Azure Databricks を使用して Azure Cosmos DB for Apache Cassandra アカウントにデータを移行する
適用対象: ![]() Cassandra
Cassandra
Azure Cosmos DB の Cassandra 用 API は、いくつかの理由から、Apache Cassandra 上で実行されているエンタープライズ ワークロードに適した選択肢になっています。
管理と監視のオーバーヘッドなし: OS、JVM、および YAML ファイルやそれらの相互作用の設定を管理したり監視したりする際のオーバーヘッドが解消されます。
大幅なコスト削減: Azure Cosmos DB によってコストを節約できます。これには、VM、帯域幅、適用されるすべてのライセンスのコストが含まれます。 データセンター、サーバー、SSD ストレージ、ネットワーク、電気のコストを管理する必要がありません。
既存のコードとツールを使用可能: Azure Cosmos DB は、既存の Cassandra SDK およびツールとの間にワイヤ プロトコルレベルの互換性があります。 この互換性により、Azure Cosmos DB for Apache Cassandra を少し変更するだけで、既存のコードベースを使用できることが保証されます。
データベースのワークロードをプラットフォーム間で移行するには、多数の方法があります。 Azure Databricks は、Apache Spark 用の PaaS (サービスとしてのプラットフォーム) オファリングです。これにより、大規模なオフライン移行を実行できます。 この記事では、Azure Databricks を使用して、ネイティブ Apache Cassandra キースペースおよびテーブルから Azure Cosmos DB for Apache Cassandra にデータを移行するために必要な手順について説明します。
前提条件
互換性を確保するために Azure Cosmos DB for Apache Cassandra でサポートされる機能を確認する。
ターゲット Azure Cosmos DB for Apache Cassandra アカウントに、空のキースペースとテーブルを既に作成していることを確認する。
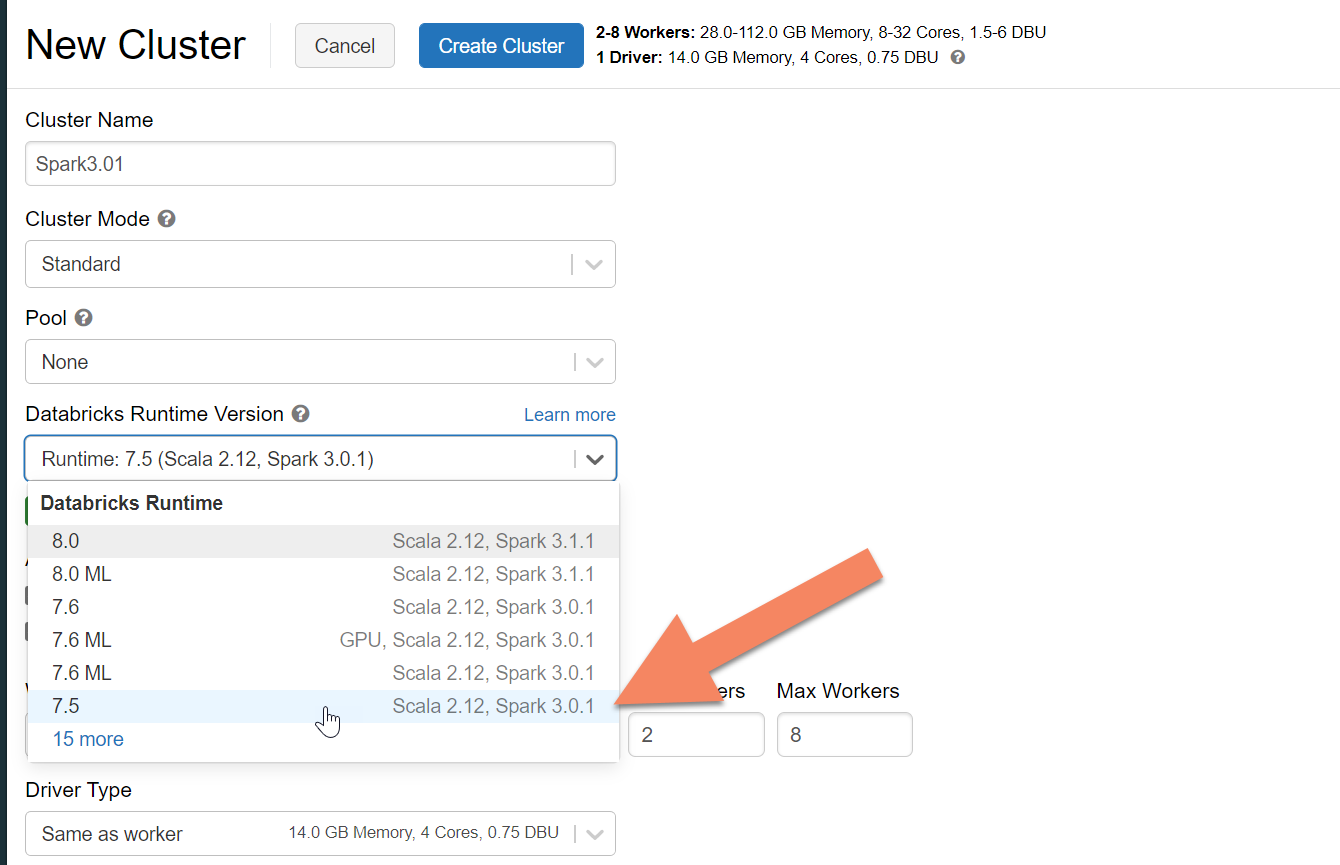
Azure Databricks クラスターのプロビジョニング
手順に従って、Azure Databricks クラスターをプロビジョニングできます。 Spark 3.0 をサポートする Databricks ランタイム バージョン 7.5 を選択することをお勧めします。
依存関係を追加する
Apache Spark Cassandra コネクタ ライブラリをクラスターに追加して、ネイティブと Azure Cosmos DB Cassandra 両方のエンドポイントに接続する必要があります。 自分のクラスターで、 [ライブラリ]>[新規インストール]>[Maven] の順に選択し、Maven 座標に com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 を追加します。

[インストール] を選択し、インストールが完了したらクラスターを再起動します。
Note
Cassandra コネクタ ライブラリがインストールされたら、必ず Databricks クラスターを再起動してください。
警告
この記事で示すサンプルは、Spark バージョン3.0.1と対応するCassandra Spark Connector com.datastax.spark:sark-cassandra-connector-assembly_2.12:3.0.0でテストされています。 それより後のバージョンの Spark や Cassandra コネクタは、予想通りに機能しない場合があります。
移行用の Scala ノートブックを作成する
Databricks で Scala ノートブックを作成します。 ソースとターゲットの Cassandra 構成を、対応する資格情報、ソースとターゲットのキースペースおよびテーブルで置き換えます。 次に、下のコードを実行します。
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Note
レート制限を回避できるように調整するうえで、spark.cassandra.output.batch.size.rows および spark.cassandra.output.concurrent.writes の値と Spark クラスター内のワーカーの数は重要な構成です。 レート制限は、Azure Cosmos DB に対する要求が、プロビジョニングされているスループットまたは要求ユニット数 (RU) を超えると、発生します。 Spark クラスター内の実行プログラム数、およびターゲット テーブルに書き込まれる各レコードのサイズ (および RU のコスト) に応じて、これらの設定の調整が必要になることがあります。
トラブルシューティング
レート制限 (429 エラー)
設定を最小値まで減らした場合でも、429 エラー コードまたは "要求レートが大きい" というエラー テキストが表示されることがあります。 次のシナリオでは、レート制限が発生する可能性があります。
テーブルに割り当てられたスループットが 6,000 要求ユニット未満である。 Spark では、最小設定でも約 6,000 要求ユニット以上のレートで書き込むことができます。 共有スループットがあるキースペースでテーブルをプロビジョニングした場合、実行時にこのテーブルで使用できる RU が 6,000 未満である可能性があります。
移行を実行する際に、移行先のテーブルでは少なくとも 6,000 RU を使用できることを確認します。 必要に応じて、そのテーブルには専用の要求ユニットを割り当てます。
大規模なデータ ボリュームでの過度のデータ スキュー。 特定のテーブルに移行するデータが大量にあるが、大きいデータ スキューがある場合 (つまり、同じパーティション キー値に対して大量のレコードが書き込まれている場合) は、テーブルに複数の要求ユニットがプロビジョニングされていても、レート制限が発生する可能性があります。 要求ユニットが物理パーティション間で均等に分割され、大量のデータ スキューによって 1 つのパーティションに対して要求のボトルネックが発生するおそれがあります。
このシナリオでは、Spark の最小スループット設定を下げて、移行の実行速度を強制的に低下させます。 このシナリオは、アクセスの頻度が低く、スキューが大きくなる可能性がある参照または制御テーブルを移行する場合によく見られます。 ただし、その他の種類のテーブルに大きなスキューが存在する場合は、データ モデルを確認して、安定状態の操作中にワークロードのホット パーティションの問題を回避することをお勧めします。