チュートリアル:Azure SQL Database と SQL Server のデータベース間の SQL データ同期を設定する
適用対象: ![]() Azure SQL データベース
Azure SQL データベース
重要
SQL データ同期 は、2027 年 9 月 30 日に廃止される予定です。 代替のデータ レプリケーション/同期ソリューションへの移行を検討してください。
このチュートリアルでは、Azure SQL Database と SQL Server の両方のインスタンスを含む同期グループを作成することによって SQL データ同期を設定する方法について説明します。 同期グループはカスタム構成され、設定されたスケジュールで同期します。
このチュートリアルは、SQL Database と SQL Server の使用経験があることを前提としています。
SQL データ同期の概要については、「Azure のSQL データ同期とは?」を参照してください。
PowerShell を使用した SQL データ同期の構成方法の例については、「Powershell を使用して Azure SQL データベースの複数データベース間でデータの同期」または「Azure SQL データベースと SQL Server のデータベース間でデータの同期」を参照してください。
ハブ データベースは同期トポロジの中心になるエンドポイントであり、1 つの同期グループには複数のデータベース エンドポイントが含まれます。 同期グループ内にエンドポイントがある他のすべてのメンバー データベースが、ハブ データベースと同期します。 SQL データ同期は Azure SQL データベースでのみサポートされています。 ハブ データベースは、Azure SQL Database にする必要があります。
Azure SQL データベース Hyperscale はハブデータベースとしてではなく、メンバーデータベースとしてのみサポートされています。
同期グループを作成する
Azure portal にアクセスします。 SQL データベースを検索して選択し、既存の Azure SQL Database を見つけます。
データ同期のハブ データベースとして使用するデータベースを選択します。
選択したデータベースの [SQL データベース] メニューの [データ管理]で、[別のデータベースに同期] を選択します。
[別のデータベースに同期] ページで、 [新しい同期グループ] を選択します。 一緒に、[データ同期グループの作成] ページが開きます。
[データ同期グループの作成] ページで、次の設定を構成します。
![Azure portal の [データ同期の作成] ページのスクリーンショット。自動同期で使用する新しい同期メタデータ データベースの作成。](media/sql-data-sync-sql-server-configure/create-sync-group.png?view=azuresql-db)
設定 説明 同期グループ名 新しい同期グループの名前を入力します。 この名前は、データベース自体の名前とは異なります。 同期メタデータ データベース 同期メタデータ データベースとして機能させるために、データベースの作成 (推奨)、あるいは既存データベースの使用を選択します。
Microsoft では、同期メタデータ データベースとして使用する新しい空のデータベースを作成することをお勧めしています。 データ同期は、このデータベースにテーブルを作成し、頻繁に発生するワークロードを実行します。 このデータベースは、選択したリージョンとサブスクリプション内のすべての同期グループの同期メタデータ データベースとして共有されます。 リージョン内のすべての同期グループと同期エージェントを削除しないと、データベースまたはその名前を変更することはできません。
新しいデータベースを作成する場合は、[新しいデータベース] を選択します。 [データベース設定を構成する]を選択する 次に、[SQL データベース] ページで、新しい Azure SQL データベースに名前を付けて構成し、[OK] を選択します。
[既存のデータベースを使用する] を選択した場合は、[同期メタデータ データベース]ドロップダウン リストからデータベースを選択します。自動同期 [オン] または [オフ] を選択します。
[オン] を選択した場合は、 [同期の頻度] セクションで数値を入力し、 [秒] 、 [分] 、 [時間] 、または [日] を選択します。
最初の同期は、構成が保存されてから、指定した期間が経過した後に開始されます。競合の解決 [Hub win](ハブ優先) または [Member win](メンバー優先) を選択します。
[Hub win](ハブ優先) とは、競合が発生した場合、ハブ データベースのデータによって、メンバー データベースの競合するデータが上書きされることを意味します。
[Member win](メンバー優先) とは、競合が発生した場合、メンバー データベースのデータによって、ハブ データベースの競合するデータが上書きされることを意味します。[ハブ データベースのユーザー名] と [ハブ データベースのパスワード] ハブ データベースのサーバー管理者 SQL 認証済みログインにユーザー名とパスワードを入力します。 これは、起動したのと同じ Azure SQL 論理サーバーのサーバー管理者のユーザー名とパスワードです。 Microsoft Entra (旧 Azure Active Directory) 認証はサポートされていません。 Private Link を使用する サービス マネージド プライベート エンドポイントを選択して、同期サービスとハブ データベースの間にセキュリティで保護された接続を確立します。 [OK] を選択し、同期グループが作成されてデプロイされるまで待ちます。
[新しい同期グループ] ページで、 [Use private link](Private Link を使用する) を選択した場合は、プライベート エンドポイント接続を承認する必要があります。 情報メッセージ内のリンクを使用すると、プライベート エンドポイント接続のエクスペリエンスに移動し、そこで接続を承認できます。
![Azure portal の [プライベート エンドポイント接続] ページのスクリーンショット。プライベート リンクを承認する場所が表示されています。](media/sql-data-sync-sql-server-configure/approve-private-link-update.png?view=azuresql-db)
Note
同期グループと同期メンバーのプライベート リンクは、個別に作成、承認、無効化する必要があります。
![Azure portal の [データ同期の作成] ページのスクリーンショット。自動同期で使用する新しい同期メタデータ データベースの作成。](media/sql-data-sync-sql-server-configure/create-sync-group.png?view=azuresql-db#lightbox)
![Azure portal の [プライベート エンドポイント接続] ページのスクリーンショット。プライベート リンクを承認する場所が表示されています。](media/sql-data-sync-sql-server-configure/approve-private-link-update.png?view=azuresql-db#lightbox)
同期メンバーを追加する
新しい同期グループが作成およびデプロイされたら、同期グループを開き、 [データベース] ページにアクセスします。ここで、同期メンバーを選択します。
Note
ユーザー名とパスワードを更新するか、ハブ データベースに挿入するには、 [同期メンバーの選択] ページの [ハブ データベース] セクションに移動します。
Azure SQL Database のデータベースをメンバーとして同期グループに追加する
[同期メンバーの選択] セクションで、必要に応じて [Azure データベースを追加] を選択して、Azure SQL Database 内のデータベースを同期グループに追加します。 [Azure データベースの構成] ページが開きます。
![Azure portal の [Azure Database の構成] ページのスクリーンショット。ここで、同期グループにデータベースを追加できます。](media/sql-data-sync-sql-server-configure/step-two-configure.png?view=azuresql-db)
[Configure Azure SQL Database](Azure SQL Database の構成) ページで、次の設定を変更します。
設定 説明 同期メンバー名 新しい同期メンバーの名前を指定します。 この名前は、データベース自体の名前とは異なります。 サブスクリプション 課金のために関連付ける Azure サブスクリプションを選択します。 Azure SQL Server 既存のサーバーを選択します。 Azure SQL Database SQL Database 内の既存のデータベースを選択します。 同期方向 同期の方向は、[ハブからメンバーへ] または [メンバーからハブへ]、あるいはその両方にすることができます。 [ハブから]、[ハブへ]、または [双方向同期] を選択します。詳細については、「しくみ」を参照してください。 [ユーザー名] と [パスワード] メンバー データベースが配置されているサーバーの既存の資格情報を入力します。 このセクションでは、"新しい" 資格情報を入力しないでください。 Private Link を使用する サービス マネージド プライベート エンドポイントを選択して、同期サービスとメンバー データベースの間にセキュリティで保護された接続を確立します。 [OK] を選択し、新しい同期メンバーが作成され、デプロイされるまで待ちます。
![Azure portal の [Azure Database の構成] ページのスクリーンショット。ここで、同期グループにデータベースを追加できます。](media/sql-data-sync-sql-server-configure/step-two-configure.png?view=azuresql-db#lightbox)
SQL Server インスタンス上のデータベースをメンバーとして同期グループに追加する
[メンバー データベース] セクションで、必要に応じて [オンプレミス データベースを追加] を選択して、SQL Server インスタンスのデータベースを同期グループに追加します。
[オンプレミスの構成] ページが開き、次の操作を実行できます。
[同期エージェント ゲートウェイの選択] を選択します。 [同期エージェントの選択] ページが開きます。
![Azure portal の [オンプレミスの構成] 手順のスクリーンショット。[同期エージェント ゲートウェイの選択] オプションを選択すると、[同期エージェントの選択] ページが表示されます。](media/sql-data-sync-sql-server-configure/steptwo-agent.png?view=azuresql-db)
[同期エージェントの選択] ページで、既存のエージェントを使用するか、エージェントを作成するかを選択します。
[既存のエージェント] を選択した場合は、一覧から既存のエージェントを選択します。
[新しいエージェントの作成] を選択した場合は、次の操作を行います。
表示されているリンクからデータ同期エージェントをダウンロードし、SQL Server インスタンスが配置されているサーバーとは別のサーバーにインストールします。 このエージェントは、Azure SQL Data Sync Agent のページから直接ダウンロードすることもできます。 データ同期クライアント エージェントのベスト プラクティスについては、「Azure SQL データ同期のベスト プラクティス」をご覧ください。
重要
クライアント エージェントがサーバーと通信できるように、ファイアウォールの送信 TCP ポート 1433 を開く必要があります。
[エージェント名] を入力する
[Create and Generate Key](作成とキーの生成) を選択し、エージェント キーをクリップボードにコピーします。
[OK] を選択して、 [同期エージェントの選択] ページを閉じます。
データ同期クライアント エージェントがインストールされているサーバーで、Client Sync Agent アプリを見つけて実行します。
![Microsoft SQL データ同期 2.0 クライアント エージェント アプリのスクリーンショット。[エージェント キーの送信] ボタンが強調表示されています。](media/sql-data-sync-sql-server-configure/datasync-preview-clientagent.png?view=azuresql-db)
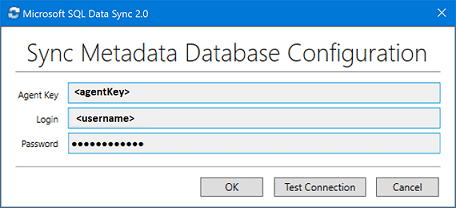
同期エージェント アプリで [Submit Agent Key](エージェント キーの送信) を選択します。 [Sync Metadata Database Configuration](同期メタデータ データベースの構成) ダイアログ ボックスが開きます。
[Sync Metadata Database Configuration](同期メタデータ データベースの構成) ダイアログ ボックスで、Azure portal からコピーしたエージェント キーを貼り付けます。 また、同期メタデータ データベース のデータベースが配置されているサーバーの既存の資格情報も適用します。 [OK] を選択し、構成が完了するまで待ちます。
Note
ファイアウォール エラーが発生する場合は、SQL Server コンピューターからの受信トラフィックを許可するファイアウォール規則を Azure 上に作成する必要があります。 この規則は、ポータルまたは SQL Server Management Studio (SSMS) で手動で作成できます。 SSMS で、名前を
<hub_database_name>.database.windows.netとして入力することで、Azure 上のハブ データベースに接続します。[登録] を選択して、SQL Server データベースをエージェントに登録します。 [SQL Server の構成] ダイアログ ボックスが開きます。
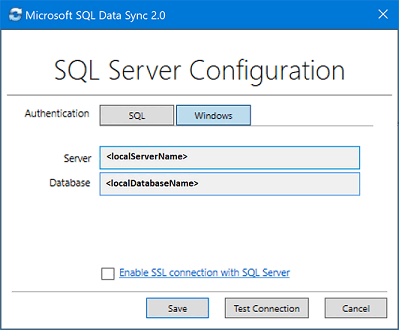
[SQL Server の構成] ダイアログ ボックスで、SQL Server 認証と Windows 認証のどちらを使用して接続するかを選択します。 SQL Server 認証を選択した場合は、既存の資格情報を入力します。 SQL Server の名前と、同期するデータベースの名前を指定し、 [テスト接続] を選択して設定をテストします。 その後、 [保存] を選択します。登録したデータベースが一覧に表示されます。
Client Sync Agent アプリを閉じます。
Azure portal の [オンプレミスの構成] ページで、[データベースの選択] を選択します。
[データベースの選択] ページの [メンバー名の同期] フィールドで、新しい同期メンバーの名前を指定します。 この名前は、データベース自体の名前とは異なります。 一覧からデータベースを選択します。 [同期方向] フィールドで、 [双方向の同期] 、 [ハブへ] 、または [ハブから] を選択します。
[OK] を選択して、 [データベースの選択] ページを閉じます。 さらに [OK] を選択して [オンプレミスの構成] ページを閉じ、新しい同期メンバーが作成およびデプロイされるまで待ちます。 最後に、 [OK] を選択して [同期メンバーの選択] ページを閉じます。
Note
SQL データ同期およびローカル エージェントに接続するには、DataSync_Executor ロールにユーザー名を追加します。 データ同期は、このロールを SQL Server インスタンス上に作成します。
同期グループを構成する
新しい同期グループ メンバーが作成およびデプロイされたら、 [データベース同期グループ] ページの [テーブル] セクションに移動します。
![Azure portal のスクリーンショット。[テーブル] ページで、同期するテーブルとフィールドを選択します。](media/sql-data-sync-sql-server-configure/configure-sync-group.png?view=azuresql-db#lightbox)
[テーブル] ページで、同期グループ メンバーの一覧からデータベースを選択し、 [スキーマの更新] を選択します。 スキーマの更新には数分の遅延が生じることがあります。また、プライベート リンクを使用している場合は遅延時間が長くなる可能性があります。
一覧から、同期するテーブルを選択します。既定では、すべての列が選択されているため、同期しない列のチェック ボックスをオフにします。主キー列は、選択されたままにしておいてください。
[保存] を選択します。
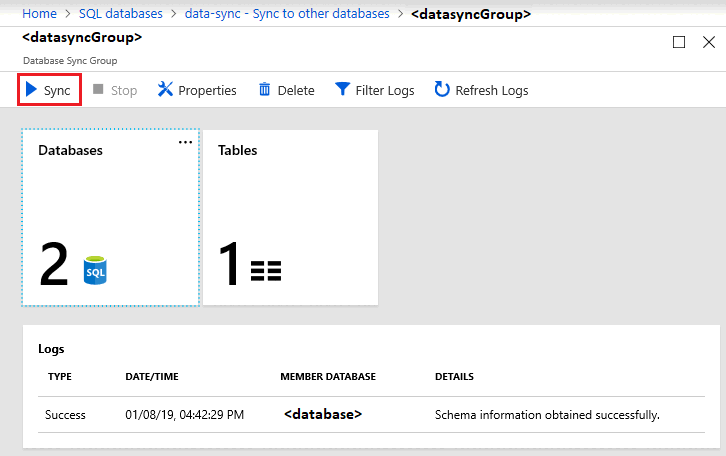
既定では、スケジュールに従うか手動で実行されるまで、データベースは同期されません。 手動による同期を実行するには、Azure portal で SQL Database 内の対象のデータベースに移動し、 [別のデータベースに同期] を選択し、同期グループを選択します。 [データ同期] ページが開きます。 [同期] を選択します。
よく寄せられる質問
このセクションでは、Azure SQL データ同期サービスに関するよくある質問に答えます。
SQL データ同期では、テーブル全体が作成されますか?
同期先データベースに同期スキーマ テーブルがない場合は、ご自分で選択した列を持つテーブルが SQL データ同期によって作成されます。 ただし、以下の理由から、これは完全に忠実なスキーマにはなりません。
- 同期先テーブルには、ご自分で選択した列だけが作成されます。 選択していない列は無視されます。
- 同期先テーブルには、選択した列のインデックスだけが作成されます。 列が選択されていない場合、それらのインデックスは無視されます。
- XML 型の列のインデックスは作成されません。
- CHECK 制約は作成されません。
- 同期元テーブル上のトリガーは作成されません。
- ビューとストアド プロシージャは作成されません。
これらの制限のため、次のことをお勧めします。
- 運用環境では、完全に忠実なスキーマをご自身で作成します。
- サービスを試す場合は、自動プロビジョニング機能を使用します。
自分で作成していないテーブルがあるのはなぜですか?
データ同期では、データベース内に変更を追跡するための追加のテーブルが作成されます。 これらを削除しないでください。削除するとデータ同期が動作を停止します。
同期後にデータは収束しますか?
必ずしもその必要はありません。 ハブと 3 つのスポーク (A、B、C) を持つ同期グループがあり、同期は ハブから A、ハブから B、ハブから C に対して行われるものとします。ハブから A への同期が実行された "後" でデータベース A が変更された場合、その変更は、次の同期タスクが実行されるまで、データベース B またはデータベース C には書き込まれません。
スキーマの変更を同期グループに反映するにはどうすればよいですか?
すべてのスキーマの変更を手動で行い、手動で反映してください。
- ハブおよびすべての同期メンバーに対してスキーマ変更を手動でレプリケートします。
- 同期スキーマを更新します。
新しいテーブルと列を追加する場合:
新しいテーブルと列は現在の同期に影響しないため、データ同期では、それらが同期スキーマに追加されるまで無視されます。 新しいデータベース オブジェクトを追加する場合は、次のシーケンスに従ってください。
- 新しいテーブルまたは列を、ハブとすべての同期メンバーに追加します。
- 新しいテーブルまたは列を、同期スキーマに追加します。
- 新しいテーブルと列への値の挿入を開始します。
列のデータ型を変更するには、次のようにします。
既存の列のデータ型を変更した場合、データ同期は新しい値が同期スキーマで定義された元のデータ型に一致する限り動作を続行します。 たとえば、同期元データベース内の型を int から bigint に変更した場合、int データ型としては大きすぎる値を挿入するまで、データ同期は動作を続行します。 変更を完了するには、ハブとすべての同期メンバーに対してスキーマの変更を手動でレプリケートした後、同期スキーマを更新します。
データ同期でデータベースのエクスポートとインポートを行うにはどうすればよいですか?
データベースを .bacpac ファイルとしてエクスポートし、そのファイルをインポートしてデータベースを作成した後、以下を実行して、新しいデータベースでデータ同期を使用します。
- Data Sync complete cleanup.sql を使用して、新しいデータベースでデータ同期オブジェクトと追加のテーブルをクリーンアップします。 このスクリプトは、データベースからすべての必要なデータ同期オブジェクトを削除します。
- 新しいデータベースで同期グループを再作成します。 古い同期グループが必要ない場合は削除します。
クライアント エージェントに関する情報はどこで見つけることができますか?
クライアント エージェントについてよく寄せられる質問については、エージェントに関する FAQ のセクションを参照してください。
リンクは、使用を開始する前に手動で承認する必要がありますか?
はい。 同期グループのデプロイ中に Azure portal の [プライベート エンドポイント接続] ページで、または PowerShell を使用して、サービス マネージド プライベート エンドポイントを手動で承認する必要があります。
同期ジョブによって Azure データベースがプロビジョニングされているときにファイアウォール エラーが発生するのはなぜですか?
これは、Azure リソースにサーバーへのアクセスが許可されていないことが原因で発生する可能性があります。 以下に示す 2 つのソリューションがあります。
- Azure データベースのファイアウォールで [Azure サービスおよびリソースにこのサーバーへのアクセスを許可する] が [はい] に設定されていることを確実にします。 詳細については、Azure SQL Database およびネットワーク アクセスの制御に関するページを参照してください。
- データ同期のプライベート リンクを構成します。これは、Azure Private Link とは異なります。 Private Link は、ファイアウォールの背後にあるデータベースとのセキュリティで保護された接続を使用して同期グループを作成する方法です。 SQL データ同期 Private Link は Microsoft マネージド エンドポイントであり、既存の仮想ネットワーク内にサブネットを内部的に作成するため、別の仮想ネットワークやサブネットを作成する必要はありません。