動的管理ビューを使用してパフォーマンスを監視する
適用対象: ![]() Azure SQL Database
Azure SQL Database ![]() Microsoft Fabric SQL Database
Microsoft Fabric SQL Database
動的管理ビュー (DMV) を使用すると、ワークロードのパフォーマンスを監視し、クエリのブロックまたは長時間の実行、リソースのボトルネック、最適ではないクエリ プランなどが原因で発生する可能性のあるパフォーマンスの問題を診断できます。
この記事では、T-SQL を使用して動的管理ビューにクエリを実行することで一般的なパフォーマンスの問題を検出する方法について説明します。 次のような任意のクエリ ツールを使用できます。
アクセス許可
Azure SQL データベースでは、コンピューティング サイズ、デプロイ オプション、DMV 内のデータに応じて、DMV のクエリを実行するには、VIEW DATABASE STATE、VIEW SERVER PERFORMANCE STATE、または VIEW SERVER SECURITY STATE のいずれかのアクセス許可が必要になる場合があります。 最後の 2 つのアクセス許可が VIEW SERVER STATE アクセス許可に含まれます。 サーバー状態表示のアクセス許可は、対応するサーバー ロールのメンバーシップを介して付与されます。 特定の DMV に対してクエリを実行するために必要なアクセス許可を決定するには、「動的管理ビュー」を参照し、DMV についての記事を見つけてください。
データベース ユーザーに VIEW DATABASE STATE アクセス許可を付与するには、次のクエリを実行し、データベース内のユーザー プリンシパルの名前を database_user に置き換えます。
GRANT VIEW DATABASE STATE TO [database_user];
##MS_ServerStateReader## サーバー ロールのメンバーシップを論理サーバーの login_name という名前のログインに付与するには、master データベースに接続し、例として次のクエリを実行します。
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
アクセス許可の付与が有効になるまでに数分かかる場合があります。 詳細については、「サーバーレベルのロールの制限」をご覧ください。
リソース使用量の監視
次のビューを使用して、データベース レベルでリソース使用量を監視できます。 これらのビューは、スタンドアロン データベースと Elastic Pool 内のデータベースに適用できます。
次のビューを使用して、Elastic Pool レベルでリソース使用量を監視できます。
Azure portal の SQL Database クエリ パフォーマンスの分析情報を使用するか、クエリ ストア経由でリソース使用量をクエリ レベルで監視できます。
sys.dm_db_resource_stats
sys.dm_db_resource_stats ビューは、すべてのデータベースで使用できます。 sys.dm_db_resource_stats ビューには、コンピューティング サイズの制限に関連した最近のリソース使用データが表示されます。 CPU、データ I/O、ログ書き込み、ワーカー スレッド、メモリ使用量の制限に対する割合は、15 秒間隔ごとに記録され、約 1 時間保持されます。
このビューには詳細なリソース使用量データが表示されるので、現状の分析やトラブルシューティングが目的の場合、最初に sys.dm_db_resource_stats を使用してください。 たとえば次のクエリは、現在のデータベースの過去 1 時間の平均リソース使用率と最大リソース使用率を表示します。
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
その他のクエリについては、sys.dm_db_resource_stats の例を参照してください。
sys.resource_stats
master データベースの sys.resource_stats ビューには、特定のサービス レベルとコンピューティング サイズでのデータベースのパフォーマンス監視に役立つ追加情報が含まれます。 データは 5 分ごとに集められ、約 14 日間保持されます。 このビューは、過去にデータベースでリソースがどのように使用されたかを長期にわたり分析する場合に役立ちます。
次のグラフは、Premium データベースの CPU リソース使用率を示しています (P2 コンピューティング サイズ、1 週間における毎時間の使用率)。 このグラフは月曜日から始まります。5 営業日が経過した後の週末ではアプリケーションの活動が大幅に減っていることがわかります。
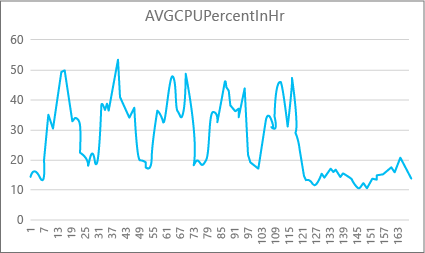
このデータから、このデータベースのピーク CPU 負荷は現在のところ、P2 コンピューティング サイズに対して 50% をわずかに超える CPU 利用率になっていることがわかります (火曜日の昼)。 アプリケーションのリソース プロファイルにおいて CPU が支配的要因である場合、P2 がワークロードに常に対処できる最適なコンピューティング サイズであると決定できます。 時間の経過と共にアプリケーションの規模が大きくなると予測される場合、アプリケーションがパフォーマンス レベルの制限に達しないように、リソース バッファーを余分に確保しておくことをお勧めします。 コンピューティング サイズを上げると、要求を効果的に処理するための十分な能力がないデータベースで発生するおそれのある、ユーザーに見えるエラーを回避できます。これは特に待機時間が重要な環境に当てはまります。
アプリケーションの種類が異なれば、同じグラフの解釈が異なる場合があります。 たとえば、あるアプリケーションで給与データを毎日処理し、同じグラフを生成する場合、P1 コンピューティング サイズでこの種の "一括ジョブ" モデルに問題なく対応できる可能性があります。 P2 コンピューティング サイズが 200 DTU であるのに対して、P1 コンピューティング サイズは 100 DTU です。 P1 コンピューティング サイズのパフォーマンスは、P2 コンピューティング サイズの半分です。 このため、P2 における 50% の CPU 使用率は、P1 における 100% の CPU 使用率に相当します。 アプリケーションにタイムアウトがない場合、当日に完了するのであれば、ジョブに 2 時間かかっても 2.5 時間かかっても問題ないものと思われます。 このカテゴリのアプリケーションではおそらく、P1 コンピューティング サイズを利用できます。 1 日の中にはリソース使用率が低くなる時間帯があるという事実を利用できます。このため、"大きなピーク" が 1 日のそのような時間帯のいずれかに波及することがあります。 ジョブを毎日定刻に完了できる限り、P1 コンピューティング サイズがこの種のアプリケーションに適している (コストが削減される) 場合があります。
データベース エンジンでは、各アクティブ データベースの使用済みリソース情報が、各論理サーバーの master データベースの sys.resource_stats ビューで公開されます。 ビューのデータは 5 分おきに集計されます。 このデータがテーブルに表示されるまでに数分かかる場合があるため、sys.resource_stats は凖リアルタイムの分析よりも過去の分析に役に立ちます。 sys.resource_stats ビューにクエリを実行すると、データベースの最近の履歴が表示され、選択したコンピューティング サイズで必要なときに望ましいパフォーマンスが発揮されたかどうかを検証できます。
Note
次の例の sys.resource_stats にクエリを実行するには、master データベースに接続する必要があります。
この例では、sys.resource_stats のデータを示します。
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
次の例では、sys.resource_stats カタログ ビューを使用して、データベースでのリソースの使用状況に関する情報を取得するさまざまな方法を示します。
ユーザー データベース
userdb1の過去 1 週間のリソース使用量を確認するには、独自のデータベース名に置き換えて、次のクエリを実行します。SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;ワークロードがコンピューティング サイズにどの程度適合しているかを評価するには、リソース メトリックの各側面を分析する必要があります。つまり、CPU、データ I/O、ログ書き込み、ワーカー数、セッション数です。
sys.resource_statsを使用して、データベースがプロビジョニングされたコンピューティング サイズごとに、これらのリソース メトリックの平均値と最大値を報告するように変更されたクエリを次に示します。SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;各リソース メトリックの平均値と最大値に関するこの情報に基づいて、選択したコンピューティング サイズにワークロードが適合しているかどうかを評価できます。 通常、
sys.resource_statsからの平均値が目標サイズに対する有効な基準となります。DTU 購入モデルのデータベースの場合:
たとえば、S2 コンピューティング サイズで Standard サービス レベルを使用しているとします。 CPU と I/O の読み取り/書き込みの平均使用率が 40% を下回り、ワーカーの平均数が 50 を下回り、セッションの平均数が 200 を下回っています。 このワークロードには、S1 コンピューティング サイズが適している可能性があります。 データベースがワーカーとセッションの制限内に収まるかどうかは簡単にわかります。 データベースが下位のコンピューティング サイズに適合するかどうかを確認するには、下位コンピューティング サイズの DTU 数を現在のコンピューティング サイズの DTU 数で割り、その計算結果に 100 を掛けます。
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40この結果は、2 つのコンピューティング サイズの間の相対的パフォーマンス差異を百分率で表したものになります。 リソースの使用がこの割合を超えていない場合、ワークロードは下位のコンピューティング サイズに適合する可能性があります。 ただし、リソース使用率の値を全範囲で見て、どのくらいの頻度でデータベースのワークロードが下位のコンピューティング サイズに適合するかを割合の観点から判断する必要があります。 次のクエリは、この例で計算した 40% のしきい値に基づき、リソース ディメンション別の適合率を出力します。
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;データベースのサービス レベルに基づき、ワークロードが下位のコンピューティング サイズに適合するかどうかを判断できます。 データベース ワークロード目標が 99.9% で、上記のクエリが 3 つすべてのリソース ディメンションに対して 99.9% を超える値を返す場合、そのワークロードはおそらく下位のコンピューティング サイズに適合します。
適合率を見ると、目標を満たすために上位のコンピューティング サイズに移行する必要があるかどうかもわかります。 たとえば、過去 1 週間のサンプル データベースの CPU 使用率は次のようになります。
平均 CPU 使用率 (%) 最大 CPU 使用率 (%) 24.5 100.00 平均 CPU は、コンピューティング サイズの制限の約 4 分の 1 であり、データベースのコンピューティング サイズにうまく適合するでしょう。
DTU 購入モデルおよび 仮想コア購入モデルのデータベースの場合:
最大値は、データベースがコンピューティング サイズの上限に達することを示します。 次に上位のコンピューティング サイズに移動する必要がありますか。 ワークロードが 100% に到達する回数を確認し、それをデータベースのワークロード目標と比較します。
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;これらの割合は、ワークロードが現在のコンピューティング サイズ "以下" に収まるサンプルの数です。 このクエリが 3 つのリソース ディメンションのいずれかについて 99.9% 未満の値を返す場合、サンプリングされた平均ワークロードは制限を超えました。 次に高いコンピューティング サイズに移行するか、アプリケーションの調整手法を使用してデータベースの負荷を軽減することを検討してください。
sys.dm_elastic_pool_resource_stats
適用対象: ![]() Azure SQL Database のみ
Azure SQL Database のみ
sys.dm_db_resource_stats と同様に、sys.dm_elastic_pool_resource_stats は、Azure SQL Database エラスティック プールのリソース使用状況について最近の詳細なデータを提供します。 ビューは、Elastic Pool 内の任意のデータベースでクエリを実行して、特定のデータベースではなく、プール全体のリソース使用量データを提供できます。 この DMV によって報告される割合の値は、Elastic Pool の制限に対するものであり、この制限は、プール内のデータベースの制限よりも高くなる可能性があります。
この例では、過去 15 分間における現在の Elastic Pool の集計されたリソース使用量データを示します。
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
リソース使用量が長期間にわたって 100% に近づいていることが判明した場合は、同じ Elastic Pool 内の個々のデータベースのリソース使用量を確認して、各データベースがプール レベルのリソース使用量にどの程度影響しているかを判断する必要がある場合があります。
sys.elastic_pool_resource_stats
適用対象: ![]() Azure SQL Database のみ
Azure SQL Database のみ
sys.resource_stats と同様に、master データベース内の sys.elastic_pool_resource_stats は、論理サーバー上のすべての Elastic Pool のリソース使用量の履歴データを提供します。 sys.elastic_pool_resource_stats は、過去 14 日間の履歴監視 (使用状況の傾向分析など) に使用できます。
この例では、現在の論理サーバー上のすべての Elastic Pool について、過去 7 日間に集計されたリソース使用量データを示します。 master データベースでクエリを実行します。
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
同時要求数
現在の同時要求数を確認するには、ユーザー データベースで次のクエリを実行します。
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
これはある時点のスナップショットにすぎません。 ワークロードと同時要求の要件をさらに詳しく理解するには、時間をかけて多くのサンプルを収集する必要があります。
平均要求レート
この例では、一定期間のデータベースまたは Elastic Pool 内のデータベースの平均要求レートを検索する方法を示します。 この例では、期間は 30 秒に設定されています。 WAITFOR DELAY ステートメントを変更することで調整できます。 ユーザー データベースでこのクエリを実行します。 データベースが Elastic Pool 内にあり、十分なアクセス許可がある場合、結果には Elastic Pool 内の他のデータベースが含まれます。
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
現在のセッション
現在のアクティブ セッション数を確認するには、データベースで次のクエリを実行します。
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
このクエリはある時点の数を返します。 時間をかけて複数のサンプルを集めると、セッションの使用状況を正確に把握できます。
要求、セッション、およびワーカーの最近の履歴
この例では、データベースまたは Elastic Pool 内のデータベースに対する要求、セッション、ワーカー スレッドの最近の使用履歴を返します。 各行は、データベースの特定の時点でのリソース使用量のスナップショットを表します。 requests_per_second 列は、snapshot_time で終了する期間の平均要求レートです。 データベースが Elastic Pool 内にあり、十分なアクセス許可がある場合、結果には Elastic Pool 内の他のデータベースが含まれます。
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
データベースとオブジェクトのサイズを計算する
次のクエリは、データベース内のデータ サイズ (メガバイト単位) を返します。
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
次のクエリは、データベース内の個々のオブジェクトのサイズ (MB 単位) を返します。
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
CPU パフォーマンスに関する問題の特定
このセクションでは、CPU コンシューマーの上位である個々のクエリを識別するのに役立ちます。
CPU 消費量が長時間にわたって 80% を超える場合は、CPU の問題が現在発生しているか、過去に発生したかに関係なく、次のトラブルシューティング手順を検討してください。 また、このセクションの手順に従って、CPU を消費する上位のクエリを事前に特定し、それらを調整することもできます。 場合によっては、CPU 消費量を減らすことで、データベースと Elastic Pool をスケールダウンし、コストを節約できる場合があります。
トラブルシューティングの手順は、Elastic Pool 内のスタンドアロン データベースとデータベースでも同じです。 ユーザー データベース内のすべてのクエリを実行します。
CPU に関する問題が現在発生している
現時点で問題が発生している場合、2 つのシナリオが考えられます。
個別のクエリが多数あり、大量の CPU が累積的に消費されている
次のクエリを使用して、クエリ ハッシュ別に上位のクエリを特定します。
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
実行時間の長いクエリが CPU を消費しており、実行中のままである
これらのクエリを特定するには、次のクエリを使用します。
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
CPU に関する問題が過去に発生した
過去に問題が発生していて、根本原因分析を行いたい場合は、クエリ ストアを使用します。 データベースにアクセスできるユーザーは、T-SQL を使用して、クエリ ストア データにクエリを実行できます。 既定では、クエリ ストアは 1 時間間隔の集計クエリ統計をキャプチャします。
大量の CPU を消費するクエリのアクティビティを確認するには、次のクエリを使用します。 このクエリは、CPU の消費が上位 15 のクエリを返します。 過去 2 時間以外の期間を確認するには、
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()を必ず変更してください。-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;問題となるクエリを特定したら、今度はそれらのクエリを調整して、CPU 使用率を抑えます。 あるいは、データベースまたは Elastic Pool のコンピューティング サイズを増やすことを選択して、問題を回避することもできます。
Azure SQL Database の CPU パフォーマンスに関する問題の処理の詳細については、「Azure SQL Database での高い CPU の診断とトラブルシューティング」を参照してください。
I/O パフォーマンスの問題を特定する
ストレージ入出力 (I/O) パフォーマンスに関する問題を特定する場合、上位の待機の種類は次のとおりです。
PAGEIOLATCH_*データ ファイル I/O に関する問題の場合 (
PAGEIOLATCH_SH、PAGEIOLATCH_EX、PAGEIOLATCH_UPなど)。 待機の種類の名前に IO が含まれている場合は、I/O の問題を示しています。 ページ ラッチ待機の名前に IO が含まれていない場合は、ストレージのパフォーマンスに関係のない別の種類の問題 (例:tempdb競合) が示されます。WRITE_LOGトランザクション ログ I/O に関する問題の場合。
I/O に関する問題が現在発生している場合
sys.dm_exec_requests または sys.dm_os_waiting_tasks を使用して、wait_type と wait_time を確認します。
データおよびログの I/O 使用率を確認する
データおよびログの I/O 使用率を確認するには、次のクエリを使用します。
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
sys.dm_db_resource_stats を使用する他の例については、この記事で後述する「リソース使用量の監視」セクションを参照してください。
I/O の上限に達した場合、次の 2 つのオプションがあります。
- コンピューティング サイズまたはサービス レベルをアップグレードする
- 最も多くの I/O を消費しているクエリを特定して調整する。
クエリ ストアを使用してバッファー関連の I/O を表示する
I/O 関連の待機で上位のクエリを特定するには、次のクエリ ストア クエリを使用して、過去 2 時間の追跡されたアクティビティを表示できます。
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
また、sys.query_store_runtime_stats ビューを使用して、avg_physical_io_reads 列と avg_num_physical_io_reads 列の大きな値を持つクエリに焦点を当てることもできます。
WRITELOG 待機に関する合計ログ I/O を表示する
待機の種類が WRITELOG の場合、次のクエリを使用して、ステートメントごとに合計ログ I/O を表示します。
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
tempdb のパフォーマンスに関する問題を特定する
tempdb の問題に関連する一般的な待機の種類は PAGELATCH_* です (PAGEIOLATCH_* ではありません)。 ただし、PAGELATCH_* 待機は必ずしも tempdb 競合があることを意味しません。 この待機は、同一のデータ ページを対象とする同時要求が原因で、ユーザーオブジェクト データ ページ競合が発生していることを意味する場合もあります。 tempdb 競合の詳細を確認するには、sys.dm_exec_requests を使用して、wait_resource 値が 2:x:y で始まることを確認します。ここで、2 は tempdb (データベース ID)、x はファイル ID、y はページ ID です。
tempdb 競合では、tempdb が使用されるアプリケーション コードを減らすか、書き直すのが一般的な方法です。 tempdb の一般的な使用領域には以下があります。
- 一時テーブル
- テーブル変数
- テーブル値パラメーター
- 並べ替え、ハッシュ結合、スプールが使用されるクエリ プランがあるクエリ
詳細については、「Azure SQL での tempdb」を参照してください。
Elastic Pool 内のすべてのデータベースは同じ tempdb データベースを共有します。 1 つのデータベースの tempdb 領域使用率が高い場合、同じ Elastic Pool 内の他のデータベースに影響する可能性があります。
テーブル変数と一時テーブルが使用される上位のクエリ
テーブル変数と一時テーブルが使用される上位のクエリを特定するには、次のクエリを使用します。
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
実行時間の長いトランザクションの特定
実行時間の長いトランザクションを特定するには、次のクエリを使用します。 実行時間の長いトランザクションは、永続的なバージョン ストア (PVS) のクリーンアップを妨げます。 詳しくは、「高速データベース復旧のトラブルシューティング」をご覧ください。
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
メモリ許可待機パフォーマンスに関する問題の特定
最上位の待機の種類が RESOURCE_SEMAPHORE の場合、メモリ許可の待機に関する問題があり、クエリが十分に大きなメモリ許可を取得するまで実行を開始できない可能性があります。
RESOURCE_SEMAPHORE 待機が上位の待機かどうかを確認します
RESOURCE_SEMAPHORE 待機が上位の待機かどうかを確認するには、次のクエリを使用します。 また、最近の履歴で RESOURCE_SEMAPHORE の待機時間ランクが上昇していることも示されます。 メモリ許可待機に関するトラブルシューティングの詳細については、「SQL Server のメモリ許可によって発生するパフォーマンスの低下またはメモリ不足の問題のトラブルシューティング」を参照してください。
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
大量のメモリを消費するステートメントの特定
Azure SQL Database でメモリ不足エラーが発生した場合は、sys.dm_os_out_of_memory_events をレビューします。 詳細については、「Azure SQL Database でのメモリ不足エラーのトラブルシューティング」を参照してください。
最初に、次のスクリプトを変更して、start_time と end_time の関連する値を更新します。 次に、次のクエリを実行して、大量のメモリを消費するステートメントを特定します。
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
上位 10 のアクティブなメモリ許可の特定
上位 10 のアクティブなメモリ許可を特定するには、次のクエリを実行します。
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
接続を監視する
sys.dm_exec_connections ビューを使用して、特定のデータベースに対して確立されている接続についての情報と、各接続の詳細を取得できます。 データベースが Elastic Pool 内にあり、十分なアクセス許可がある場合、ビューは Elastic Pool 内のすべてのデータベースの接続セットを返します。 また、sys.dm_exec_sessions ビューは、すべてのアクティブなユーザー接続と内部タスクについての情報を取得する場合に役立ちます。
現在のセッションを表示する
次のクエリは、現在の接続とセッションの情報を取得します。 すべての接続とセッションを表示するには、WHERE 句を削除します。
sys.dm_exec_requests ビューと sys.dm_exec_sessions ビューを実行するときに、データベースに対する VIEW DATABASE STATE アクセス許可を持っている場合にのみ、データベース上の実行中のすべてのセッションが表示されます。 それ以外の場合は、現在のセッションのみが表示されます。
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
クエリ パフォーマンスを監視する
クエリが低速または実行時間が長いと、大量のシステム リソースが消費される可能性があります。 このセクションでは、動的管理ビュー (sys.dm_exec_query_stats 動的管理ビュー) を使用して、いくつかの一般的なクエリ パフォーマンスの問題を検出する方法について説明します。 このビューには、キャッシュされたプラン内のクエリ ステートメントごとに 1 行が含まれており、その行の有効期間はプラン自体に関連付けられています。 つまり、プランがキャッシュから削除されると、対応する行もこのビューから削除されます。 クエリにキャッシュされたプランがない場合 (たとえば、OPTION (RECOMPILE) が使用されているため)、このビューの結果には表示されません。
CPU 時間別に上位のクエリを検出する
次の例では、実行あたりの平均 CPU 時間の上位 15 個のクエリに関する情報を返します。 この例では、論理的に等価なクエリがリソースの累計消費量ごとにグループ化されるように、クエリ ハッシュに応じてクエリを集計します。
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
累積 CPU 時間についてクエリ プランを監視する
クエリ プランの効率が悪いと、CPU の消費量が増える可能性があります。 次の例では、最近の履歴で累積 CPU 時間が最も多いクエリを特定します。
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
クエリのブロックを監視する
クエリが低速または実行時間が長いと、大量のリソースが消費され、結果としてクエリがブロックされる可能性があります。 ブロックの原因には、不適切なアプリケーション設計、不適切なクエリ プラン、有効なインデックスの欠如などがあります。
sys.dm_tran_locks ビューを使用すると、データベース内の現在ロックされているアクティビティに関する情報を取得できます。 コード例については、「sys.dm_tran_locks」をご覧ください。 ブロッキングのトラブルシューティングの詳細については、Azure SQL のブロックの問題の概要と解決策に関するページを参照してください。
デッドロックを監視する
場合によっては、2 つ以上のクエリが互いにブロックされ、デッドロックが発生することがあります。
拡張イベント トレースを作成して、デッドロック イベントをキャプチャし、クエリ ストアで関連するクエリとその実行プランを探すことができます。 詳細については、ラボ「AdventureWorksLT でデッドロックが発生する」を含め、「Azure SQL Database でデッドロックを分析および防止する」を参照してください。 デッドロックが発生する可能性があるリソースの種類について詳しくは、こちらを参照してください。