文字起こしの表示と更新
この記事では、Azure AI Video Indexer Web サイトでトランスクリプト行を挿入または削除する方法について説明します。 また、単語レベルの情報を表示する方法も示します。
Azure AI Video Indexer Web サイトでトランスクリプト行を挿入または削除する
このセクションでは、Azure AI Video Indexer Web サイト にトランスクリプト行を挿入または削除する方法について説明します。
トランスクリプト タイムラインに新しい行を追加する
編集モードで、2 つのトランスクリプト行の間にマウス ポインターを合わせます。 トランスクリプト行の終了時刻と次のトランスクリプト行の開始との間に差が見つかります。ユーザーには、下の [add new transcription line] (新しいトランスクリプト行の追加) オプションが表示されます。
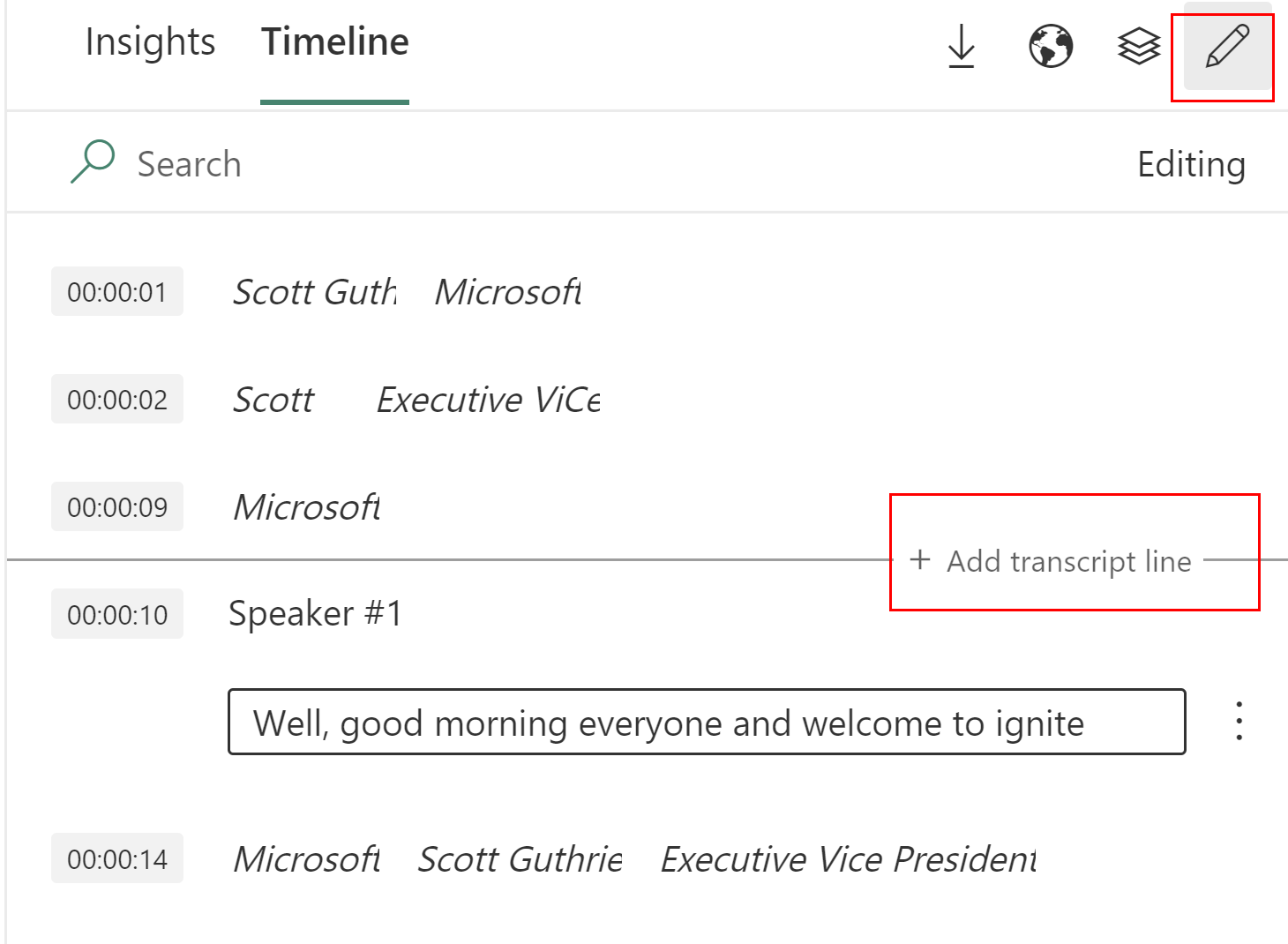
[add new transcription line] (新しいトランスクリプト行の追加) をクリックすると、新しいテキストと新しい行のタイムスタンプを追加するオプションが表示されます。 テキストを入力し、新しい行のタイム スタンプを選択して、[保存] を選択します。 既定のタイム スタンプは、前と次のトランスクリプト行の間の差です。
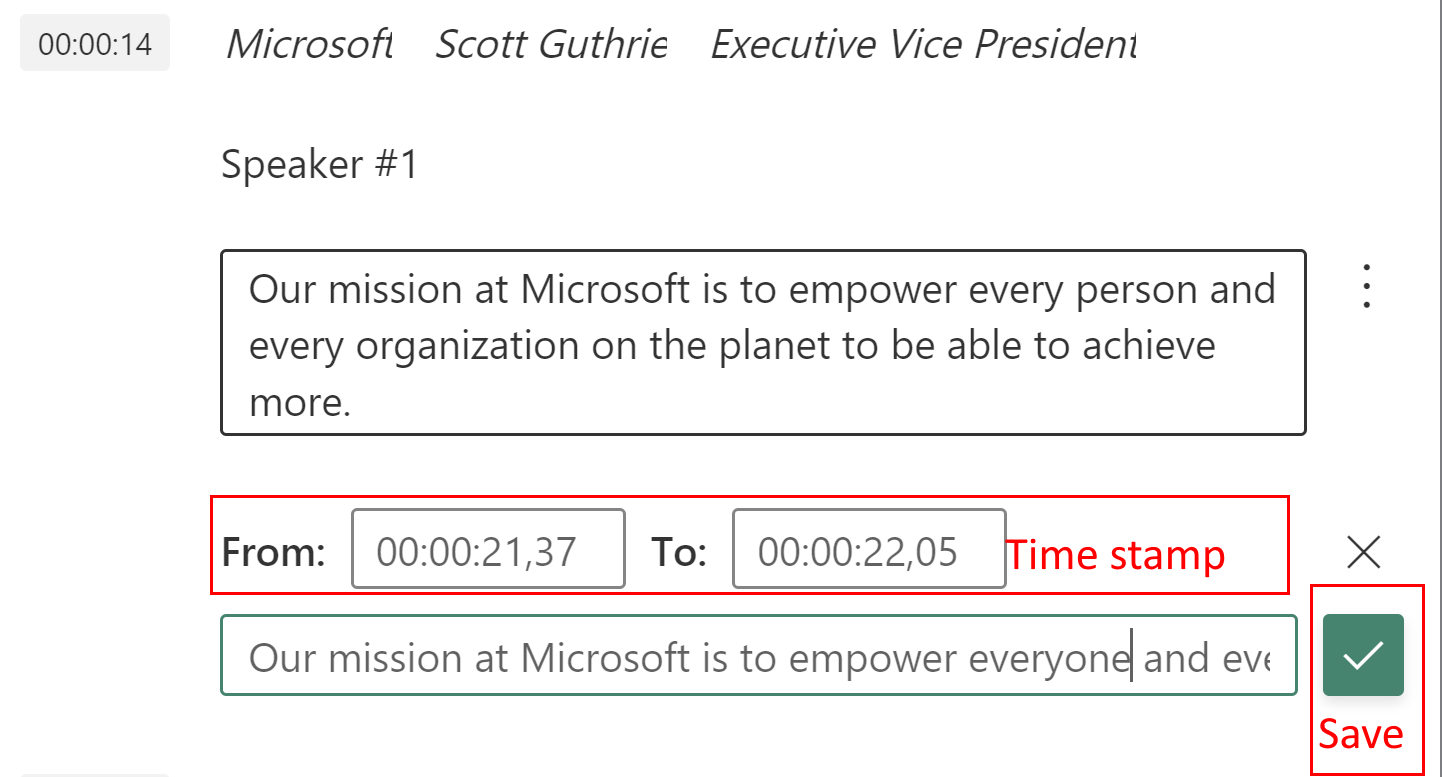
新しい行を追加するオプションが表示されない場合は、目的の場所に新しい行が収まるように、関連するトランスクリプト行の終了/開始時刻を調整できます。
トランスクリプト行で既存の行を選択し、3 つのドット アイコンをクリックし、[編集] を選択して、タイム スタンプを適宜変更します。
Note
新しい行は、[言語] の下で [コンテンツ モデルのカスタマイズ] の [トランスクリプトの編集から] の一部として表示されません。
API の使用中に、新しい行を追加するときに、フリー テキストを使用して [Speaker name] (話者の名前) を追加できます。 たとえば、Speaker 1 は Adam になります。
既存の行の編集
編集モードで、3 つのドット アイコンを選択します。 編集オプションが強化され、テキストだけでなく、ミリ秒の精度でタイム スタンプも含まれるようになりました。
行の削除
同じ 3 つのドット アイコンを使用して行を削除できるようになりました。
2 行を 1 として統合する
1 行として表示する必要があると考える 2 つの行を統合するには、次のようにします。
- 行番号 2 に移動し、[編集] を選択します。
- テキストをコピーします。
- 行を削除します。
- 1 行目に移動し、テキストを編集し、貼り付けて保存します。
単語レベルの文字起こし情報を調べる
このセクションでは、Azure AI Video Indexer によって識別された文と語句に基づいて、単語レベルの文字起こし情報を調べる方法を示します。 各語句は単語に分割され、各単語には次の情報が関連付けられています
| 名前 | Description | 例 |
|---|---|---|
| Word | 語句の単語。 | "thanks" |
| 信頼度 | Azure AI Video Indexer の単語が正しいことをどの程度確信しているか。 | 0.80127704 |
| オフセット | ビデオの先頭から単語の開始位置までの時間オフセット。 | PT0.86S |
| 長さ | 単語の期間。 | PT0.28S |
トランスクリプトを取得して表示する
- Azure AI Video Indexer の Web サイトにサインインします。
- ビデオを選択します。
- 右上隅にある下矢印を押し、[成果物 (ZIP)] を選択します。
- 成果物をダウンロードします。
- ダウンロードしたファイルを解凍します > 解凍したファイルがある場所を参照します > 検索して開きます
transcript.speechservices.json。 - json を書式設定して表示します。
RecognizedPhrases>NBest>Wordsを検索して、興味のある情報を見つけます。
"RecognizedPhrases": [
{
"RecognitionStatus": "Success",
"Channel": 0,
"Speaker": 1,
"Offset": "PT0.86S",
"Duration": "PT11.01S",
"OffsetInTicks": 8600000,
"DurationInTicks": 110100000,
"NBest": [
{
"Confidence": 0.82356554,
"Lexical": "thanks for joining ...",
"ITN": "thanks for joining ...",
"MaskedITN": "",
"Display": "Thanks for joining ...",
"Words": [
{
"Word": "thanks",
"Confidence": 0.80127704,
"Offset": "PT0.86S",
"Duration": "PT0.28S",
"OffsetInTicks": 8600000,
"DurationInTicks": 2800000
},
{
"Word": "for",
"Confidence": 0.93965703,
"Offset": "PT1.15S",
"Duration": "PT0.13S",
"OffsetInTicks": 11500000,
"DurationInTicks": 1300000
},
{
"Word": "joining",
"Confidence": 0.97060966,
"Offset": "PT1.29S",
"Duration": "PT0.31S",
"OffsetInTicks": 12900000,
"DurationInTicks": 3100000
},
{