インテリジェントなアプリケーション
適用対象: ![]() Azure SQL Database
Azure SQL Database ![]() Fabric の SQL Database
Fabric の SQL Database
この記事では、OpenAI やベクターなどの人工知能 (AI) オプションを使用し、Azure SQL Database や Azure SQL Database の多くの機能を共有する Fabric SQL データベースを使ってインテリジェントなアプリケーションを構築するための概要を示します。
サンプルと例については、「SQL AI サンプル リポジトリ」を参照してください。
AI 対応アプリケーションの構築の簡単な概要については、「Azure SQL データベース Essentials シリーズ」のこちらのビデオをご覧ください:
概要
大規模言語モデル (LLM) を使用すると、開発者は使い慣れたユーザー エクスペリエンスで AI 搭載アプリケーションを作成できます。
アプリケーションで LLM を使用すると、モデルがアプリケーションのデータベースから適切なタイミングで、適切なデータにアクセスできる時、価値が高くなり、ユーザー エクスペリエンスが向上します。 このプロセスは取得拡張生成 (RAG) と呼ばれます。Azure SQL Database と Fabric SQL データベースにはこの新しいパターンをサポートする多くの機能があり、インテリジェントなアプリケーションを構築するための優れたデータベースとなっています。
以下のリンクは、インテリジェントなアプリケーションを構築するためのさまざまなオプションのサンプル コードを示しています。
| AI オプション | 説明 |
|---|---|
| Azure OpenAI | RAG の埋め込みを生成し、Azure OpenAI でサポートされている任意のモデルと統合します。 |
| ベクトル | データベースにベクターを格納してクエリを実行する方法について説明します。 |
| Azure AI Search | Azure AI 検索と共にデータベースを使用して、データの LLM をトレーニングします。 |
| インテリジェントなアプリケーション | 任意のシナリオで再現できる一般的なパターンを使用して、エンド ツー エンド ソリューションを作成する方法について説明します。 |
| Azure SQL データベースの Copilot スキル | Azure SQL データベース駆動型アプリケーションの設計、操作、最適化、正常性を効率化するように設計された AI 支援エクスペリエンスのセットについて説明します。 |
| Fabric SQL データベースでの Copilot スキル | Fabric SQL データベース駆動型アプリケーションの設計、操作、最適化、ヘルスを効率化するために設計された一連の AI 支援エクスペリエンスについて説明します。 |
Azure OpenAI で RAG を実装するための主要な概念
このセクションでは、Azure SQL Database または Fabric SQL データベースで Azure OpenAI を使用して RAG を実装するために不可欠な主要な概念について説明します。
検索拡張生成 (RAG)
RAG は、外部ソースから追加のデータを取得することで、関連する有益な応答を生成する LLM の機能を強化する手法です。 たとえば、RAG では、ユーザーの質問またはプロンプトに関連する ドメイン 固有の知識を含む記事やドキュメントに対してクエリを実行できます。 LLM は、その応答を生成するときに、この取得したデータをリファレンスとして使用できます。 たとえば、Azure SQL Database を使用する単純な RAG パターンは次のようになります。
- データをテーブルに挿入します。
- Azure SQL データベース を Azure AI Search にリンクします。
- Azure OpenAI GPT4 モデルを作成し、Azure AI Search にこれを接続します。
- アプリケーションと Azure SQL Database のトレーニング済みの Azure OpenAI モデルを使用して、データに関するチャットと質問を行います。
RAG パターンは、プロンプト エンジニアリングを使用して、モデルにより多くのコンテキスト情報を提供することで応答品質を向上させる役割を果たします。 RAG を使用することで、関連する外部ソースを生成プロセスに組み込むことで、モデルがより広範な知識ベースを適用できるため、より包括的で情報に基づいた応答が得られます。 LLM の グラウンディング の詳細については、「LLM のグラウンディング - Microsoft コミュニティ ハブ」を参照してください。
プロンプトとプロンプト エンジニアリング
プロンプトは、LLM への命令、または LLM が構築できるコンテキスト データとして機能する特定のテキストまたは情報を指します。 プロンプトは、質問、ステートメント、コード スニペットなど、さまざまな形式を取る可能性があります。
LLM からの応答を生成するために使用できるサンプル プロンプトは次のとおりです。
- 命令: LLM に対しディレクティブを提供します
- プライマリ コンテンツ: 処理のために LLM に情報を提供します
- 例: 特定のタスクまたはプロセスにモデルを条件付けするのに役立ちます
- キュー: LLM の出力を正しい方向に方向付けます
- サポート コンテンツ: LLM が出力の生成に使用できる補足情報を表します
シナリオに適したプロンプトを作成するプロセスは、プロンプト エンジニアリングと呼ばれます。 プロンプト エンジニアリングのプロンプトとベスト プラクティスの詳細については、「Azure OpenAI Service」を参照してください。
トークン
トークンは、入力テキストをより小さなセグメントに分割することによって生成されるテキストの小さなチャンクです。 これらのセグメントは、単語、または、1 文字から単語全体までの異なる長さを持つ文字のグループから成ります。 たとえば、hamburger という単語は、ham、bur、ger などのトークンに分割され、pear のような短くて一般的な単語は 1 つのトークンと見なされます。
Azure OpenAI では、API に提供される入力テキストはトークンに変換されます (トークン化)。 各 API 要求で処理されるトークンの合計数は、入力、出力、および要求パラメーターの長さによって異なります。 処理されるトークンの量は、モデルの応答時間とスループットにも影響します。 各モデルが Azure OpenAI からの 1 回の要求/応答で受け取ることができるトークンの数には制限があります。 詳細については、「Azure OpenAI Service のクォータと制限」を参照してください
ベクトル
ベクトルは、一部のデータに関する情報を表すことができる数値 (通常は浮動小数点数) の順序付けられた配列です。 たとえば、画像をピクセル値のベクトルとして表したり、テキストの文字列を ASCII 値のベクトルとして表したりすることができます。 データをベクトルに変換するプロセスを「ベクター化」と呼びます。 詳しくは、「ベクトル」をご覧ください。
埋め込み
埋め込みは、データの重要な特徴量を表すベクトルです。 埋め込みは、多くの場合、ディープ ラーニング モデルを使用して学習され、機械学習と AI モデルは埋め込みを機能として利用します。 埋め込みでは、同様の概念間のセマンティック類似性を把握することもできます。 たとえば、単語 person と human の埋め込みを生成する場合、これらの単語は意味的に似ているため、埋め込み (ベクトル表現) の値も似ていることが予想されます。
Azure OpenAI は、テキスト データから埋め込みを作成するためのモデルが特色となります。 このサービスは、テキストをトークンに分割し、OpenAI によって事前トレーニングされたモデルを使用して埋め込みを生成します。 詳細については、「Azure OpenAI を使用した埋め込みの作成」を参照してください。
ベクター検索
ベクトル検索とは、データセットから特定のクエリ ベクトルと意味的に似ているベクトルをすべて検索するプロセスを指します。 したがって、単語 human に対するクエリ ベクトルは、意味的に似た単語を辞書全体で検索し、近い一致として単語 person が見つけることができます。 この近接度 (距離) は、コサイン類似性などの類似性メトリックを使用して測定されます。 ベクトルの類似性が高くなるほど、それらの間の距離は小さくなります。
何百万ものドキュメントに対するクエリを実行し、データ内で最も類似したドキュメントを検索するシナリオを考えてみましょう。 Azure OpenAI を使用して、データとクエリ ドキュメントの埋め込みを作成できます。 次に、ベクトル検索を実行して、データセットから最も類似したドキュメントを見つけることができます。 ただし、少数の例に対しベクトル検索を実行するのは簡単です。 この同じ検索を数千または数百万のデータ ポイントに対して実行することは困難になります。 さらに、待機時間、処理能力、精度、コストなど、全数検索と近似最近傍 (ANN) 探索方法の間でのトレードオフもあります。これらはすべて、アプリケーションの要件に依存します。
以降のセクションで説明するように、Azure SQL Database ではベクトルを効率的に保存およびクエリできるため、正確な最近傍探索を高いパフォーマンスで実行できます。 精度と速度のどちらか一方を犠牲にする必要は無く、両方を実現できます。 統合ソリューションにデータと共にベクトル埋め込みを格納することで、データ同期を管理する必要性が最小限に抑えられ、AI アプリ開発の市場投入までの時間が短縮されます。
Azure OpenAI
埋め込みは、現実世界をデータとして表すプロセスです。 テキスト、画像、またはサウンドを埋め込みに変換できます。 Azure OpenAI モデルでは、現実世界の情報を埋め込みに変換できます。 モデルは REST エンドポイントとして使用できるため、sp_invoke_external_rest_endpoint システム ストアド プロシージャを使用して Azure SQL Database から簡単に実行できます。
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
REST サービスの呼び出しを使用して埋め込みを取得することは、SQL Database と OpenAI を連携するときに有する統合オプションの 1 つに過ぎません。 次の例のように、使用可能なモデルのいずれも Azure SQL Database に格納されているデータにアクセスして、ユーザーがデータを操作できるソリューションを作成できます。
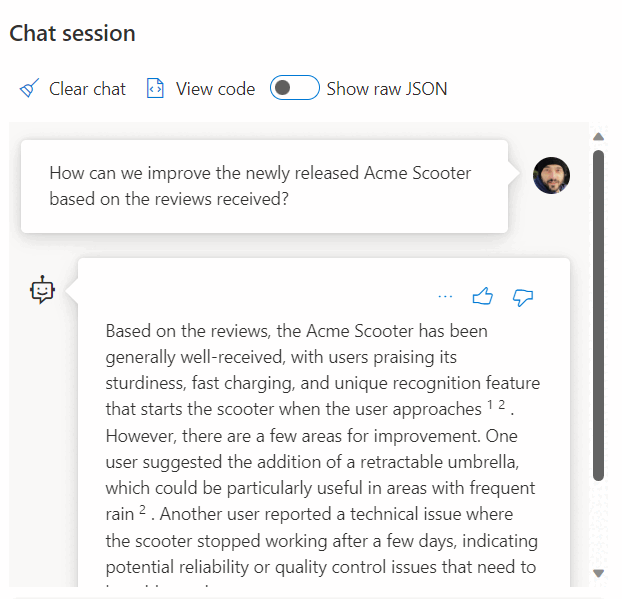
SQL Database と OpenAI の使用に関するその他の例については、次の記事を参照してください。
- Azure OpenAI Service (DALL-E) と Azure SQL Database を使用してイメージを生成する
- Azure SQL Database での OpenAI REST エンドポイントの使用
ベクトル
ベクトル データ型
2024 年 11 月に、新しいベクトル データ型が Azure SQL Database に導入されました。
専用のベクトル型により、ベクトル データを効率的に最適化して保存できるようになり、またこれにはベクトル検索や類似検索の実装を簡素化する一連の関数が用意されています。 新しい VECTOR_DISTANCE 関数を使用すると、2 つのベクトル間の距離を 1 行のコードで計算できます。 ベクトル データ型および関連関数についての詳細は、SQL Database Engine におけるベクトルの概要に関するページを参照してください。
次に例を示します。
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
以前のバージョンの SQL Server のベクトル
以前のバージョンの SQL Server エンジン (SQL Server 2022 まで) にはネイティブのベクトル型はありませんが、ベクトルは単に順序付けされたタプルであり、タプルの管理にはリレーショナル データベースが最適です。 タプルは、テーブル内の行の正式な用語と考えることができます。
Azure SQL Database では、列ストア インデックスと バッチ モードの実行もサポートされています。 ベクターベースの手法はバッチ モード処理に使用されます。つまり、バッチ内の各列には、ベクターとして格納される独自のメモリ位置があります。 これにより、データをより迅速かつ効率的にバッチ処理できます。
SQL Database にベクターを格納する方法の例を次に示します。
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
OpenAI を使用して既に生成された埋め込みで Wikipedia の記事の一般的なサブセットを使用する例については、「Azure SQL Database と OpenAI を使用したベクター類似性検索」を参照してください。
Azure SQL データベースでベクトル検索を利用するためのもう 1 つのオプションは、垂直統合機能を使用した Azure AI との統合です。「Azure SQL データベースと Azure AI Search を使用したベクトル検索」を参照してください。
Azure AI Search
Azure SQL データベース とAzure AI Search を使用して RAG パターンを実装します。 Azure AI Search と Azure OpenAI および Azure SQL Database の統合のおかげで、モデルをトレーニングまたは微調整することなく、Azure SQL データベース に格納されているデータでサポートされているチャット モデルを実行できます。 データでモデルを実行すると、データに基づいてチャットしたり、より正確かつ迅速にデータを分析したりできます。
- 独自のデータに基づく Azure OpenAI
- Azure AI Search での取得拡張生成 (RAG)
- Azure SQL データベース と Azure AI Search を使用したベクトル検索
インテリジェントなアプリケーション
Azure SQL データベース は、以下の図のように、レコメンダーや取得拡張生成 (RAG) などの AI 機能を含むインテリジェント なアプリケーションを構築するために使用できます。

セッション要約をサンプル データセットとして使用して AI 対応アプリケーションを構築するエンドツーエンドのサンプルについては、次を参照してください。
LangChain の統合
LangChain は、言語モデルを搭載したアプリケーションを開発するための有名なフレームワークです。 LangChain を使用して独自のデータでチャットボットを作成する方法を示す例については、次を参照してください。
- Azure SQL、Langchain、Chainlit を使用して 1 時間で独自のデータでチャットボットを構築する: Langchain で LLM 呼び出しを調整し、Chainlit で UI を構築して、独自のデータで RAG パターンを使用してチャット ボットを構築します。
- Azure OpenAI GPT-4 を使用して独自の DB Copilot for Azure SQL を構築する: 自然言語を使用してデータベースにクエリを実行する、Copilot に似たエクスペリエンスを構築します。
セマンティック カーネルの統合
セマンティック カーネルは、既存のコードを呼び出すことができるエージェントを簡単に構築できるオープンソース SDK です。 高度に拡張可能な SDK として、OpenAI、Azure OpenAI、Hugging Face などのモデルでセマンティック カーネルを使用できます。 既存の C#、Python、Java コードをこれらのモデルと組み合わせることにより、質問に回答し、プロセスを自動化するエージェントを構築できます。
- 究極のチャットボット?: NL2SQL と RAG の両方のパターンを使用して独自のデータでチャットボットを構築し、究極のユーザー エクスペリエンスを実現します。
- OpenAI 埋め込みサンプル: セマンティック カーネルとカーネル メモリを使用して、SQL Server をベクター データベースとして使用する .NET アプリケーションの埋め込みを操作する方法を示す例。
- セマンティック カーネルとカーネル メモリ - SQL コネクタ - メモリのセマンティック カーネルの SQL Database への接続を提供します。
Azure SQL データベースの Microsoft Copilot スキル
Azure SQL データベースの Copilot スキル(プレビュー) は、Azure SQL データベース駆動型アプリケーションの設計、操作、最適化、正常性を効率化するように設計された AI 支援エクスペリエンスのセットです。 Copilot は、自然言語から SQL への変換とデータベース管理のセルフヘルプを提供することで、生産性を向上させることができます。
Copilot は、ユーザーの質問に対し関連する回答を提供し、データベース コンテキスト、ドキュメント、動的管理ビュー、クエリ ストア、その他のナレッジ ソースを活用してデータベース管理を簡素化します。 次に例を示します。
- データベース管理者は、データベースを独力で管理して問題を解決したり、データベースのパフォーマンスや機能をより詳細に把握したりできます。
- 開発者は、テキストまたは会話の場合と同様にデータについて質問して、T-SQL クエリを生成することができます。 開発者は、生成されたクエリの詳細な説明によって、クエリをより速く記述する方法を習得することもできます。
Note
Azure SQL データベースの Microsoft Copilot スキルは現在、限られた人数の早期導入者向けのプレビュー段階にあります。 このプログラムにサインアップするには、「Azure SQL データベースで Copilot へのアクセスを要求する: プレビュー」を参照してください。
Azure SQL データベース用 Copilot のプレビューには、次の 2 つの Azure portal エクスペリエンスが含まれています。
| ポータルの場所 | エクスペリエンス |
|---|---|
| Azure portal クエリ エディター | 自然言語から SQL: Azure SQL データベースの Azure portal クエリ エディター内でのこのエクスペリエンスにより、自然言語クエリが SQL に変換され、データベースの操作がより直感的になります。 自然言語から SQL への変換機能のチュートリアルと例については、「Azure portal クエリ エディターでの SQL への自然言語 (プレビュー)」を参照してください。 |
| Microsoft Copilot for Azure | Azure コパイロット統合: このエクスペリエンスにより、Microsoft Copilot for Azure に Azure SQL スキルが追加され、お客様にセルフガイド付きアシスタンスが提供され、データベースを管理して問題を独力で解決できるようになります。 |
詳細については、「Azure SQL データベースの Microsoft Copilot スキル (プレビュー) に関してよく寄せられる質問」を参照してください。
Fabric SQL データベースでの Microsoft Copilot スキル (プレビュー)
Microsoft Fabric での Copilot for SQL database (プレビュー) は、次の機能を備えた統合 AI アシスタンスが含まれています。
コード補完: SQL クエリ エディターで T-SQL の記述を開始すると、Copilot によってクエリの完成に役立つコード候補が自動的に生成されます。 Tab キーでコード候補を受け入れるか、候補を無視して入力を続けます。
クイック アクション: SQL クエリ エディターのリボンにある [修正] と [説明] オプションがクイック アクションです。 任意の SQL クエリを強調表示し、クイック アクション ボタンのいずれかを選択して、選択したアクションをクエリに対して実行します。
修正: Copilot は、エラー メッセージが発生した場合にコード内のエラーを修正できます。 エラー シナリオには、不適切な T-SQL コードやサポートされていない T-SQL コード、間違ったスペルなどが含まれます。 また、Copilot は、変更内容を説明し、SQL のベスト プラクティスを提案するコメントも提供します。
説明: Copilot は、SQL クエリとデータベース スキーマの自然言語による説明をコメント形式で提供できます。
チャット ウィンドウ: チャット ウィンドウを使用して、自然言語で Copilot に質問できます。 Copilot は、質問に基づいて、生成された SQL クエリまたは自然言語で応答します。
自然言語から SQL: プレーン テキストのリクエストから T-SQL コードを生成し、質問の提案を得ることで、ワークフローを高速化できます。
ドキュメント ベースの Q&A: 一般的な SQL データベース機能について Copilot に質問すると、自然言語で応答が返されます。 Copilot は、リクエストに関連するドキュメントの検索も支援します。
Copilot for SQL database は、テーブル名とビュー名、列名、主キー、外部キーのメタデータを利用して T-SQL コードを生成します。 Copilot for SQL database は、T-SQL 提案の生成にテーブル内のデータは使用しません。