マルチモデル機能
適用対象: ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Microsoft Fabric SQL Database
Microsoft Fabric SQL Database
マルチモデル データベースを使用すると、リレーショナル データ、グラフ、JSON または XML ドキュメント、空間データ、キーと値のペアなどの複数の形式で表されているデータを格納したり、処理したりすることができます。
Azure SQL 製品群では、さまざまな汎用アプリケーションに対して最適なパフォーマンスを提供するリレーショナル モデルが使用されています。 ただし、Azure SQL Database や SQL Managed Instance などの Azure SQL 製品はリレーショナル データに限定されるわけではありません。 それらを使用すると、リレーショナル モデルに緊密に統合される非リレーショナル形式を使用できます。
以下の場合に、Azure SQL のマルチモデル機能の使用を検討します。
- NoSQL モデルに適した情報または構造はあるが、別個の NoSQL データベースを使用したくない。
- 大多数のデータがリレーショナル モデルに適しており、データの一部を NoSQL スタイルでモデル化する必要がある。
- Transact-SQL 言語を使用してリレーショナル データと NoSQL データの両方に対するクエリと分析を実行した後、そのデータを SQL 言語を使用できるツールやアプリケーションと統合したい。
- 分析のパフォーマンスや NoSQL データ構造の処理を向上させるために、メモリ内テクノロジなどのデータベース機能を適用したい。 トランザクション レプリケーションまたは読み取り可能レプリカを使用して、データのコピーを作成し、一部の分析ワークロードをプライマリ データベースからオフロードできます。
以下のセクションで、Azure SQL の最も重要なマルチモデル機能について説明します。
Note
同じ Transact-SQL クエリ内で JSONPath 式、XQuery/XPath 式、空間関数、およびグラフ クエリ式を使用して、データベースに格納したデータにアクセスできます。 Transact-SQL クエリを実行できるツールまたはプログラミング言語では、そのクエリ インターフェイスを使用してマルチモデル データにアクセスすることもできます。 これが、Azure Cosmos DB などの、データ モデル用の特別な API が用意されているマルチモデル データベースとの重要な違いです。
グラフ機能
Azure SQL 製品では、データベース内の多対多リレーションシップをモデル化するグラフ データベース機能が提供されています。 グラフは、ノード (頂点) とエッジ (リレーションシップ) のコレクションです。 ノードは、エンティティ (人や組織など) を表します。 エッジは、それによって接続される 2 つのノード間のリレーションシップ (例: 好意や友人など) を表します。
グラフ データベースを特徴付けるいくつかの特性を次に示します。
- エッジは、グラフ データベース内のファーストクラスのエンティティです。 属性またはプロパティを関連付けることができます。
- 1 つのエッジで、グラフ データベース内の複数のノードを柔軟に接続できます。
- パターン マッチングとマルチホップ ナビゲーション クエリを簡単に表現できます。
- 推移閉包およびポリモーフィック クエリを簡単に表現できます。
グラフ リレーションシップとグラフ クエリ機能は Transact-SQL に統合されており、基本的なデータベース管理システムとして SQL Server データベース エンジンを使用することから恩恵を受けます。 グラフ機能では、グラフの MATCH 演算子で拡張された標準の Transact-SQL クエリを使用して、グラフ データに対するクエリが実行されます。
リレーショナル データベースでは、グラフ データベースで可能なことをすべて実現できます。 しかし、グラフ データベースでは、特定のクエリをより簡単に表現することができます。 次の要因に基づいて、どちらを選択するかを決定できます。
- 1 つのノードで複数の親を持つことができる階層データをモデル化する必要があるため、hierarchyId データ型を使用できない。
- アプリケーションに、複雑な多対多リレーションシップがある。 アプリケーションが進化するにつれて、新しいリレーションシップが追加されます。
- 相互接続されたデータとリレーションシップを分析する必要があります。
- グラフ固有の T-SQL 検索条件 (SHORTEST_PATH など) を使用したい。
JSON 機能
Azure SQL 製品では、JavaScript Object Notation (JSON) 形式で表されているデータの解析とクエリ、およびリレーショナル データの JSON テキストとしてのエクスポートが可能です。 JSON は SQL Server データベース エンジンの中核となる機能です。
JSON 機能を使用すると、JSON ドキュメントのテーブルへの格納、リレーショナル データの JSON ドキュメントへの変換、および JSON ドキュメントのリレーショナル データへの変換を実行できます。 ドキュメントを解析するために、JSON 機能で拡張された標準の Transact-SQL 言語を使用できます。 非クラスター化インデックス、列ストア インデックス、またはメモリ最適化テーブルを使用して、クエリを最適化することもできます。
JSON は、最新の Web とモバイル アプリケーションでデータ交換を行うために使用される一般的なデータ形式です。 JSON は、ログ ファイルや NoSQL データベースに半構造化データを格納するためにも使用されます。 REST Web サービスの多くは結果を JSON テキスト形式で返し、データを JSON 形式で受け取ります。
ほとんどの Azure サービスには、JSON を返すか使用する REST エンドポイントがあります。 これらのサービスには、Azure Cognitive Search、Azure Storage、および Azure Cosmos DB が含まれます。
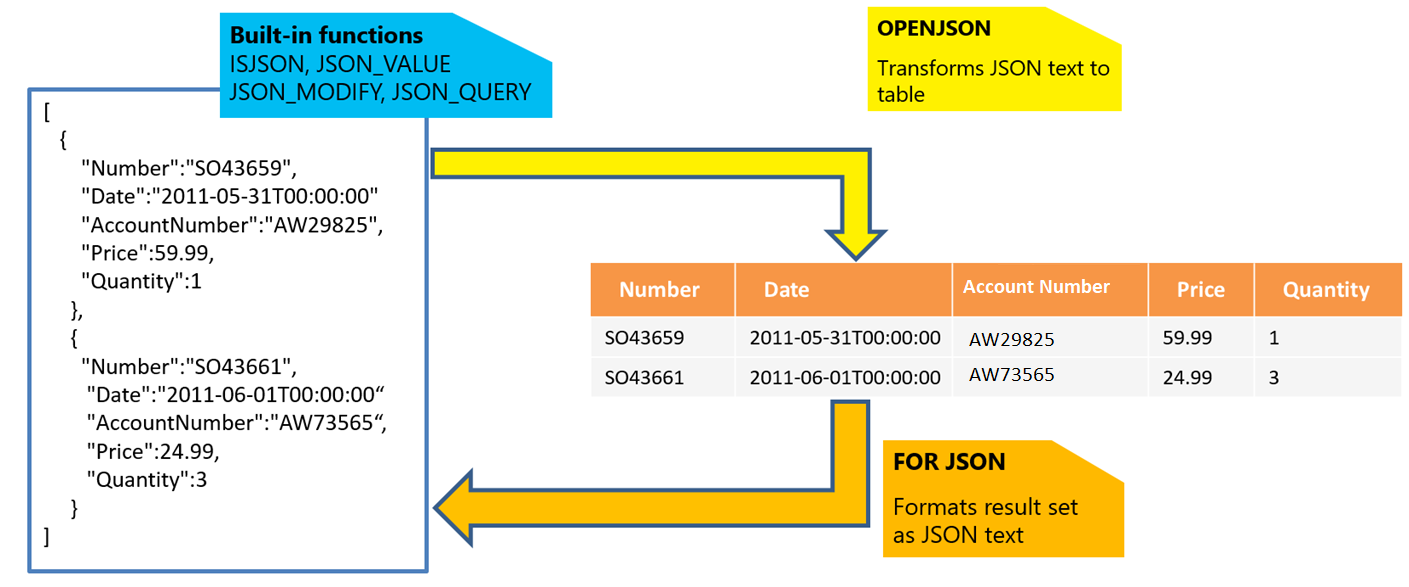
JSON テキストがある場合、組み込み関数 JSON_VALUE、JSON_QUERY、および ISJSON を使用して、JSON からデータを抽出したり、JSON が適切に書式設定されていることを確認したりすることができます。 その他の関数は次のとおりです。
- JSON_MODIFY: JSON テキスト内の値を更新できます。
- OPENJSON: 高度なクエリと分析のために、JSON オブジェクトの配列を行セットに変換できます。 すべての SQL クエリを返された結果セットで実行することができます。
- FOR JSON: リレーショナル テーブルに格納されるデータを JSON テキストとしてフォーマットできます。
詳細については、JSON データを処理する方法に関するページを参照してください。
次の特定のシナリオでは、リレーショナル モデルではなくドキュメント モデルを使用できます。
- オブジェクトのすべてのフィールドに一度にアクセスするため、スキーマの高度な正規化を行っても大きなメリットが得られない、またはオブジェクトの正規化された部分を更新することがない。 ただし、正規化されたモデルでは、データを取得するために結合する必要があるテーブルの数が多いため、クエリの複雑さが増します。
- 通信やデータ モデルで JSON ドキュメントをネイティブに使用するアプリケーションを使用しているが、リレーショナル データから JSON へ、またはその逆の変換を行うレイヤーをさらに導入したくない。
- 子テーブルまたはエンティティ/オブジェクト/値パターンの正規化を解除することで、データ モデルを簡略化する必要がある。
- データを解析する追加のツールなしで、JSON 形式で格納されているデータを読み込んだりエクスポートしたり必要がある。
XML 機能
XML 機能では、データベースに XML データを格納してインデックスを作成し、ネイティブの XQuery/XPath 演算を使用して XML データを処理することができます。 Azure SQL 製品には、XML データを処理する特別な XML データ型とクエリ関数が組み込まれています。
SQL Server データベース エンジンには、半構造化データを管理するアプリケーションを開発するための強力なプラットフォームが用意されています。 XML のサポートは、データベース エンジンのすべてのコンポーネントに統合されており、以下が含まれます。
- XML 値を XML データ型列にネイティブに格納する機能。XML スキーマのコレクションに従って型指定することも、型指定なしのままにすることもできます。 XML 列のインデックスを作成できます。
- XML 型の列と変数に格納されている XML データに対する XQuery クエリを指定する機能。 データベースで使用するデータ モデルにアクセスするすべての Transact-SQL クエリで XQuery 機能を使用できます。
- プライマリ XML インデックスを使用した XML ドキュメント内のすべての要素の自動インデックス作成。 または、セカンダリ XML インデックスを使用して、インデックスを作成する必要がある正確なパスを指定できます。
OPENROWSET。XML データを一括読み込みできます。- リレーショナル データを XML 形式に変換する機能。
次の特定のシナリオでは、リレーショナル モデルではなくドキュメント モデルを使用できます。
- オブジェクトのすべてのフィールドに一度にアクセスするため、スキーマの高度な正規化を行っても大きなメリットが得られない、またはオブジェクトの正規化された部分を更新することがない。 ただし、正規化されたモデルでは、データを取得するために結合する必要があるテーブルの数が多いため、クエリの複雑さが増します。
- 通信やデータ モデルで XML ドキュメントをネイティブに使用するアプリケーションを使用しているが、リレーショナル データから JSON へ、またはその逆の変換を行うレイヤーをさらに導入したくない。
- 子テーブルまたはエンティティ/オブジェクト/値パターンの正規化を解除することで、データ モデルを簡略化する必要がある。
- データを解析する追加のツールなしで、XML 形式で格納されているデータを読み込んだりエクスポートしたり必要がある。
空間機能
空間データは、オブジェクトの物理的な場所と形状に関する情報を表します。 これらのオブジェクトは、ポイントの場所や、国/地域、道路、湖などのより複雑なオブジェクトである可能性があります。
Azure SQL では、2 つの空間データ型がサポートされています。
- geometry 型では、ユークリッド (平面) 座標系でデータを表します。
- geography 型では、球状の地球座標系でデータを表します。
Azure SQL の空間機能を使用すると、幾何学的データと地理的データを格納できます。 Azure SQL の空間オブジェクトを使用して、JSON 形式で表されているデータの解析とクエリ、およびリレーショナル データの JSON テキストとしてのエクスポートを実行できます。 これらの空間オブジェクトには、Point、LineString、および Polygon があります。 Azure SQL には、空間クエリのパフォーマンスを向上させるために使用できる特別な空間インデックスも用意されています。
空間サポートは、SQL Server データベース エンジンの中核となる機能です。
キーと値のペア
Azure SQL 製品では、キー/値の構造を標準のリレーショナル テーブルとしてネイティブに表現できるため、キーと値のペアをサポートする特別な型も構造体もありません。
CREATE TABLE Collection (
Id int identity primary key,
Data nvarchar(max)
)
このキー/値の構造体は、何の制約も受けることなく、ニーズに合わせてカスタマイズできます。 たとえば、値を nvarchar(max) 型ではなく XML ドキュメントにすることができます。 値が JSON ドキュメントの場合は、JSON コンテンツの有効性を検証する CHECK 制約を使用できます。 追加の列に、1 つのキーに関連する任意の数の値を設定できます。 次に例を示します。
- 計算列とインデックスを追加して、データ アクセスを簡略化および最適化します。
- テーブルをメモリ最適化のスキーマ専用テーブルとして定義して、パフォーマンスを向上させます。
実際にリレーショナル モデルをキーと値のペア ソリューションとして効果的に使用する方法の例については、「bwin で SQL Server 2016 In-Memory OLTP を使用して前例のないパフォーマンスとスケーリングを実現する方法」を参照してください。 このケース スタディでは、bwin で ASP.NET キャッシュ ソリューション用のリレーショナル モデルを使用して、1 秒あたり 120 万バッチを達成しています。
次のステップ
マルチモデル機能は、Azure SQL 製品で共有される SQL Server データベース エンジンの中核となる機能です。 これらの機能の詳細については、次の記事を参照してください。