データ品質
データ品質は、クラウド規模の分析の管理機能です。 データ品質は、データ管理ランディング ゾーン内にあり、ガバナンスの中核となる部分です。
データ品質に関する考慮事項
データ品質は、データ製品を作成および使用するすべてのユーザーの責任です。 作成者はグローバル ルールとドメイン ルールに従う必要があり、使用者はフィードバック ループを介して所有データ ドメインにデータの不整合を報告する必要があります。
データ品質は役員会に提供されるすべてのデータに影響するため、組織の最上部から開始する必要があります。 役員会は、提供されるデータの品質に関して見識を持っている必要があります。
それでも、プロアクティブであるには、処理を必要とする膨大なデータをクリーニングできるデータ品質の専門家が必要です。 この作業を中央チームに押し付けることを避け、特定のデータ ナレッジを使用し、データ ドメインをターゲットにしてデータをクレンジングします。
データ品質メトリック
データ品質メトリックは、データ製品の品質を評価し、向上させる点で鍵となる要素です。 グローバル レベルとドメイン レベルで、品質メトリックを決定する必要があります。 少なくとも、次のメトリックをお勧めします。
| メトリック | メトリックの定義 |
|---|---|
| 完全度 = null 値以外 + 空白以外の合計 (%) | データの可用性、空ではないデータセット内のフィールド、および変更された既定値を測定します。 たとえば、あるレコードに出生データとして 01/01/1900 が含まれている場合、そのフィールドは設定されていない可能性が高くなります。 |
| 一意性 = 重複しない値の割合 (%) | テーブル内の行数と比較して、特定の列の個別の値を測定します。 たとえば、5 行のテーブルに 4 つの異なる色の値 (赤、青、黄、緑) がある場合、そのフィールドは 80% (または 4/5) 一意です。 |
| 整合性 = パターンを持つデータの割合 (%) | 特定の列内で、想定されるデータ型または形式への準拠を測定します。 たとえば、書式設定されたメール アドレスを含む電子メール フィールドや、数値を含む名前フィールドなどです。 |
| 有効性 = 参照一致の割合 (%) | ドメイン参照セットに一致する成功したデータを測定します。 たとえば、トランザクション レコード システムの "国/地域" フィールド (分類値に準拠) では、"US of A" という値は無効です。 |
| 正確性 = 変更されていない値の割合 (%) | 複数のシステム間で目的の値の正常な再現を測定します。 たとえば、ある請求書の明細に元の注文と異なる SKU と拡張価格が記されている場合、その請求書明細項目は不正確になります。 |
| リンケージ = 適切に統合されたデータの割合 (%) | 別のシステムのコンパニオン参照の詳細への正常な関連付けを測定します。 たとえば、ある請求書の明細に正しくない SKU と製品説明が記されている場合、その請求書明細項目はリンク可能ではありません。 |
データ プロファイル
データ プロファイルは、登録されているデータ カタログ内のデータ製品を分析し、そのデータに関する統計と情報を収集します。 時間の経過に伴ってデータ品質に関する概要ビューと傾向ビューを提供するには、このデータをそのデータ製品に対してメタデータ リポジトリに格納します。
データ プロファイルは、データ製品に関する次のような質問にユーザーが答えるのに役立ちます。
- ビジネス上の問題解決に利用できるか。
- データが特定の標準やパターンに従っているか。
- データ ソースの不規則性。
- データをアプリケーションに統合するうえでどのような課題が考えられるか。
ユーザーは、データ マーケットプレース内のレポート ダッシュボードを使用することにより、データ製品のプロファイルを表示できます。
レポートできる項目には次のものが含まれます。
- 完全性: 空白や null 値ではないデータの割合を示します
- 一意性: 重複していないデータの割合を示します
- 整合性: データ整合性が維持されるデータを示します
データ品質に関する推奨事項
データ品質を実装するには、次のようにして人的能力とコンピューティング能力の両方を使用する必要があります。
アルゴリズム、ルール、データ プロファイル、メトリックを含むソリューションを使用する。
コンピューティング レイヤーを通過するエラーの数が多く、アルゴリズムをトレーニングすることが必要になる場合に介入できるドメイン エキスパートを活用する。
早期に検証する。 従来のソリューションでは、データの抽出、変換、読み込みの後にデータ品質チェックが適用されます。 この時点で、そのデータ製品は既に消費されており、エラーがダウンストリームのデータ製品で表面化していました。 そうする代わりに、データがソースから取り込まれるときに、ソースに近い、ダウンストリームのコンシューマーがそのデータ製品を使用する前の段階にデータ品質チェックを実装します。 データ レイクからのバッチ取り込みがある場合は、データを未加工からエンリッチに移動するときにこれらのチェックを実行します。
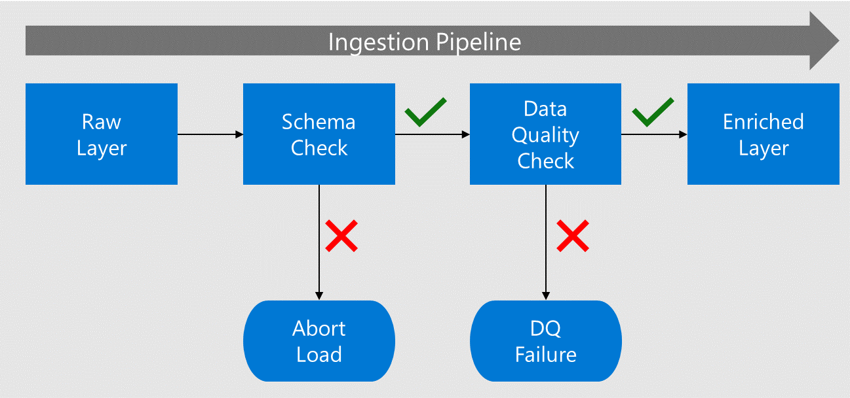
データがエンリッチ層に移動される前に、そのスキーマと列がデータ カタログに登録されているメタデータと照合されます。
データにエラーが含まれている場合、読み込みは停止され、データ アプリケーション チームに失敗が通知されます。
スキーマと列のチェックに合格した場合、データは適合したデータ型でエンリッチ層に読み込まれます。
エンリッチ層に移動する前に、データ品質プロセスによって、アルゴリズムとルールに対するコンプライアンスが確認されます。

ヒント
グローバル レベルとドメイン レベルの両方でデータ品質ルールを定義します。 そうすることにより、企業は作成されたすべてのデータ製品の標準を定義でき、データ ドメインはそのドメインに関連する追加のルールを作成できるようになります。
データ品質ソリューション
信頼性の高い AI 主導の分析情報と意思決定に不可欠なデータ品質を評価および管理するためのソリューションとして、"Microsoft Purview データ品質" の検討をお勧めします。 次の情報が含まれます。
- ノーコード/ローコードのルール: すぐに使用できる AI 生成のルールを使用してデータ品質を評価します。
- AI を活用したデータ プロファイリング: プロファイリング用の列を推奨し、人による介入による改良を可能にします。
- データ品質スコアリング: データ資産、データ製品、ガバナンス ドメインのスコアを提供します。
- データ品質アラート: データ所有者に品質の問題を通知します。
詳細については、「データ品質とは」を参照してください。
組織がデータを操作するために Azure Databricks の実装を決定した場合は、このソリューションが提供するデータの品質管理、テスト、監視、および適用を評価する必要があります。 期待値を使用すると、関連する子データ製品に影響する前に、インジェスト時のデータ品質の問題を把握できます。 詳細については、「データ品質基準を確立する」と、Databricks によるデータ品質管理に関するページを参照してください。
データ品質ソリューションについては、パートナー、オープンソース、カスタム オプションから選択することもできます。
データ品質の概要
データ品質の修正は、ビジネスに重大な結果をもたらす場合があります。 データ品質の修正により、部署がデータ製品を異なる方法で解釈するようになる場合があります。 この解釈の誤りは、データ品質の低いデータ製品に基づいて決定を行う企業にとって高くつく場合があります。 属性が不足した状態のデータ製品を修正することは、コストのかかる作業となり、期間の数からデータを完全に再度読み込むことが必要になるおそれがあります。
データ品質を早期に検証し、データ品質の低さにプロアクティブに対処するためのプロセスを導入します。 たとえば、ある程度の完全性を達成するまで、データ製品を運用環境にリリースできないようにします。
ツールは自由な選択肢として使用できますが、期待値 (ルール)、データ メトリック、プロファイリングに加えて、グローバルベースの期待値とドメインベースの期待値を実装できるように期待値をセキュリティで保護する機能がそのツールに含まれるようにする必要があります。