セルフサービス データ プラットフォームの設計に関する考慮事項
データ メッシュは、データ アーキテクチャの設計と開発に対する魅力的な新しいアプローチです。 従来のデータ アーキテクチャとは異なり、データ メッシュは、データ製品の作成に重点を置く機能データ ドメインと、技術的な機能に重点を置くプラットフォーム チームとの間で責任を分離します。 この責任の分離は、プラットフォームに反映される必要があります。 ドメインに依存しない機能を提供することと、ドメイン チームが組織全体でデータをモデル化、処理、配布できるようにすることのバランスを取る必要があります。
適切なレベルのドメイン粒度とルールを選択し、プラットフォームを使用して分離するのは、簡単なことではありません。 この記事には、詳細なガイダンスを提供するいくつかのシナリオが含まれています。
クラウド規模の分析
Azure でデータ メッシュを構築する場合は、クラウド規模の分析を採用することをお勧めします。 このフレームワークはデプロイ可能な参照アーキテクチャであり、オープンソースのテンプレートとベスト プラクティスが付属しています。 クラウド規模の分析アーキテクチャには、すべてのデプロイの選択肢の基本となる 2 つの主要な構成要素があります。
- データ管理ランディング ゾーン: データ アーキテクチャの基盤。 これには、データ カタログ、データ系列、API カタログ、マスター データ管理など、データ管理に関するすべての重要な機能が含まれています。
- データ ランディング ゾーン: 分析および AI ソリューションをホストするサブスクリプション。 これには、分析プラットフォームをホストするための主要な機能が含まれています。
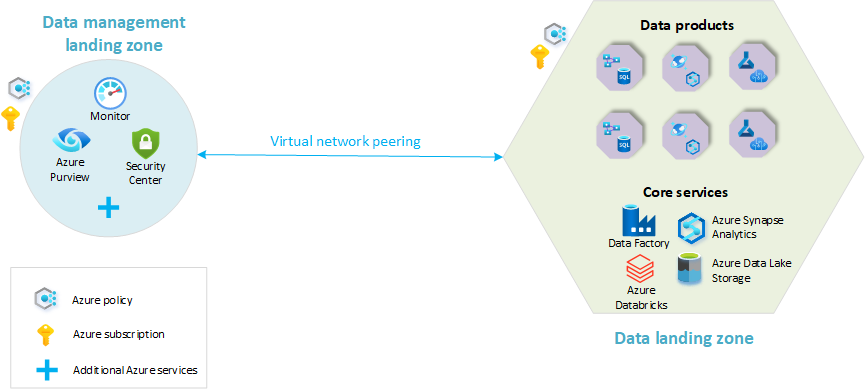
次の図は、クラウド規模の分析プラットフォームの概要を示しています。データ管理ランディング ゾーンと 1 つのデータ ランディング ゾーンがあります。 図で表されているのは Azure サービスの一部です。 アーキテクチャ内のリソース編成の主要な概念を強調するために、簡略化されています。
クラウドベースの分析フレームワークでは、プロビジョニングする必要があるデータ アーキテクチャの正確な種類について明示していません。 これは、(エンタープライズ) データ ウェアハウス、データ レイク、データ レイク ハウス、データ メッシュなど、多くの一般的なクラウド規模の分析ソリューションに使用できます。 この記事のすべてのソリューション例では、データ メッシュ アーキテクチャを使用します。
すべてのアーキテクチャがデータ メッシュの原則 (ドメイン所有権、製品としてのデータ、セルフサービス データ プラットフォーム、フェデレーション コンピューティング ガバナンス) に準拠していることを理解してください。 すべての異なるパスが、データ メッシュにつながる可能性があります。 正しい答えが 1 つしかないわけではなく、間違った答えがあるわけでもありません。 組織のニーズに合わせて適切なトレードオフを行う必要があります。
単一のデータ ランディング ゾーン
データ メッシュ アーキテクチャを構築するための最も単純なデプロイ パターンには、1 つのデータ管理ランディング ゾーンと 1 つのデータ ランディング ゾーンが含まれます。 このようなシナリオのデータ アーキテクチャは次のようになります。

このモデルでは、すべての機能データ ドメインが同じデータ ランディング ゾーンに存在します。 1 つのサブスクリプションには、標準のサービス セットが含まれています。 リソース グループは、さまざまなデータ ドメインとデータ製品を分離します。 Azure Data Lake Store、Azure Logic Apps、Azure Synapse Analytics などの標準データ サービスは、すべてのドメインに適用されます。
すべてのデータ ドメインは、データ メッシュの原則に従います。データはドメインの所有権に従い、データは製品のように扱われます。 プラットフォームは完全にセルフサービスですが、サービスのバリエーションは限られています。 すべてのドメインは、同じデータ管理原則に厳密に準拠している必要があります。
このデプロイ オプションは、データ メッシュを導入したいが過度に複雑化させたくない小規模な企業やグリーンフィールド プロジェクトに役立ちます。 このデプロイは、より複雑なものを構築する予定の組織の出発点になる場合もあります。 その場合は、後で複数のランディング ゾーンに拡張することを計画します。
ソース システムに合わせたランディング ゾーンとコンシューマーに合わせたランディング ゾーン
前のモデルでは、他のサブスクリプションやオンプレミス アプリケーションを考慮しませんでした。 ソース システムに合わせたランディング ゾーンを追加し、すべての受信データを管理することで、前のモデルを少し変更できます。 データのオンボードは困難なプロセスであるため、2 つのデータ ランディング ゾーンがあると便利です。 オンボーディングは、データを大規模に使用する場合の最も困難な部分の 1 つです。 また、オンボーディングの課題と統合の課題は異なるため、多くの場合、統合に対処するために追加のツールが必要になります。 これは、データの提供とデータの使用を区別するために役立ちます。

この図の左側のアーキテクチャでは、サービスは、CDC、API を取得するためのサービス、データセットを動的に構築するためのデータ レイク サービスなどのように、サービスがすべてのデータ オンボードを容易にします。 このプラットフォームのサービスは、オンプレミス、クラウド環境、または SaaS ベンダーからデータを取得できます。 この種類のプラットフォームは、基盤となる運用アプリケーションとの結合が多いため、通常はオーバーヘッドも大きくなります。 これは、データの使用状況とは異なる扱いにすることもできます。
図の右側にあるアーキテクチャでは、組織は消費を最適化し、データを価値に変えることに重点を置いたサービスを所有しています。 これらのサービスには、機械学習、レポートなどが含まれる可能性があります。
これらのアーキテクチャ ドメインは、データ メッシュのすべての原則に従います。 ドメインはデータの所有権を取得し、他のドメインにデータを直接配布できます。
ハブ、汎用、および特殊なデータ ランディング ゾーン
次のデプロイ オプションは、前述の設計を再度繰り返したものです。 このデプロイは、管理されたメッシュ トポロジに従います。データは中央ハブを介して分散され、データはドメインごとにパーティション分割され、論理的に分離され、統合されません。 このモデルのハブは、独自の (ドメインに依存しない) データ ランディング ゾーンを使用し、どのデータがどのドメインに分散されているかを監督する中央データ ガバナンス チームが所有している可能性があります。 ハブには、データのオンボードを容易にするサービスも含まれています。

新しいデータの消費、使用、分析、作成に標準サービスを必要とするドメインでは、汎用データ ランディング ゾーンを使用します。 この 1 つのサブスクリプションには、標準のサービス セットが含まれています。 また、ほとんどのデータ製品は既にハブに永続化されており、データの重複を増やす必要はないので、データの仮想化を適用します。
このデプロイでは、"specials" を使用できます。これは、ドメインを論理的にグループ化できない場合にプロビジョニングできる追加のランディング ゾーンです。 地域や法的な境界が適用される場合、またはドメイン固有の対照的な要件がある場合に必要になる場合があります。 また、海外活動は例外として、堅牢な全社的子会社ガバナンスが適用される状況でも必要になる場合があります。
組織で、どのデータがどのドメインによって分散され、使用されているかを制御する必要がある場合は、ハブのデプロイをお勧めします。 また、大規模なデータ コンシューマーに対する時間変動や非揮発性の懸念に対処する場合にも、選択肢となります。 データ製品の設計を厳密に標準化できるので、ドメインはタイム トラベルや再配信を実行できます。 このモデルは、金融業界では特に一般的です。
機能と地域に合わせたデータ ランディング ゾーン
複数のデータ ランディング ゾーンをプロビジョニングすると、データの作業と共有の一貫性と効率性に基づいて機能ドメインをグループ化する際に役立ちます。 すべてのデータ ランディング ゾーンは同じ監査と制御に従いますが、異なるデータ ランディング ゾーン間で設計を変更できる柔軟性を維持できます。

共有データ ランディング ゾーンに対して論理的にグループ化する機能データメインを決定します。 たとえば、地域の境界がある場合は、同じテンプレートを実装できます。 所有権、セキュリティ、または法的境界により、ドメインの分離が強制される場合もあります。 柔軟性、変化のペース、能力の分離や売却も考慮すべき重要な要素です。
詳細なガイダンスとベスト プラクティスについては、データ ドメインに関するページを参照してください。
異なるランディング ゾーンが単独で成立することはありません。 他のゾーンにホストされているデータ レイクに接続できます。 これにより、企業全体でドメインに対する共同作業を行うことができます。 また、ポリグロットな永続化を適用して、さまざまなデータ ストア テクノロジを混在させることもできます。 ポリグロットな永続化を使用すると、ドメインはデータを複製することなく、他のドメインから直接データを読み取ることができます。
複数のデータ ランディング ゾーンをデプロイする場合は、各データ ランディング ゾーンに管理オーバーヘッドが追加されることに注意してください。 すべてのデータ ランディング ゾーン間で VNet ピアリングを適用し、追加のプライベート エンドポイントを管理することなどが必要です。
データ アーキテクチャが大きい場合は、複数のデータ ランディング ゾーンをデプロイすることをお勧めします。 さまざまなドメインの一般的なニーズに対応するために、アーキテクチャにランディング ゾーンを追加できます。 これらの追加のランディング ゾーンは、仮想ネットワーク ピアリングを使用して、データ管理ランディング ゾーンおよび他のすべてのランディング ゾーンの両方に接続します。 ピアリングを使用すると、ランディング ゾーン間でデータセットとリソースを共有できます。 データを別々のゾーンに分割すると、Azure サブスクリプションとリソース全体にワークロードを分散させることができます。 この方法は、データ メッシュを有機的に実装するうえで役立ちます。
異なるデータ管理ゾーンを必要とする大規模企業
世界規模で事業を展開する大企業では、組織のさまざまな部署によってデータ管理要件が異なる場合があります。 この問題に対処するために、複数のデータ管理ゾーンとデータ ランディング ゾーンを一緒にデプロイできます。 次の図は、このタイプのアーキテクチャの例を示しています。

複数のデータ管理ランディング ゾーンを使用する場合は、オーバーヘッドと統合の複雑さを受け入れる必要があります。 たとえば、組織の (メタ) データを組織外のユーザーが見てはならない状況では、別のデータ管理ランディング ゾーンが意味を持つ場合があります。
まとめ
データ メッシュへの移行は、微妙な違い、トレードオフ、考慮事項を含む文化的な変化です。 クラウド規模の分析を使用して、ベスト プラクティスと実行可能リソースを取得できます。 この記事の参照アーキテクチャでは、実装を開始するための開始点を提供します。