Azure ストレージからデータを取得する
データ インジェストは、Azure Data Explorer で 1 つ以上のソースからテーブルにデータを読み込むプロセスです。 取り込まれたデータは、クエリに使用できるようになります。 この記事では、Azure ストレージ (ADLS Gen2 コンテナー、BLOB コンテナー、または個々の BLOB) から新規または既存のテーブルにデータを取得する方法について説明します。
Azure ストレージ アカウントからのインジェストは、1 回限り操作です。 データを継続的に取り込むには、「ストリーミング インジェストの構成」を参照してください。
データ インジェストの一般的な情報については、「 Azure Data Explorer データ インジェストの概要を参照してください。
前提条件
- Microsoft アカウントまたは Microsoft Entra ユーザー ID。 Azure サブスクリプションは不要です。
- Azure Data Explorer Web UI にサインインします。
- Azure Data Explorer クラスターとデータベース。 クラスターとデータベースを作成します。
- ストレージ アカウント。
データを取得する
左側のメニューから Query を選択します。
データを取り込むデータベースを右クリックします。 データの取得を選択します。
![データベースを右クリックし、[オプションの取得] ダイアログが開いている [クエリ] タブのスクリーンショット。](media/get-data-storage/get-data.png)
![データベースを右クリックし、[オプションの取得] ダイアログが開いている [クエリ] タブのスクリーンショット。](media/get-data-storage/get-data.png#lightbox)
ソース
[データの取り込み] ウィンドウで [ソース] タブが選択されます。
使用可能な一覧からデータ ソースを選択します。 この例では Azure ストレージからデータを取り込もうとしています。
![[ソース] タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-storage/select-data-source.png#lightbox)
構成
ターゲット データベースとテーブルを選択します。 新しいテーブルにデータを取り込む場合は、[+ 新しいテーブル] を選択し、テーブル名を入力します。
Note
テーブル名には、スペース、英数字、ハイフン、アンダースコアを含め、最大 1024 文字を使用できます。 特殊文字はサポートされていません。
ソースを追加するには、コンテナーの選択または [URI の追加を選択します。
[コンテナーの選択] 選択した場合次のフィールドに入力します。
![新しいテーブルが入力され、1 つのサンプル データ ファイルが選択されている [構成] タブのスクリーンショット。](media/get-data-storage/configure-tab.png)
設定 フィールドの説明 サブスクリプション ストレージ アカウントが配置されているサブスクリプション ID。 ストレージ アカウント ストレージ アカウントを識別する名前。 コンテナー 取り込むストレージ コンテナー。 ファイル フィルター (省略可能) フォルダー パス 特定のフォルダー パスを持つファイルを取り込むようにデータをフィルター処理します。 ファイル拡張子 特定のファイル拡張子を持つファイルのみを取り込むようにデータをフィルター処理します。 ストレージ アカウントで [URIの追加] を選択した場合は、取り込みたいコンテナーまたは個々の Blob のSAS URLを生成します。 コンテナーのアクセス許可を [読み取り] と [リスト] に設定するか、個々の BLOB のアクセス許可を [読み取り] に設定します。 詳細については、「SAS トークンの生成」を参照してください。
- URI フィールドに URL を貼り付け、プラス (+) を選択します。 個々の BLOB に対して複数の URI を追加することも、コンテナーに 1 つの URI を追加することもできます。
![[構成] タブのスクリーンショット。接続文字列が [URI] フィールドに貼り付けられます。](media/get-data-storage/add-uri.png)
Note
- 最大 10 個の個々の BLOB を追加できます。 各 BLOB の最大サイズは未圧縮で 1 GB です。
- 1 つのコンテナーから最大 5000 個の BLOB を取り込むことができます。
- 同じインジェストで個々の BLOB とコンテナーを取り込むことはありません。
[次へ] を選択します
![新しいテーブルが入力され、1 つのサンプル データ ファイルが選択されている [構成] タブのスクリーンショット。](media/get-data-storage/configure-tab.png#lightbox)
![[構成] タブのスクリーンショット。接続文字列が [URI] フィールドに貼り付けられます。](media/get-data-storage/add-uri.png#lightbox)
検査
[検査] タブが開き、データのプレビューが表示されます。
インジェスト プロセスを完了するには、[完了] を選択します。
![[検査] タブのスクリーンショット。](media/get-data-storage/inspect-data.png#lightbox)
必要に応じて、次の操作を行います。
- [コマンド ビューアー] を選択し、入力から生成される自動コマンドを表示してコピーします。
- [スキーマ定義ファイル] ドロップダウンを使用して、スキーマを推論する元のファイルを変更します。
- ドロップダウンから必要な形式を選択して、自動的に推論されるデータの形式を変更します。 インジェストについては、Azure Data Explorer でサポートされている Data 形式を参照してください。
- 列を編集します。
- データ型に基づく [詳細] オプションを確認します。
列の編集
Note
- 表形式 (CSV、TSV、PSV) では、列を 2 回マップすることはできません。 既存の列にマップするには、最初に新しい列を削除します。
- 既存の列の型を変更することはできません。 異なる形式の列にマップしようとすると、空の列になってしまう場合があります。
テーブルに加えることができる変更は、次のパラメーターによって異なります。
- テーブルの種類が新規かまたは既存か
- マッピングの種類が新規かまたは既存か
| テーブルの種類です。 | マッピングの種類 | 使用可能な調整 |
|---|---|---|
| 新しいテーブル | 新しいマッピング | 列の名前変更、データ型の変更、データ ソースの変更、マッピング変換、列の追加、列の削除 |
| 既存のテーブル | 新しいマッピング | 新しい列の追加 (その後、データ型の変更、名前変更、更新が可能) |
| 既存のテーブル | 既存のマッピング | なし |

マッピング変換
一部のデータ形式マッピング (Parquet、JSON、Avro) では、簡単な取り込み時の変換がサポートされています。 マッピング変換を適用するには、[列の編集] ウィンドウで列を作成または更新します。
マッピング変換は、データ型が int または long であるソースを使用して、string または datetime 型の列に対して実行できます。 サポートされているマッピング変換は次のとおりです。
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
データ型に基づく [詳細] オプション
表形式 (CSV、TSV、PSV):
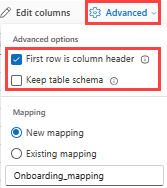
テーブル形式を 既存のテーブルに取り込む場合、 Advanced>Keep 現在のテーブル スキーマを選択できます。 表形式データには、ソース データを既存の列にマップするために使用される列名が必ずしも含まれるとは限りません。 このオプションをオンにすると、マッピングは順番に行われ、テーブル スキーマは同じままになります。 このオプションをオフにすると、データ構造に関係なく、受信するデータに対して新しい列が作成されます。
最初の行を列名として使用するには、[詳細]>[最初の行を列ヘッダーにする] を選択します。
JSON:
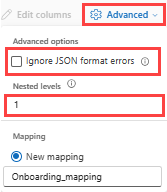
JSON データの列分割を指定するには、[詳細]>[入れ子のレベル] を 1 から 100 までで選択します。
Advanced>Ignore データ形式エラーを選択した場合、データは JSON 形式で取り込まれます。 このチェック ボックスをオフのままにすると、データは multijson 形式で取り込まれます。
まとめ
[データ準備] ウィンドウでは、データ インジェストが正常に終了した場合、3 つのステップすべてに緑色のチェックマークが表示されます。 各ステップで使用されたコマンドを表示したり、取り込まれたデータのクエリ、視覚化、削除を行うカードを選択したりできます。
