Azure Cosmos DB for PostgreSQL でのスケーリングの基本的な概念
適用対象: ![]() Azure Cosmos DB for PostgreSQL (PostgreSQL の Citus データベース拡張機能を利用)
Azure Cosmos DB for PostgreSQL (PostgreSQL の Citus データベース拡張機能を利用)
新しいアプリの構築手順に進む前に、関係する用語と概念について簡単に説明します。
アーキテクチャの概要
Azure Cosmos DB for PostgreSQL を使うと、テーブルやスキーマをクラスター内の複数のマシンに分散させ、プレーンな PostgreSQL のクエリと同じように、それらのクエリを透過的に実行できます。
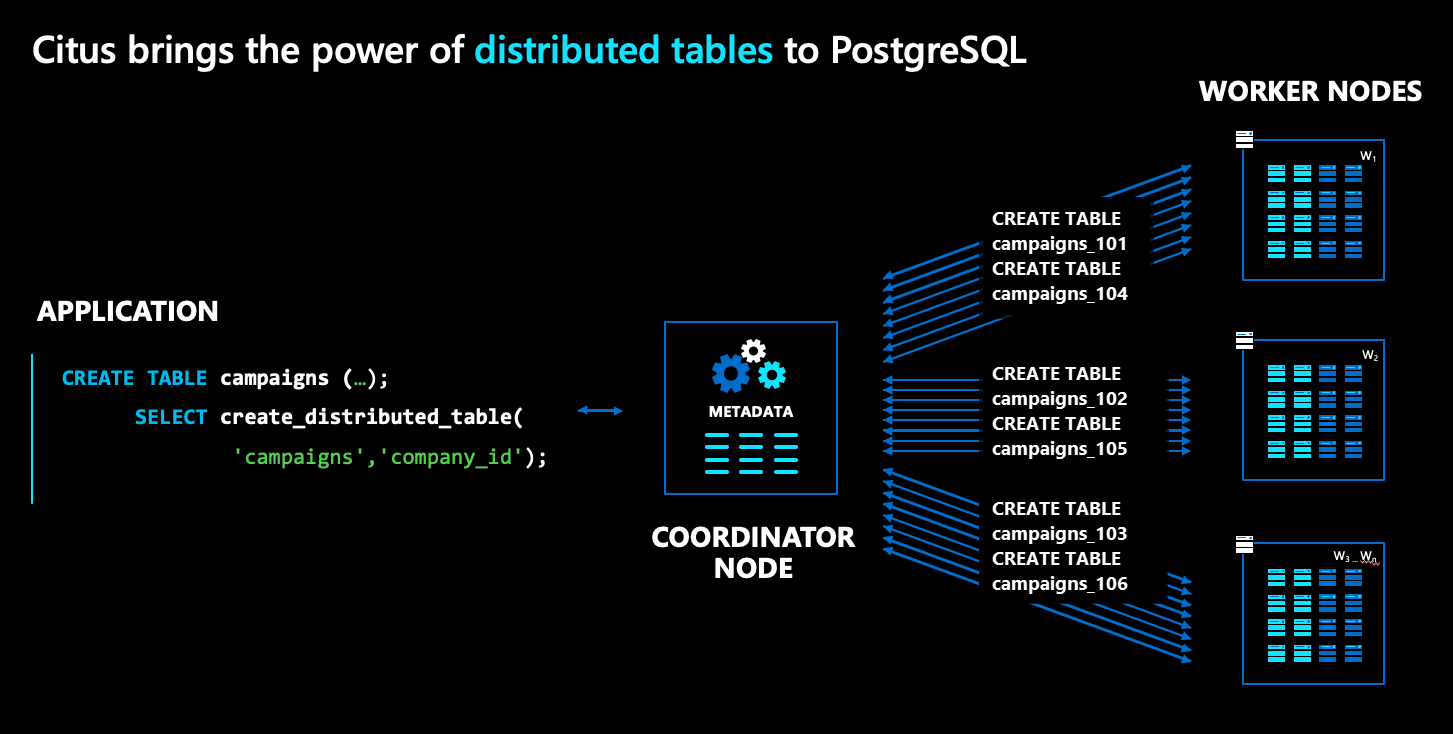
Azure Cosmos DB for PostgreSQL アーキテクチャには、次のような複数の種類のノードがあります。
- コーディネーター ノードは、分散テーブルのメタデータを格納し、分散計画を担当します。
- これに対し、ワーカー ノードは、実際のデータとメタデータを格納し、計算を行います。
- コーディネーターとワーカーはどちらもプレーン PostgreSQL データベースであり、
citus拡張機能が読み込まれています。
上の図の campaigns のような通常の PostgreSQL テーブルを分散するには、create_distributed_table() というコマンドを実行します。 このコマンドを実行すると、Azure Cosmos DB for PostgreSQL により、テーブルのシャードがワーカー ノード間で透過的に作成されます。 図では、青のボックスでシャードを表しています。
通常の PostgreSQL スキーマを分散させるには、citus_schema_distribute() コマンドを実行します。 このコマンドを実行すると、Azure Cosmos DB for PostgreSQL は、このようなスキーマ内のテーブルを、クラスターのノード間で 1 つの単位として移動できる、単一のシャード併置テーブルに透過的に変換します。
Note
ワーカー ノードのないクラスターでは、分散テーブルのシャードはコーディネーター ノード上にあります。
シャードは、データのスライスを保持するプレーンな (ただし特別な名前の) PostgreSQL テーブルです。 この例では、company_id によって campaigns を分散したので、シャードはキャンペーンを保持し、さまざまな会社のキャンペーンがさまざまなシャードに割り当てられます。
分散列 (別名シャード キー)
create_distributed_table() は、テーブルを分散したり、複数のマシンにまたがってリソースを使用したりするために Azure Cosmos DB for PostgreSQL が提供するマジック関数です。
SELECT create_distributed_table(
'table_name',
'distribution_column');
上記の 2 番目の引数は、テーブルから分散列として列を選択します。 ネイティブ PostgreSQL 型の任意の列を指定できます (整数とテキストが最も一般的です)。 分散列の値によって、どの行がどのシャードに入るかが決まります。そのため、分散列はシャード キーとも呼ばれます。
Azure Cosmos DB for PostgreSQL は、シャード キーの使用に基づいてクエリの実行方法を決定します。
| クエリに関係するもの | これを実行しています。 |
|---|---|
| ただ 1 つのシャード キー | そのシャードを保持するワーカー ノード |
| 複数のシャード キー | 複数のノード間で並列化 |
シャード キーの選択により、アプリケーションのパフォーマンスとスケーラビリティが決まります。
- シャード キーあたりの不均一なデータ分散 (データ スキューとも呼ばれます) は、パフォーマンスにとって最適ではありません。 たとえば、1 つの値がデータの 50% を表す列を選択しないでください。
- カーディナリティが低いシャード キーは、スケーラビリティに影響を与える可能性があります。 個別のキー値があるのと同じ数のシャードのみを使用できます。 カーディナリティが数百から数千のキーを選択してください。
- シャード キーが異なる 2 つの大きなテーブルの結合には、時間がかかる場合があります。 大きなテーブル間で共通のシャード キーを選択してください。 「コロケーション」で詳しく説明します。
併置
シャード キーに密接に関連するもう 1 つの概念は、コロケーションです。 同じ分散列の値によってシャード化されたテーブルは併置され、併置されたテーブルのシャードは同じワーカーにまとめて格納されます。
同じキー site_id によってシャード化された 2 つのテーブルを次に示します。 これらは併置されます。
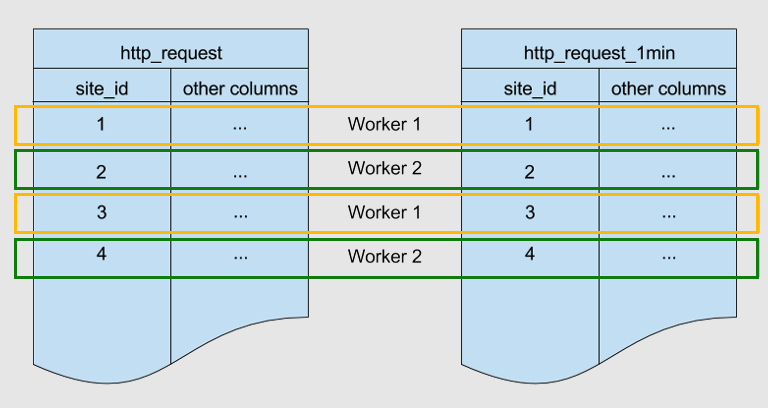
Azure Cosmos DB for PostgreSQL は、両方のテーブルで site_id の値が一致する行が同じワーカー ノードに格納されることを保証します。 両方のテーブルで、site_id=1 を含む行がワーカー 1 に格納されていることがわかります。 他のサイト ID についても同様です。
コロケーションは、これらのテーブル全体で JOIN を最適化するのに役立ちます。 site_id で 2 つのテーブルを結合すると、Azure Cosmos DB for PostgreSQL では、ノード間でデータをシャッフルすることなく、ワーカー ノードでローカル結合を実行できます。
分散スキーマ内のテーブルは、常に相互に併置されます。