1 対多のリレーショナル データを Azure Cosmos DB for NoSQL アカウントに移行する
適用対象: ![]() NoSQL
NoSQL
リレーショナル データベースから Azure Cosmos DB for NoSQL に移行するには、最適化のためにデータ モデルに変更を加える必要がある場合があります。
1 つの一般的な変換では、関連するサブ項目を 1 つの JSON ドキュメント内に埋め込むことによってデータを非正規化します。 ここでは、Azure Data Factory または Azure Databricks を使用して、このためのいくつかのオプションについて説明します。 Azure Cosmos DB のデータ モデリングの詳細については、「Azure Cosmos DB でのデータ モデリング」を参照してください。
シナリオ例
SQL データベースに、Orders と OrderDetails という 2 つのテーブルがあると仮定します。
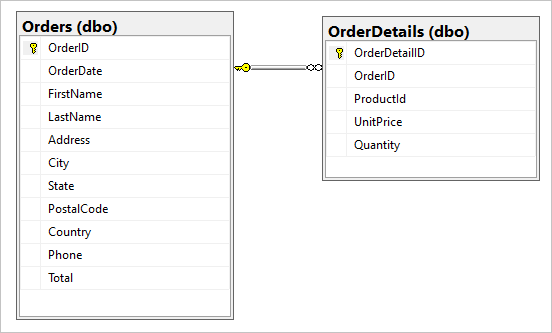
移行中に、この 1 対多のリレーションシップを 1 つの JSON ドキュメントに結合します。 1 つのドキュメントを作成するには、FOR JSON を使用して T-SQL クエリを作成します。
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
このクエリの結果には、Orders テーブルのデータが含まれます。

理想的には、単一の Azure Data Factory (ADF) コピー アクティビティを使用してソースとして SQL データのクエリを実行し、出力を適切な JSON オブジェクトとして Azure Cosmos DB シンクに直接書き込みます。 現時点では、1 つのコピー アクティビティで必要な JSON 変換を実行することはできません。 上記のクエリの結果を Azure Cosmos DB for NoSQL コンテナーにコピーしようとすると、OrderDetails フィールドが、予期される JSON 配列ではなく、ドキュメントの文字列プロパティとして表示されます。
この現時点の制限には、次のいずれかの方法で回避できます。
- 2 つのコピー アクティビティで Azure Data Factory を使用する:
- SQL から中間 BLOB ストレージの場所にあるテキストファイルに JSON 形式のデータを取得する
- Azure Cosmos DB で、JSON テキストファイルからコンテナーにデータを読み込みます。
- Azure Databricks を使用して SQL から読み取り、Azure Cosmos DB に書き込む - ここでは 2 つのオプションを提示します。
これらの方法を詳しく見てみましょう。
Azure Data Factory
OrderDetails を変換先 Azure Cosmos DB ドキュメントに JSON 配列として埋め込むことはできませんが、2 つの異なるコピー アクティビティを使用して問題を回避できます。
コピー アクティビティ #1: SqlJsonToBlobText
ソース データの場合、SQL クエリを使用して、SQL Server の OPENJSON 機能と FOR JSON PATH 機能を使用して、行ごとに 1 つの JSON オブジェクト (Order を表す) を含む 1 つの列として結果セットを取得します。
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)
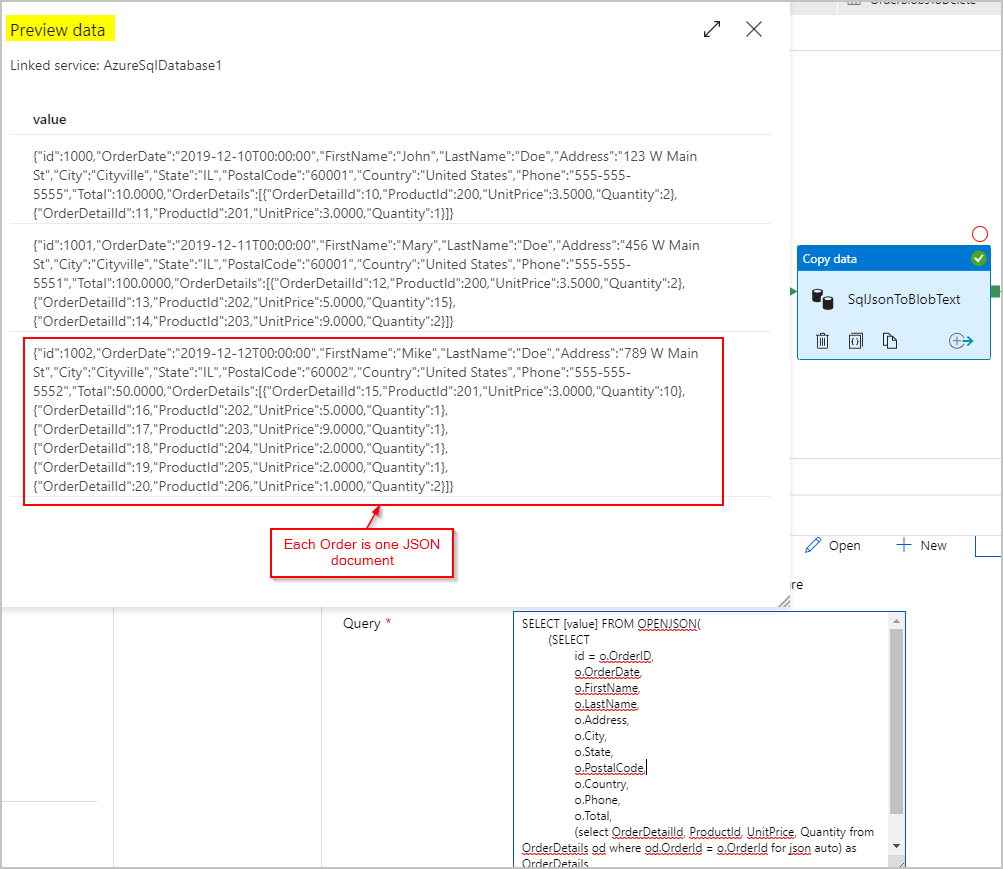
SqlJsonToBlobText コピー アクティビティのシンクでは、"区切りテキスト" を選択し、Azure Blob Storage 内の特定のフォルダーを指定します。 このシンクには、動的に生成された一意のファイル名 (例、@concat(pipeline().RunId,'.json')) が含まれます。
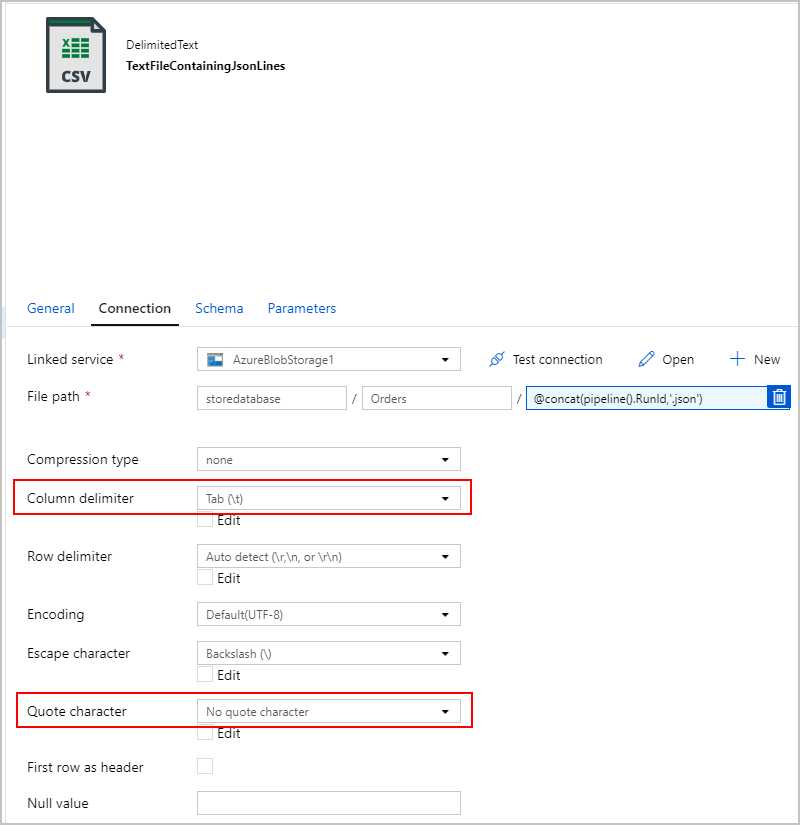
このテキスト ファイルは実際には "区切られて" おらず、コンマを使用して個別の列に解析したいとは考えていません。 さらに、二重引用符 (") を保持し、"列区切り記号"をタブ ("\t")、つまりデータに出現しない別の文字に設定し、"引用符文字" を "引用符文字なし" に設定したいと考えています。
コピー アクティビティ #2: BlobJsonToCosmos
次に、最初のアクティビティによって作成されたテキスト ファイルを Azure Blob Storage で検索する 2 番目のコピー アクティビティを追加して、ADF パイプラインを変更します。 これは、テキスト ファイルで見つかった JSON 行ごとに 1 つのドキュメントとして Azure Cosmos DB シンクに挿入する "JSON" ソースとして処理されます。
![JSON ソース ファイルと [ファイル パス] フィールドが強調表示されているスクリーンショット。](media/migrate-relational-data/adf3.png)
また、必要に応じて、各実行の前に /Orders/ フォルダーに残っている以前のすべてのファイルを削除するように、パイプラインに "削除" アクティビティを追加します。 これで、ADF パイプラインは以下のようになっているはずです。
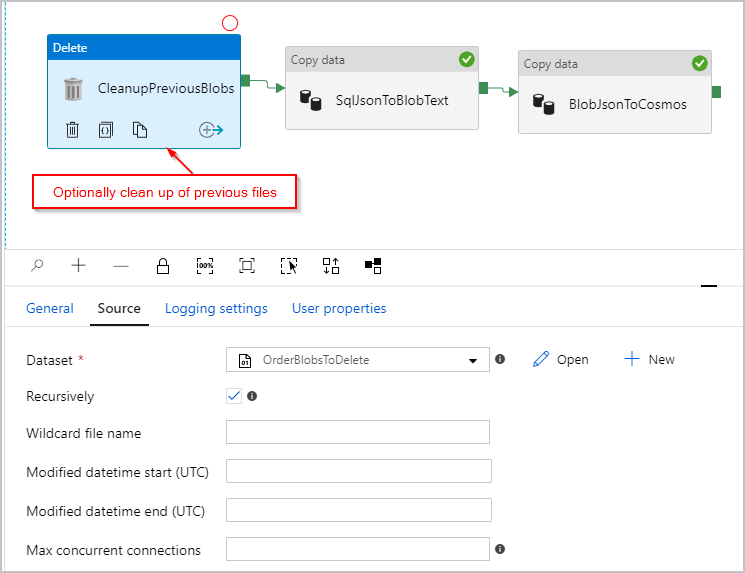
上記のパイプラインをトリガーすると、中間 Azure Blob Storage の場所に、1 行に 1 つの JSON オブジェクトを含むファイルが作成されます。
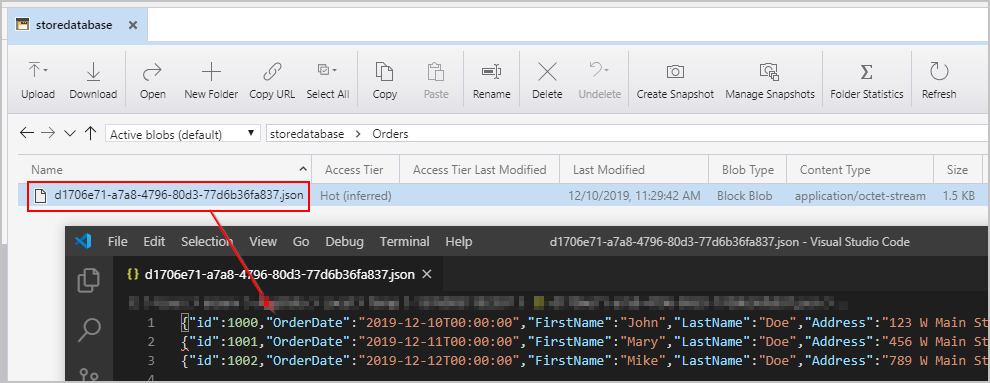
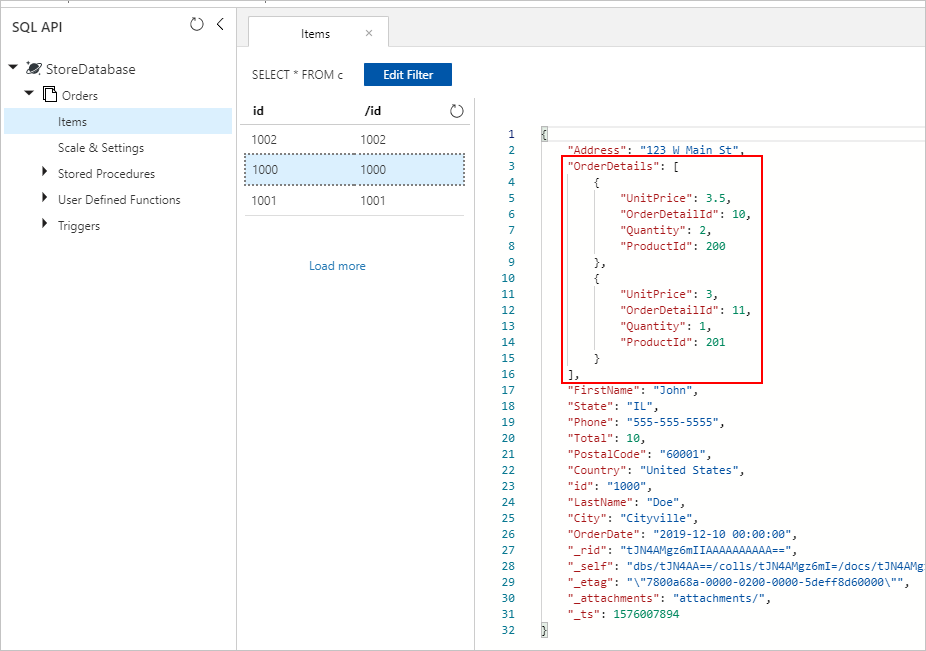
また、Azure Cosmos DB コレクションに挿入された OrderDetails が適切に埋め込まれた Orders ドキュメントも表示されます。
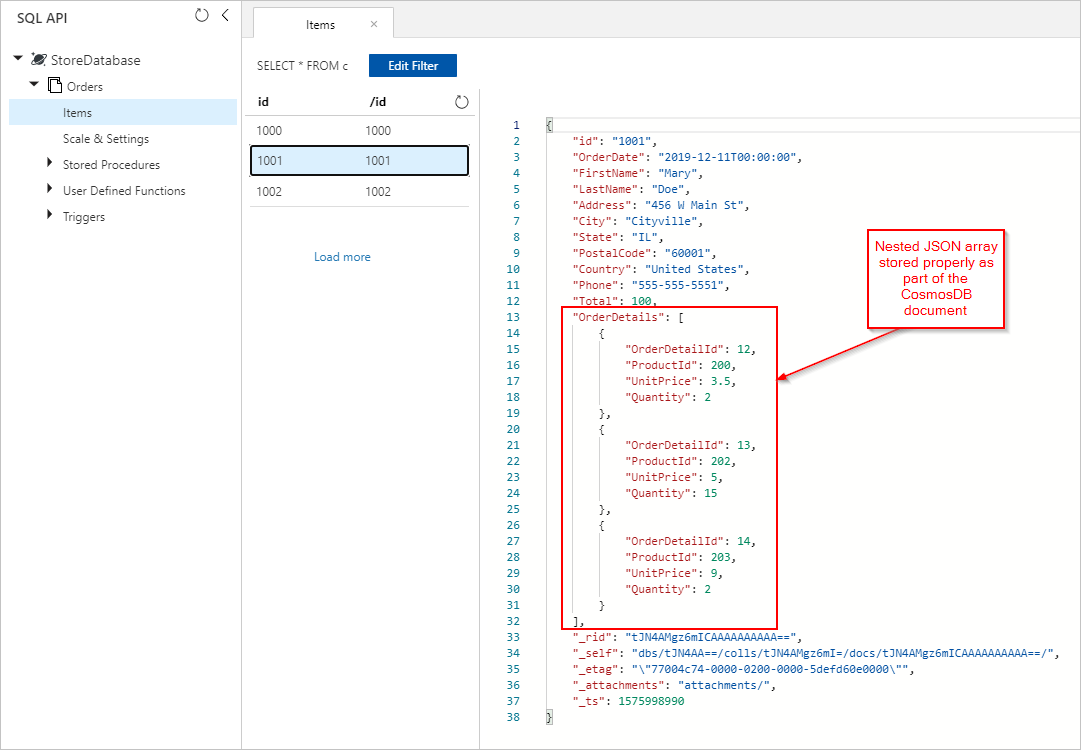
Azure Databricks
また、Azure Databricks で Spark を使用して、Azure Blob Storage に中間テキスト/JSON ファイルを作成せずに、SQL Database のソースから Azure Cosmos DB のコピー先にデータをコピーすることもできます。
Note
明確でわかりやすくするために、コード スニペットには、ダミーのデータベースのパスワードがインラインに明示的に含まれていますが、理想的に Azure Databricks シークレットを使用する必要があります。
まず、必要な SQL コネクタと Azure Cosmos DB コネクタ ライブラリを作成して、Azure Databricks クラスターに接続します。 クラスターを再起動して、ライブラリが読み込まれていることを確認します。

次に、Scala と Python の 2 つのサンプルを紹介します。
Scala
ここでは、DataFrame に "FOR JSON" 出力を含む SQL クエリの結果を取得します。
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
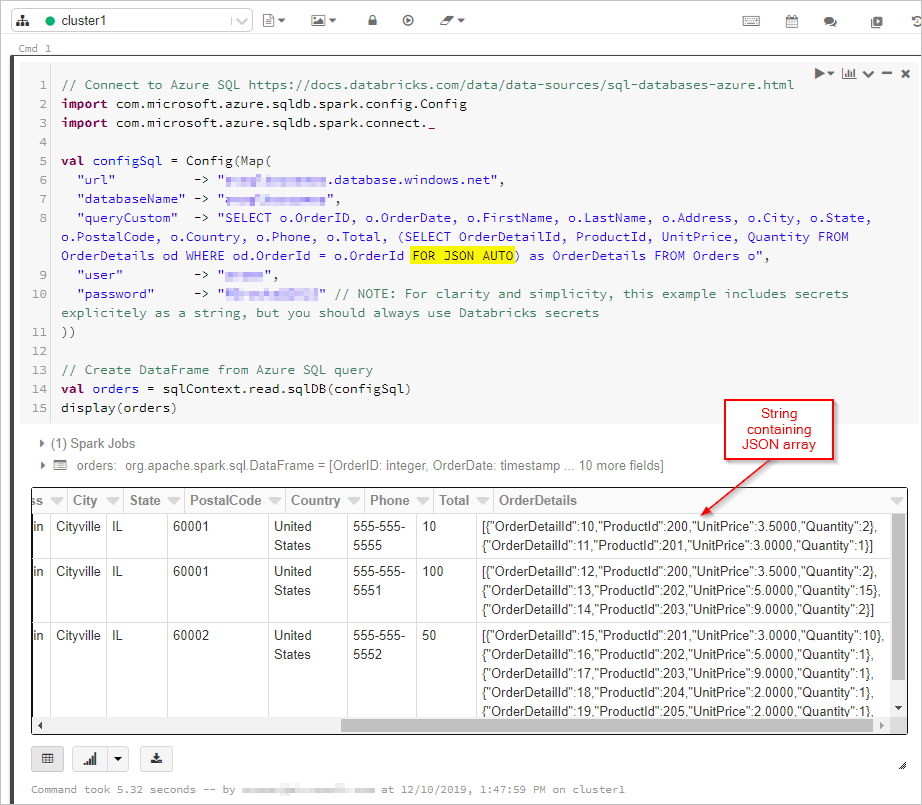
次に、Azure Cosmos DB データベースとコレクションに接続します。
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
最後に、スキーマを定義し、from_json を使用して、Cosmos DB コレクションに保存する前に DataFrame を適用します。
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
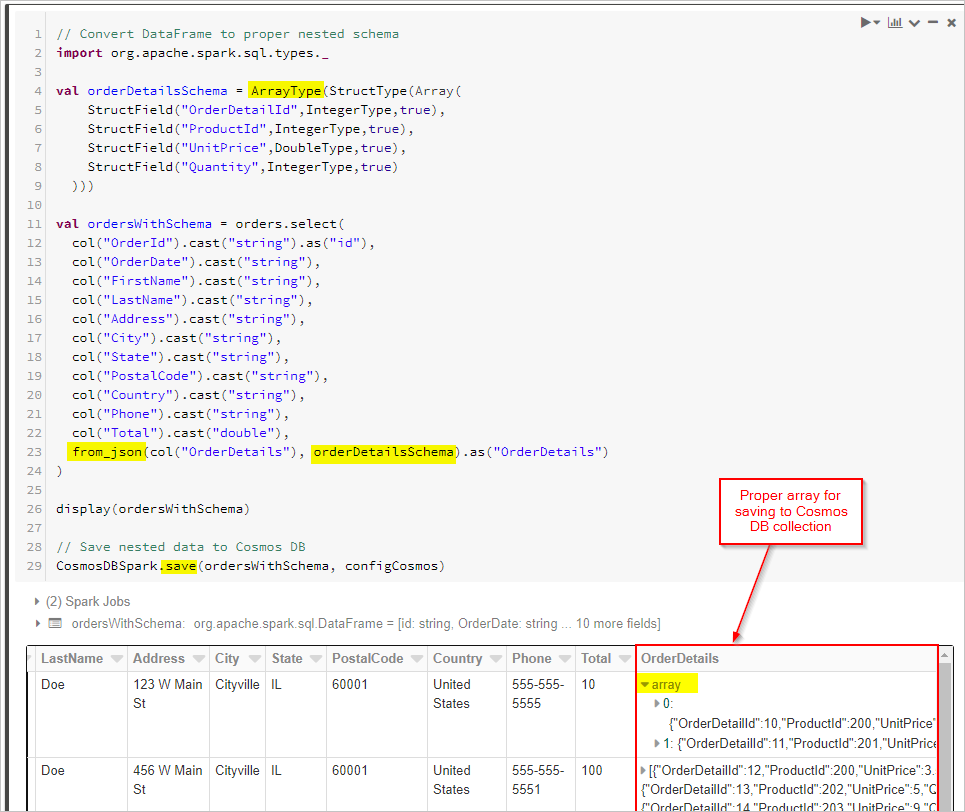
Python
別の方法として、ソース データベースで FOR JSON または同様の操作がサポートされていない場合は、Spark で JSON 変換を実行する必要がある場合があります。 または、大規模なデータ セットに対して並列操作を使用することもできます。 ここでは、PySpark サンプルを紹介します。 最初のセルにソースとターゲットのデータベース接続を構成することから始めます。
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
次に、注文と注文の詳細の両方のレコードについて、ソースのデータベース (この場合は SQL Server) のクエリを実行し、結果を Spark Dataframes に配置します。 また、すべての注文 ID を含む一覧と、並列操作のスレッド プールも作成します。
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
次に、ターゲットの NoSQL 用 API コレクションに注文を書き込むための関数を作成します。 この関数は、指定された注文 ID のすべての注文の詳細をフィルター処理し、それらを JSON 配列に変換して、配列を JSON ドキュメントに挿入します。 その後、JSON ドキュメントは、その順序で NoSQL コンテナーのターゲット API に書き込まれます。
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#https://learn.microsoft.com/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
最後に、スレッド プールでマップ関数を使用して Python writeOrder 関数を呼び出し、前に作成した注文 ID の一覧を渡して並列実行します。
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
どちらの方法でも、最終的には、Azure Cosmos DB コレクション内の各注文ドキュメント内に埋め込まれた OrderDetails を適切に保存する必要があります。
次のステップ
- Azure Cosmos DB のデータ モデリングについて確認する
- Azure Cosmos DB のデータをモデル化およびパーティション分割する方法について確認する