Azure Cosmos DB のインデックス作成の概要
適用対象: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Cosmos DB はスキーマ非依存のデータベースであり、スキーマやインデックスの管理に対応することなく、アプリケーション上で反復処理を実行することができます。 Azure Cosmos DB の既定では、コンテナー内のすべての項目のすべてのプロパティに自動的にインデックスが作成されます。スキーマの定義やセカンダリ インデックスの構成は必要ありません。
この記事の目的は、Azure Cosmos DB がデータのインデックスを作成する方法と、インデックスを使用してクエリのパフォーマンスを向上する方法について説明することです。 インデックス作成ポリシーのカスタマイズ方法を検討する前に、このセクションに目を通すことをお勧めします。
項目からツリーへ
項目がコンテナーに格納されるたびに、そのコンテンツは JSON ドキュメントとして投影され、ツリー表現に変換されます。 この変換により、その項目のすべてのプロパティがツリー内のノードとして表示されます。 擬似ルート ノードは、項目のすべての第 1 レベル プロパティに対する親として作成されます。 リーフ ノードには、項目に格納されている実際のスカラー値が含まれます。
たとえば、次の項目を検討してみましょう。
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
このツリーは、JSON 項目の例を表しています。
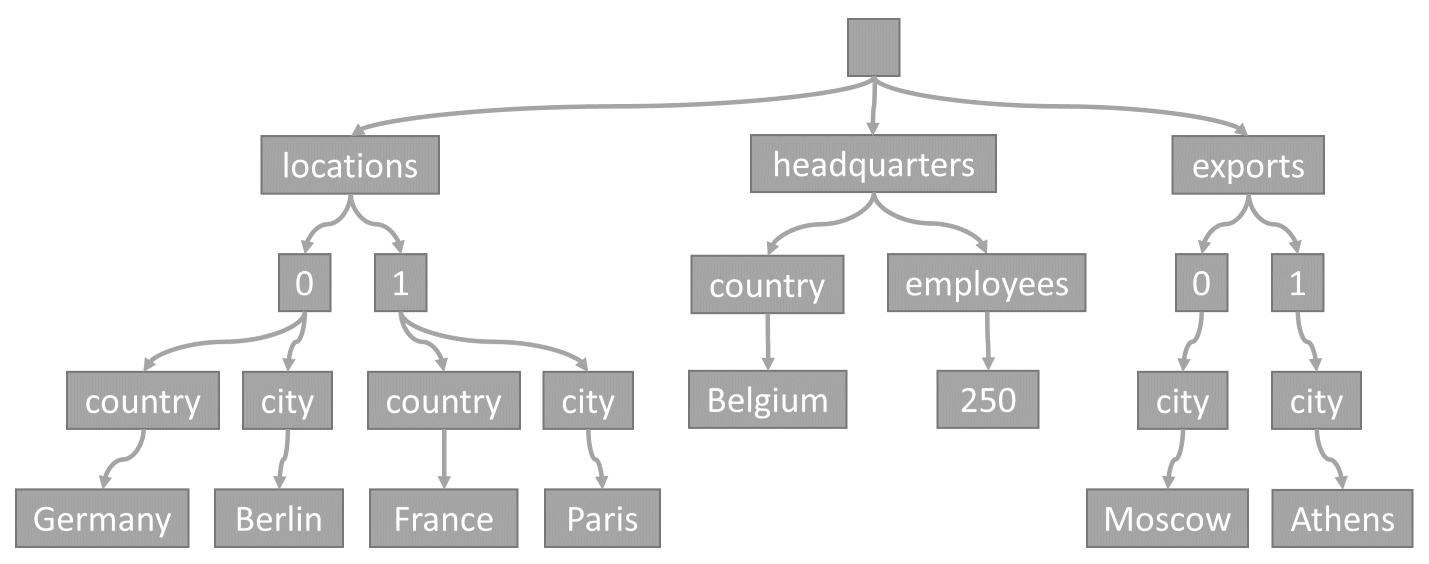
ツリー内で配列がどのようにエンコードされるかに注目します。配列内の各エントリは、配列内のそのエントリのインデックス (0、1 など) でラベル付けされた中間ノードを取得します。
ツリーからプロパティ パスへ
Azure Cosmos DB が項目をツリーに変換する理由は、そのようなツリー内のパスを使用して、システムがプロパティを参照できるようにするためです。 プロパティのパスを取得するには、ルート ノードからそのプロパティまでツリーを走査し、たどった各ノードのラベルを連結します。
前述の例の項目から各プロパティへのパスは次のとおりです。
/locations/0/country: "Germany"/locations/0/city: "Berlin"/locations/1/country: "France"/locations/1/city: "Paris"/headquarters/country: "Belgium"/headquarters/employees: 250/exports/0/city: "Moscow"/exports/1/city: "Athens"
項目が書き込まれると、Azure Cosmos DB では、各プロパティのパスとそれに対応する値のインデックスが効果的に作成されます。
インデックスのタイプ
現在、Azure Cosmos DB では 3 種類のインデックスがサポートされています。 インデックス作成ポリシーを定義するときに、これらのインデックスのタイプを構成できます。
範囲インデックス
範囲インデックスは、順序付けされたツリーのような構造に基づいています。 範囲インデックス タイプは、次のために使用されます。
等値クエリ:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")配列要素の等値一致
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")範囲クエリ:
SELECT * FROM container c WHERE c.property > 'value'注意
(
>、<、>=、<=、!=に適しています)プロパティが存在するかどうかの確認:
SELECT * FROM c WHERE IS_DEFINED(c.property)文字列システム関数:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYクエリ:SELECT * FROM container c ORDER BY c.propertyJOINクエリ:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
範囲インデックスは、スカラー値 (文字列または数値) に使用できます。 新しく作成したコンテナーの既定のインデックス作成ポリシーでは、文字列または数値に範囲インデックスが適用されます。 範囲インデックスを構成する方法については、範囲インデックス作成ポリシーの例に関する記事を参照してください。
Note
1 つのプロパティで並べ替える ORDER BY 句には常に範囲インデックスが必要であり、その句が参照するパスにこのインデックスが存在しない場合は失敗します。 同様に、複数のプロパティで並べ替える ORDER BY クエリには、常に複合インデックスが必要です。
空間インデックス
空間インデックスを使用すると、点、線、多角形、複数の多角形などの地理空間オブジェクトに対して、効率的なクエリを行うことができます。 これらのクエリでは、ST_DISTANCE、ST_WITHIN、ST_INTERSECTS の各キーワードを使用します。 空間インデックス タイプを使用するいくつかの例を次に示します。
地理空間距離クエリ:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40クエリ内の地理空間:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })地理空間交差クエリ:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
空間インデックスは、正しい形式の GeoJSON オブジェクトに対して使用できます。 現在、Points、LineStrings、Polygons、MultiPolygons がサポートされています。 空間インデックスを構成する方法については、空間インデックス作成ポリシーの例に関する記事を参照してください。
複合インデックス
複合インデックスを使用すると、複数のフィールドに対して操作を実行するときの効率が向上します。 複合インデックス タイプは、次のために使用されます。
複数のプロパティに対する
ORDER BYクエリ:SELECT * FROM container c ORDER BY c.property1, c.property2フィルターと
ORDER BYを使用するクエリ。 これらのクエリは、フィルター プロパティがORDER BY句に追加された場合に、複合インデックスを利用できます。SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2少なくとも 1 つのプロパティが等値フィルターである 2 つ以上のプロパティに対するフィルターを使用するクエリ
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
1 つのフィルター述語でいずれかのインデックス タイプが使用されている限り、クエリ エンジンでは、残りの部分をスキャンする前に最初にそれが評価されます。 たとえば、次のような SQL クエリがあるとします: SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
上のクエリでは、最初にインデックスを使用して firstName = "Andrew" のエントリがフィルター処理されます。 次に、すべての firstName = "Andrew" エントリが後続のパイプラインを通過して、CONTAINS フィルター述語が評価されます。
CONTAINS などのフル スキャンを実行する関数を使用するときに、クエリを高速化し、フル コンテナー スキャンを回避できます。 インデックスを使用するフィルター述語をさらに追加して、これらのクエリを高速化できます。 フィルター句の順序は重要ではありません。 クエリ エンジンでは、どの述語がより選択的であるかが判断され、それに応じてクエリが実行されます。
複合インデックスを構成する方法については、複合インデックス作成ポリシーの例に関する記事を参照してください。
ベクトル インデックス
ベクトル インデックス作成では、VectorDistance システム関数を使用して、ベクトル検索の実行効率を向上させます。 ベクトル検索は、ベクトル インデックスを活用することで、待機時間を大幅に短縮し、スループットを高め、RU 消費を削減します。
ベクトル インデックスを構成する方法については、「ベクトル インデックス作成ポリシーの例」を参照してください。
ORDER BYベクトル検索クエリ:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)ベクトル検索クエリにおける類似性スコアのプロジェクション:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)類似性スコアの範囲フィルター。
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
重要
現在、ベクトル ポリシーとベクトル インデックスは、作成後に変更できません。 変更するには、新しいコレクションを作成してください。
インデックスの使用量
クエリ エンジンでクエリ フィルターを評価できる 5 つの方法を、最も効率的なものから非効率なものの順に以下に示します。
- インデックス シーク
- 正確なインデックス スキャン
- 拡張インデックス スキャン
- フル インデックス スキャン
- フル スキャン
プロパティ パスのインデックスを作成すると、クエリ エンジンによって可能な限り効率的にインデックスが自動的に使用されます。 新しいプロパティ パスのインデックス作成以外に、クエリでインデックスを使用する方法の最適化に関して構成する必要があるものは何もありません。 クエリの RU 料金は、インデックス使用の RU 料金と、項目読み込みの RU 料金を合わせたものです。
Azure Cosmos DB でのインデックスのさまざまな使用方法をまとめた表を次に示します。
| インデックス参照の種類 | 説明 | 一般的な例 | インデックス使用の RU 料金 | トランザクション データ ストアからの項目読み込みの RU 料金 |
|---|---|---|---|---|
| インデックス シーク | 必要なインデックス値のみの読み取りと、一致する項目のみのトランザクション データ ストアからの読み込み | 等値フィルター、IN | 等値フィルターごとの定数 | クエリ結果内の項目数に基づいて増加します |
| 正確なインデックス スキャン | 必要なインデックス値のバイナリ検索と、一致する項目のみのトランザクション データ ストアからの読み込み | 範囲の比較 (>、<、<=、>=)、StartsWith | インデックス シークと比較して、インデックス付けされたプロパティのカーディナリティの分だけ少し増えます | クエリ結果内の項目数に基づいて増加します |
| 拡張インデックス スキャン | インデックス値の最適化された検索 (ただし、バイナリ検索よりは非効率的) と、一致する項目のみのトランザクション データ ストアからの読み込み | StartsWith (大文字と小文字の区別なし)、StringEquals (大文字と小文字の区別なし) | インデックス付けされたプロパティのカーディナリティの分だけ少し増えます | クエリ結果内の項目数に基づいて増加します |
| フル インデックス スキャン | インデックス値の個別のセットの読み取りと、一致する項目のみのトランザクション データ ストアからの読み込み | Contains、EndsWith、RegexMatch、LIKE | インデックス付けされたプロパティのカーディナリティに基づいて、直線的に増加します | クエリ結果内の項目数に基づいて増加します |
| フル スキャン | トランザクション データ ストアからすべての項目を読み込みます | Upper、Lower | なし | コンテナー内の項目数に基づいて増加します |
クエリを作成するときは、インデックスを可能な限り効率的に使用するフィルター述語を使用する必要があります。 たとえば、ユース ケースに StartsWith または Contains のいずれかを使用できる場合は、StartsWith を選択する必要があります。そうすれば、フル インデックス スキャンではなく、正確なインデックス スキャンが実行されます。
インデックスの使用の詳細
このセクションでは、クエリでのインデックスの使用方法についてさらに詳しく説明します。 Azure Cosmos DB を使い始めるに当たって、この詳細度で学習する必要はありませんが、学習意欲のあるユーザー向けに詳細に説明してあります。 このドキュメントで前に共有した項目の例を参照します。
項目の例:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB では、逆インデックスが使用されます。 インデックスは、各 JSON パスを、その値が含まれる項目のセットにマップすることによって機能します。 項目 ID のマッピングは、コンテナーのさまざまなインデックス ページで表されます。 次に示すのは、2 つの項目例が含まれるコンテナーの逆インデックスのサンプルの図です。
| パス | 値 | 項目 ID の一覧 |
|---|---|---|
| /locations/0/country | ドイツ | 1 |
| /locations/0/country | アイルランド | 2 |
| /locations/0/city | ベルリン | 1 |
| /locations/0/city | ダブリン | 2 |
| /locations/1/country | フランス | 1 |
| /locations/1/city | Paris | 1 |
| /headquarters/country | ベルギー | 1、2 |
| /headquarters/employees | 200 | 2 |
| /headquarters/employees | 250 | 1 |
逆インデックスには、2 つの重要な属性があります。
- 特定のパスでは、値は昇順に並べ替えられます。 そのため、クエリ エンジンでインデックスから簡単に
ORDER BYを提供できます。 - 特定のパスについて、クエリ エンジンで可能な値の個別のセットをスキャンして、結果が存在するインデックス ページを識別できます。
クエリ エンジンでは、4 つの方法で逆インデックスを利用できます。
インデックス シーク
次のクエリがあるとします。
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
クエリの述語 (場所に国やリージョンとして "France" が含まれている項目のフィルター処理) は、この図に強調表示されているパスと一致します。
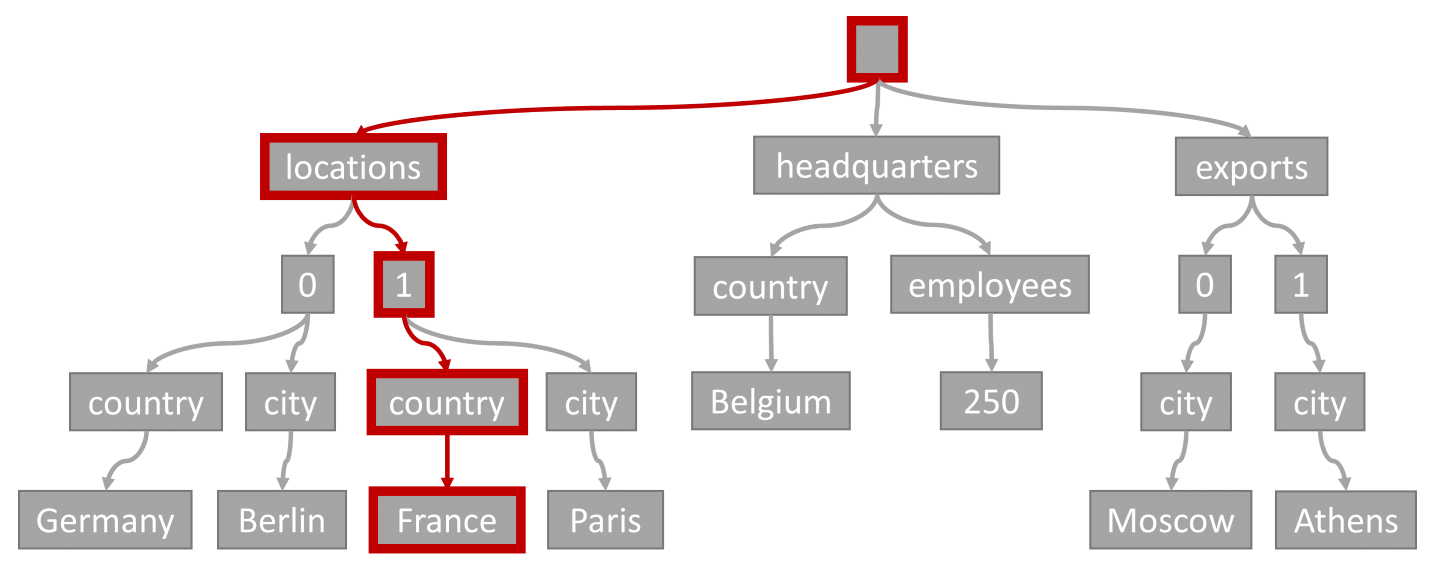
このクエリには等値フィルターがあるため、このツリーを走査した後、クエリ結果を含むインデックス ページをすばやく特定できます。 この場合、クエリ エンジンにより、項目 1 を含むインデックス ページが読み取られます。 インデックス シークは、インデックスを使用する最も効率的な方法です。 インデックス シークを使用すると、必要なインデックス ページだけが読み取られて、クエリ結果内の項目だけが読み込まれます。 そのため、インデックス検索の時間と、インデックス検索による RU 料金は、合計データ量に関係なく、非常に少なくなります。
正確なインデックス スキャン
次のクエリがあるとします。
SELECT *
FROM company
WHERE company.headquarters.employees > 200
クエリ述語 (従業員数が 200 を超える項目でのフィルター) は、headquarters/employees パスの正確なインデックス スキャンによって評価できます。 正確なインデックス スキャンを実行すると、クエリ エンジンによって最初に可能な値の個別のセットのバイナリ検索が実行され、headquarters/employees パスに対する値 200 の場所が検索されます。 各パスの値は昇順に並べ替えられているため、クエリ エンジンによるバイナリ検索は簡単に実行できます。 クエリ エンジンで値 200 が検出された後、残りのすべてのインデックス ページの読み取りが開始されます (昇順の方向)。
バイナリ検索を行うことにより、クエリ エンジンで不要なインデックス ページをスキャンしなくて済むため、正確なインデックス スキャンの待機時間と RU 料金は、インデックス シーク操作と同程度になる傾向があります。
拡張インデックス スキャン
次のクエリがあるとします。
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
クエリ述語 (大文字と小文字が区別されない "United" で始まる場所に本社がある項目のフィルター処理) は、headquarters/country パスの拡張インデックス スキャンを使用して評価できます。 拡張インデックス スキャンを実行する操作が備える最適化によって、すべてのインデックス ページをスキャンする必要はありませんが、正確なインデックス スキャンのバイナリ検索よりはコストが多少高くなります。
たとえば、大文字と小文字の区別なしで StartsWith を評価する場合、クエリ エンジンにより、大文字と小文字の値の考えられるさまざまな組み合わせで、インデックスがチェックされます。 この最適化により、クエリ エンジンでインデックス ページの大部分を読み取らずに済むようになります。 すべてのインデックス ページの読み取りを避けるために使用できる最適化は、システム関数によって異なるため、これらは拡張インデックス スキャンとして広く分類されています。
フル インデックス スキャン
次のクエリがあるとします。
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
クエリ述語 ("United" が含まれる場所に本社がある項目のフィルター処理) は、headquarters/country パスのインデックス スキャンを使用して評価できます。 正確なインデックス スキャンとは異なり、フル インデックス スキャンでは、常に、可能な値の個別のセットがスキャンされて、結果が存在するインデックス ページが特定されます。 この場合、Contains がインデックスで実行されます。 インデックス スキャンでのインデックス検索の時間と RU 料金は、パスのカーディナリティが増えるにつれて増加します。 つまり、クエリ エンジンでスキャンする必要がある、個別の可能な値が増えるにつれて、フル インデックス スキャンの実行に伴う待機時間と RU 料金が高くなります。
たとえば、town と country という 2 つのプロパティで考えてみましょう。 town のカーディナリティは 5,000 で、country のカーディナリティは 200 です。 次の 2 つのクエリ例には、town プロパティに対してフル インデックス スキャンを行う Contains システム関数が含まれています。 1 番目のクエリの方が 2 番目のクエリより多くの RU が使用されます。これは、town のカーディナリティの方が country より高いためです。
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
フル スキャン
場合によっては、クエリ エンジンによりインデックスを使用してクエリ フィルターを評価できないことがあります。 この場合は、クエリ エンジンでクエリ フィルターを評価するために、トランザクション ストアからすべての項目を読み込む必要があります。 フル スキャンではインデックスは使用されず、RU 料金は総データ サイズに比例して増加します。 幸運なことに、フル スキャンを必要とする操作はめったにありません。
ベクトル インデックスが定義されていないベクトル検索クエリ
ベクトル インデックス ポリシーを定義せず、ORDER BY 句で VectorDistance システム関数を使用すると、フル スキャンが実行され、ベクトル インデックス ポリシーを定義した場合よりも RU 料金が高くなります。 同様に、ブルート フォース ブール値を true に設定して VectorDistance を使用し、ベクトル パスに flat インデックスが定義されていない場合は、フル スキャンが実行されます。
複雑なフィルター式を使用するクエリ
前の例では、単純なフィルター式を使用するクエリ (たとえば、1 つの等値フィルターまたは範囲フィルターだけを含むクエリ) のみを検討しました。 実際には、ほとんどのクエリでさらに複雑なフィルター式が使用されています。
次のクエリがあるとします。
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
このクエリを実行するには、クエリ エンジンで、headquarters/employees に対するインデックス シークと、headquarters/country に対するフル インデックス スキャンを行う必要があります。 クエリ エンジンには内部ヒューリスティックがあり、クエリ フィルター式を可能な限り効率的に評価するために使用されます。 この場合は、クエリ エンジンによって、インデックス シークを最初に実行することにより、不要なインデックス ページを読み取る必要がなくなります。 たとえば、等値フィルターと一致するのが 50 項目のみの場合、クエリ エンジンで Contains を評価する必要があるのは、それら 50 項目が含まれるインデックス ページだけです。 コンテナー全体のフル インデックス スキャンは必要ありません。
スカラー集計関数でのインデックスの使用
集計関数を使用するクエリでインデックスを使用するには、そのインデックスのみに依存している必要があります。
場合によっては、インデックスで擬陽性が返されることがあります。 たとえば、インデックスで Contains を評価するとき、インデックス内の一致の数がクエリ結果の数を超える場合があります。 クエリ エンジンにより、すべてのインデックス一致が読み込まれ、読み込まれた項目に対してフィルターが評価されて、正しい結果だけが返されます。
ほとんどのクエリでは、擬陽性のインデックス一致を読み込んでも、インデックスの使用に大きな影響はありません。
たとえば、次のクエリを考えてみましょう。
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Contains システム関数によって擬陽性の一致がいくつか返される可能性があるため、読み込まれた各項目がフィルター式と一致するかどうかをクエリ エンジンで検証する必要があります。 この例では、クエリ エンジンで余分に読み込む必要があるのは数項目だけなので、インデックスの使用と RU 料金に対する影響は最小限に抑えられます。
ただし、集計関数を使用するクエリでインデックスを使用するには、そのインデックスのみに依存している必要があります。 たとえば、次のような Count 集計を含むクエリを考えてみます。
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
最初の例と同様に、Contains システム関数からは、擬陽性の一致が返されることがあります。 ただし、SELECT * クエリとは異なり、Count クエリでは、読み込まれた項目のフィルター式を評価して、すべてのインデックスの一致を検証することはできません。 Count クエリはインデックスに排他的に依存する必要があるため、フィルター式で擬陽性の一致が返される可能性がある場合は、クエリ エンジンによってフル スキャンが実行されます。
次の集計関数を使用するクエリは、インデックスだけに依存する必要があるため、一部のシステム関数を評価するにはフル スキャンが必要です。
次のステップ
以下の記事で、インデックス作成についての詳細を参照してください。