) ページの右上で、時間フィルターを選択します。 既定では、このページには過去 15 分間のデータが表示されます。

結果テーブルには、最初の 500 レコードが表示されます。 ドキュメントを展開して、JSON 形式またはテーブル形式のいずれかで、フィールド データを調べることができます。
![[検出] タブで展開されたレコードのスクリーンショット。](media/k2bridge/k2bridge-expand-record.png)
フィールド名の横にある [add]\(追加\) を選択することで、結果テーブルに特定の列を追加できます。 既定では、[結果] テーブルには、[時間] フィールドが存在する場合は、 _source 列と 時刻 列が含まれます。
クエリ バーでは、次の方法でデータを検索できます。
- 検索用語の入力。
- Lucene クエリ構文の使用。 例:
- "error" を検索して、この値を含むすべてのレコードを検索します。
- "status: 200" を検索して、状態値が 200 のすべてのレコードを取得します。
- 論理演算子 AND、OR、および NOT を使用します。
- アスタリスク (*) と疑問符 (?) のワイルドカード文字を使用します。 たとえば、クエリ "destination_city: L*" は、宛先の市区町村の値が "L" または "l" で始まるレコードと一致します。 (K2Bridge では大文字と小文字は区別されません。)

Note
Kibana の Lucene クエリ構文のみがサポートされています。 Kibana クエリ言語を表す KQL オプションは使用しないでください。
ヒント
「検索」では、さらに多くの検索ルールとロジックを見つけることができます。
検索結果をフィルター処理するには、使用可能なフィールドの一覧を使用します。 フィールド リストには、次の項目が表示されます。
- フィールドの上位 5 つの値。
- フィールドが含まれているレコードの数。
- 各値を含むレコードの割合。
ヒント
虫眼鏡を使用して、特定の値を持つすべてのレコードを検索します。
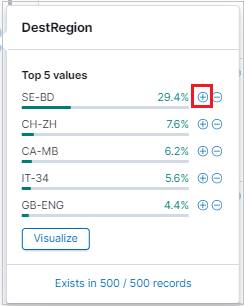
また虫眼鏡を使用して結果をフィルター処理し、結果テーブル内の各レコードの結果テーブル形式ビューを表示することもできます。

検索を保持するには、[Save]\(保存\) または [Share]\(共有\) を選択します。

データの視覚化
Kibana の視覚化を使用して、Azure Data Explorer のデータを一目で確認できます。
[検出] タブから視覚化を作成する
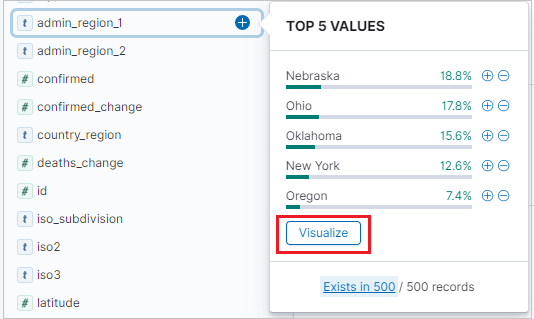
縦棒の視覚化を作成するには、[検出] タブで、[使用できるフィールド] の横棒を見つけます。
![[検出] タブの使用できるフィールドからフィールドを選択中のスクリーンショット。](media/k2bridge/available-fields-discover-tab-kibana.png)
フィールド名を選択し、[視覚化] をクリックします。
[視覚化] タブが開き、視覚化が表示されます。 視覚化のデータとメトリクスを編集するには、「視覚化タブから視覚化を作成する」も参照してください。
![[視覚化] タブから視覚化を編集中のスクリーンショット。](media/k2bridge/edit-visualization.png)
[視覚化] タブから視覚化を作成する
[視覚化] タブを選択し、[視覚化の作成] をクリックします。
![[視覚化] タブを選択中のスクリーンショット。](media/k2bridge/add-visualization.png)
[新しい視覚化] ウィンドウで、視覚化の種類を選択します。
視覚化が生成されたら、メトリクスを編集し、最大で 1 つのバケットに追加できます。
Note
K2Bridge は、バケット集計を 1 つサポートします。 一部の集計では、検索オプションがサポートされています。 Kibana クエリ言語の構文を表す KQL オプションではなく、Lucene 構文を使用します。
重要
Vertical bar、Area chart、Line chart、Horizontal bar、Pie chart、Gauge、Data table、Heat map、Goal chart、およびMetric chartの各視覚化がサポートされています。- サポートされているメトリクスは、
Average、Count、Max、Median、Min、Percentiles、Standard deviation、Sum、Top hitsおよびUnique countです。 - メトリクス
Percentiles ranksはサポートされていません。 - バケット集計の使用は省略可能で、バケット集計なしでデータを視覚化できます。
No bucket aggregation、Date histogram、Filters、Range、Date range、Histogram、およびTermsの各バケットがサポートされています。- バケット
IPv4 rangeとSignificant termsはサポートされていません。
ダッシュボードを作成する
Kibana による視覚化を使用してダッシュボードを作成し、Azure Data Explorer のデータを一目で要約、比較、および対比することができます。
ダッシュボードを作成するには、[ダッシュボード] タブを選択し、[新しいダッシュボードの作成] をクリックします。
![[ダッシュボード] タブを選択中のスクリーンショット。](media/k2bridge/dashboard-tab.png)
新しいダッシュボードが編集モードで開きます。
新しい視覚化パネルを追加するには、[新規作成] をクリックします。
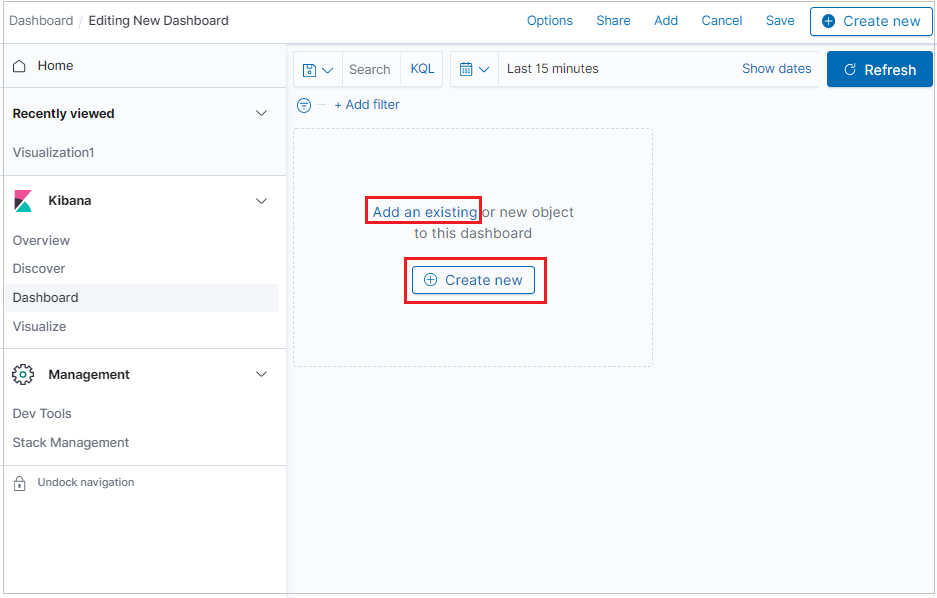
既に作成した視覚化を追加するには、[既存のものを追加] をクリックし、視覚化を選択します。
パネルの整列、優先順位によるパネルの整理、パネルのサイズ変更などを行うには、[編集] をクリックし、次のオプションを使用します。
- パネルを移動するには、パネルのヘッダーをクリックしたまま、新しい場所にドラッグします。
- パネルのサイズを変更するには、[サイズ変更] コントロールをクリックし、新しいディメンションにドラッグします。