Azure SQL Database でのリソース管理
適用対象:![]() Azure SQL データベース
Azure SQL データベース
この記事では、Azure SQL Database でのリソース管理の概要を示します。 リソース制限が上限に達した場合の動作に関する情報を示すと共に、これらの制限の適用に利用されるリソース ガバナンスのメカニズムについて説明します。
単一データベースの価格レベルごとの特定のリソース制限については、次のいずれかを参照してください。
エラスティック プールのリソース制限については、次のいずれかを参照してください。
Azure Synapse Analytics の専用 SQL プールの制限については、以下を参照してください。
サブスクリプション リージョンごとの仮想コアの制限
2024 年 3 月以降、サブスクリプションには、各リージョンにおける各サブスクリプションあたりの仮想コア制限が以下のように定められます。
| サブスクリプション タイプ | 既定の仮想コア制限 |
|---|---|
| Enterprise Agreement (EA) | 2000 |
| 無料試用版 | 10 |
| Microsoft for startups | 100 |
| MSDN / MPN / Imagine / AzurePass / Azure for Students | 40 |
| 従量課金制 (PAYG) | 150 |
次の点について検討してください。
- これらの制限は、新規および既存のサブスクリプションに適用されます。
- DTU 購入モデルで、プロビジョニングされたデータベースやエラスティック プールは、仮想コア クォータとしてもカウントされます。仮想コア購入モデルの場合でも同様です。 消費される各仮想コアは、サーバー レベルのクォータで消費される 100 DTU に相当するとみなされます。
- 既定の制限には、プロビジョニングされたコンピューティング データベース/エラスティック プール用に構成された仮想コアと、サーバーレス データベース用に構成
最大仮想コア の両方が含まれます。 - Subscription Usages - Get REST API 呼び出しを使用して、お使いのサブスクリプションの現在の仮想コア使用状況を確認できます。
- 既定よりも高い仮想コア クォータを要求するには、Azure portal で新しいサポート要求を送信します。 詳細については、「Azure SQL Database と SQL Managed Instanceのクォータの引き上げを要求する」を参照してください。
論理サーバーの制限
| リソース | 制限 |
|---|---|
| 論理サーバーあたりのデータベース | 5000 |
| 1 つのリージョンにおけるサブスクリプションあたりの既定の論理サーバー数 | 250 |
| 1 つのリージョンにおけるサブスクリプションあたりの最大の論理サーバー数 | 250 |
| 論理サーバーあたりの最大エラスティック プール | DTU または仮想コアの数によって制限されます。 たとえば、各プールが 1000 DTU の場合、1 つのサーバーで 54 プールをサポートできます。 |
重要
データベースの数が論理サーバーあたりの制限に近づくと、次の状況が発生する可能性があります。
-
masterデータベースに対して実行するクエリの待機時間が増えます。 これには、sys.resource_statsなど、リソース使用率統計情報のビューも含まれます。 - サーバー内のデータベースの列挙を要する、管理操作やポータル ビュー ポイント表示の待機時間が長くなります。
リソースが制限に達したときの影響
コンピューティングの CPU
データベース コンピューティングの CPU 使用率が高くなると、クエリの待機時間が長くなり、クエリがタイムアウトすることさえあります。このような状況下では、クエリはサービスによってキューに格納される場合があり、リソースが空くと実行用のリソースが提供されます。
高いコンピューティング使用率が発生した場合、次のような軽減オプションがあります。
- データベースまたエラスティック プールのコンピューティング サイズを上げて、より多くのコンピューティング リソースをデータベースに提供します。 シングルトンのリソースの拡大縮小に関する記事と、エラスティック プールのリソースの拡大縮小に関する記事を参照してください。
- クエリを最適化して、各クエリの CPU リソース使用率を引き下げます。 詳しくは、「クエリの調整とヒント」をご覧ください。
ストレージ
使用されるデータ領域がデータベース レベルまたはエラスティック プール レベルの最大データ サイズ制限に達すると、データ サイズを増やす挿入と更新が失敗し、クライアントは
Premium および Business Critical サービス レベルでは、単一のデータベースまたはエラスティック プールについて、データ、トランザクション ログ、および tempdb によるストレージ使用量の合計が最大ローカル ストレージ サイズを超えた場合にも、クライアントはエラー メッセージを受け取ります。 詳細については、「ストレージ スペースのガバナンス」を参照してください。
高い記憶域スペースの使用率が発生した場合、次のような軽減オプションがあります。
- データベースまたはエラスティック プールの最大データ サイズを増やすか、最大データ サイズの上限が高いサービス目標にスケールアップします。 シングルトンのリソースの拡大縮小に関する記事と、エラスティック プールのリソースの拡大縮小に関する記事を参照してください。
- データベースがエラスティック プール内にある場合は、もう 1 つの方法として、データベースをプールの外に移動し、ストレージ領域が他のデータベースと共有されないようにすることもできます。
- 未使用領域を再利用できるようにデータベースを縮小します。 詳細については、「データベースのファイル領域を管理する」を参照してください。
- エラスティック プールでは、データベースを圧縮することで、プール内の他のデータベースのストレージを増やすことができます。
- 高い領域使用率が、永続的なバージョン ストア (PVS) のサイズの急増によるものかどうかを確認します。 PVS は各データベースの一部であり、高速データベース復旧
実装するために使用されます。 現在の PVS サイズを確認するには、「高速データベース復旧 のトラブルシューティングを参照してください。 PVS サイズが大きい一般的な理由は、トランザクションが長時間 (数時間) にわたって開いているために、PVS での古いバージョンの行のクリーンアップが妨げられるためです。 - 大量のストレージを消費する、Premium および Business Critical サービス レベルのデータベースおよびエラスティック プールの場合、データベースまたはエラスティック プールの使用領域が最大データ サイズの上限を下回っている場合でも、領域不足エラーが発生することがあります。 これは、
tempdbまたはトランザクション ログ ファイルが大量のストレージを消費し、ローカル ストレージの上限に近づいた場合に発生する可能性があります。 データベースまたはエラスティック プールをフェールオーバーして、tempdbを初期の小さいサイズにリセットするか、トランザクション ログを圧縮してローカル ストレージの使用量を減らします。
セッション、ワーカー、要求
セッション、ワーカー、要求は次のように定義されます。
- セッションとは、データベース エンジンに接続されているプロセスを表します。
- 要求とは、クエリまたはバッチを論理的に表したものです。 要求は、セッションに接続されたクライアントによって発行されます。 時間が経つにつれて、同じセッションで複数の要求が発行される可能性があります。
- ワーカー スレッドは、ワーカーまたはスレッドとも呼ばれ、オペレーティング システムのスレッドを論理的に表したものです。 並列クエリ実行プランで実行される要求には多数のワーカーが含まれ、直列 (シングル スレッド) 実行プランで実行される要求には 1 つのワーカーが含まれる可能性があります。 ワーカーは、要求以外のアクティビティをサポートするためにも必要です。たとえば、セッションの接続時にログイン要求を処理するには、ワーカーが必要です。
これらの概念の詳細については、「スレッドとタスクのアーキテクチャ ガイド」を参照してください。
worker の最大数は、サービス レベルとコンピューティング サイズによって決まります。 セッションまたはワーカーが上限に達した場合、新しい要求は拒否され、クライアントはエラー メッセージを受け取ります。 接続数はアプリケーションで制御できますが、同時 worker の数は、多くの場合、推定と制御が困難です。 クエリを長時間実行したため、ブロッキング チェーンの規模が大きいため、またはクエリの並行が過剰になっているために、データベース リソースが上限に達してワーカーが滞留している場合のピーク負荷期間には、これは特に当てはまります。
注意
初期の Azure SQL Database では、シングル スレッド クエリのみがサポートされていました。 そのときは、要求の数は常にワーカーの数と同じでした。 Azure SQL データベースのエラー メッセージ 10928 には、下位互換性のみを目的とした文言 The request limit for the database is *N* and has been reached が含まれています。 制限に達したのは、実際にはワーカーの数です。
並列処理の最大度 (MAXDOP) の設定値が 0 または 1 より大きい場合、ワーカーの数は要求の数よりもはるかに多くなる可能性があり、MAXDOP が 1 の場合よりもはるかに早く制限に達することがあります。
- エラー 10928 の詳細については、「リソース ガバナンス エラー」を参照してください。
- エラー 10928 と 10936 の 要求制限の枯渇の詳細について説明します。
次の方法で、ワーカーまたはセッションの制限に近づく可能性や制限に達する可能性を軽減できます。
- データベースまたはエラスティック プールのサービス レベルまたはコンピューティング サイズを高くします。 シングルトンのリソースの拡大縮小に関する記事と、エラスティック プールのリソースの拡大縮小に関する記事を参照してください。
- コンピューティング リソースの競合によってワーカーが増加している場合は、クエリを最適化して各クエリのリソース使用率を下げます。 詳しくは、「クエリの調整とヒント」をご覧ください。
- クエリのワークロードを最適化して、発生回数とクエリ ブロックの時間を削減します。 詳細については、「ブロックの問題を理解して解決する」を参照してください。
- 必要に応じて MAXDOP の設定値を減らします。
サービス レベルとコンピューティング サイズごとに Azure SQL Database のワーカーとセッションの制限を確認してください。
- 仮想コア購入モデルを使用した単一データベースに対するリソース制限
- 仮想コア購入モデルを使用したエラスティック プールに対するリソース制限
- DTU 購入モデルを使用した単一データベースに対するリソース制限
- DTU 購入モデルを使用したエラスティック プールのリソース制限
セッションまたはワーカーの制限に関する特定のエラーのトラブルシューティングの詳細については、「リソース ガバナンス エラー」を参照してください。
外部接続
sp_invoke_external_rest_endpoint 経由で行われる外部エンドポイントへのコンカレント接続の数はワーカー スレッドの 10% に制限され、ハード キャップは最大 150 ワーカーです。
[メモリ]
他のリソース (CPU、ワーカー、ストレージ) とは異なり、メモリ制限に達してもクエリのパフォーマンスに悪影響は及ばず、エラーやエラーは発生しません。 メモリ管理アーキテクチャ ガイドで詳しく説明されているように、データベース エンジンでは、多くの場合、使用可能なすべてのメモリが設計によって使用されます。 メモリは主にデータをキャッシュするために使用され、速度の遅いストレージ アクセスが回避されます。 そのため、メモリ使用率が高いと、通常、クエリのパフォーマンスが向上します。これは、読み取りの遅いストレージではなく、読み取りの速いメモリが使用されるからです。
データベース エンジンが起動した後、ワークロードでストレージからデータの読み取りを開始すると、データベース エンジンにより、データが積極的にメモリにキャッシュされます。 この初期起動期間が経過すると、「avg_memory_usage_percent」の「avg_instance_memory_percent」と「」列が表示され、sql_instance_memory_percent Azure Monitor メトリックが 100% に近く達することが一般的であり、予想されます(特にアイドル状態ではなく、メモリに完全に収まらないデータベースの場合)。
注意
sql_instance_memory_percent メトリックは、データベース エンジンの合計メモリ消費量が反映されます。 このメトリックは、高い強度のワークロードが実行されている場合でも 100% に達しない可能性があります。 これは、使用可能なメモリのごく一部が、スレッド スタックや実行可能モジュールなど、データ キャッシュ以外の重要なメモリ割り当て用に確保されているためです。
データ キャッシュ以外にも、データベース エンジンの他のコンポーネントでメモリが使用されます。 メモリの需要があり、使用可能なすべてのメモリがデータ キャッシュによって使用されている場合、データベース エンジンでは、他のコンポーネントがメモリを使用できるようにデータ キャッシュ サイズが動的に削減され、他のコンポーネントでメモリが解放されると、データ キャッシュが動的に拡大されます。
まれに、十分に負荷の高いワークロードが原因でメモリ不足状態が発生し、メモリ不足エラーになることがあります。 メモリ不足エラーは 0% から 100% までのどのレベルでも発生する可能性があります。 メモリ不足エラーは、コンピューティング サイズが小さく、メモリ制限が相対的に小さい場合や、クエリ処理により多くのメモリを使用するワークロード (高密度エラスティック プールなど) で発生する可能性が高くなります。
メモリ不足エラーが発生した場合、次のような軽減オプションがあります。
- sys.dm_os_out_of_memory_events で OOM 条件の詳細を確認します。
- データベースまたはエラスティック プールのサービス レベルまたはコンピューティング サイズを高くします。 シングルトンのリソースの拡大縮小に関する記事と、エラスティック プールのリソースの拡大縮小に関する記事を参照してください。
- クエリと構成を最適化して、メモリ使用率を引き下げます。 一般的な解決策について次の表で説明します。
| 解決策 | 説明 |
|---|---|
| メモリ許可のサイズを小さくする | メモリ許可の詳細については、SQL Server メモリ許可の概要に関するブログ記事をご覧ください。 過度に大きなメモリ許可を回避する一般的な解決策は、統計 互換性レベル 140 以降が使用されているデータベースでは、データベース エンジンにより、既定で バッチ モード メモリ許可フィードバックを使用したメモリ許可サイズの自動調整が行われる可能性があります。 同様に、互換性レベル 150 以上を使用しているデータベースでは、データベース エンジンは、より一般的な行モードのクエリについて、行モード メモリ許可フィードバックも使用します。 この組み込み機能を使用すると、大規模なメモリ許可が原因のメモリ不足エラーを回避できます。 |
| クエリ プラン キャッシュのサイズを小さくする | クエリの実行ごとにクエリ プランがコンパイルされないように、データベース エンジンにより、クエリ プランがメモリ内にキャッシュされます。 1 回だけ使用されるキャッシュ プランが原因でクエリ プランのキャッシュが大きくなるのを避けるには、必ずパラメーター化されたクエリを使用し、OPTIMIZE_FOR_AD_HOC_WORKLOADS データベース スコープの構成を有効にすることを検討してください。 |
| ロック メモリのサイズを小さくする | データベース エンジンにより、ロックにメモリが使用されます。 可能であれば、大量のロックを取得し、ロック メモリの消費量が高くなる可能性のある大きなトランザクションは避けてください。 |
ユーザー ワークロードと内部プロセスによるリソース使用量
Azure SQL Database には、高可用性とディザスター リカバリー、データベースのバックアップと復元、監視、クエリ ストア、自動チューニングなどの中核的なサービス機能を実装するための、コンピューティング リソースが必要です。システムでは、リソース ガバナンス メカニズムを使用して、これらの内部プロセス用にリソース全体の限られた部分が確保されます。これにより、ユーザーのワークロードで残りのリソースを使用できるようになります。 内部プロセスでコンピューティング リソースが使用されていない場合は、システムによってユーザーのワークロードで使用できるようになります。
ユーザー ワークロードと内部プロセスによる CPU とメモリの使用量の合計は、sys.dm_db_resource_stats および sys.resource_stats ビューの avg_instance_cpu_percent 列と avg_instance_memory_percent 列で報告されます。 このデータは、sql_instance_cpu_percentおよびプール レベルのsql_instance_memory_percentについて、 および Azure Monitor メトリックによって報告されます。
注意
sql_instance_cpu_percent と sql_instance_memory_percent の Azure Monitor のメトリックは、2023 年 7 月以降に使用できます。 これらは、以前に使用可能な sqlserver_process_core_percent メトリックと sqlserver_process_memory_percent メトリックと完全に同等です。 後者の 2 つのメトリックは引き続き使用できますが、今後削除される予定です。 データベース監視の中断を回避するには、古いメトリックを使用しないでください。
これらのメトリックは、Basic、S1、S2 サービス目標を使用するデータベースでは使用できません。 同じデータは、以下の動的管理ビューで使用できます。
各データベースのユーザー ワークロードによる CPU とメモリの使用量は、sys.dm_db_resource_stats および sys.resource_stats ビューの avg_cpu_percent 列と avg_memory_usage_percent 列で報告されます。 エラスティック プールの場合、プール レベルのリソース消費量は、(履歴レポート シナリオの場合は) sys.elastic_pool_resource_stats ビュー、およびリアルタイム監視の場合は sys.dm_elastic_pool_resource_stats で報告されます。 ユーザー ワークロードの CPU 消費量は、cpu_percentおよびプール レベルのエラスティック プールについて、 Azure Monitor メトリックによって報告されます。
ユーザー ワークロードと内部プロセスによる最近のリソース消費の詳細な内訳は、sys.dm_resource_governor_resource_pools_history_ex および sys.dm_resource_governor_workload_groups_history_ex ビューで報告されます。 これらのビューで参照されているリソース プールとワークロード グループの詳細については、「リソース管理」を参照してください。 これらのビューでは、関連付けられているリソース プールおよびワークロード グループにおける、ユーザー ワークロードと特定の内部プロセスによるリソース使用量が報告されます。
ヒント
ワークロード パフォーマンスの監視またはトラブルシューティングを行う場合は、ユーザーの CPU 消費量 (avg_cpu_percent、cpu_percent) と、ユーザー ワークロードと内部プロセスによる合計 CPU 消費量 (avg_instance_cpu_percent、sql_instance_cpu_percent) の両方を考慮することが重要です。 これらのメトリックの "いずれか" が 70 - 100% の範囲にある場合は、パフォーマンスが著しく影響を受ける可能性があります。
ユーザー CPU 消費量は、各サービス目標におけるユーザー ワークロードの CPU 上限に対する割合として計算されます。 同様に、 合計 CPU 消費量は、すべてのワークロードの CPU 上限に対する割合として定義されます。 2 つの制限が異なるため、ユーザーと合計 CPU 消費量はさまざまなスケールで測定され、互いに直接比較することはできません。
ユーザーの CPU 消費量が 100% に達すると、たとえ合計 CPU 消費量が 100% を下回った場合でも、ユーザーのワークロードが、選択するサービス目標で利用可能な CPU 容量が完全に使用しているとみなされます。
合計 CPU 消費量が 70 から 100% の範囲に達した場合は、ユーザー CPU 消費量が 100% を大幅に下回ったままであっても、ユーザー ワークロードのスループットが平坦化され、クエリの待機時間が増加する可能性があります。 これは、コンピューティング リソースが適度に割り当てられている、より小さいサービス目標を使用していても、高密度エラスティック プールのような比較的集中的なユーザー ワークロードの場合に、発生する可能性が高くなります。 これは、データベースの新しいレプリカの作成やデータベースのバックアップなど、内部プロセスが一時的により多くのリソースを必要とする場合に、サービス目標が小さい場合にも発生します。
同様に、
ユーザーの CPU 消費量または合計 CPU 消費量が高い場合、軽減オプションは「コンピューティングの CPU」セクションで説明したものと同じであり、サービス目標の引き上げや、ユーザー ワークロードの最適化が含まれます。
注意
完全にアイドル状態のデータベースまたはエラスティック プールでも、バックグラウンド データベース エンジンのアクティビティのため、CPU 消費量の合計がゼロになることはありません。 特定のバックグラウンド アクティビティ、コンピューティング サイズ、および以前のユーザー ワークロードに応じて、広い範囲で変動する可能性があります。
リソース ガバナンス
Azure SQL Database では、リソース制限を適用するためにクラウドで実行できるよう修正や拡張が行われた SQL Server Resource Governor に基づいたリソース ガバナンスの実装が使用されます。 SQL Database には複数のリソース プールおよびワークロード グループがあり、プール レベルおよびグループ レベル両方でリソース制限が設定され、均衡の取れた Database-as-a-Service が提供されています。 ユーザー ワークロードと内部ワークロードは、別々のリソース プールとワークロード グループに分類されます。 プライマリ レプリカおよび読み取り可能なセカンダリ レプリカ (geo レプリカを含む) のユーザー ワークロードは、SloSharedPool1 リソース プールと UserPrimaryGroup.DBId[N] ワークロード グループに分類されます。[N] はデータベース ID の値を表します。 さらに、さまざまな内部ワークロード用に複数のリソース プールとワークロード グループがあります。
Resource Governor を使用してデータベース エンジン内でリソースを管理するだけでなく、Azure SQL Database ではプロセス レベルのリソース管理用に Windows ジョブ オブジェクト、また、ストレージ クォータ管理用に Windows ファイル サーバー リソース マネージャー (FSRM) も使用します。
Azure SQL Database のリソース管理は、本質的に階層化されています。 制限は一貫して、オペレーティング システムのリソース管理メカニズムと Resource Governor を使用して OS レベルとストレージ ボリューム レベルで適用され、Resource Governor を使用してリソース プール レベルで、さらには Resource Governor を使用してワークロード グループ レベルで適用されます。 現在のデータベースまたはエラスティック プールに対して有効になっているリソース ガバナンスの制限は、sys.dm_user_db_resource_governance ビューで報告されます。
データ I/O のガバナンス
データ I/O のガバナンスは、データベースのデータ ファイルに対する読み取りと書き込み両方の物理 I/O を制限するために使用される、Azure SQL Database 内のプロセスです。 IOPS 制限はサービス レベルごとに設定され、"うるさい隣人" の影響を最小限に抑えて、マルチテナント サービス内のリソース割り当ての公平性を提供すると共に、基になるハードウェアとストレージの機能内に収めます。
単一データベースの場合、ワークロード グループの制限は、データベースに対するすべてのストレージ I/O に適用されます。 エラスティック プールの場合、ワークロード グループの制限は、プール内の各データベースに適用されます。 また、リソース プールの制限は、エラスティック プールの累積 I/O にも適用されます。
tempdb では、I/O はワークロード グループの制限が適用されますが、より高い tempdb I/O 制限が適用される Basic、Standard、General Purpose のサービス レベルを除きます。 ワークロード グループの制限はリソース プールの制限よりも低く、IOPS/スループットをより迅速に制限することから、通常、(単一またはプールされた) データベースに対するワークロードがリソース プールの制限に到達しない可能性があります。 しかし、同じプール内の複数のデータベースに対して組み合わされたワークロードによって、プールの制限に到達する可能性があります。
たとえば、あるクエリで I/O リソース管理なしで 1000 IOPS が生成されるが、ワークロード グループの IOPS 上限が 900 IOPS に設定されている場合、このクエリで、900 を超える IOPS は生成できません。 しかし、リソース プールの IOPS 上限が 1500 IOPS に設定されており、リソース プールに関連付けられているすべてのワークロード グループからの I/O 合計が 1500 IOPS を超過した場合、同じクエリの I/O がワークロード グループの制限である 900 IOPS を下回るまで減らされる可能性があります。
sys.dm_user_db_resource_governance ビューから返される IOPS およびスループットの最大値は、保証としてではなく、制限/上限として機能します。 さらに、リソース管理によって、特定のストレージ待機時間が保証されるわけではありません。 特定のユーザーのワークロードに対して実現できる最適な待機時間、IOPS、スループットは、I/O リソース管理の上限だけではなく、使用される最大 I/O サイズや基になるストレージの機能にも依存します。 SQL Database で使用される I/O 操作のサイズは、512 バイトから 4 MB の間で変動します。 IOPS 制限を適用するため、Azure Storage 内でデータ ファイルを備えるデータベースを除き、サイズに関係なくどの I/O も考慮されます。 その場合、Azure Storage I/O の説明に従って、256 KB より大きい I/O は、複数の 256 KB の I/O として考慮されます。
Azure Storage 内のデータ ファイルを使用する Basic、Standard、General Purpose の各データベースでは、IOPS のこの数値を累積的に提供できる十分なデータ ファイルがデータベースにない場合、データがファイル間で均等に分散されていない場合、または基本となる BLOB のパフォーマンス レベルによって IOPS/スループットがリソース管理の制限より下に制限される場合、primary_group_max_io 値に到達しない可能性があります。 同様に、トランザクションの頻繁なコミットによって生成された小規模なログ I/O 操作では、基になる Azure Storage BLOB 上に IOPS 制限があるため、ワークロードによって primary_max_log_rate 値に到達しない可能性があります。 Azure Premium Storage を使用するデータベースの場合、Azure SQL Database では、データベースのサイズに関係なく、必要な IOPS/スループットを取得するのに十分な大容量のストレージ BLOB が使用されます。 大規模なデータベースの場合、合計 IOPS/スループット容量を増やすために複数のデータファイルが作成されます。
avg_data_io_percent、avg_log_write_percent、sys.dm_elastic_pool_resource_stats、sys.elastic_pool_resource_stats ビュー上で報告される、 および などのリソース使用率の値は、リソース管理の上限の割合として計算されています。 そのため、リソース管理以外の要素によって IOPS/スループットが制限される場合は、報告されるリソース使用率が 100% を下回ったままであっても、IOPS/スループットのフラット化とワークロードの増加に伴う待機時間の増加が見られる可能性があります。
データベース ファイルごとの読み取りおよび書き込みの IOPS、スループット、および待機時間を監視するには、sys.dm_io_virtual_file_stats() 関数を使用します。 この関数では、avg_data_io_percent に対しては考慮されないバックグラウンド I/O を含む、データベースに対するすべての I/O が網羅されますが、基になるストレージの IOPS とスループットが使用され、監視されているストレージの待機時間に影響を及ぼす可能性があります。 この関数では、I/O リソース ガバナンスによって発生する可能性のある読み取りと書き込みの追加の待機時間も、それぞれ io_stall_queued_read_ms 列と io_stall_queued_write_ms 列で報告されます。
トランザクション ログ速度ガバナンス
トランザクション ログ速度ガバナンスは、一括挿入、SELECT INTO、インデックス作成などのワークロードの高いインジェクション速度を制限するために使用される、Azure SQL Database 内のプロセスです。 こうした制限は追跡され、1 秒未満のレベルでログ レコード生成速度に適用されて、データ ファイルに対して発行できる IO の数に関係なく、スループットが制限されます。 現在、トランザクション ログ生成率は、ハードウェアに依存し、サービス レベルに依存するポイントまで直線的にスケールアップされます。
ログ速度をさまざまなシナリオで実現し維持できるとともに、ユーザー負荷への影響を最小限に抑えながらシステム全体の機能を維持できように、ログ速度が設定されます。 ログ速度ガバナンスにより、トランザクション ログ バックアップは、発行された復元可能性 SLA 内で維持されます。 また、このガバナンスにより、セカンダリ レプリカ上の過剰なバックログが回避されます。そうしなければ、フェールオーバー中のダウンタイムが予想以上に長くなることがあります。
トランザクション ログ ファイルへの実際の物理的な IO は、管理または制限されません。 ログ レコードが生成されると、各操作が評価され、望ましい最大ログ速度 (MB/秒) を維持するために遅延する必要があるかどうかが判断されます。 ログ レコードがストレージにフラッシュされる場合には、遅延は追加されません。ログ速度ガバナンスは、ログ速度生成プロセス自体に適用されます。
実行時に適用される実際のログ生成速度は、フィードバック メカニズムによっても影響されます。この場合、システムを安定化するために許容ログ速度が一時的に低下します。 ログ領域の不足状態を回避しようとするログ ファイル領域管理と、データ レプリケーション メカニズムにより、全体的なシステムの制限が一時的に低くなる可能性があります。
ログ速度ガバナーのトラフィック シェイプは、次の待機の種類を使用して表示されます (sys.dm_exec_requests および sys.dm_os_wait_stats ビューで公開されます)。
| 待機の種類 | メモ |
|---|---|
LOG_RATE_GOVERNOR |
データベース制限 |
POOL_LOG_RATE_GOVERNOR |
プール制限 |
INSTANCE_LOG_RATE_GOVERNOR |
インスタンス制限 |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
フィードバック制御、Premium/Business Critical での可用性グループの物理的なレプリケーションが維持されていない |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
フィードバック制御、ログ領域の不足を回避するために速度を制限 |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
geo レプリケーションのフィードバック制御、geo セカンダリの長いデータ待機時間や使用不可状態を回避するためにログ速度を制限 |
望ましいスケーラビリティを損なうログ速度制限が発生した場合は、次のオプションを検討してください。
- サービス レベル最大のログ速度を実現したり、異なるサービス レベルに切り替えたりするには、より高いサービス レベルにスケールアップします。 Hyperscale サービス レベルでは、選択したサービス レベルに関係なく、データベースあたり 100 MiB/秒のログ レートとエラスティック プールあたり 125 MiB/秒が提供されます。 オプトイン プレビュー機能として、150 MiB/秒のログ生成率を使用できます。 詳細については、150 MiB/秒にオプトインするには、ブログを参照してください。2024 年 11 月の Hyperscale 拡張機能。
- ETL プロセスでのステージング データなど、読み込まれるデータが一時的なデータである場合、
tempdbに読み込むことができます (ログ記録が最小限に抑えられます)。 - 分析シナリオの場合は、クラスター化された列ストア テーブル、またはデータ圧縮を使用するインデックスを含むテーブルに読み込む必要があります。 この場合、必要なログ速度が小さくなります。 この手法は CPU 使用率を高め、クラスター化列ストア インデックスまたはデータ圧縮からベネフィットを得られるデータ セットにのみ適用されます。
ストレージ スペースのガバナンス
Premium および Business Critical サービス レベルでは、データ ファイル、トランザクション ログ ファイル、tempdb ファイルなどの顧客データが、データベースまたはエラスティック プールをホストするマシンのローカル SSD ストレージに保存されます。 ローカル SSD ストレージによって、さらに高い IOPS およびスループットと、さらに短い I/O 待ち時間が実現されます。 顧客データに加えて、オペレーティング システム、管理ソフトウェア、監視データおよびログ、システム操作に必要な他のファイルにもローカル ストレージが使用されます。
ローカル ストレージのサイズは有限であり、ハードウェアの性能 (これにより最大ローカル ストレージの制限が決まります) または顧客データ用に確保されるローカル ストレージの量に左右されます。 この制限は、安全で信頼性の高いシステム操作を確保しつつ、顧客データのストレージを最大化するために設定されています。 各サービス目標の最大ローカル ストレージの値を確認するには、単一データベースおよびエラスティック プールのリソース制限に関するドキュメントを参照してください。
この値と、特定のデータベースまたはエラスティック プールで現在使用されているローカル ストレージの容量は、次のクエリを使用して確認することもできます。
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| 列 | 説明 |
|---|---|
server_name |
論理サーバー名 |
database_name |
データベース名 |
slo_name |
サービス目標名 (ハードウェアの世代を含む) |
user_data_directory_space_quota_mb |
最大ローカル ストレージ (MB) |
user_data_directory_space_usage_mb |
データ ファイル、トランザクション ログ ファイル、および tempdb ファイルによるローカル ストレージの現在の使用量 (MB)。 5 分ごとに更新されます。 |
このクエリは、master データベースではなく、ユーザー データベースで実行する必要があります。 エラスティック プールの場合、プール内の任意のデータベースでクエリを実行できます。 報告された値はプール全体に適用されます。
重要
Premium および Business Critical サービス レベルでは、ワークロードが、データ ファイル、トランザクション ログ ファイル、tempdb ファイルによるローカル ストレージの合計使用量を最大ローカル ストレージの制限を超えて増やそうとすると、領域不足エラーが発生します。 これは、データベース ファイル内の使用済の領域がファイルの最大サイズに達していない場合でも発生します。
ローカル SSD ストレージは、tempdb データベースと Hyperscale RBPEX キャッシュのために、Premium および Business Critical 以外のサービス レベルのデータベースでも使われます。 データベースの作成、削除、サイズの増減に伴って、マシン上のローカル ストレージの合計使用量は経時的に変動します。 システムは、マシン上の使用可能なローカル ストレージが少なくなっており、データベースまたはエラスティック プールが領域不足になる危険性があることを検知すると、使用可能なローカル ストレージが十分にある別のマシンにそのデータベースまたはエラスティック プールを移動します。
この移動処理は、データベースのスケーリング操作と同様にオンラインで実行され、操作終了時の短時間 (秒単位) のフェールオーバーなど、 これと同様の影響を与えます。 このフェールオーバーにより、開いている接続が終了され、トランザクションがロールバックされるので、その時点でデータベースを使用しているアプリケーションに影響を与える可能性があります。
すべてのデータが別のマシンのローカル ストレージ ボリュームにコピーされるため、Premium および Business Critical サービス レベルの大規模なデータベースに移動するにはかなりの時間を要する可能性があります。 その間に、データベースやエラスティック プール、または tempdb データベースによるローカル領域の使用量が急激に増加すると、領域不足の危険性が高まります。 システムでは、領域不足エラーを最小限に抑え、不要なフェールオーバーを回避するために、バランスの取れた方法でデータベースの移動が開始されます。
tempdb のサイズ
Azure SQL Database の tempdb のサイズ制限は、購入およびデプロイのモデルに応じて異なります。
詳細については、以下の tempdb のサイズ制限を確認してください。
- 仮想コア購入モデル: 単一データベース、プールされたデータベース
- DTU 購入モデル: 単一データベース、プールされたデータベース。
以前から利用可能なハードウェア
このセクションには、以前から利用できるハードウェアの詳細が含まれています。
- Gen4 ハードウェアは廃止されているため、プロビジョニング、アップスケーリング、ダウンスケーリングには使用できません。 サポートされているハードウェア世代にデータベースを移行すると、広範な仮想コアとストレージのスケーラビリティ、高速ネットワーク、最高の IO パフォーマンス、最小待機時間が実現します。 詳細については、「Azure SQL Database での Gen 4 ハードウェアのサポートが終了しました」を参照してください。
Azure Resource Graph エクスプローラーを使って、現在 Gen4 ハードウェアが使われているすべての Azure SQL Database リソースを特定できます。また、Azure portal で特定の論理サーバーのリソースによって使われているハードウェアをチェックすることもできます。
Azure Resource Graph エクスプローラーで結果を表示するには、Azure オブジェクトまたはオブジェクト グループに対して少なくとも read アクセス許可が必要です。
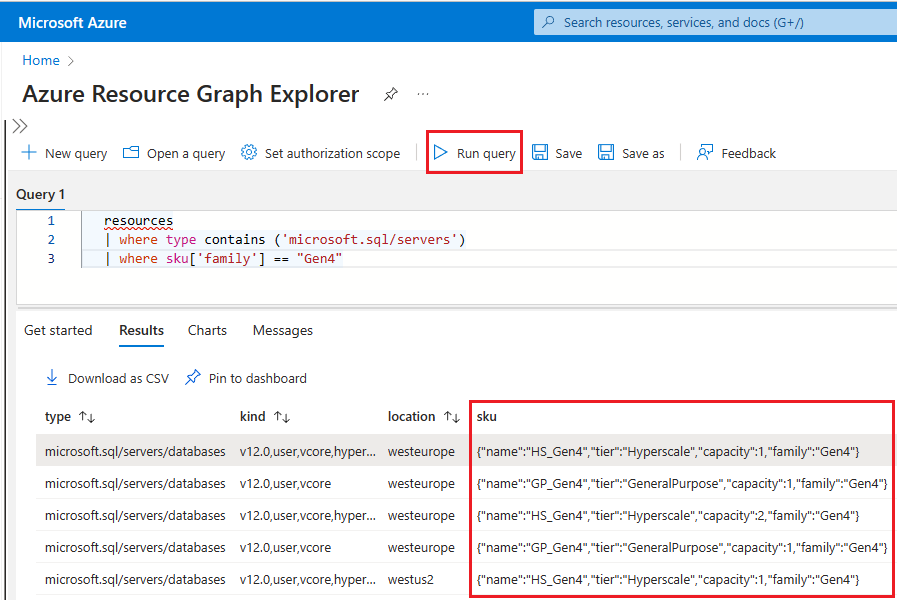
Resource Graph エクスプローラーを使って Gen4 ハードウェアがまだ使用されている Azure SQL リソースを特定するには、次の手順に従います。
Azure ポータルにアクセスします。
検索ボックスで「
Resource graph」を検索し、検索結果から Resource Graph エクスプローラー サービスを選択します。クエリ ウィンドウで、次のクエリを入力し、[クエリの実行] を選択します。
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"[結果] ペインには、現在 Azure にデプロイされていて、Gen4 ハードウェアを使用しているすべてのリソースが表示されます。
Azure の特定の論理サーバーのリソースによって使用されているハードウェアをチェックするには、次の手順に従います。
- Azure ポータルにアクセスします。
- 検索ボックスで「
SQL servers」を検索し、検索結果から [SQL サーバー] を選択して [SQL サーバー] ページを開き、選択したサブスクリプションのすべてのサーバーを表示します。 - 目的のサーバーを選択して、そのサーバーの [概要] ページを開きます。
- 使用可能なリソースまで下にスクロールし、gen4 ハードウェアを使用しているリソースの [価格レベル] 列をチェックします。
![Azure の論理サーバーの [概要] ページのスクリーンショット。[概要] ページが選択され、gen4 が強調表示されています。](../includes/media/identify-gen4-hardware/identify-gen4-hardware.png?view=azuresql)
リソースを standard シリーズのハードウェアに移行するには、ハードウェアの変更に関する記事を参照してください。
関連するコンテンツ
- Azure の一般的な制限については、「Azure サブスクリプションとサービスの制限、クォータ、制約」をご覧ください。
- DTU と eDTU については、「データベース トランザクション ユニット (DTU) とエラスティック データベース トランザクション ユニット (eDTU) の説明」をご覧ください。
-
tempdbのサイズ制限の詳細については、単一仮想コア データベース、プールされた仮想コア データベース、単一 DTU データベース、プールされた DTU データベースに関する記事を参照してください。