Apache Kafka から Azure Data Explorer にデータを取り込む
Apache Kafka は、システム間やアプリケーション間で確実にデータを移動するリアルタイム ストリーミング データ パイプラインを構築するための分散ストリーミング プラットフォームです。 Kafka Connect は、Apache Kafka と他のデータ システムとの間でスケーラブルかつ高い信頼性でデータをストリーム配信するためのツールです。 Kusto Kafka シンク は Kafka からのコネクタとして機能し、コードを使用する必要はありません。 Git リポジトリ または Confluent Connector Hub からシンク コネクタ jar をダウンロードしてください。
この記事では、Kafka クラスターと Kafka コネクタ クラスターのセットアップを簡略化するために自己完結型の Docker セットアップを使用して、Kafka でデータを取り込む方法について説明します。
詳細については、コネクタの Git リポジトリとバージョンの詳細を参照してください。
前提条件
- Azure サブスクリプション。 無料の Azure アカウントを作成します。
- 既定のキャッシュおよび保持ポリシーが設定された Azure Data Explorer クラスターおよびデータベース。
- Azure CLI。
- Docker と Docker Compose
Microsoft Entra サービス プリンシパルを作成する
Microsoft Entra サービス プリンシパルは、次の例のように Azure portal またはプログラムを使用して作成できます。
このサービス プリンシパルは、コネクタが Kusto テーブルにデータを書き込むために使用する ID です。 Kusto リソースにアクセスするためのアクセス許可をこのサービス プリンシパルに付与します。
Azure CLI 経由で Azure サブスクリプションにサインインします。 次に、ブラウザーで認証します。
az loginプリンシパルをホストするサブスクリプションを選択します。 この手順は、複数のサブスクリプションがある場合に必要です。
az account set --subscription YOUR_SUBSCRIPTION_GUIDサービス プリンシパルを作成します。 この例では、サービス プリンシパルを
my-service-principalと呼びます。az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}返された JSON データから、
appId、password、およびtenantを後で使用のためにコピーします。{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Microsoft Entra アプリケーションとサービス プリンシパルが作成されました。
ターゲット テーブルを作成する
クエリ環境から、次のコマンドを使用して
Stormsというテーブルを作成します。.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)次のコマンドを使用して、取り込まれたデータに対応するテーブル マッピング
Storms_CSV_Mappingを作成します。.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'構成可能なキューに入れられたインジェスト待機時間用のインジェスト バッチ ポリシーをテーブルに作成します。
ヒント
インジェスト バッチ処理ポリシーはパフォーマンス オプティマイザーであり、3 つのパラメーターを含みます。 最初の条件が満たされると、テーブルへのインジェストがトリガーされます。
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'「Microsoft Entra のサービス プリンシパルを作成する」のサービス プリンシパルを使用して、データベースを操作するアクセス許可を付与します。
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
ラボを実行する
次のラボは、データの作成の開始、Kafka コネクタの設定、およびこのデータのストリーミングのエクスペリエンスをユーザーに提供するように設計されています。 その後、取り込まれたデータを確認できます。
Git リポジトリをクローンする
ラボの Git リポジトリをクローンします。
お使いのマシン上にローカル ディレクトリを作成します。
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holリポジトリをクローンします。
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
クローンされたリポジトリの内容
次のコマンドを実行して、クローンされたリポジトリの内容を一覧表示します。
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
この検索の結果は次のとおりです。
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
クローンされたリポジトリ内のファイルを確認する
次のセクションでは、ファイル ツリー内のファイルの重要な部分について説明します。
adx-sink-config.json
このファイルには、特定の構成の詳細を更新する Kusto シンク プロパティ ファイルが含まれています。
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
セットアップに従って、aad.auth.authority、aad.auth.appid、aad.auth.appkey、kusto.tables.topics.mapping (データベース名)、kusto.ingestion.url、kusto.query.url の各属性の値を置き換えてください。
connector - Dockerfile
このファイルには、コネクタ インスタンス用の Docker イメージを生成するコマンドが含まれています。 これには、Git リポジトリのリリース ディレクトリからのコネクタのダウンロードが含まれています。
storm-events-producer ディレクトリ
このディレクトリには、ローカルの "StormEvents.csv" ファイルを読み取り、そのデータを Kafka トピックに発行する Go プログラムがあります。
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
コンテナーを開始する
ターミナルで、コンテナーを開始します。
docker-compose upプロデューサー アプリケーションによって、
storm-eventsトピックへのイベントの送信が開始されます。 次のようなログが表示されます。.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....ログを確認するには、別のターミナルで次のコマンドを実行します。
docker-compose logs -f | grep kusto-connect
コネクタを開始する
Kafka Connect REST 呼び出しを使用して、コネクタを開始します。
別のターミナルで、次のコマンドを使用してシンク タスクを起動します。
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectors状態を確認するには、別のターミナルで次のコマンドを実行します。
curl http://localhost:8083/connectors/storm/status
コネクタは、インジェスト プロセスのキュー登録を開始します。
Note
ログ コネクタの問題がある場合は、issue を作成します。
マネージド ID
既定では、Kafka コネクタは、インジェスト中に認証にアプリケーションの方法を使用します。 マネージド ID を使用して認証するには:
クラスターにマネージド ID を割り当て、ストレージ アカウントに読み取りアクセス許可を付与します。 詳細については、「 マネージド ID 認証を使用したデータのインレスト」を参照してください。
adx-sink-config.json ファイルで、
aad.auth.strategyをmanaged_identityに設定し、aad.auth.appidがマネージド ID クライアント (アプリケーション) ID に設定されていることを確認します。Microsoft Entra サービス プリンシパルの代わりにインスタンス メタデータ サービス トークンを使用。
Note
マネージド ID を使用する場合、 appId と tenant は呼び出しサイトのコンテキストから推測され、 password は必要ありません。
データのクエリを実行して確認する
データ インジェストを確認する
データが
Stormsテーブルに到着したら、行数を確認して、データの転送を確認します。Storms | countインジェスト プロセスでエラーが発生していないことを確認します。
.show ingestion failuresデータを確認したら、クエリをいくつか試してみてください。
データにクエリを実行する
すべてのレコードを表示するには、次のクエリを実行します。
Storms | take 10whereとprojectを使用して、特定のデータをフィルター処理します。Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdsummarize演算子を使用します。Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart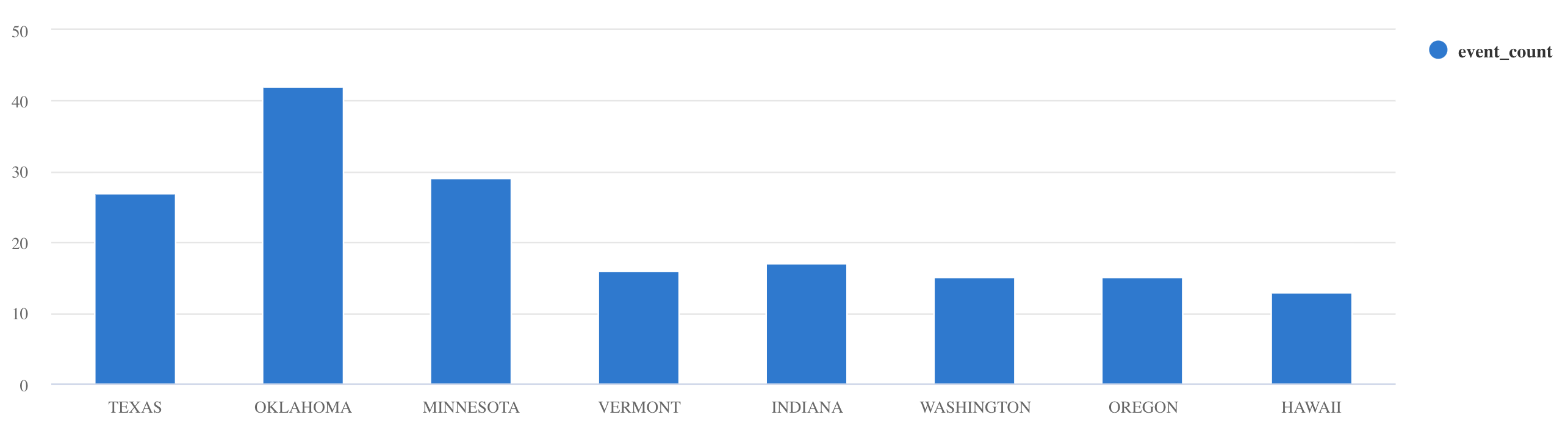
その他のクエリの例とガイダンスについては、「KQL のクエリを記述する」と Kusto クエリ言語のドキュメントを参照してください。
リセット
リセットするには、次の手順を実行します。
- コンテナーを停止します (
docker-compose down -v) - 削除 (
drop table Storms) Stormsテーブルを再作成します- テーブル マッピングを再作成します
- コンテナーを再起動します (
docker-compose up)
リソースをクリーンアップする
Azure Data Explorer リソースを削除するには、 az kusto cluster delete (kusto extension) または az kusto database delete (kusto extension)を使用します。
az kusto cluster delete --name "<cluster name>" --resource-group "<resource group name>"
az kusto database delete --cluster-name "<cluster name>" --database-name "<database name>" --resource-group "<resource group name>"
クラスターとデータベースは、 Azure ポータルから削除することもできます。 詳細については、「Azure Data Explorer クラスターを削除するAzure Data Explorer でデータベースを削除するを参照してください。
Kafka シンク コネクタのチューニング
インジェスト バッチ処理ポリシーを使用するために Kafka シンク コネクタを調整します。
- Kafka シンク
flush.size.bytesのサイズ制限を 1 MB から調整し、10 MB または 100 MB の増分ずつ増やします。 - Kafka シンクを使用する場合、データは 2 回集計されます。 コネクタ側のデータはフラッシュ設定に従って集計され、サービス側ではバッチ処理ポリシーに従って集計されます。 バッチ処理時間が短すぎてコネクタとサービスの両方でデータを取り込めなかった場合は、バッチ処理時間を長くする必要があります。 バッチ処理サイズを 1 GB に設定し、必要に応じて 100 MB ずつ増減します。 たとえば、フラッシュ サイズが 1 MB で、バッチ処理ポリシー サイズが 100 MB の場合、Kafka シンク コネクタはデータを 100 MB のバッチに集計します。 そのバッチは、サービスによって取り込まれます。 バッチ処理ポリシーの時間が 20 秒で、Kafka シンク コネクタが 20 秒間に 50 MB をフラッシュする場合、サービスは 50 MB のバッチを取り込みます。
- インスタンスと Kafka パーティションを追加することでスケーリングできます。
tasks.maxをパーティションの数まで増やします。flush.size.bytes設定のサイズの BLOB に生成するのに十分なデータがある場合は、パーティションを作成します。 BLOB が小さい場合、バッチは制限時間に達したときに処理されるため、パーティションは十分なスループットを受け取ることができません。 パーティションの数が多い場合は、処理オーバーヘッドが増えます。