チュートリアル: 可用性グループを手動で構成する - Azure VM 上の SQL Server
適用対象: ![]() Azure VM 上の SQL Server
Azure VM 上の SQL Server
ヒント
可用性グループをデプロイする方法は多数あります。 デプロイを簡略化し、Always On 可用性グループに対して Azure Load Balancer または分散ネットワーク名 (DNN) を不要にするには、同じ Azure 仮想ネットワーク内の複数のサブネットに SQL Server 仮想マシン (VM) を作成します。 可用性グループを 1 つのサブネットに既に作成している場合は、マルチサブネット環境に移行できます。
このチュートリアルでは、1 つのサブネット内の Azure VM 上に SQL Server の Always On 可用性グループを作成する方法を説明します。 チュートリアル全体で、2 つの SQL Server インスタンス上に、データベース レプリカを使用して可用性グループを作成します。
この記事では、可用性グループ環境を手動で構成します。 Azure portal、PowerShell または Azure CLI、または Azure クイックスタート テンプレートを使用して、手順を自動化することもできます。
推定所要時間: このチュートリアルは、前提条件が満たされてから完了するまでに約 30 分かかります。
前提条件
このチュートリアルでは、SQL Server Always On 可用性グループに関する基本的な知識があることを前提としています。 詳しくは、「Always On 可用性グループの概要 (SQL Server)」をご覧ください。
このチュートリアルの手順を始める前に、Azure 仮想マシンで Always On 可用性グループを作成するための前提条件を満たす必要があります。 これらの前提条件が既に満たされている場合は、「クラスターを作成する」に進むことができます。
次の表に、このチュートリアルを開始する前に満たす必要がある前提条件の概要を示します。
| 要件 | 説明 |
|---|---|
 2 つの SQL Server インスタンス 2 つの SQL Server インスタンス |
- Azure 可用性セット内 - 単一のドメイン内 - フェールオーバー クラスタリングがインストールされている |
| Windows Server |
クラスター監視用のファイル共有 |
| SQL Server サービス アカウント |
ドメイン アカウント |
| SQL Server エージェント サービス アカウント |
ドメイン アカウント |
| ファイアウォール ポートを開く |
- SQL Server: 1433 (既定のインスタンスの場合) - データベース ミラーリング エンドポイント:5022 または使用可能な任意のポート - 可用性グループのロード バランサー IP アドレスの正常性プローブ: 59999 または使用可能な任意のポート - クラスター コアのロードバランサー IP アドレスの正常性プローブ: 58888 または使用可能な任意のポート |
| フェールオーバー クラスタリング |
両方の SQL Server インスタンスに必要 |
| インストール ドメイン アカウント |
- 各 SQL Server インスタンスのローカル管理者 - 各 SQL Server インスタンスの sysadmin 固定サーバー ロールのメンバー |
| ネットワーク セキュリティ グループ (NSG) |
環境でネットワーク セキュリティ グループを使用している場合は、現在の構成で、ファイアウォールの構成に関する記事で説明されているポートを通じたネットワーク トラフィックが許可されていることを確認してください。 |
クラスターを作成する
最初のタスクは、SQL Server VM とミラーリング監視サーバーの両方を含む Windows Server フェールオーバー クラスターを作成することです。
リモート デスクトップ プロトコル (RDP) を使用して、最初の SQL Server VM に接続します。 SQL Server VM と監視サーバー両方で管理者であるドメイン アカウントを使用します。
ヒント
前提条件に従っていれば、CORP\Install という名前のアカウントが作成されています。 このアカウントを使います。
[サーバー マネージャー] ダッシュボードで、[ツール]、[フェールオーバー クラスター マネージャー] の順に選択します。
左側のペインで、[フェールオーバー クラスター マネージャー] を右クリックし、[クラスターの作成] を選択します。
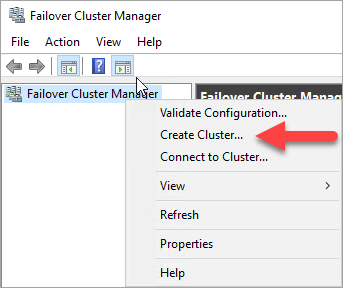
クラスターの作成ウィザードで次の表の設定を使用してページを進めて、1 ノードのクラスターを作成します。
ページ 設定 はじめに 既定値を使用します。 サーバーの選択 [サーバー名を入力してください] に最初の SQL Server VM の名前を入力し、[追加] を選択します。 検証の警告 [いいえ、このクラスターに Microsoft のサポートは必要ありませんので、検証テストを実行しません。[次へ] を選択して、クラスターの作成を続行します。] を選択します。 クラスター管理用のアクセス ポイント [クラスター名] にクラスター名 (例: SQLAGCluster1) を入力します。 確認 記憶域スペースを使用している場合を除き、既定値を使用します。
Windows Server フェールオーバー クラスターの IP アドレスを設定する
注意
Windows Server 2019 では、クラスターはクラスター ネットワーク名の値ではなく、分散サーバー名の値を作成します。 Windows Server 2019 を使用している場合は、このチュートリアルでクラスターのコア名を参照するすべての手順をスキップしてください。 クラスター ネットワーク名は、PowerShell を使用して作成できます。 詳細については、ブログ記事「フェールオーバー クラスター: クラスター ネットワーク オブジェクト」を参照してください。
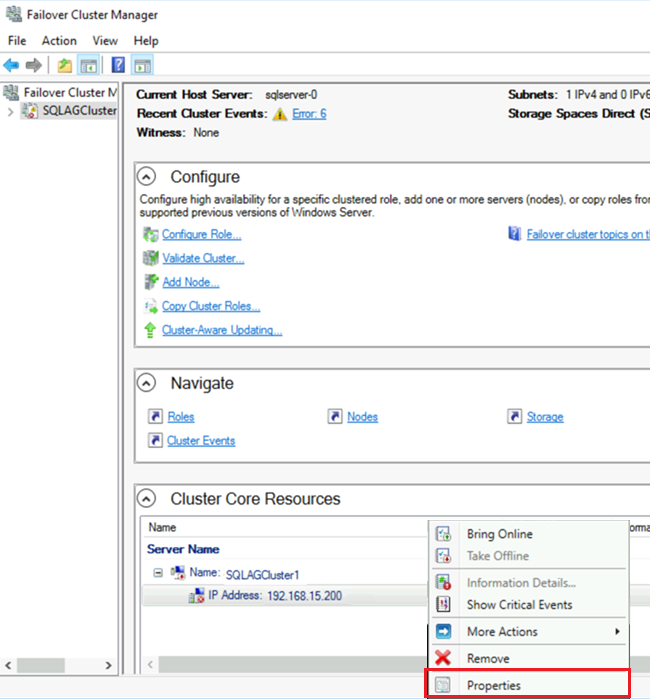
フェールオーバー クラスター マネージャーで、 [クラスター コア リソース] まで下にスクロールして、クラスターの詳細を展開します。 [名前] と [IP アドレス] の両方のリソースが [失敗] 状態にあることが表示されます。
クラスターにコンピューター自体と同じ IP アドレスが割り当てられているため、IP アドレス リソースをオンラインにすることはできません。 これは重複するアドレスです。
失敗した IP アドレス リソースを右クリックし、 [プロパティ] を選択します。
[静的 IP アドレス] を選択し、 仮想マシンと同じサブネットの使用可能なアドレスを指定します。
[クラスター コア リソース] セクションで、クラスター名を右クリックして、[オンラインにする] を選択します。 両方のリソースがオンラインになるまで待ちます。
クラスター名リソースがオンラインになると、新しい Active Directory コンピューター アカウントでドメイン コントローラー サーバーが更新されます。 この Active Directory アカウントは、後で可用性グループのクラスター化サービスを実行するために使用されます。
他の SQL Server インスタンスをクラスターに追加する
ブラウザー ツリーで、クラスターを右クリックし、 [ノードの追加] を選択します。
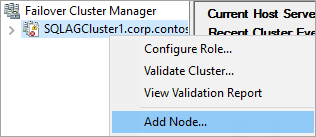
ノードの追加ウィザードで、 [次へ] を選択します。
[サーバーの選択] ページで、2 番目の SQL Server VM を追加します。 [サーバー名を入力してください] に VM 名前を入力し、[追加]>[次へ]の順に選択します。
[検証の警告] ページで、[いいえ] を選択します (運用シナリオでは、検証テストを実行する必要があります)。次に、[次へ] を選択します。
記憶域スペースを使用している場合は、[確認] ページで、[使用可能な記憶域をすべてクラスターに追加する] チェックボックスをオフにします。
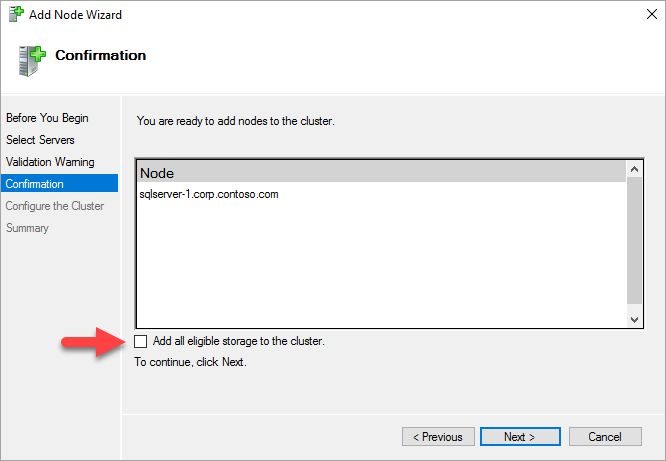
警告
[使用可能な記憶域をすべてクラスターに追加する] をオフにしないと、クラスタリング プロセスの実行中、Windows によって仮想ディスクがデタッチされます。 その結果、記憶域をクラスターから削除し、PowerShell を使って再アタッチするまで、仮想ディスクはディスク マネージャーやオブジェクト エクスプローラーに表示されなくなります。
[次へ] を選択します。
[完了] を選択します。
フェールオーバー クラスター マネージャーに、クラスターに新しいノードがあることが示され、そのノードが [ノード] コンテナーの一覧に表示されます。
リモート デスクトップ セッションからサインアウトします。
クラスター クォーラムのファイル共有を追加する
この例では、Windows クラスターはファイル共有を使ってクラスター クォーラムを作成します。 このチュートリアルでは、NodeAndFileShareMajority クォーラムを使用します。 詳細については、「クォーラムを構成および管理する」を参照してください。
リモート デスクトップ セッションを使用して、ファイル共有のミラーリング監視サーバー VM に接続します。
サーバー マネージャーで、[ツール] を選択します。 [コンピューターの管理] を開きます。
[共有フォルダー] を選択します。
[共有] を右クリックし、[新しい共有] を選択します。
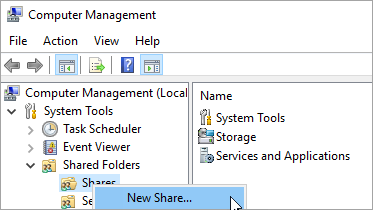
共有フォルダーの作成ウィザードを使用して共有を作成します。
[フォルダー パス] ページで、[参照] を選択します。 共有フォルダーのパスを見つけるか作成し、[次へ] を選択します。
[名前、説明および設定] ページで、共有名とパスを確認します。 [次へ] を選択します。
[共有フォルダーのアクセス許可] ページで、[アクセス許可のカスタマイズ] を設定します。 [カスタム] を選択します。
[アクセス許可のカスタマイズ] ダイアログで、[追加] を選択します。
クラスターの作成に使用するアカウントがフル コントロールを持っていることを確認します。
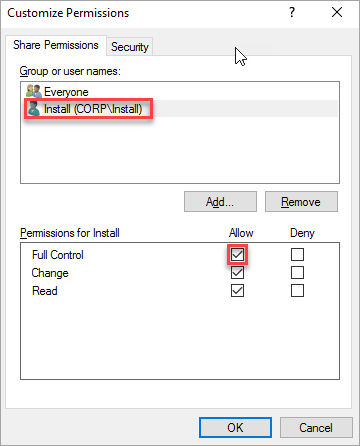
[OK] を選択します。
[共有フォルダーのアクセス許可] ページで、[完了] を選択します。 もう一度 [完了] を選択します。
サーバーからサインアウトします。
クラスター クォーラムを構成する
注意
可用性グループの構成によっては、Windows Server フェールオーバー クラスターに参加しているノードのクォーラム投票を変更することが必要な場合があります。 詳細については、「Azure VM 上の SQL Server 用にクラスター クォーラムを構成する」を参照してください。
リモート デスクトップ セッションを使用して最初のクラスター ノードに接続します。
フェールオーバー クラスター マネージャーで、クラスターを右クリックし、[その他の操作] をポイントして、[クラスター クォーラム設定の構成] を選択します。
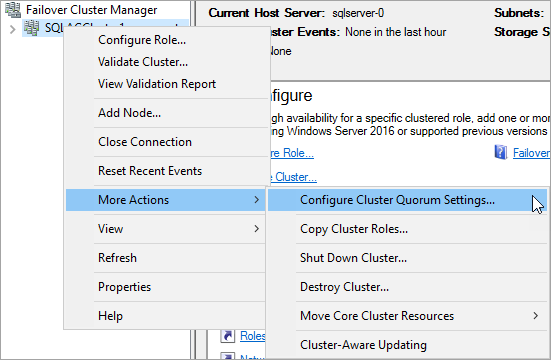
クラスター クォーラムの構成ウィザードで、[次へ] を選択します。
[クォーラム構成オプションの選択] ページで、[クォーラム監視を選択する]、[次へ] の順に選択します。
[クォーラム監視の選択] ページで、 [ファイル共有監視を構成する] を選択します。
ヒント
Windows Server 2016 では、クラウド監視がサポートされています。 この種類の監視を選択した場合、ファイル共有監視は必要ありません。 詳細については、「フェールオーバー クラスターのクラウド監視を展開する」を参照してください。 このチュートリアルでは、以前のオペレーティング システムでサポートされているファイル共有監視を使用します。
[ファイル共有監視の構成] で、作成した共有のパスを入力します。 次に [次へ] を選択します。
[確認] ページで、設定を確認します。 [次へ] を選択します。
[完了] を選択します。
クラスター コア リソースにファイル共有監視が構成されます。
可用性グループを有効にする
次に、Always On 可用性グループを有効にします。 両方の SQL Server VM で次の手順を行います。
[スタート] 画面から SQL Server 構成マネージャーを起動します。
ブラウザー ツリーで、[SQL Server サービス] を選択します。 [SQL Server (MSSQLSERVER)] サービスを右クリックし、[プロパティ] を選択します。
[AlwaysOn 高可用性] タブを選択し、[Always On 可用性グループを有効にする] をオンにします。
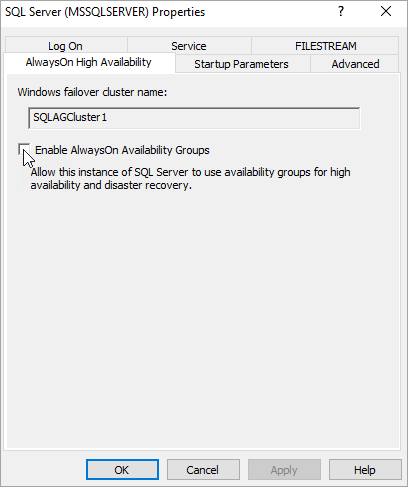
[適用] を選択します。 ポップアップ ダイアログで [OK] を選択します。
SQL Server サービスを再起動します。
FILESTREAM 機能を有効にする
可用性グループ内のデータベースに FILESTREAM を使用していない場合は、この手順をスキップして、次の手順であるデータベースの作成に進みます。
FILESTREAMを使用する可用性グループにデータベースを追加する場合、FILESTREAMは既定では無効になっているので、有効にする必要があります。 両方の SQL Server インスタンスを対象に、SQL Server 構成マネージャーを使用してこの機能を有効にします。
FILESTREAM 機能を有効にするには、次の手順を実行します。
sysadmin 固定サーバー ロールのメンバーであるドメイン アカウント、たとえば前提条件のドキュメントで作成した CORP\Install ドメイン アカウントを使用し、RDP ファイルを起動して 1 つ目の SQL Server VM (SQL-VM-1 など) に接続します。
いずれかの SQL Server VM の スタート画面から SQL Server 構成マネージャーを起動します。
ブラウザー ツリーで、 [SQL Server のサービス] を強調表示し、 [SQL Server (MSSQLSERVER)] サービスを右クリックして、 [プロパティ] を選択します。
FILESTREAM タブを選択し、[Transact-SQL アクセスに対して FILESTREAM を有効にする] チェック ボックスをオンにします。
[適用]を選択します。 ポップアップ ダイアログで [OK] を選択します。
SQL Server Management Studio で [新しいクエリ] を選択して、クエリ エディターを表示します。
クエリ エディターで、次の Transact-SQL コードを入力します。
EXEC sp_configure filestream_access_level, 2 RECONFIGURE[実行] を選択します。
SQL Server サービスを再起動します。
もう一方の SQL Server インスタンスについてもこれらの手順を繰り返します。
最初の SQL Server インスタンスでデータベースを作成する
- sysadmin 固定サーバー ロールのメンバーであるドメイン アカウントを使用して、最初の SQL Server VM の RDP ファイルを開きます。
- SQL Server Management Studio (SSMS) を開き、最初の SQL Server インスタンスに接続します。
- オブジェクト エクスプローラーで、 [データベース] を右クリックし、 [新しいデータベース] を選択します。
- [データベース名] に「MyDB1」と入力し、[OK] を選択します。
バックアップ共有を作成する
サーバー マネージャーの 1 つ目の SQL Server VM で、 [ツール] を選択します。 [コンピューターの管理] を開きます。
[共有フォルダー] を選択します。
[共有] を右クリックし、[新しい共有] を選択します。
共有フォルダーの作成ウィザードを使用して共有を作成します。
[フォルダー パス] ページで、[参照] を選択します。 データベース バックアップの共有フォルダーのパスを見つけるか作成し、[次へ] を選択します。
[名前、説明および設定] ページで、共有名とパスを確認します。 [次へ] を選択します。
[共有フォルダーのアクセス許可] ページで、[アクセス許可のカスタマイズ] を設定します。 次に、[カスタム] を選択します。
[アクセス許可のカスタマイズ] ダイアログで、[追加] を選択します。
[フル コントロール] チェック ボックスをオンにして、SQL Server サービス アカウント (
Corp\SQLSvc) に共有へのフル アクセスを付与します。![[アクセス許可のカスタマイズ] ダイアログのスクリーンショット。両方のサーバーの SQL Server サービスアカウントがフルコントロール権限を持っていることを確認してください。](media/availability-group-manually-configure-tutorial-single-subnet/68-backup-share-permission.png?view=azuresql)
[OK] を選択します。
[共有フォルダーのアクセス許可] ページで、[完了] を選択します。 [完了] をもう一度選択します。
データベースの完全バックアップを作成する
ログ チェーンを初期化するには、新しいデータベースをバックアップする必要があります。 新しいデータベースのバックアップを作成しないと、データベースを可用性グループに含めることはできません。
オブジェクト エクスプローラーで、データベースを右クリックし、[タスク] をポイントして、[バックアップ] を選択します。
[OK] を選択して、既定のバックアップ場所に完全バックアップを作成します。
可用性グループを作成する
以上で、次のタスクを実行して可用性グループを作成および構成する準備ができました。
- 最初の SQL Server インスタンスでデータベースを作成する。
- データベースの完全バックアップとトランザクション ログ バックアップの両方を作成します。
NO RECOVERYオプションを使用して、2 番目の SQL Server インスタンスに完全バックアップとログ バックアップを復元する。- 同期コミット、自動フェールオーバー、読み取り可能なセカンダリ レプリカを含む可用性グループ (MyTestAG) を作成する。
可用性グループを作成する
リモート デスクトップを使用して SQL Server VM に接続し、SQL Server Management Studio を開きます。
SSMS のオブジェクト エクスプローラーで、[Always On 高可用性] を右クリックし、[新しい可用性グループ ウィザード] を選択します。
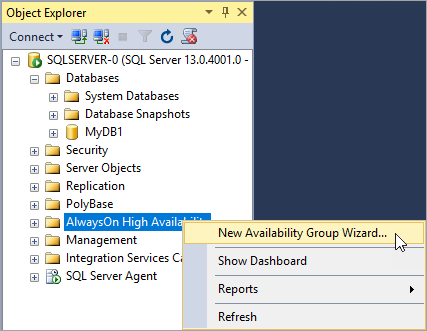
[説明] ページで [次へ] を選択します。 [可用性グループ オプションの指定] ページの [可用性グループ名] ボックスに、可用性グループの名前を入力します。 たとえば、「MyTestAG」と入力します。 [次へ] を選択します。
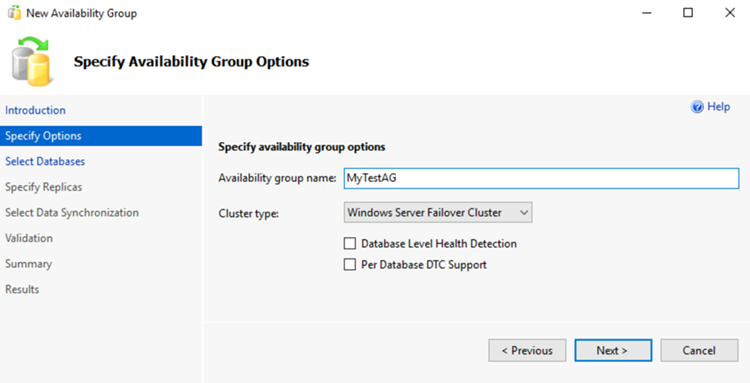
[データベースの選択] ページで、対象のデータベースを選択し、 [次へ] を選択します。
注意
対象とするプライマリ レプリカで完全バックアップを少なくとも 1 つは作成しているため、このデータベースは可用性グループの前提条件を満たしています。
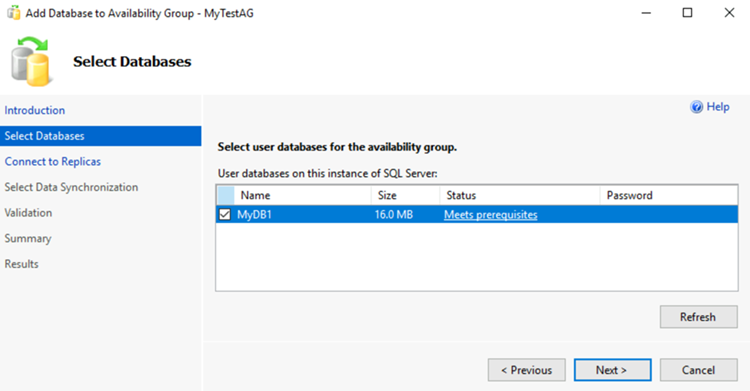
[レプリカの指定] ページで [レプリカの追加] を選択します。
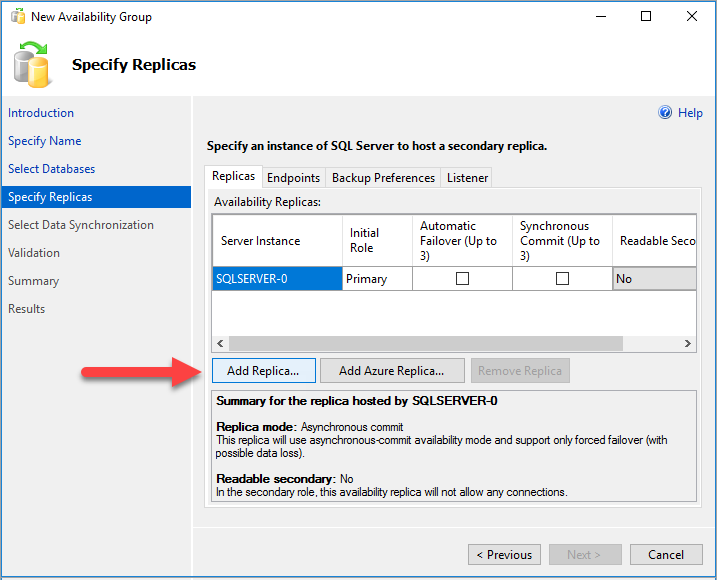
[サーバーへの接続]ダイアログの [サーバー名] に、2 番目の SQL Server インスタンスの名前を入力します。 次に、 [接続](Connect) を選択します。
[レプリカの指定] ページに戻ると、[可用性レプリカ] の下にある一覧に 2 番目のサーバーが表示されていることがわかります。 次に示すようにレプリカを構成します。
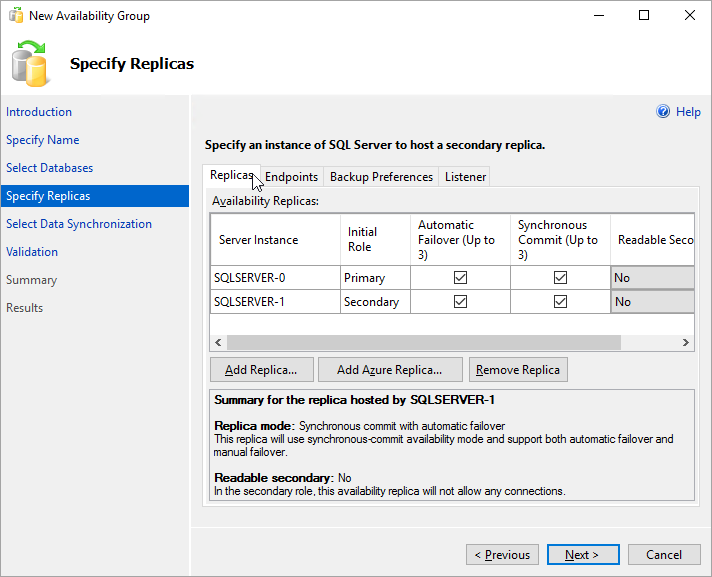
[エンドポイント] を選択して、この可用性グループのデータベース ミラーリング エンドポイントを表示します。 データベース ミラーリング エンドポイントのファイアウォール ルールを設定するときに使ったものと同じポートを使います。
![SSMS の新しい可用性グループ ウィザードの [エンドポイント] タブのスクリーンショット。](media/availability-group-manually-configure-tutorial-single-subnet/66-endpoint.png?view=azuresql)
[最初のデータ同期を選択] ページで、[完全] を選択し、共有ネットワークの場所を指定します。 この場所としては、先に作成したバックアップ共有を使います。 この例では、\\<最初の SQL Server インスタンス>\Backup\ でした。 [次へ] を選択します。
注意
完全同期では、SQL Server の 1 番目のインスタンスにあるデータベースの完全バックアップが作成されて、2 番目のインスタンスに復元されます。 大規模なデータベースの場合、完全同期は長時間かかる可能性があるためお勧めしません。
手動でデータベースのバックアップを作成し、
NO RECOVERYで復元することにより、この時間を短縮できます。 可用性グループを構成する前に、2 番目の SQL Server インスタンスでNO RECOVERYを使用してデータベースが既に復元されている場合は、[結合のみ] を選択します。 可用性グループを構成した後でバックアップを作成する場合は、[最初のデータ同期をスキップ] を選択します。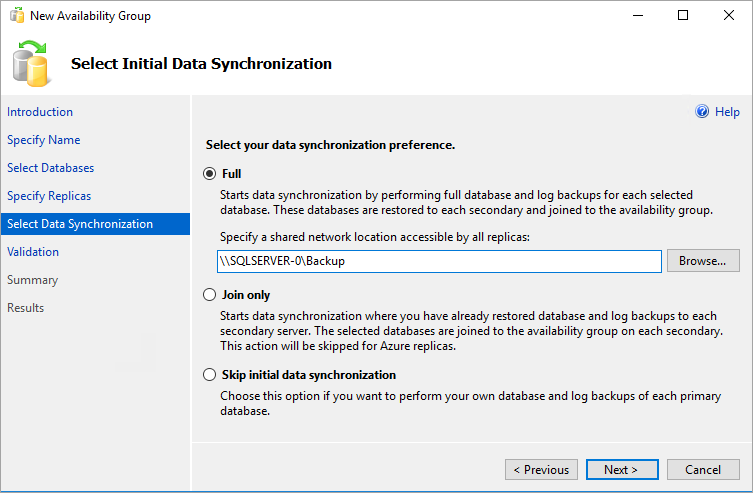
[検証] ページで [次へ] を選択します。 このページは次の図のようになります。
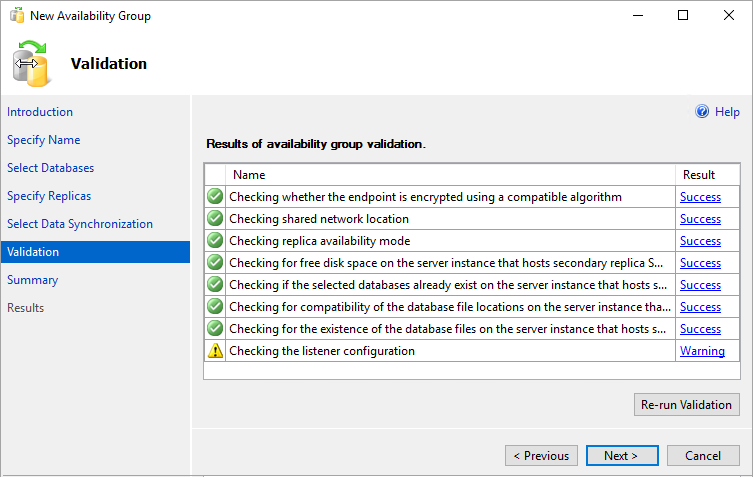
注意
可用性グループ リスナーを構成していないため、リスナー構成に関する警告が表示されます。 Azure 仮想マシンで Azure Load Balancer を作成した後にリスナーを作成するので、この警告は無視してかまいません。
[概要] ページで、[完了] を選択し、ウィザードで新しい可用性グループが構成されるまで待ちます。 [進行状況] ページで [詳細] を選択すると、進行状況が詳しく表示されます。
ウィザードで構成が完了したら、[結果] ページを調べて、可用性グループが正常に作成されたことを確認します。
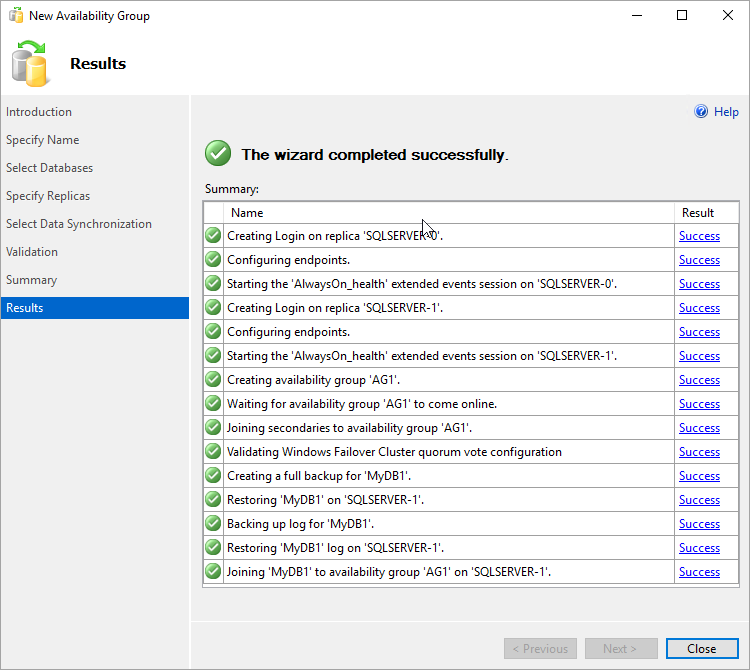
[閉じる] を選択してウィザードを閉じます。
![SSMS の新しい可用性グループ ウィザードの [エンドポイント] タブのスクリーンショット。](media/availability-group-manually-configure-tutorial-single-subnet/66-endpoint.png?view=azuresql#lightbox)
可用性グループを確認する
オブジェクト エクスプローラーで、[AlwaysOn 高可用性]、[可用性グループ] の順に展開します。 このコンテナー内に新しい可用性グループが表示されます。 可用性グループを右クリックして [ダッシュボードの表示] をクリックします。
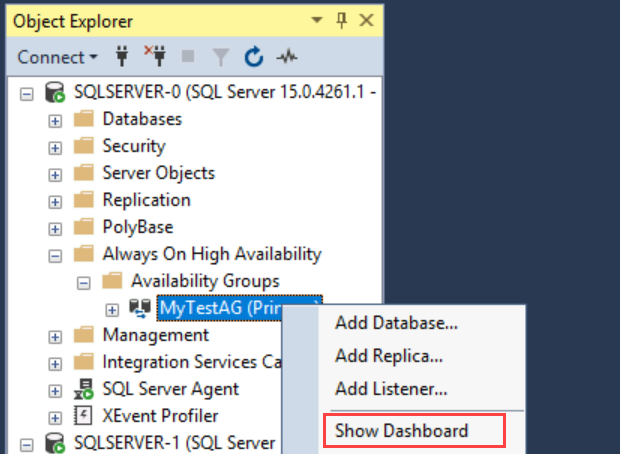
可用性グループ ダッシュボードが、次のスクリーンショットのように表示されます。
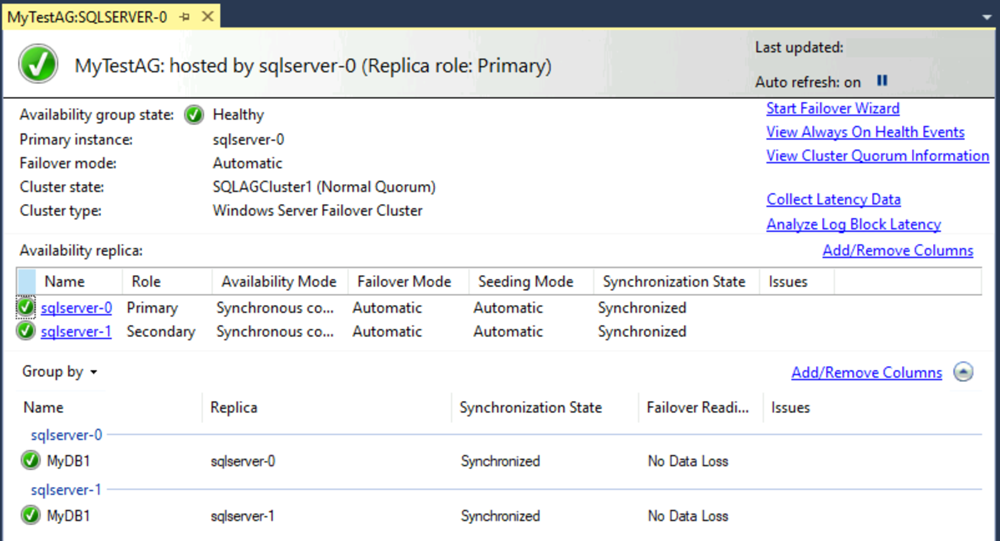
このダッシュボードには、レプリカ、各レプリカのフェールオーバー モード、同期の状態が表示されます。
フェールオーバー クラスター マネージャーで、対象のクラスターを選択します。 [役割] を選びます。
使用した可用性グループ名は、クラスターでのロールです。 リスナーを構成していないため、その可用性グループにはクライアント接続用の IP アドレスがありません。 Azure Load Balancer を作成した後で、リスナーを構成します。
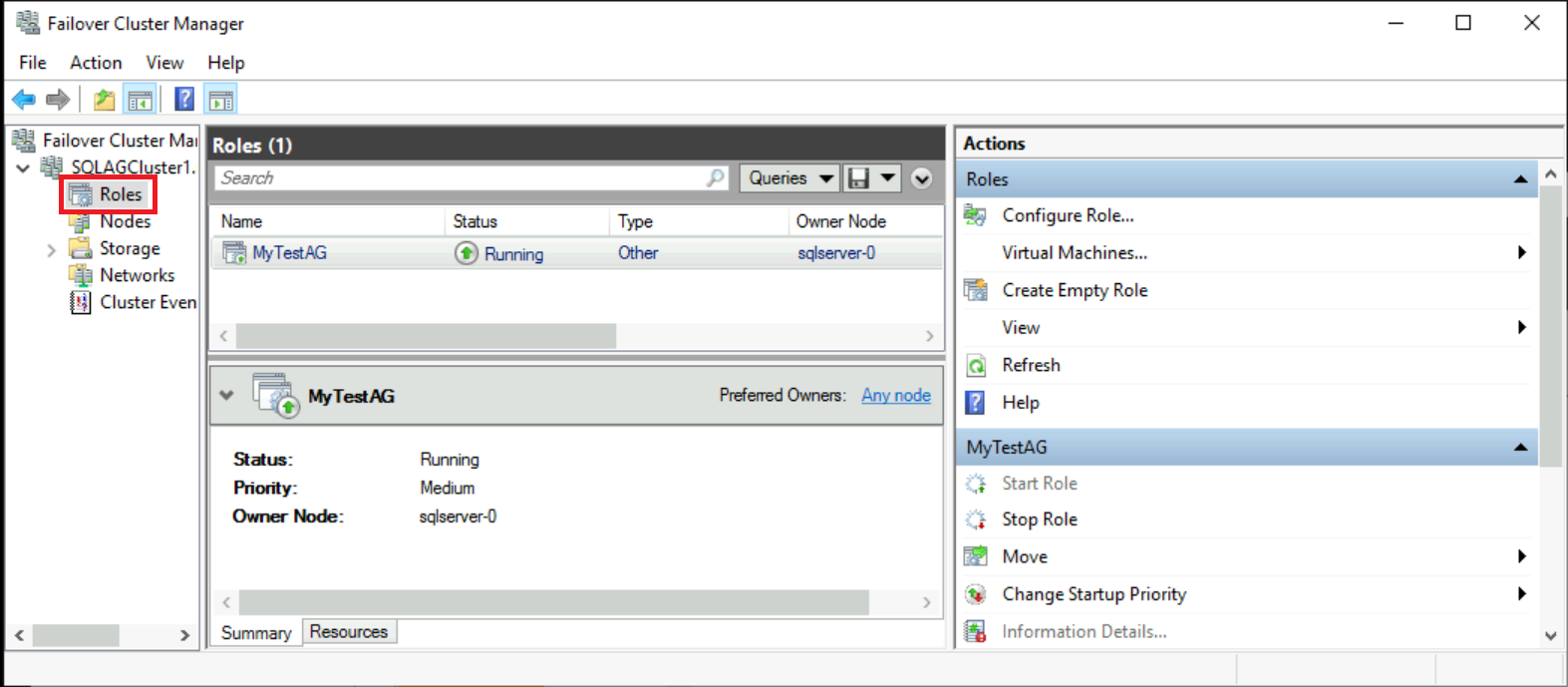
警告
フェールオーバー クラスター マネージャーから可用性グループのフェールオーバーを実行しないでください。 すべてのフェールオーバー操作は、SSMS の可用性グループ ダッシュボードから実行する必要があります。 詳細については、フェールオーバー クラスター マネージャーを使用した可用性グループの操作に関する制限事項に関するページを参照してください。


この時点で、2 つの SQL Server レプリカを含む可用性グループが作成されています。 可用性グループは、インスタンス間で移動できます。 リスナーがないため、可用性グループにはまだ接続できません。
Azure Virtual Machines では、リスナーにはロード バランサーが必要です。 次に、Azure でロード バランサーを作成します。
Azure Load Balancer を作成する
注意
複数のサブネットに可用性グループをデプロイする場合、ロード バランサーは必要ありません。 単一サブネット環境の場合、Windows 2016 以降で SQL Server 2019 CU8 以降をお使いのお客様は、従来の仮想ネットワーク名 (VNN) リスナーと Azure Load Balancer を分散ネットワーク名 (DNN) リスナーに置き換えることができます。 DNN を使用する場合は、可用性グループ用に Azure Load Balancer を構成するチュートリアル手順をスキップしてください。
単一サブネット内の Azure 仮想マシンでは、SQL Server 可用性グループにロード バランサーが必要です。 ロード バランサーには、可用性グループ リスナーと Windows Server フェールオーバー クラスターの IP アドレスが保持されます。 このセクションでは、Azure Portal でロード バランサーを作成する方法の概要を説明します。
Azure のロード バランサーは、Standard または Basic のいずれかになります。 Standard Load Balancer には、Basic Load Balancer よりも多くの機能があります。 可用性グループでは、(可用性セットではなく) 可用性ゾーンを使用する場合、Standard Load Balancer が必要です。 SKU の違いの詳細については、「Azure Load Balancer の SKU」を参照してください。
重要
Azure Load Balancer の Basic SKU は、2025 年 9 月 30 日に廃止される予定です。 詳細については、公式告知を参照してください。 現在、Basic Load Balancer をお使いの場合は、廃止日前に Standard Load Balancer にアップグレードしてください。 ガイダンスについては、ロード バランサーのアップグレードに関するページを参照してください。
Azure portal で、お使いの SQL Server VM が含まれているリソース グループに移動し、[+ 追加] を選択します。
" ロード バランサー" を検索します。 Microsoft が公開しているロード バランサーを選択します。
[作成] を選択します
[ロード バランサーの作成] ページで、ロード バランサーの次のパラメーターを構成します。
設定 入力または選択 サブスクリプション 仮想マシンと同じサブスクリプションを使います。 リソース グループ 仮想マシンと同じリソース グループを使用します。 名前 ロード バランサーのテキスト名 (例: sqlLB) を使用します。 リージョン 仮想マシンと同じリージョンを使用します。 SKU [Standard] を選択します。 Type [内部] を選択します。 ページは次のようになります。
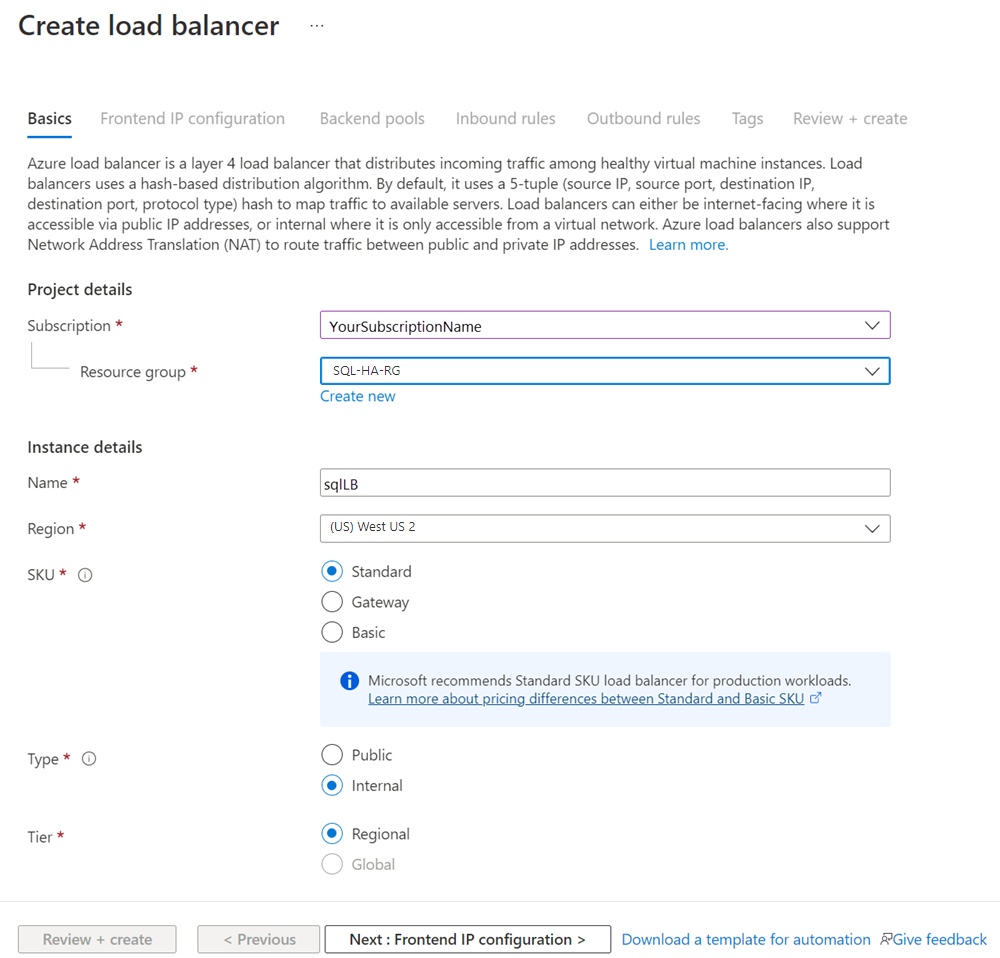
[次へ: フロントエンド IP 構成] を選びます。
[+ Add a frontend IP configuration] (+ フロントエンド IP 構成の追加) を選択します。
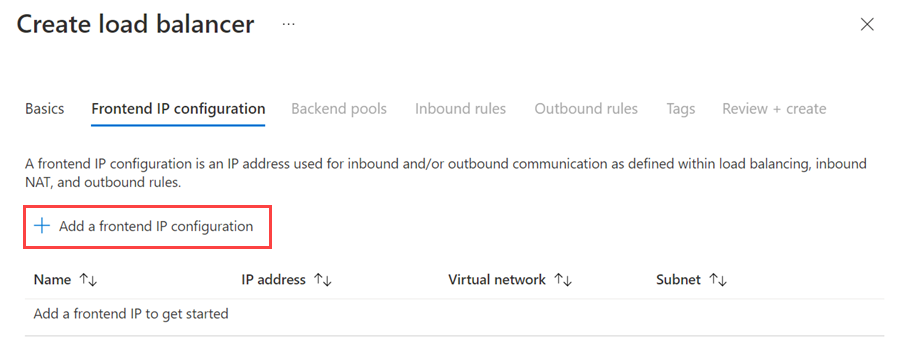
次の値を使用してフロントエンド IP アドレスを設定します。
- 名前: フロントエンド IP 構成を識別する名前を入力します。
- [仮想ネットワーク]: 仮想マシンと同じネットワークを選択します。
- [サブネット]: 仮想マシンと同じサブネットを選択します。
- [割り当て]: [静的] を選択します。
- [IP アドレス]: サブネットで利用できるアドレスを使用します。 可用性グループ リスナーにはこのアドレスを使用します。 このアドレスはクラスター IP アドレスとは異なります。
- 可用性ゾーン: 必要に応じて、IP アドレスをデプロイする可用性ゾーンを選択します。
次の図は、[フロントエンド IP 構成の追加] ダイアログを示しています。
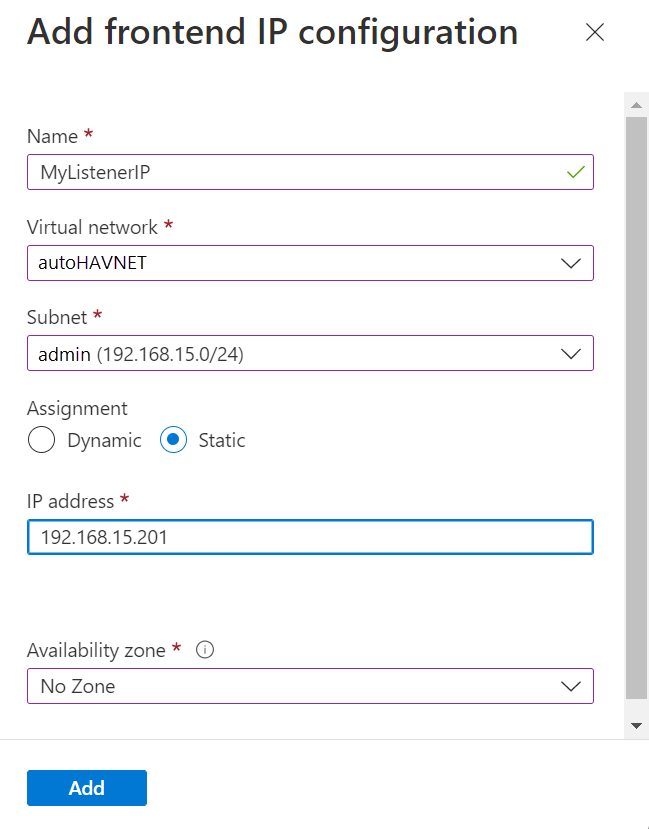
[追加] を選択します。
[確認と作成] を選択して構成を検証します。 次に、[作成] を選択して、ロード バランサーとフロントエンド IP アドレスを作成します。


ロード バランサーを構成するには、バックエンド プールとプローブを作成し、負荷分散規則を設定する必要があります。
可用性グループ リスナーのバックエンド プールを追加する
Azure ポータルで、ご利用のリソース グループに移動します。 新しく作成したロード バランサーを表示するため、ビューの更新が必要な場合があります。
ロード バランサーを選び、[バックエンド プール]、[+ 追加] の順に選択します。
[名前] で、バックエンド プールの名前を指定します。
[バックエンド プールの構成] で [NIC] を選択します。
[追加] を選択して、VM を含む可用性セットにバックエンド プールを関連付けます。
[仮想マシン] で、可用性グループ レプリカをホストする仮想マシンを選択します。 ファイル共有監視サーバーは含めないでください。
注意
仮想マシンを両方とも指定しないと、プライマリ レプリカにしか接続できません。
[追加] を選択して、仮想マシンをバックエンド プールに追加します。
[保存] を選択して、バックエンド プールを作成します。

プローブを設定する
Azure portal でロード バランサーを選び、[正常性プローブ]、[+ 追加] の順に選択します。
リスナーの正常性プローブを次のように設定します。
設定 説明 例 名前 Text SQLAlwaysOnEndPointProbe プロトコル TCP を選びます TCP [ポート] 未使用の任意のポート 59999 間隔 プローブの試行の間隔 (秒単位) 5 [追加] を選択します。
負荷分散規則を設定する
Azure portal でロード バランサーを選び、[負荷分散規則]、[+ 追加] の順に選択します。
リスナーの負荷分散規則を次のように設定します。
設定 説明 例 名前 Text SQLAlwaysOnEndPointListener フロントエンド IP アドレス アドレスを選びます ロード バランサーの作成時に作成したアドレスを使います。 バックエンド プール バックエンド プールを選ぶ ロード バランサーを対象とする仮想マシンを含むバックエンド プールを選択します。 プロトコル TCP を選びます TCP [ポート] 可用性グループ リスナーのポートを使用する 1433 バックエンド ポート Direct Server Return にフローティング IP を設定する場合は、このフィールドは使用しません 1433 正常性プローブ プローブに指定した名前 SQLAlwaysOnEndPointProbe セッション永続化 ドロップダウン リスト なし アイドル タイムアウト TCP 接続を開いたままにしておく時間 (分) 4 フローティング IP (ダイレクト サーバー リターン) フロー トポロジと IP アドレス マッピング スキーム 有効 警告
Direct Server Return は作成の間に設定されます。 これは変更できません。
[保存] を選択します。
Windows Server フェールオーバー クラスターのクラスター コア IP アドレスを追加する
Windows Server フェールオーバー クラスターの IP アドレスもロード バランサー上に存在する必要があります。 Windows Server 2019 を使用している場合は、クラスターでクラスター ネットワーク名の値ではなく、分散サーバー名の値が作成されるため、このプロセスをスキップしてください。
Azure portal で、同じ Azure ロード バランサーに移動します。 [フロントエンド IP 構成]、[+ 追加] の順に選択します。 クラスター コア リソース内の Windows Server フェールオーバー クラスター用に構成した IP アドレスを使用します。 この IP アドレスを [静的] として設定します。
ロード バランサーで、 [正常性プローブ] を選択し、 [+ 追加] を選択します。
Windows Server フェールオーバー クラスターのクラスター コア IP アドレスの正常性プローブを次のように設定します。
設定 説明 例 名前 Text WSFCEndPointProbe プロトコル TCP を選びます TCP [ポート] 未使用の任意のポート 58888 間隔 プローブの試行の間隔 (秒単位) 5 [追加] を選択して、正常性プローブを設定します。
[負荷分散規則]、[+ 追加] の順に選択します。
クラスター コア IP アドレスの負荷分散規則を次のように設定します。
設定 説明 例 名前 Text WSFCEndPoint フロントエンド IP アドレス アドレスを選びます Windows Server フェールオーバー クラスターの IP アドレスを構成したときに作成したアドレスを使用します。 これは、リスナーの IP アドレスとは異なります。 バックエンド プール バックエンド プールを選ぶ ロード バランサーを対象とする仮想マシンを含むバックエンド プールを選択します。 プロトコル TCP を選びます TCP [ポート] クラスター IP アドレスのポートを使用します。 これは、リスナー プローブ ポートには使用されない使用可能なポートです。 58888 バックエンド ポート Direct Server Return にフローティング IP を設定する場合は、このフィールドは使用しません 58888 プローブ プローブに指定した名前 WSFCEndPointProbe セッション永続化 ドロップダウン リスト なし アイドル タイムアウト TCP 接続を開いたままにしておく時間 (分) 4 フローティング IP (ダイレクト サーバー リターン) フロー トポロジと IP アドレス マッピング スキーム 有効 警告
Direct Server Return は作成の間に設定されます。 これは変更できません。
[OK] を選択します。
リスナーの構成
次に行う手順は、フェールオーバー クラスター上の可用性グループ リスナーの構成です。
注意
このチュートリアルでは、内部ロード バランサー用の 1 つの IP アドレスを持つ 1 つのリスナーを作成する方法について説明します。 1 つ以上の IP アドレスを使用してリスナーを作成するには、「1 つ以上の Always On 可用性グループ リスナーの構成」を参照してください。
可用性グループ リスナーとは、SQL Server 可用性グループがリッスンする IP アドレスとネットワーク名のことです。 可用性グループ リスナーを作成するには、次の手順を実行します。
-
a. プライマリ レプリカのホストとなっている Azure 仮想マシンに RDP で接続します。
b. フェールオーバー クラスター マネージャーを開きます。
c. Networks ノードを選択し、クラスター ネットワーク名をメモします。 この名前は、PowerShell スクリプトの
$ClusterNetworkName変数に使用します。 次の図で、クラスター ネットワーク名は Cluster Network 1 です。![[フェールオーバー クラスター マネージャー] 内のクラスター ネットワーク名を示すスクリーンショット。](../../includes/media/virtual-machines-ag-listener-configure/90-cluster-network-name.png?view=azuresql)
クライアント アクセス ポイントを追加します。 クライアント アクセス ポイントは、アプリケーションが可用性グループ内のデータベースに接続するために使用するネットワーク名です。
a. [フェールオーバー クラスター マネージャー] で、クラスター名を展開し、[ロール] を選択します。
b. [ロール] ペインで、可用性グループ名を右クリックし、[リソースの追加]>[クライアント アクセス ポイント] の順に選択します。
![可用性グループのショートカット メニューで [クライアント アクセス ポイント] コマンドの選択を示すフェールオーバー クラスター マネージャーのスクリーンショット。](../../includes/media/virtual-machines-ag-listener-configure/92-add-client-access-point.png?view=azuresql)
c. [名前] ボックスで、この新しいリスナーの名前を指定します。 新しいリスナーの名前は、アプリケーションが SQL Server 可用性グループ内のデータベースへの接続に使用するネットワーク名です。
d. リスナーの作成を完了するには、[次へ] を 2 回選択し、[完了] を選択します。 この時点では、リスナーまたはリソースをオンラインにしないでください。
可用性グループのクラスター ロールをオフラインにします。 [フェールオーバー クラスター マネージャー] の [ロール] で、ロールを右クリックし、[ロールの停止] を選択します。
-
a. [リソース] タブを選択し、作成したクライアント アクセス ポイントを展開します。 クライアント アクセス ポイントはオフラインになっています。

b. IP リソースを右クリックし、[プロパティ] を選択します。 この IP アドレス名はメモしておき、PowerShell スクリプトの
$IPResourceName変数に使用します。c. [IP アドレス] で [静的 IP アドレス] を選択します。 静的 IP アドレスを、Azure Portal でロード バランサーのアドレス設定時に使用したものと同じアドレスに設定します。

SQL Server 可用性グループ リソースがクライアント アクセス ポイントに依存するように設定します。
a. [フェールオーバー クラスター マネージャー] で、[ロール]、可用性グループの順に選択します。
b. [リソース] タブの [その他のリソース] で、可用性グループのリソースを右クリックし、[プロパティ] をクリックします。
c. [依存関係] タブで、クライアント アクセス ポイント (リスナー) の名前を追加します。
![[依存関係] タブでの名前の追加を示すフェールオーバー クラスター マネージャーのスクリーンショット。](../../includes/media/virtual-machines-ag-listener-configure/97-properties-dependencies.png?view=azuresql)
d. [OK] を選択します。
クライアント アクセス ポイントが IP アドレスに依存するように設定します。
a. [フェールオーバー クラスター マネージャー] で、[ロール]、可用性グループの順に選択します。
b. [リソース] タブの [サーバー名] で、クライアント アクセスポイント リソースを右クリックし、[プロパティ] を選択します。
![リスナーの名前の [プロパティ] メニュー オプションを示すフェールオーバー クラスター マネージャーのスクリーンショット。](../../includes/media/virtual-machines-ag-listener-configure/98-dependencies.png?view=azuresql)
c. [依存関係] タブを選択します。IP アドレスが依存関係の要素であることを確認します。 そうでない場合は、IP アドレスへの依存関係を設定します。 複数のリソースが一覧表示される場合は、IP アドレスに (AND ではなく) OR 依存関係があることを確認します。 [OK] をクリックします。
![可用性グループの IP リソースを示す [依存関係] タブのスクリーンショット。](../../includes/media/virtual-machines-ag-listener-configure/98-properties-dependencies.png?view=azuresql)
ヒント
依存関係が正しく構成されていることを確認できます。 [フェールオーバー クラスター マネージャー] で [ロール] に移動し、可用性グループを右クリックし、[その他の操作]、[依存関係レポートの表示] の順に選択します。 依存関係が正しく構成されると、可用性グループはネットワーク名に依存し、ネットワーク名は IP アドレスに依存します。
PowerShell でクラスターのパラメーターを設定します。
a. いずれかの SQL Server インスタンスに次の PowerShell スクリプトをコピーします。 環境に合わせて変数を更新してください。
$ClusterNetworkNameは、フェールオーバー クラスター マネージャーで [ネットワーク] を選択し、ネットワークを右クリックして [プロパティ] を選択することで、名前を見つけることができます。 $ClusterNetworkName は [全般] タブの [名前] にあります。$IPResourceNameは、フェールオーバー クラスター マネージャーの IP アドレス リソースに指定された名前です。 これはフェールオーバー クラスター マネージャーで [ロール] を選択し、SQL Server AG または FCI 名を選択し、[サーバー名] の [リソース] タブを選択し、IP アドレス リソースを右クリックして [プロパティ] を選択することで見つけることができます。 正しい値は [全般] タブの [名前] にあります。$ListenerILBIPは、Azure Load Balancer に対して作成した、可用性グループ リスナーの IP アドレスです。 フェールオーバー クラスター マネージャーの SQL Server AG または FCI リスナー リソース名と同じプロパティ ページで、$ListenerILBIP を見つけることができます。$ListenerProbePortは、Azure Load Balancer に対して構成した、可用性グループ リスナーのポート (59999 など) です。 未使用の TCP ポートが有効です。
$ClusterNetworkName = "<MyClusterNetworkName>" # The cluster network name. Use Get-ClusterNetwork on Windows Server 2012 or later to find the name. $IPResourceName = "<IPResourceName>" # The IP address resource name. $ListenerILBIP = "<n.n.n.n>" # The IP address of the internal load balancer. This is the static IP address for the load balancer that you configured in the Azure portal. [int]$ListenerProbePort = <nnnnn> Import-Module FailoverClusters Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{"Address"="$ListenerILBIP";"ProbePort"=$ListenerProbePort;"SubnetMask"="255.255.255.255";"Network"="$ClusterNetworkName";"EnableDhcp"=0}b. いずれかのクラスター ノード上で PowerShell スクリプトを実行して、クラスター パラメーターを設定します。
注意
SQL Server インスタンスが別個のリージョンに存在する場合は、PowerShell スクリプトを 2 回実行する必要があります。 1 回目の実行では、1 番目のリージョンの
$ListenerILBIPと$ListenerProbePortを使用します。 2 回目の実行では、2 番目のリージョンの$ListenerILBIPと$ListenerProbePortを使用します。 クラスター ネットワーク名とクラスター IP リソース名も、リージョンごとに異なります。可用性グループのクラスター ロールをオンラインにします。 [フェールオーバー クラスター マネージャー] の [ロール] で該当するロールを右クリックし、[ロールの起動] を選択します。
必要に応じて前の手順を繰り返し、Windows Server フェールオーバー クラスターの IP アドレスのクラスター パラメーターを設定します。
Windows Server フェールオーバー クラスターの IP アドレス名を取得します。 [フェールオーバー クラスター マネージャー] の [クラスター コア リソース] で、[サーバー名] を見つけます。
[IP アドレス] を右クリックし、[プロパティ] を選択します。
[名前] から IP アドレスの名前をコピーします。 これはクラスター IP アドレスである可能性があります。
PowerShell でクラスターのパラメーターを設定します。
a. いずれかの SQL Server インスタンスに次の PowerShell スクリプトをコピーします。 環境に合わせて変数を更新してください。
$ClusterCoreIPは、Azure Load Balancer に対して作成した、Windows Server フェールオーバー クラスターのコア クラスター リソースの IP アドレスです。 これは、可用性グループ リスナーの IP アドレスとは異なります。$ClusterProbePortは、Azure Load Balancer に対して作成した、Windows Server フェールオーバー クラスターの正常性プローブのポートです。 これは、可用性グループ リスナーのプローブとは異なります。
$ClusterNetworkName = "<MyClusterNetworkName>" # The cluster network name. Use Get-ClusterNetwork on Windows Server 2012 or later to find the name. $IPResourceName = "<ClusterIPResourceName>" # The IP address resource name. $ClusterCoreIP = "<n.n.n.n>" # The IP address of the cluster IP resource. This is the static IP address for the load balancer that you configured in the Azure portal. [int]$ClusterProbePort = <nnnnn> # The probe port from WSFCEndPointprobe in the Azure portal. This port must be different from the probe port for the availability group listener. Import-Module FailoverClusters Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{"Address"="$ClusterCoreIP";"ProbePort"=$ClusterProbePort;"SubnetMask"="255.255.255.255";"Network"="$ClusterNetworkName";"EnableDhcp"=0}b. いずれかのクラスター ノード上で PowerShell スクリプトを実行して、クラスター パラメーターを設定します。
49152 から 65536 までのポート (TCP/IP の既定の動的ポート範囲) を使用するように SQL リソースが構成されている場合は、各ポートの除外を追加します。 このようなリソースとしては、次のものがあります。
- SQL Server データベース エンジン
- AlwaysOn 可用性グループ リスナー
- フェールオーバー クラスター インスタンスの正常性プローブ
- データベース ミラーリング エンドポイント
- クラスター コア IP リソース
除外を追加することにより、他のシステム プロセスが同じポートに動的に割り当てられるのを防ぐことができます。 このシナリオでは、すべてのクラスター ノードで次の除外を構成します。
netsh int ipv4 add excludedportrange tcp startport=58888 numberofports=1 store=persistentnetsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
ポートが使用されていないときにポート除外を構成することが重要です。 それ以外の場合、コマンドは失敗し、"ファイルは別のプロセスで使用されているため、このプロセスでアクセスすることはできません" のようなメッセージが返されます。除外が正しく構成されていることを確認するには、コマンド netsh int ipv4 show excludedportrange tcp を使用します。
警告
可用性グループ リスナーの正常性プローブのポートは、クラスター コア IP アドレスの正常性プローブのポートとは異なっている必要があります。 これらの例で、リスナー ポートは 59999 で、クラスター コア IP アドレスの正常性プローブ ポートは 58888 です。 どちらのポートにも、"受信許可" ファイアウォール規則が必要です。
リスナー ポートを設定する
SQL Server Management Studio で、リスナー ポートを設定します。
SQL Server Management Studio を開き、プライマリ レプリカに接続します。
[Always On 高可用性]>[可用性グループ]>[可用性グループ リスナー] の順に移動します。
フェールオーバー クラスター マネージャーで作成したリスナー名を右クリックし、[プロパティ] を選択します。
[ポート] ボックスで、可用性グループ リスナーのポート番号を指定します。 既定では 1433 です。 [OK] を選択します。
これで、Azure Resource Manager モードで実行されている Azure VM 上に SQL Server の可用性グループが作成されました。
リスナーへの接続をテストする
接続をテストするには、次の手順に従います。
RDP を使用して、同じ仮想ネットワーク内にあるがレプリカ (他のレプリカなど) を所有していない SQL Server VM に接続します。
sqlcmd ユーティリティを使用して接続をテストします。 たとえば、次のスクリプトは、Windows 認証を使用してリスナー経由でプライマリ レプリカとの sqlcmd 接続を確立しています。
sqlcmd -S <listenerName> -Eリスナーが既定のポート (1433) 以外のポートを使用している場合は、そのポートを接続文字列で指定します。 たとえば、次のコマンドでは、ポート 1435 でリスナーに接続します。
sqlcmd -S <listenerName>,1435 -E
sqlcmd ユーティリティは、可用性グループの現在のプライマリ レプリカである SQL Server インスタンスに自動的に接続します。
ヒント
指定したポートは必ず、両方の SQL Server VM のファイアウォールで開放してください。 使用する TCP ポートに対する入力方向の規則が両方のサーバーに必要となります。 詳細については、「ファイアウォール規則を追加または編集する」を参照してください。