仮想コア購入モデル - Azure SQL Database
- Azure SQL Database
- Azure SQL マネージド インスタンス と
この記事では、Azure SQL Database 用の仮想コア購入モデルを確認します。
概要
仮想コア (仮想コア) は論理 CPU を表し、ハードウェアの物理的特性 (コアの数、メモリ、ストレージ サイズなど) を選択するオプションを提供します。 仮想コアベースの購入モデルを使用すると、個々のリソース消費の柔軟性、制御、透明性、オンプレミスのワークロード要件をクラウドに簡単に変換できます。 このモデルでは価格が最適化され、ワークロードのニーズに基づいてコンピューティング、メモリ、ストレージ のリソースを選択できます。
仮想コアベースの購入モデルでは、コストは次の選択と使用によって異なります。
- サービス レベル
- ハードウェア構成
- コンピューティング リソース (仮想コアの数とメモリの量)
- 予約済みデータベース ストレージ
- 実際のバックアップ ストレージ
重要
コンピューティング リソース、I/O、データおよびログ ストレージは、データベースまたはエラスティック プールごとに課金されます。 バックアップ ストレージは、各データベースごとに課金されます。 価格の詳細については、Azure SQL Database の価格ページ
仮想コアと DTU の購入モデルを比較する
Azure SQL Database で使用される仮想コア購入モデルには、DTU ベースの購入モデルよりもいくつかの利点があります。
- コンピューティング、メモリ、I/O、ストレージの上限が高くなります。
- ワークロードのコンピューティングとメモリの要件をより適切に一致させるハードウェア構成の選択。
- Azure ハイブリッド特典 (AHB) の料金割引があります。
- コンピューティングを強化するハードウェアの詳細の透明性が向上し、オンプレミスのデプロイからの移行の計画が容易になります。
- 予約インスタンスの価格 は、仮想コア購入モデルでのみ使用できます。
- 複数のコンピューティング サイズを使用して、より高いスケーリングの粒度を実現します。
仮想コアと DTU の購入モデルの選択に関するヘルプについては、仮想コアベースの購入モデルと DTU ベースの購入モデルの
計算する
仮想コアベースの購入モデルには、プロビジョニングされたコンピューティング レベルと サーバーレス コンピューティング レベルがあります。 プロビジョニングされたコンピューティング レベルでは、コンピューティング コストには、ワークロード アクティビティに関係なく、アプリケーション用に継続的にプロビジョニングされたコンピューティング容量の合計が反映されます。 仮想コアとメモリの要件に基づいてビジネス ニーズに最適なリソース割り当てを選択し、ワークロードで必要に応じてリソースをスケールアップおよびスケールダウンします。 Azure SQL Database のサーバーレス コンピューティング レベルでは、コンピューティング リソースはワークロードの容量に基づいて自動スケーリングされ、1 秒あたりのコンピューティング使用量に対して課金されます。
要約すると、次のようになります。
- プロビジョニング済みコンピューティング レベル では、ワークロード アクティビティとは無関係に継続的にプロビジョニングされる特定の量のコンピューティング リソースが提供されますが、サーバーレス コンピューティング レベル、ワークロード アクティビティに基づいてコンピューティング リソースが自動スケールされます。
- プロビジョンされたコンピューティング層 は、時間あたりの固定価格でプロビジョンされたコンピューティングの容量に対して課金されますが、サーバーレス コンピューティング層 は、秒単位で使用されたコンピューティングの量に対して課金されます。
コンピューティング レベルに関係なく、3 つの追加の高可用性セカンダリ レプリカが Business Critical サービス レベルに自動的に割り当てられ、障害と高速フェールオーバーに対する高い回復性が提供されます。 これらの追加レプリカにより、コストは General Purpose サービス レベルよりも約 2.7 倍高くなります。 同様に、Business Critical サービス レベルの GB あたりのストレージ コストが高いほど、ローカル SSD ストレージの IO 制限が高くなり、待機時間が短くなります。
Hyperscale では、追加の高可用性レプリカの数を 0 から 4 に制御して、コストを制御しながら、アプリケーションに必要な回復性のレベルを取得します。
Azure SQL Database でのコンピューティングの詳細については、コンピューティング リソース (CPU とメモリ)
リソースの制限
仮想コア リソースの制限については、使用可能な ハードウェア構成を確認してから、リソースの制限を確認します。
データストレージとログストレージ
次の要因は、データ ファイルとログ ファイルに使用されるストレージの量に影響し、General Purpose レベルと Business Critical レベルに適用されます。
- 各コンピューティング サイズでは、構成可能な最大データ サイズがサポートされ、既定値は 32 GB です。
- 最大データ サイズを構成すると、ログ ファイルに対して課金対象ストレージの 30% が自動的に追加されます。
- General Purpose サービス レベルでは、
tempdbはローカル SSD ストレージを使用し、このストレージ コストは仮想コアの価格に含まれます。 - Business Critical サービス レベルでは、
tempdbはローカル SSD ストレージをデータ ファイルとログ ファイルと共有し、tempdbストレージ コストは仮想コアの価格に含まれます。 - General Purpose レベルと Business Critical レベルでは、データベースまたはエラスティック プール用に構成された最大ストレージ サイズに対して課金されます。
- SQL Database の場合、1 GB からサポートされているストレージ サイズの最大までの最大データ サイズを 1 GB 単位で選択できます。
Hyperscale には、次のストレージに関する考慮事項が適用されます。
- データ ストレージの最大サイズは 128 TB に設定されており、構成できません。
- 割り当てられたデータ ストレージに対してのみ課金され、最大データ ストレージには課金されません。
- ログ ストレージには課金されません。
tempdbはローカル SSD ストレージを使用し、そのコストは仮想コアの価格に含まれています。 SQL Database で現在割り当て済みと使用済みのデータ ストレージのサイズを監視するには、それぞれ allocated_data_storage と storage の Azure Monitor メトリックを使います。
T-SQL を使用して、データベース内の個々のデータ ファイルとログ ファイルの現在の割り当て済みおよび使用されているストレージ サイズを監視するには、sys.database_files ビューと FILEPROPERTY(... , 'SpaceUsed') 関数を使用します。
ヒント
状況によっては、使用されていない領域を再利用するためにデータベースを圧縮する必要がある場合があります。 詳細については、「Azure SQL Databaseでのファイル領域の管理」を参照してください。
バックアップ ストレージ
データベース バックアップ用のストレージは、SQL Database の ポイントインタイム リストア (PITR) と 長期リテンション期間 (LTR) 機能をサポートするために割り当てられます。 このストレージは、データ とログ ファイルのストレージとは別であり、個別に課金されます。
PITR : General Purpose レベルと Business Critical レベルでは、個々のデータベース バックアップが Azure Storage自動的にコピーされます。 ストレージ サイズは、新しいバックアップが作成されると動的に増加します。 ストレージは、完全バックアップ、差分バックアップ、トランザクション ログ バックアップで使用されます。 ストレージの使用量は、データベースの変更率とバックアップ用に構成されたリテンション期間によって異なります。 SQL Database では、データベースごとに 1 日から 35 日の間に個別の保有期間を構成できます。 構成された最大データ サイズと同じバックアップ ストレージ量は、追加料金なしで提供されます。 - LTR: 完全バックアップの長期保有期間を最大 10 年間構成することもできます。 LTR ポリシーを設定すると、これらのバックアップは Azure Blob Storage に自動的に格納されますが、バックアップのコピー頻度を制御できます。 さまざまなコンプライアンス要件を満たすために、毎週、毎月、または毎年のバックアップに対して異なる保有期間を選択できます。 選択した構成によって、LTR バックアップに使用されるストレージの量が決まります。 詳細については、「長期的なバックアップ保有期間の」を参照してください。
Hyperscale のバックアップ ストレージについては、「Hyperscale データベースの自動バックアップ」を参照してください。
サービス レベル
仮想コア購入モデルのサービス レベル オプションには、General Purpose、Business Critical、Hyperscale が含まれます。 一般に、サービス レベルは、ストレージの種類とパフォーマンス、高可用性とディザスター リカバリーのオプション、および In-Memory OLTP などの特定の機能の可用性を決定します。
| ユース ケース | General Purpose | ビジネスクリティカル | ハイパースケール |
|---|---|---|---|
| 最適な用途 | ほとんどのビジネス ワークロード。 予算指向でバランスのとれたスケーラブルなコンピューティングとストレージのオプションを提供します。 | 複数の高可用性セカンダリ レプリカを使用して、ビジネス アプリケーションに障害に対する最も高い回復性を提供し、最高の I/O パフォーマンスを提供します。 | 拡張性の高いストレージと読み取りスケールの要件を持つワークロードなど、さまざまなワークロード。 複数の高可用性セカンダリ レプリカの構成を許可することで、障害に対するより高い回復性を提供します。 |
| コンピューティング サイズ | 2 ~ 128 個の仮想コア | 2 ~ 128 個の仮想コア | 2 ~ 128 個の仮想コア |
| ストレージの種類 | プレミアム遠隔ストレージ(インスタンスごとに) | 超高速ローカル SSD ストレージ (インスタンスごと) | ローカル SSD キャッシュを使用して切り離されたストレージ (コンピューティング レプリカごと) |
| ストレージ サイズ | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 128 TB |
| IOPS | 仮想コアあたり 320 IOPS、最大 16,000 IOPS | 仮想コアあたり 4,000 IOPS、最大 327,680 IOPS | 最大ローカル SSD で 327,680 IOPS Hyperscale は、複数のレベルでキャッシュを使用する多層アーキテクチャです。 有効な IOPS はワークロードによって異なります。 |
| 仮想コアあたりのメモリ | 5.1 GB | 5.1 GB | 5.1 GB または 10.2 GB |
| バックアップ | geo冗長、ゾーン冗長、またはローカル冗長のバックアップ用ストレージの選択、1〜35日の保持期間(既定は7日間) 最長 10 年間の長期保有期間 |
地理冗長、ゾーン冗長、またはローカル冗長バックアップ ストレージの選択、1~35日間の保持期間(デフォルトは7日間) 最長 10 年間の長期保有期間 |
ローカル冗長 (LRS)、ゾーン冗長 (ZRS)、または geo 冗長 (GRS) ストレージの選択 1 ~ 35 日 (既定では 7 日間) のリテンション期間。最大 10 年間の長期保有期間が利用可能 |
| 可用性 | 1 レプリカ、読み取りスケール レプリカなし、 ゾーン冗長高可用性 (HA) |
3 レプリカ、1 読み取りスケール レプリカ、 ゾーン冗長高可用性 (HA) |
ゾーン冗長高可用性 (HA) |
| 価格設定/請求 | 仮想コア、予約ストレージ、バックアップ ストレージの が課金されます。 IOPS は課金されません。 |
仮想コア、予約ストレージ、バックアップ ストレージの が課金されます。 IOPS は課金されません。 |
各レプリカの 仮想コアと使用されたストレージ が課金対象となります。 IOPS は課金されません。 |
| 割引モデル | 予約インスタンス Azure ハイブリッド特典 (開発/テスト サブスクリプションでは使用できません) Enterprise と開発テスト用の従量課金制プラン オファー サブスクリプション |
予約済みインスタンス Azure ハイブリッド特典 (開発/テスト サブスクリプションでは使用できません) Enterprise と 従量課金制You-Go 開発/テスト プラン サブスクリプション |
Azure ハイブリッド特典 (開発/テスト サブスクリプションでは使用できません) 1 Enterprise と開発テスト用の従量課金制プラン オファー サブスクリプション |
| インメモリ OLTP テーブル | いいえ | はい | なし |
1 SQL Database Hyperscale の簡略化された価格は近日公開予定です。 詳細については、Hyperscale の価格に関するブログ を参照してください。
詳細については、論理サーバー、単一データベース、およびプールされたデータベース のリソース制限を確認します。
手記
サービス レベル アグリーメント (SLA) の詳細については、Azure SQL Database の
General Purpose
General Purpose サービス レベルのアーキテクチャ モデルは、コンピューティングとストレージの分離に基づいています。 このアーキテクチャ モデルは、データベース ファイルを透過的にレプリケートし、基になるインフラストラクチャの障害が発生してもデータ損失を保証する Azure Blob Storage の高可用性と信頼性に依存しています。
次の図は、分離されたコンピューティング レイヤーとストレージ レイヤーを持つ標準アーキテクチャ モデルの 4 つのノードを示しています。
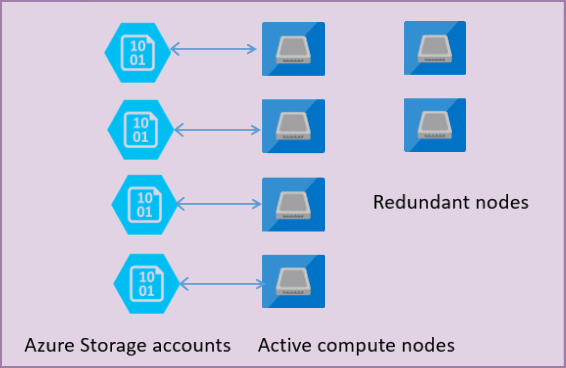
General Purpose サービス レベルのアーキテクチャ モデルには、次の 2 つのレイヤーがあります。
sqlservr.exeプロセスを実行し、一時的なデータとキャッシュされたデータ (プラン キャッシュ、バッファー プール、列ストア プールなど) のみを含むステートレス コンピューティング レイヤー。 このステートレス ノードは、プロセスを初期化し、ノードの正常性を制御し、必要に応じて別の場所へのフェールオーバーを実行する Azure Service Fabric によって動作します。- Azure Blob Storage に格納されているデータベース ファイル (.mdf/.ldf) を含むステートフル データ レイヤー。 Azure Blob Storage は、データベース ファイルに配置されたレコードのデータ損失がないことを保証します。 Azure Storage には、データの可用性と冗長性が組み込まれているため、プロセスがクラッシュした場合でも、ログ ファイルまたはデータ ファイル内のページ内のすべてのレコードが確実に保持されます。
データベース エンジンまたはオペレーティング システムがアップグレードされるたびに、基になるインフラストラクチャの一部が失敗したり、sqlservr.exe プロセスで重大な問題が検出された場合、Azure Service Fabric はステートレス プロセスを別のステートレス コンピューティング ノードに移動します。 フェールオーバー時間を最小限に抑えるためにプライマリ ノードのフェールオーバーが発生した場合、新しいコンピューティング サービスの実行を待機している予備ノードのセットがあります。 Azure Storage レイヤー内のデータは影響を受けず、データ/ログ ファイルは新しく初期化されたプロセスにアタッチされます。 この仕組みにより、デフォルトで99.99%の可用性が保証され、ゾーン冗長が有効になっている場合は99.995%の可用性が保証されます。 移行時間と新しいノードがコールド キャッシュで始まるという事実により、実行中の負荷の高いワークロードにパフォーマンスへの影響が生じる可能性があります。
このサービス レベルを選択するタイミング
General Purpose サービス レベルは、ほとんどの汎用ワークロード用に設計された Azure SQL Database の既定のサービス レベルです。 既定の SLA とストレージ待機時間が 5 ミリ秒から 10 ミリ秒のフル マネージド データベース エンジンが必要な場合は、General Purpose レベルが最適です。
業務に不可欠
Business Critical サービス レベル モデルは、データベース エンジン プロセスのクラスターに基づいています。 このアーキテクチャ モデルは、メンテナンス アクティビティ中でも、ワークロードへのパフォーマンスへの影響を最小限に抑えるために、データベース エンジン ノードのクォーラムに依存します。 基になるオペレーティング システム、ドライバー、データベース エンジンのアップグレードとパッチは透過的に実行され、エンド ユーザーのダウンタイムは最小限に抑えられます。
Business Critical モデルでは、コンピューティングとストレージが各ノードに統合されます。 4 ノード クラスターの各ノード上のデータベース エンジン プロセス間でのデータのレプリケーションは高可用性を実現し、各ノードはローカルに接続された SSD をデータ ストレージとして使用します。 次の図は、Business Critical サービス レベルが可用性グループ レプリカ内のデータベース エンジン ノードのクラスターを整理する方法を示しています。

データベース エンジン プロセスと基になる .mdf/.ldf ファイルの両方が、ローカルに接続された SSD ストレージを持つ同じノードに配置されるため、ワークロードの待機時間が短くなります。 高可用性は、SQL Server Always On 可用性グループと同様のテクノロジを使用して実装されます。 すべてのデータベースは、お客様のワークロードに対してアクセスできる 1 つのプライマリ レプリカと、データのコピーを含む 3 つのセカンダリ レプリカを持つデータベース ノードのクラスターです。 プライマリ レプリカは、何らかの理由でプライマリが失敗した場合にセカンダリ レプリカでデータを使用できるように、常にセカンダリ レプリカに変更をプッシュします。 フェールオーバーは Service Fabric とデータベース エンジンによって処理されます。1 つのセカンダリ レプリカがプライマリになり、クラスターに十分なノードがあることを確認するために新しいセカンダリ レプリカが作成されます。 ワークロードは、新しいプライマリ レプリカに自動的にリダイレクトされます。
さらに、Business Critical クラスターには、プライマリ レプリカのワークロードのパフォーマンスに影響を与えない読み取り専用クエリ (レポートなど) の実行に使用される無料の読み取り専用レプリカを提供する、読み取りスケールアウト 機能が組み込まれています。
このサービス レベルを選択するタイミング
Business Critical サービス レベルは、基になる SSD ストレージからの待機時間の短い応答 (平均で 1 ~ 2 ミリ秒) を必要とするアプリケーション向けに設計されています。また、基になるインフラストラクチャで障害が発生した場合の復旧速度が向上します。また、プライマリ データベースの読み取り可能なセカンダリ レプリカにレポート、分析、読み取り専用のクエリを無料で読み込む必要があるアプリケーション向けに設計されています。
General Purpose レベルではなく Business Critical サービス レベルを選択する主な理由は次のとおりです。
- 低 I/O 待機時間の要件 – ストレージ 層からの一貫して高速な応答を必要とするワークロード (平均で 1 ~ 2 ミリ秒) は、Business Critical レベルを使用する必要があります。
- レポートクエリと分析クエリを使用するワークロード、1 つの無料のセカンダリ読み取り専用レプリカで十分です。
- 回復性が向上し、障害からの復旧が速。 システム障害が発生した場合、プライマリ インスタンス上のデータベースは無効になり、セカンダリ レプリカの 1 つが新しい読み取り/書き込みプライマリ データベースになり、クエリを処理する準備が整います。
- 高度なデータ破損保護。 Business Critical レベルではバックグラウンドでデータベース レプリカが使用されるため、このサービスでは、データの破損を軽減するために
ミラーリングと可用性グループで使用可能な自動ページ修復が使用されます。 データの整合性の問題が原因でレプリカがページを読み取ることができない場合、ページの新しいコピーが別のレプリカから取得され、読み取り不可能なページがデータ損失や顧客のダウンタイムなしで置き換えられます。 この機能は、データベースに geo セカンダリ レプリカがある場合に General Purpose レベルで使用できます。 - 高可用性 - マルチ可用性ゾーン構成の Business Critical レベルは、ゾーン障害に対する回復性と高可用性 SLA を提供します。
- 高速 geo リカバリー - アクティブ geo レプリケーションが構成された Business Critical レベルでは、100% のデプロイ時間に対して、5 秒の回復ポイントの目標 (RPO) と 30 秒の回復時間の目標 (RTO) が保証されています。
ハイパースケール
Hyperscale サービス レベルは、すべてのワークロードの種類に適しています。 そのクラウド ネイティブ アーキテクチャは、従来および最新のアプリケーションの多種多様をサポートするために、個別にスケーラブルなコンピューティングとストレージを提供します。 Hyperscale のコンピューティング リソースとストレージ リソースは、General Purpose レベルと Business Critical レベルで使用可能なリソースを大幅に超えています。
詳細については、Azure SQL Databaseの Hyperscale サービス レベル
このサービス レベルを選択するタイミング
Hyperscale サービス レベルでは、クラウド データベースで従来見られる実際的な制限の多くが削除されます。 他のほとんどのデータベースが 1 つのノードで使用可能なリソースによって制限されている場合、Hyperscale サービス レベルのデータベースにはそのような制限はありません。 柔軟なストレージ アーキテクチャにより、Hyperscale データベースは必要に応じて拡張され、使用したストレージ容量に対してのみ課金されます。
Hyperscale は、高度なスケーリング機能に加えて、大規模なデータベースだけでなく、あらゆるワークロードに最適なオプションです。 Hyperscale では、次のことができます。
- 高可用性レプリカ 0 から 4 の数を選択して、コストを制御しながら、高い回復性と迅速な障害復旧 を実現します。
- コンピューティングとストレージ ゾーン冗長性を有効にすることで、高可用性 を向上させます。
- データベースの頻繁にアクセスされる部分に対して低 I/O 待ち時間 (平均 1 - 2 ミリ秒) を実現します。 小規模なデータベースの場合、これはデータベース全体に適用される場合があります。
- 名前付きレプリカを使用して、さまざまな読み取りスケールアウト シナリオを実装します。
- 新しいノードでローカルストレージにデータがコピーされるのを待たずに、の高速スケーリング
を活用してください。 ゼロインパクトの継続的なデータベースバックアップ と高速復元をご利用ください。 - フェールオーバー グループと geo レプリケーションを使用して ビジネス継続性 要件をサポートします。
ハードウェア構成
仮想コア モデルの一般的なハードウェア構成には、Standard シリーズ (Gen5)、Fsv2 シリーズ、DC シリーズがあります。 Hyperscale には、Premium シリーズと Premium シリーズのメモリ最適化ハードウェアのオプションも用意されています。 ハードウェア構成では、コンピューティングとメモリの制限、およびワークロードのパフォーマンスに影響を与えるその他の特性を定義します。
Standard シリーズ (Gen5) などの特定のハードウェア構成では、コンピューティング リソース (CPU とメモリ)で説明されているように、複数の種類のプロセッサ (CPU) を使用できます。 特定のデータベースまたはエラスティック プールは、同じ CPU の種類を持つハードウェア上に長時間 (通常は数か月間) 存在する傾向がありますが、データベースまたはプールが別の CPU の種類を使用するハードウェアに移動される可能性がある特定のイベントがあります。
データベースまたはプールは、次のようなさまざまなシナリオで移動できます。
- サービス目標が変更されました
- データセンター内の現在のインフラストラクチャが容量制限に近づいている
- 現在使用されているハードウェアは、寿命が終了したため使用停止中です
- ゾーン冗長構成が有効になっており、使用可能な容量が原因で別のハードウェアに移動する
一部のワークロードでは、異なる CPU の種類への移行によってパフォーマンスが変わる可能性があります。 SQL Database は、CPU の種類が変化しても予測可能なワークロード パフォーマンスを提供し、パフォーマンスの変化を狭い帯域内で維持することを目的としてハードウェアを構成します。 ただし、SQL Database のさまざまなお客様のワークロードで、新しい種類の CPU が使用可能になると、データベースまたはプールが別の CPU の種類に移行した場合に、パフォーマンスがより顕著に変化する可能性があります。
使用される CPU の種類に関係なく、データベースまたはエラスティック プールのリソース制限 (コア数、メモリ、最大データ IOPS、最大ログ レート、最大同時ワーカー数など) は、データベースが同じサービス目標にとどまっている限り変わりません。
コンピューティング リソース (CPU とメモリ)
次の表では、さまざまなハードウェア構成とコンピューティング レベルのコンピューティング リソースを比較します。
| ハードウェア構成 | CPU | 記憶 |
|---|---|---|
| Standard シリーズ (Gen5) | プロビジョニング済みコンピューティング - Intel® E5-2673 v4 (Broadwell) 2.3 GHz、Intel® SP-8160 (Skylake)*、Intel® 8272CL (Cascade Lake) 2.5 GHz*、Intel® Xeon® Platinum 8370C (Ice Lake)*、AMD EPYC 7763v (ミラノ) プロセッサ - 最大 128 個の仮想コアをプロビジョニングする (ハイパースレッド) サーバーレス コンピューティング - Intel® E5-2673 v4 (Broadwell) 2.3 GHz、Intel® SP-8160 (Skylake)*、Intel® 8272CL (Cascade Lake) 2.5 GHz*、Intel® Xeon® Platinum 8370C (Ice Lake)*、AMD EPYC 7763v (ミラノ) プロセッサ - 最大 80 個の仮想コアを自動スケーリング (ハイパースレッド) - メモリと仮想コアの比率は、ワークロードの需要に基づいてメモリと CPU 使用率に動的に適応し、仮想コアあたり最大 24 GB にすることができます。 たとえば、特定の時点でワークロードが使用し、240 GB のメモリと 10 個の仮想コアに対してのみ課金される場合があります。 |
プロビジョニング済みコンピューティング - 仮想コアあたり 5.1 GB - 最大 625 GB をプロビジョニングする サーバーレス コンピューティング - 仮想コアあたり最大 24 GB の自動スケール - 最大 240 GB まで自動スケール |
| Fsv2 シリーズ | - Intel® 8168 (Skylake) プロセッサ - 3.4 GHz のすべてのコア ターボ クロック速度と 3.7 GHz の最大シングル コア ターボ クロック速度を備えています。 - 最大 72 個の仮想コアをプロビジョニングする (ハイパースレッド) |
- 仮想コアあたり 1.9 GB - 最大 136 GB のプロビジョニング |
| DC シリーズ | - Intel® Xeon® E-2288G プロセッサ インテルのソフトウェアガード拡張機能 (Intel SGX) を特徴とする - 最大 8 個の仮想コアをプロビジョニングする (物理) |
仮想コアあたり 4.5 GB |
* sys.dm_user_db_resource_governance 動的管理ビューでは、Intel® SP-8160 (Skylake) プロセッサを使用するデータベースのハードウェア生成は Gen6 として表示され、Intel® 8272CL (Cascade Lake) を使用するデータベースのハードウェア生成は Gen7 として表示され、Intel® Xeon® Platinum 8370C (Ice Lake) または AMD® EPYC® 7763v (ミラノ) を使用するデータベースのハードウェア世代は Gen8 と表示されます。 特定のコンピューティング サイズとハードウェア構成では、リソースの制限は CPU の種類 (Intel Broadwell、Skylake、Ice Lake、Cascade Lake、AMD Milan) に関係なく同じです。
詳細については、エラスティック プール
Hyperscale データベースのコンピューティング リソースと仕様については、hyperscale コンピューティング リソース に関するページを参照してください。
Standard シリーズ (Gen5)
- Standard シリーズ (Gen5) ハードウェアは、バランスの取れたコンピューティング リソースとメモリ リソースを提供し、ほとんどのデータベース ワークロードに適しています。
Standard シリーズ (Gen5) ハードウェアは、世界中のすべてのパブリック リージョンで利用できます。
Hyperscale Premium シリーズ
- Premium シリーズのハードウェア オプションでは、Intel と AMD の最新の CPU およびメモリ テクノロジが使用されます。 Premium シリーズは、Standard シリーズ ハードウェアに対するコンピューティング パフォーマンスを向上させます。
- Premium シリーズ オプションを使用すると、Standard シリーズに比べて CPU パフォーマンスが向上し、仮想コアの最大数が多くなります。
- Premium シリーズのメモリ最適化オプションでは、Standard シリーズに比べて 2 倍のメモリ量が提供されます。
- スタンダード シリーズ、プレミアム シリーズ、メモリ最適化を備えたプレミアム シリーズは、ハイパースケール エラスティック プール
で使用できます。
詳細については、Hyperscale Premium シリーズのブログ発表を参照してください。
利用可能なリージョンについては、Hyperscale Premiumシリーズの可用性を参照してください。
Fsv2 シリーズ
- Fsv2 シリーズは、コンピューティング最適化されたハードウェア構成であり、CPU の要求が最も厳しいワークロードに対して低い CPU 待機時間と高クロック速度を実現します。 Hyperscale Premium シリーズの ハードウェア構成と同様に、Fsv2 シリーズには Intel と AMD の最新の CPU とメモリ テクノロジが搭載されており、お客様は General Purpose サービス レベルでデータベースとエラスティック プールを使用しながら、最新のハードウェアを利用できます。
- Fsv2 シリーズは、ワークロードに応じて、他の種類のハードウェアよりも仮想コアあたりの CPU パフォーマンスを向上させることができます。 たとえば、72 仮想コア Fsv2 コンピューティング サイズを使用すると、Standard シリーズ (Gen5) では 80 個を超える CPU パフォーマンスを低コストで実現できます。
- Fsv2 では、仮想コアあたりのメモリと
tempdbが他のハードウェアよりも少ないため、これらの制限に敏感なワークロードは Standard シリーズ (Gen5) でパフォーマンスが向上する可能性があります。
General Purpose レベルでのみサポートされる Fsv2 シリーズ。 Fsv2 シリーズが使用可能なリージョンについては、Fsv2 シリーズの可用性
DC シリーズ
- DC シリーズハードウェアは、ソフトウェア ガード拡張機能 (Intel SGX) テクノロジを備えた Intel プロセッサを使用します。
- 仮想化ベースのセキュリティ (VBS) エンクレーブと比べて、ハードウェア エンクレーブのセキュリティ保護を強化する必要がある、セキュリティ エンクレーブを使用する Always Encrypted ワークロードでは、DC シリーズが必要です。
- DC シリーズは、機密データを処理し、セキュリティで保護されたエンクレーブを備えた Always Encrypted によって提供される機密クエリ処理機能を要求するワークロード向けに設計されています。
- DC シリーズ ハードウェアは、バランスの取れたコンピューティング リソースとメモリ リソースを提供します。
DC シリーズは、プロビジョニングされたコンピューティングでのみサポートされており (サーバーレスはサポートされていません)、ゾーンの冗長性はサポートされません。 DC シリーズが使用可能なリージョンについては、DC シリーズの可用性
DC シリーズでサポートされる Azure オファーの種類
DC シリーズ ハードウェア上にデータベースまたはエラスティック プールを作成するには、サブスクリプションは従量課金制You-Go プランまたは Enterprise Agreement (EA) を含む有料プランの種類である必要があります。 DC シリーズでサポートされている Azure オファーの種類の完全な一覧については、使用制限のない現在のオファーを参照してください。
ハードウェア構成の選択
作成時に SQL Database のデータベースまたはエラスティック プールのハードウェア構成を選択できます。 既存のデータベースまたはエラスティック プールのハードウェア構成を変更することもできます。
SQL Database またはプール を作成するときにハードウェア構成を選択するには
詳細については、「SQL Databaseの作成」を参照してください。
[の基本] タブの [コンピューティングとストレージの] セクションで [データベース の構成] リンクを選択し、[構成 の変更] リンクを選択します。
![Azure portal の [構成] ページの [SQL Database のデプロイの作成] のスクリーンショット。[構成の変更] ボタンが強調表示されています。](media/service-tiers-sql-database-vcore/configure-sql-database.png?view=azuresql#lightbox)
目的のハードウェア構成を選択します。
![Azure SQL データベースの [SQL ハードウェア構成] ページの Azure portal のスクリーンショット。](media/service-tiers-sql-database-vcore/select-hardware.png?view=azuresql#lightbox)
既存の SQL Database またはプール のハードウェア構成を変更するには
データベースの場合、[概要] ページで、価格レベルの リンクを選択します。

プールについては、[の概要] ページで、[構成]を選択します。
構成を変更する手順に従い、前の手順で説明したようにハードウェア構成を選択します。
ハードウェアの可用性
前の世代のハードウェアの詳細については、「以前の世代のハードウェアの可用性を参照してください。
Standard シリーズ (Gen5)
Standard シリーズ (Gen5) ハードウェアは、世界中のすべてのパブリック リージョンで利用できます。
Hyperscale Premium シリーズ
Hyperscale サービス レベルの Premium シリーズおよび Premium シリーズのメモリ最適化ハードウェアは、次のリージョンの単一データベースとエラスティック プールで使用できます。
- オーストラリア東部 **
- オーストラリア南東部
- ブラジル南部 **,*
- カナダ中部 **
- カナダ東部
- 東アジア
- ヨーロッパ北部 **
- ヨーロッパ西部 **
- フランス中部
- ドイツ中西部
- インド中部
- インド南部
- 東日本 **
- 西日本
- 東南アジア**
- スイス北部
- スウェーデン中部 **,*
- 英国南部 **
- 英国西部 *
- 米国中部 **
- 米国東部 **
- 米国東部 2 **
- 米国中北部
- 米国中南部
- 米国中西部
- 米国西部 1
- 米国西部 2 **
- 米国西部 3 **
* Premium シリーズのメモリ最適化ハードウェアは現在使用できません。
** ゾーン冗長のサポートが含まれています。
Fsv2 シリーズ
Fsv2 シリーズは、次のリージョンで利用できます。
- オーストラリア中部
- オーストラリア中部 2
- オーストラリア東部
- オーストラリア南東部
- ブラジル南部
- カナダ中部
- 東アジア
- ヨーロッパ北部
- ヨーロッパ西部
- フランス中部
- インド中部
- 韓国中部
- 韓国南部
- 南アフリカ北部
- 東南アジア
- 英国南部
- 英国西部
- 米国東部
- 米国西部 2
DC シリーズ
DC シリーズは、次のリージョンで利用できます。
- カナダ中部
- ヨーロッパ西部
- ヨーロッパ北部
- 東南アジア
- 英国南部
- 米国西部
- 米国東部
現在サポートされていないリージョンで DC シリーズが必要な場合は、サポート リクエスト送信
- [問題の種類] で、[技術] を選択します。
- ハードウェアの目的のサブスクリプションを指定します。 を選択して次に
- サービスの種類で、SQL Databaseを選択します。
- リソースで [全般質問]を選択します。
- 概要の場合は、目的のハードウェアの可用性とリージョンを指定します。
- [問題の種類]
で、[セキュリティ]、[プライベート]、[コンプライアンス] 選択します。 - [問題のサブタイプ] で [Always Encrypted] を選択します。

以前の世代のハードウェア
Gen4
Gen4 ハードウェアは廃止され、プロビジョニング、アップスケール、ダウンスケールには使用できません。 より広範な仮想コアとストレージのスケーラビリティ、高速ネットワーク、最適な IO パフォーマンス、および最小限の待機時間を実現するために、サポートされているハードウェア世代にデータベースを移行します。 単一データベース のためのハードウェア オプション