適用対象: ![]() Azure VM 上の SQL Server
Azure VM 上の SQL Server
ヒント
可用性グループをデプロイする方法は多数あります。 デプロイを簡略化し、Always On 可用性グループに対して Azure Load Balancer または分散ネットワーク名 (DNN) を不要にするには、同じ Azure 仮想ネットワーク内の複数のサブネットに SQL Server 仮想マシン (VM) を作成します。 可用性グループを 1 つのサブネットに既に作成している場合は、マルチサブネット環境に移行できます。
このチュートリアルでは、Azure Virtual Machines (VM) の複数のサブネット内に SQL Server の Always On 可用性グループを作成する方法を説明します。 チュートリアル全体では、Windows Server フェールオーバー クラスターを 1 つを作成し、さらに、2 つの SQL Server レプリカと 1 つのリスナーを含む可用性グループを 1 つ作成します。
推定所要時間: このチュートリアルの所要時間は、前提条件が満たされていると仮定して約 30 分です。
前提条件
次の表に、このチュートリアルを開始する前に完了している必要がある前提条件を示します。
| 要件 | 説明 |
|---|---|
 2 つの SQL Server インスタンス 2 つの SQL Server インスタンス |
- 各 VM が 2 つの異なる Azure Availability Zones または同じ可用性セットに存在すること - Azure Virtual Network 内の別個のサブネットに存在すること - 2 つのセカンダリ IP が各 VM に割り当てられていること - 単一ドメイン内 |
| SQL Server サービス アカウント |
各マシンの SQL Server サービスによって使用されるドメイン アカウント |
| ファイアウォールのポートを開きます |
- SQL Server: 1433 (既定のインスタンス用) - データベース ミラーリングのエンドポイント:5022 または使用可能な任意のポート |
| ドメインのインストール アカウント |
- 各 SQL Server 上のローカル管理者 - SQL Server の各インスタンスの SQL Server sysadmin 固定サーバー ロールのメンバー |
このチュートリアルでは、SQL Server Always On 可用性グループの基本的な知識があることを前提としています。
クラスターを作成する
Always On 可用性グループは Windows Server フェールオーバー クラスター インフラストラクチャ上で動作するため、可用性グループをデプロイするにあたってはまず、Windows Server フェールオーバー クラスターを構成する作業、たとえばその機能の追加、クラスターの作成、クラスターの IP アドレスの設定が必要となります。
フェールオーバー クラスターの機能を追加する
両方の SQL Server VM にフェールオーバー クラスターの機能を追加します。 これを行うには、次のステップに従います。
前提条件の記事で作成した CORP\Install ドメイン アカウントなど、AD にオブジェクトを作成するためのアクセス許可が割り当てられたドメイン アカウントを使用し、リモート デスクトップ プロトコル (RDP) を通じて SQL Server 仮想マシンに接続します。
[サーバー マネージャー] ダッシュボードを開きます。
ダッシュボードの [役割と機能の追加] リンクを選択します。
![ダッシュボードの [役割と機能の追加] リンクを選択します。](media/availability-group-manually-configure-prerequisites-tutorial-multi-subnet/09-add-features.png?view=azuresql)
[Server Features (サーバーの機能)] セクションが表示されるまで [次へ] を選択します。
[機能] で [フェールオーバー クラスタリング] を選択します。
その他の必要な機能を追加します。
[インストール] を選択して機能を追加します。
もう一方の SQL Server VM についても同じ手順を繰り返します。
クラスターの作成
それぞれの SQL Server VM にクラスター機能を追加したら、Windows Server フェールオーバー クラスターを作成する準備は完了です。
クラスターを作成するには、次の手順に従います。
前提条件の記事で作成した CORP\Install ドメイン アカウントなど、AD にオブジェクトを作成するためのアクセス許可が割り当てられたドメイン アカウントを使用し、リモート デスクトップ プロトコル (RDP) を使用して 1 つ目の SQL Server VM (SQL-VM-1 など) に接続します。
[サーバー マネージャー] ダッシュボードで、 [ツール] を選択し、 [フェールオーバー クラスター マネージャー] を選択します。
左側のペインで、 [フェールオーバー クラスター マネージャー] を右クリックし、 [クラスターの作成] を選択します。
クラスターの作成ウィザードの各ページの手順に従い、次の表に示した設定を使って 2 ノード クラスターを作成します。
ページ 設定 はじめに 既定値を使用します。 サーバーの選択 [サーバー名を入力してください] に 1 つ目の SQL Server の名前 (SQL-VM-1 など) を入力し、 [追加] を選択します。
[サーバー名を入力してください] に 2 つ目の SQL Server の名前 (SQL-VM-2 など) を入力し、 [追加] を選択します。検証の警告 [はい。[次へ] をクリックして、構成検証テストを実行し、その後クラスターの作成プロセスに戻ります] を選択します。 開始する前に [次へ] を選択します。 選択するテストのみを実行する [Run only the tests I select](選択したテストのみを実行する) を選択します。 テストの選択 [Storage](ストレージ) をクリアします。 [インベントリ] 、 [ネットワーク] 、 [システム構成] が選択されていることを確認してください。 確認 [次へ] を選択します。
検証の完了を待ちます。
[レポートの表示] を選択してレポートを確認します。 VM に到達できるネットワーク インターフェイスが 1 つしかないという警告は無視してかまいません。 Azure インフラストラクチャは物理的な冗長性を備えています。したがって、別途ネットワーク インターフェイスを追加する必要はありません。
[完了] を選択します。クラスター管理用のアクセス ポイント [クラスター名] にクラスター名を入力します (例: SQLAGCluster1)。 確認 [使用可能な記憶域をすべてクラスターに追加する] をオフにし、 [次へ] を選択します。 まとめ [完了] を選択します。 警告
[使用可能な記憶域をすべてクラスターに追加する] をオフにしないと、Windows はクラスター作成処理中に仮想ディスクをデタッチします。 その結果、仮想ディスクはディスク マネージャーやエクスプローラーに表示されなくなり、表示するためには、記憶域をクラスターから削除し、PowerShell を使って再アタッチしなければなりません。
フェールオーバー クラスターの IP アドレスを設定する
通常、クラスターに割り当てられる IP アドレスは VM に割り当てられた IP アドレスと同じです。つまり Azure では、クラスターの IP アドレスがエラー状態になるので、オンラインにすることができません。 IP リソースをオンラインにするには、クラスターの IP アドレスを変更してください。
「前提条件」で、各 SQL Server VM にセカンダリ IP アドレスを割り当てました。以下の表はその例です (実際の IP アドレスは異なる場合があります)。
| VM 名 | サブネット名 | サブネットのアドレス範囲 | セカンダリ IP 名 | セカンダリ IP アドレス |
|---|---|---|---|---|
| SQL-VM-1 | SQL-subnet-1 | 10.38.1.0/24 | windows-cluster-ip | 10.38.1.10 |
| SQL-VM-2 | SQL-subnet-2 | 10.38.2.0/24 | windows-cluster-ip | 10.38.2.10 |
これらの IP アドレスを、対象となる各サブネットのクラスターの IP アドレスとして割り当てます。
Note
Windows Server 2019 では、クラスター ネットワーク名の代わりに分散サーバー名がクラスターによって作成されます。また、クラスターの全ノードの IP アドレスにクラスター名オブジェクト (CNO) が自動的に登録されるので、Windows クラスター専用 IP アドレスは必要ありません。 Windows Server 2019 を使っている場合は、このセクションおよびクラスター コア リソースに関する他のステップをスキップするか、PowerShell を使って仮想ネットワーク名 (VNN) ベースのクラスターを作成してください。 詳細については、「フェールオーバー クラスター: クラスター ネットワーク オブジェクト」のブログを参照してください。
クラスターの IP アドレスを変更するには、次の手順に従います。
フェールオーバー クラスター マネージャーで、 [クラスター コア リソース] まで下にスクロールして、クラスターの詳細を展開します。 各サブネットの [名前] リソースと 2 つの [IP アドレス] リソースがエラー状態になっていることがわかります。
エラー状態の 1 つ目の IP アドレス リソースを右クリックし、 [プロパティ] を選択します。
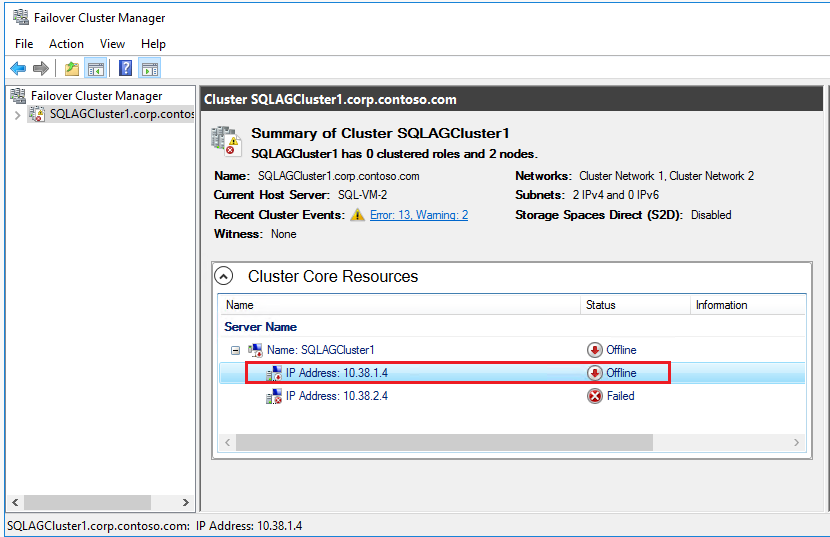
[静的 IP アドレス] を選択し、1 つ目の SQL Server VM (SQL-VM-1 など) に割り当てたサブネットの Windows クラスター専用 IP アドレスに更新します。 [OK] を選択します。
![**[静的 IP アドレス]** を選択し、「前提条件」の記事で SQL Server VM に割り当てた同じサブネットの Windows クラスター専用 IP アドレスに更新](media/availability-group-manually-configure-tutorial-multi-subnet/03-first-static-ip-address.png?view=azuresql)
2 つ目の SQL Server VM (SQL-VM-2 など) に割り当てたサブネットの Windows クラスター専用 IP アドレスを使用して、エラー状態の 2 つ目の [IP アドレス] リソースについても同じ手順を繰り返します。
![もう一方の SQL Server VM に割り当てたサブネットの Windows クラスター専用 IP アドレスを使用して、エラー状態の 2 つ目の **[IP アドレス]** リソースについても同じ手順を繰り返します。](media/availability-group-manually-configure-tutorial-multi-subnet/04-second-static-ip-address.png?view=azuresql)
[クラスター コア リソース] セクションで、クラスター名を右クリックして、 [オンラインにする] を選択します。 名前リソースといずれかの IP アドレス リソースがオンラインになるまで待ちます。
これらの SQL Server VM はそれぞれ異なるサブネットに存在するため、クラスターに使用されるのは、2 つの Windows クラスター専用 IP アドレスのうち、どちらか一方のみとなります。 クラスター名リソースがオンラインになると、新しい Active Directory (AD) コンピューター アカウントでドメイン コントローラー (DC) サーバーが更新されます。 クラスター コア リソースによってノードが移動された場合、一方の IP アドレスがオフラインになり、もう一方はオンラインに切り替わって、その新しい IP アドレスの関連付けで DC サーバーが更新されます。
ヒント
運用環境の Azure VM でクラスターを実行するときは、クラウド環境におけるクラスターの安定性と信頼性を高めるために、クラスターの設定をより緩やかな監視状態に変更してください。 詳細については、SQL Server VM の HADR 構成のベスト プラクティスに関する記事を参照してください。
クォーラムを構成する
2 ノード クラスターでは、クラスターの信頼性と安定性を確保するためにクォーラム デバイスが必要となります。 Azure VM では、クォーラム構成としてクラウド監視が推奨されますが、その他のオプションも提供されています。 このセクションの手順では、クォーラムのクラウド監視を構成します。 ストレージ アカウントへのアクセス キーを確認した後、クラウド監視を構成します。
ストレージ アカウントのアクセス キーを取得する
Microsoft Azure ストレージ アカウントを作成すると、自動的に生成される 2 つのアクセス キー (プライマリ アクセス キーとセカンダリ アクセス キー) がそこに関連付けられます。 クラウド監視の初回作成時はプライマリ アクセス キーを使用しますが、それ以降は、クラウド監視に使用するキーに制限はありません。
前提条件の記事で作成した Azure ストレージ アカウントのストレージ アクセス キーを Azure portal で確認し、コピーしてください。
ストレージ アクセス キーを確認してコピーするには、次の手順に従います。
Azure portal で対象のリソース グループに移動し、作成したストレージ アカウントを選択します。
[セキュリティとネットワーク] の [アクセス キー] を選択します。
[キーの表示] を選択してキーをコピーします。
![**[キーの表示]** を選択してキーをコピーします](media/availability-group-manually-configure-tutorial-multi-subnet/05-storage-account-keys.png?view=azuresql)
クラウド監視を構成する
アクセス キーをコピーしたら、クラスター クォーラムのクラウド監視を作成します。
クラウド監視を作成するには、次の手順に従います。
リモート デスクトップを使用して 1 つ目の SQL Server VM (SQL-VM-1) に接続します。
Windows PowerShell を管理者モードで開きます。
PowerShell スクリプトを実行して、接続の TLS (トランスポート層セキュリティ) の値を 1.2 に設定します。
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12PowerShell を使用してクラウド監視を構成します。 ストレージ アカウント名とアクセス キーの値は、実際の情報に置き換えてください。
Set-ClusterQuorum -CloudWitness -AccountName "Storage_Account_Name" -AccessKey "Storage_Account_Access_Key"次の出力例は成功を示しています。

クラスター コア リソースにクラウド監視が構成されます。
AG 機能を有効にする
Always On 可用性グループ機能は、既定では無効になっています。 両方の SQL Server インスタンスを対象に、SQL Server 構成マネージャーを使用してこの機能を有効にします。
可用性グループの機能を有効にするには、次の手順に従います。
sysadmin 固定サーバー ロールのメンバーであるドメイン アカウント、たとえば前提条件のドキュメントで作成した CORP\Install ドメイン アカウントを使用し、RDP ファイルを起動して 1 つ目の SQL Server VM (SQL-VM-1 など) に接続します。
いずれかの SQL Server VM の スタート画面から SQL Server 構成マネージャーを起動します。
ブラウザー ツリーで、 [SQL Server のサービス] を強調表示し、 [SQL Server (MSSQLSERVER)] サービスを右クリックして、 [プロパティ] を選択します。
[AlwaysOn 高可用性] タブを選択し、[Always On 可用性グループを有効にする] チェック ボックスをオンにします。
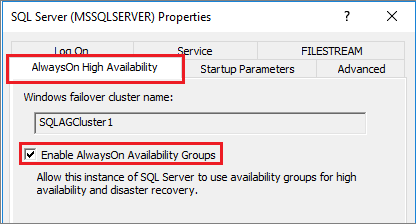
[適用] を選択します。 ポップアップ ダイアログで [OK] を選択します。
SQL Server サービスを再起動します。
もう一方の SQL Server インスタンスについてもこれらの手順を繰り返します。
FILESTREAM 機能を有効にする
可用性グループ内のデータベースに FILESTREAM を使用していない場合は、この手順をスキップして、次の手順であるデータベースの作成に進みます。
FILESTREAMを使用する可用性グループにデータベースを追加する場合、FILESTREAMは既定では無効になっているので、有効にする必要があります。 両方の SQL Server インスタンスを対象に、SQL Server 構成マネージャーを使用してこの機能を有効にします。
FILESTREAM 機能を有効にするには、次の手順を実行します。
sysadmin 固定サーバー ロールのメンバーであるドメイン アカウント、たとえば前提条件のドキュメントで作成した CORP\Install ドメイン アカウントを使用し、RDP ファイルを起動して 1 つ目の SQL Server VM (SQL-VM-1 など) に接続します。
いずれかの SQL Server VM の スタート画面から SQL Server 構成マネージャーを起動します。
ブラウザー ツリーで、 [SQL Server のサービス] を強調表示し、 [SQL Server (MSSQLSERVER)] サービスを右クリックして、 [プロパティ] を選択します。
FILESTREAM タブを選択し、[Transact-SQL アクセスに対して FILESTREAM を有効にする] チェック ボックスをオンにします。
[適用]を選択します。 ポップアップ ダイアログで [OK] を選択します。
SQL Server Management Studio で [新しいクエリ] をクリックして、クエリ エディターを表示します。
クエリ エディターで、次の Transact-SQL コードを入力します。
EXEC sp_configure filestream_access_level, 2 RECONFIGURE実行をクリックします。
SQL Server サービスを再起動します。
もう一方の SQL Server インスタンスについてもこれらの手順を繰り返します。
データベースの作成
データベースについては、このセクションの手順に従って新しいデータベースを作成するか、または AdventureWorks データベースを復元してください。 また、データベースをバックアップしてログ チェーンを初期化する必要があります。 バックアップされていないデータベースは、可用性グループの前提条件を満たしません。
データベースを作成するには、次の手順に従います。
- sysadmin 固定サーバー ロールのメンバーであるドメイン アカウント、たとえば前提条件のドキュメントで作成した CORP\Install ドメイン アカウントを使用し、RDP ファイルを起動して 1 つ目の SQL Server VM (SQL-VM-1 など) に接続します。
- SQL Server Management Studio を開き、SQL Server インスタンスに接続します。
- オブジェクト エクスプローラーで、 [データベース] を右クリックし、 [新しいデータベース] を選択します。
- [データベース名] に「MyDB1」と入力します。
- [オプション] ページを選択し、 [復旧モデル] ボックスの一覧から [完全] (既定値) を選択します。 可用性グループに参加する前提条件として、データベースが完全復旧モデルになっている必要があります。
- [OK] を選択して [新しいデータベース] ページを閉じ、新しいデータベースを作成します。
データベースをバックアップするには、次の手順に従います。
オブジェクト エクスプローラーでデータベースを右クリックし、 [タスク] を強調表示して、 [バックアップ] を選択します。
[OK] を選択して、既定のバックアップ場所にデータベースの完全バックアップを作成します。
ファイル共有の作成
2 つの SQL Server VM とそのサービス アカウントからアクセスできるバックアップ ファイル共有を作成します。
バックアップ ファイル共有を作成するには、次の手順に従います。
サーバー マネージャーの 1 つ目の SQL Server VM で、 [ツール] を選択します。 [コンピューターの管理] を開きます。
[共有フォルダー] を選択します。
[共有] を右クリックして [新しい共有] を選択し、共有フォルダーの作成ウィザードを使用して共有を作成します。
![[新しい共有] を選択する](media/availability-group-manually-configure-tutorial-multi-subnet/09-new-share.png?view=azuresql)
[フォルダー パス] で、 [参照] を選択して、データベース バックアップ共有フォルダーのパスを検索するか作成します (例:
C:\Backup)。 [次へ] を選択します。[名前、説明および設定] で、共有名とパスを確認します。 [次へ] を選択します。
[共有フォルダーのアクセス許可] で、 [アクセス許可のカスタマイズ] を設定します。 [カスタム] を選択します。
[アクセス許可のカスタマイズ] で、 [追加] を選択します。
[フル コントロール] チェック ボックスをオンにして、SQL Server サービス アカウント (
Corp\SQLSvc) に共有へのフル アクセスを付与します。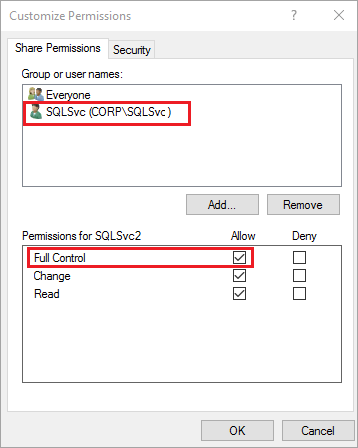
[OK] を選択します。
[共有フォルダーのアクセス許可] で、 [完了] を選択します。 [完了] をもう一度選択します。
可用性グループを作成する
データベースのバックアップが完了したら、可用性グループを作成することができます。可用性グループを作成することで自動的に、プライマリ SQL Server レプリカから完全バックアップとトランザクション ログ バックアップが作成され、NORECOVERY オプションでセカンダリ SQL Server インスタンスに復元されます。
可用性グループを作成するには、次の手順に従います。
1 つ目の SQL Server VM (SQL-VM-1 など) で、SQL Server Management Studio (SSMS) のオブジェクト エクスプローラーから [Always On 高可用性] を右クリックし、 [新しい可用性グループ ウィザード] を選択します。
[説明] ページで [次へ] を選択します。 [可用性グループ名の指定] ページで、 [可用性グループ名] に可用性グループの名前を入力します (例: AG1)。 [次へ] を選択します。
[データベースの選択] ページで、対象のデータベースを選択し、 [次へ] を選択します。 データベースが前提条件を満たしていない場合、データベースが完全復旧モデルになっていることを確認して、バックアップを作成してください。
[レプリカの指定] ページで [レプリカの追加] を選択します。
[サーバーに接続] ダイアログが表示されます。 2 番目のサーバーの名前を [サーバー名] に入力します (例: SQL-VM-2)。 [接続] を選択します。
[レプリカの指定] ページの [自動フェールオーバー] チェック ボックスをオンにし、可用性モードのボックスの一覧から [同期コミット] を選択します。
![**[レプリカの指定]** ページの [自動フェールオーバー] チェック ボックスをオンにし、可用性モードに [同期コミット] を選択します](media/availability-group-manually-configure-tutorial-multi-subnet/15-new-ag-replica.png?view=azuresql)
[エンドポイント] タブを選択して、データベース ミラーリング エンドポイントに使用されているポートが、ファイアウォールで開放したポートであることを確認します。
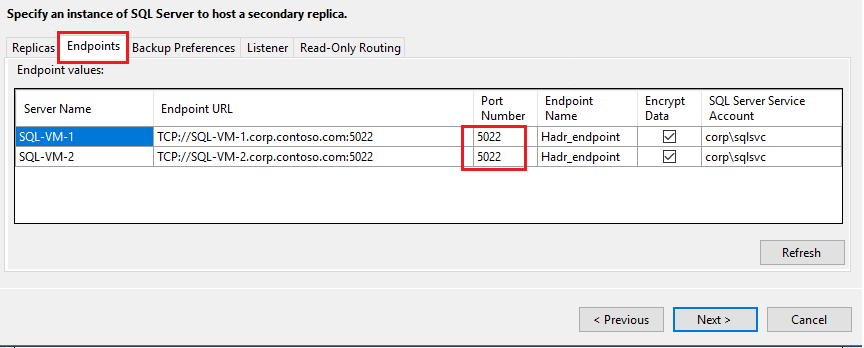
[リスナー] タブを選択し、可用性グループ リスナーを作成します。リスナーには次の値を使用します。
フィールド 値 リスナーの DNS 名 AG1-Listener Port 既定の SQL Server ポートを使用します。 1433 ネットワーク モード 静的 IP [追加] を選択し、両方の SQL Server VM について、リスナーのセカンダリ専用 IP アドレスを指定します。
次の表に示したのは、前提条件のドキュメントのリスナーに対して作成された IP アドレスの例です (実際の IP アドレスとは異なる場合があります)。
VM 名 サブネット名 サブネットのアドレス範囲 セカンダリ IP 名 セカンダリ IP アドレス SQL-VM-1 SQL-subnet-1 10.38.1.0/24 availability-group-listener 10.38.1.11 SQL-VM-2 SQL-subnet-2 10.38.2.0/24 availability-group-listener 10.38.2.11 [IP アドレスの追加] ダイアログ ボックスにあるドロップダウンから 1 つ目のサブネット (10.38.1.0/24 など) を選択し、リスナー専用のセカンダリ IPv4 アドレス (
10.38.1.11など) を入力します。 [OK] を選択します。![[IP アドレスの追加] ダイアログ ボックスにあるドロップダウンから 1 つ目のサブネット (10.38.1.0/24 など) を選択し、リスナー専用のセカンダリ IPv4 アドレス (10.38.1.11 など) を入力します](media/availability-group-manually-configure-tutorial-multi-subnet/18-add-listener-ip-subnet-1.png?view=azuresql)
もう一度同じ手順を行います。ただし、ドロップダウンから選択するのは、もう一方のサブネット (10.38.2.0/24 など) です。また、入力するアドレスも、もう一方の SQL Server VM のリスナー専用セカンダリ IPv4 アドレス (
10.38.2.11など) となります。 [OK] を選択します。
[リスナー] ページで値を確認した後、 [次へ] を選択します。
![[リスナー] ページで値を確認した後、[次へ] を選択します。](media/availability-group-manually-configure-tutorial-multi-subnet/20-listener.png?view=azuresql)
[最初のデータ同期を選択] ページで [完全なデータベースとログ バックアップ] を選択し、前に作成したネットワーク共有場所 (
\\SQL-VM-1\Backupなど) を入力します。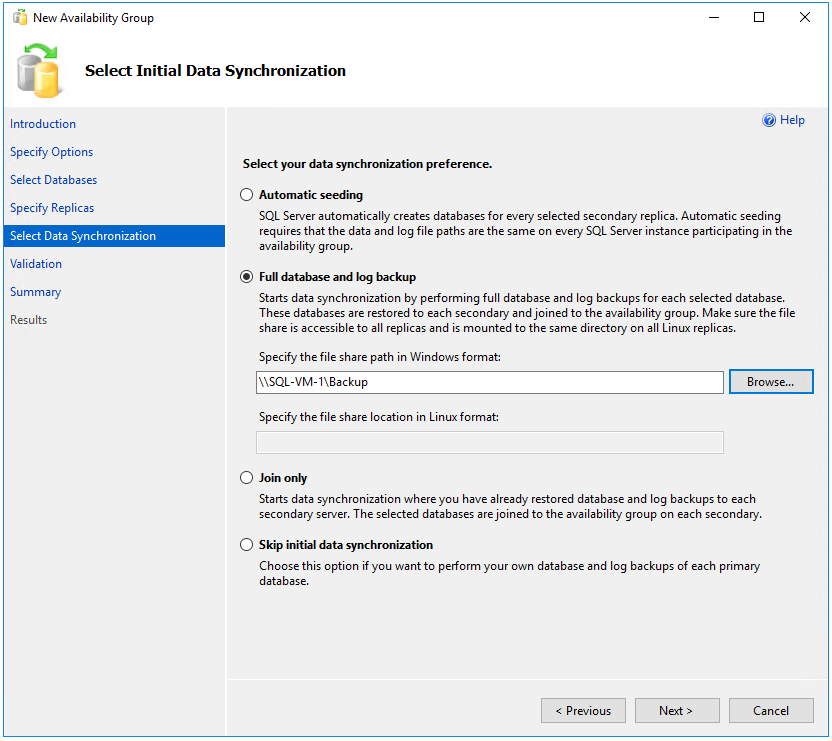
Note
完全同期では、SQL Server の 1 番目のインスタンスにあるデータベースの完全バックアップが作成されて、2 番目のインスタンスに復元されます。 大規模なデータベースの場合、完全同期は長い時間がかかることがあるのでお勧めできません。 手動でデータベースのバックアップを作成し、
NO RECOVERYで復元することにより、この時間を短縮できます。 可用性グループを構成する前に 2 番目の SQL Server のデータベースがNO RECOVERYで既に復元されている場合は、 [参加のみ] を選びます。 可用性グループを構成した後でバックアップを作成する場合は、 [最初のデータ同期をスキップ] を選びます。[検証] ページで、すべての検証チェックに成功していることを確認し、 [次へ] を選択します。
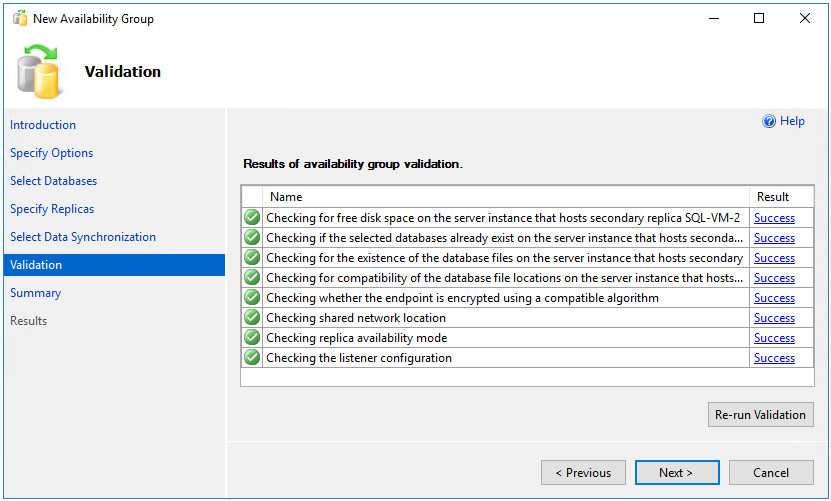
サマリー ページで [完了] を選択し、ウィザードによって新しい可用性グループが構成されるのを待ちます。 [進行状況] ページの [詳細情報] を選択して詳細な進行状況を表示します。 [結果] ページに "ウィザードが正常に完了しました" と入力されたら、サマリーを見て可用性グループとリスナーが正常に作成されたことを確認します。
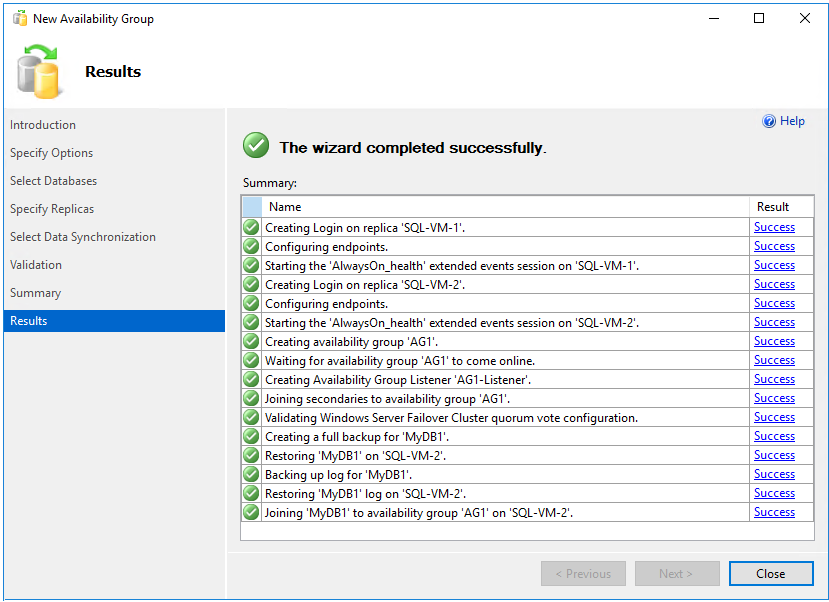
[閉じる] を選択してウィザードを終了します。
可用性グループを確認する
可用性グループの正常性は、SQL Server Management Studio とフェールオーバー クラスター マネージャーを使用して確認できます。
可用性グループの状態を確認するには、次の手順に従います。
オブジェクト エクスプローラーで [Always On 高可用性] を展開し、 [可用性グループ] を展開します。 このコンテナー内に新しい可用性グループが表示されます。 可用性グループを右クリックして [ダッシュボードの表示] をクリックします。
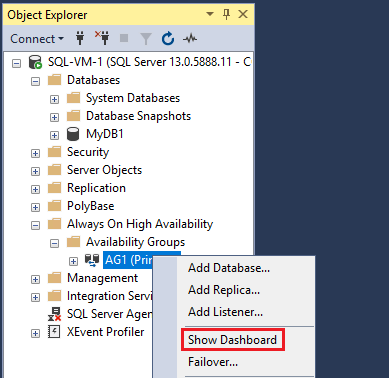
可用性グループ ダッシュボードに、レプリカと各レプリカのフェールオーバー モード、同期状態が表示されます。以下はその例です。
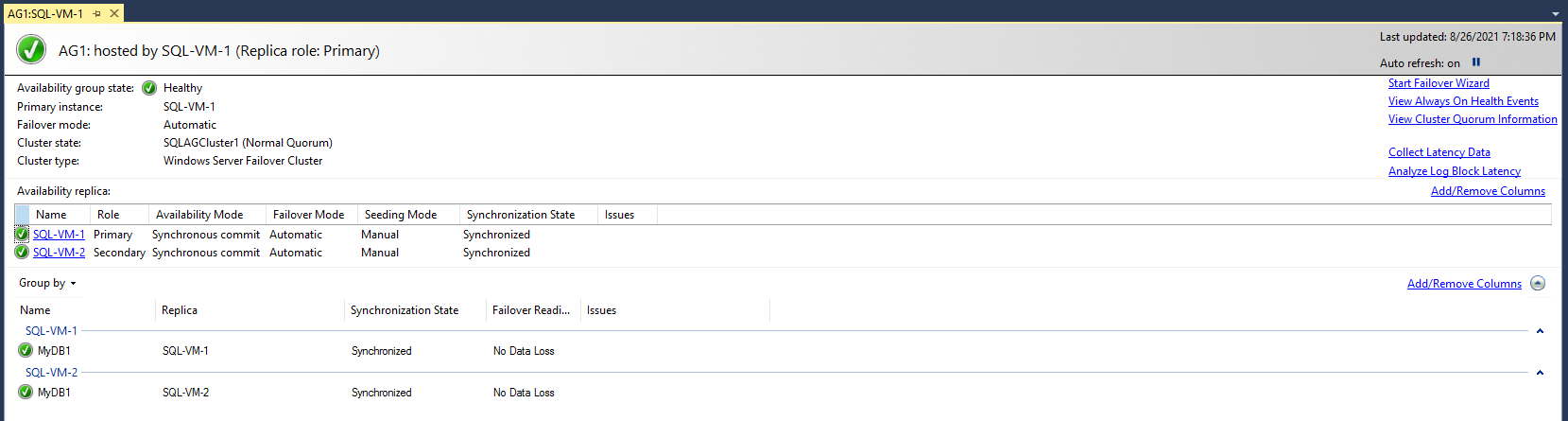
[フェールオーバー クラスター マネージャー] を開き、該当するクラスターを選択して [ロール] を選択すると、そのクラスター内に作成した可用性グループのロールが表示されます。 [AG1] ロールを選択し、 [リソース] タブを選択すると、次の例のように、リスナーとそれに関連付けられている IP アドレスが表示されます。
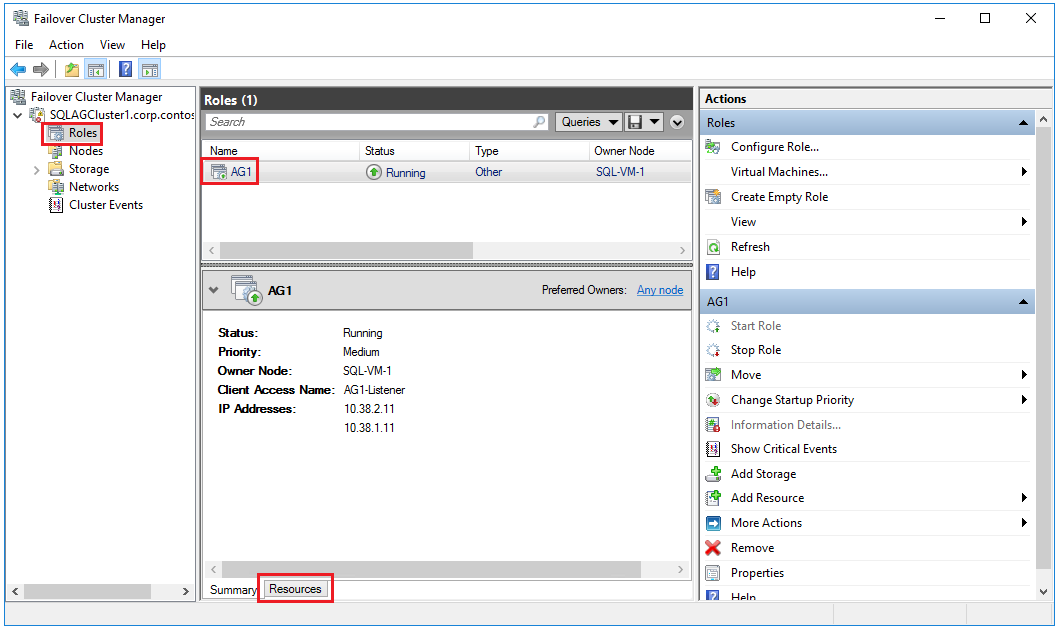
この時点で可用性グループは完成しており、SQL Server の 2 つのインスタンス上にレプリカが存在するほか、対応する可用性グループ リスナーが 1 つ存在します。 リスナーを使用して接続したり、SQL Server Management Studio を使用して 2 つのインスタンス間で可用性グループを移動したりすることができます。
警告
フェールオーバー クラスター マネージャーを使用して、可用性グループのフェールオーバーを実行することは避けてください。 フェールオーバー操作はすべて SQL Server Management Studio 内から、Always On ダッシュボードや Transact-SQL (T-SQL) を使用するなどして実行する必要があります。 詳細については、可用性グループに対するフェールオーバー クラスター マネージャーの使用に関する制限事項のページを参照してください。
リスナー接続をテストする
可用性グループの準備が整い、適切なセカンダリ IP アドレスでリスナーを構成したら、リスナーへの接続をテストします。
接続をテストするには、次の手順に従います。
同じ仮想ネットワーク内に存在するもののレプリカを保有していない SQL Server に RDP で接続します。クラスター内のもう一方の SQL Server インスタンスなど、SQL Server Management Studio がインストールされている VM であれば何でもかまいません。
SQL Server Management Studio を開き、 [サーバーに接続] ダイアログ ボックスの [サーバー名] にリスナーの名前 (「AG1-Listener」など) を入力し、 [オプション] を選択します。
![SQL Server Management Studio を開いて、リスナーの名前 (「AG1-Listener」など) を [サーバー名] に入力します](media/availability-group-manually-configure-tutorial-multi-subnet/27-ssms-listener-connect.png?view=azuresql)
[追加の接続パラメーター] ウィンドウに「
MultiSubnetFailover=True」と入力して [接続] を選択すると、プライマリ SQL Server レプリカがホストされているいずれかのインスタンスへと自動的に接続されます。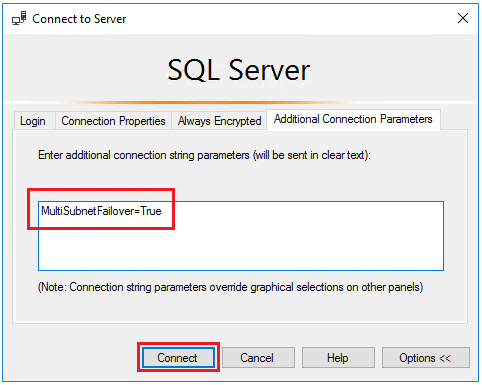
Note
- 異なるサブネット上の可用性グループに接続するときは、「
MultiSubnetFailover=true」に設定することで、現在のプライマリ レプリカの検出とレプリカへの接続にかかる時間が短縮されます。 「MultiSubnetFailover を使用した接続」を参照してください。
次のステップ
マルチサブネット可用性グループを構成したので、これを必要に応じて複数のリージョンに拡張できます。
詳細については、以下をご覧ください。