リージョン間で Log Analytics ワークスペースをレプリケートして回復性を強化する (プレビュー)
リージョン間で Log Analytics ワークスペースをレプリケートすると、レプリケートされたワークスペースに切り替えて、リージョンで障害が発生した場合に運用を続行できるため、回復性が向上します。 この記事では、Log Analytics ワークスペースのレプリケーションのしくみ、ワークスペースをレプリケートする方法、切り替え方法とスイッチバックして元に戻す方法、レプリケートされたワークスペースを切り替える場合を判断する方法について説明します。
Log Analytics ワークスペースのレプリケーションのしくみの概要を説明するビデオを次に示します。
重要
API 呼び出しなどでフェールオーバーという用語を使用することがありますが、一般にフェールオーバーは、自動処理を表すためにも使用されます。 そのため、この記事では、レプリケートされたワークスペースへの切り替えが手動でトリガーする処理であることを強調するために、切り替えという用語を使用します。
Log Analytics ワークスペースのレプリケーションのしくみ
元のワークスペースとリージョンはプライマリと呼ばれます。 レプリケートされたワークスペースと代替リージョンは、セカンダリと呼ばれます。
ワークスペース レプリケーション プロセスでは、セカンダリ リージョンにワークスペースのインスタンスが作成されます。 このプロセスでは、プライマリ ワークスペースと同じ構成でセカンダリ ワークスペースが作成され、Azure Monitor によって、プライマリ ワークスペースの構成に対して将来加える変更でセカンダリ ワークスペースが自動的に更新されます。
セカンダリ ワークスペースは、回復性のみを目的とした "シャドウ" ワークスペースです。 Azure portal のセカンダリ ワークスペースを見ることはできず、直接管理またはアクセスすることもできません。
ワークスペース レプリケーションを有効にすると、Azure Monitor はプライマリ ワークスペースに取り込まれた新しいログをセカンダリ リージョンにも送信します。 ワークスペース レプリケーションを有効にする前にワークスペースに取り込んだログは、コピーされません。
障害がプライマリ リージョンに影響する場合は、すべてのインジェスト要求とクエリ要求をセカンダリ リージョンに切り替えて再ルーティングできます。 Azure で障害が軽減され、プライマリ ワークスペースが再び正常に戻った後は、スイッチバックしてプライマリ リージョンに戻すことができます。
セカンダリに切り替えると、セカンダリ ワークスペースがアクティブになり、プライマリが非アクティブになります。 その後、Azure Monitor は、プライマリ リージョンでなく、セカンダリ リージョンのインジェスト パイプラインを介して新しいデータを取り込みます。 セカンダリ リージョンに切り替えると、Azure Monitor はセカンダリ リージョンからプライマリ リージョンに取り込むすべてのデータをレプリケートします。 このプロセスは非同期であり、インジェストの待機時間には影響しません。
Note
セカンダリ リージョンに切り替えた後、プライマリ リージョンが受信ログ データを処理できない場合、Azure Monitor はセカンダリ リージョン内のデータを最大 11 日間バッファーします。 最初の 4 日間、Azure Monitor はデータを定期的にレプリケートするように自動的に再試行します。

リージョンでの障害時に発生する、転送中のデータの損失に対する保護
Azure Monitor には、プライマリ リージョンで障害が発生した際に転送中のデータが失われないようにするための、いくつかのメカニズムが備わっています。
Azure Monitor は、プライマリ リージョンのパイプラインでデータを処理できない場合、プライマリ リージョンのインジェスト エンドポイントに到達したデータを保護します。 パイプラインが使用可能になると、転送中のデータの処理が続行され、データは Azure Monitor によって取り込まれて、セカンダリ リージョンにレプリケートされます。
プライマリ リージョンのインジェスト エンドポイントが使用できない場合、Azure Monitor エージェントは、エンドポイントへのログ データの送信を定期的に再試行します。 セカンダリ リージョンのデータ インジェスト エンドポイントは、切り替えをトリガーした数分後に、エージェントからのデータ受信を開始します。
ご自分の Log Analytics ワークスペースにログ データを送信する独自のクライアントを作成する場合は、失敗したインジェスト要求が、そのクライアントで処理されていることを確認してください。
デプロイに関する考慮事項
現在、専用クラスターにリンクされている Log Analytics ワークスペースのレプリケーションはサポートされていません。
ワークスペースからレコードを削除する消去操作では、プライマリ ワークスペースとセカンダリ ワークスペースの両方から関連するレコードが削除されます。 ワークスペース インスタンスのいずれかが使用できない場合、消去操作は失敗します。
Azure Monitor では、非アクティブなリージョンのクエリがサポートされています。 アクティブなリージョンのアラート サービスが正常に動作しないか、アラート ルールを使用できない場合を除き、リージョンを切り替えると、クエリベースのアラートは引き続き機能します。 現在、リージョン間でのアラート ルールのレプリケーションはサポートされていません。
Sentinel と対話するワークスペースのレプリケーションを有効にすると、ウォッチリストと脅威インテリジェンスのデータがセカンダリ ワークスペースに完全にレプリケートされるまでに最大 12 日かかることがあります。
ワークスペース管理操作は、切り替え中に開始することはできません。これには次のような場合が含まれます。
- ワークスペースのリテンション期間、価格レベル、日次上限などを変更する
- ネットワーク設定を変更する
- 新しいカスタム ログを使用してスキーマを変更するか、新しいリソース プロバイダーからプラットフォーム ログを接続する (新しいリソースの種類からの診断ログの送信など)
従来の Log Analytics エージェントのソリューション ターゲット機能は、切り替え中はサポートされません。 切り替え中に、すべてのエージェント ソリューション データが取り込まれます。
フェールオーバー プロセスでは、ドメイン ネーム システム (DNS) レコードが更新され、処理のためにすべてのインジェスト要求がセカンダリ リージョンに再ルーティングされます。 HTTP クライアントによっては、接続状態を維持するものがあり、更新後の DNS の再取得に時間がかかる場合があります。 このようなクライアントは、切り替え中に、しばらくの間プライマリ リージョンを介してログの取り込みを試みる場合があります。 プライマリ ワークスペースへのログの取り込みには、従来の Log Analytics エージェント、Azure Monitor エージェント、コード (Logs Ingestion API または従来の HTTP データ収集 API を使用)、Microsoft Sentinel といった他のサービスなど、さまざまなクライアントを使用する可能性があります。
現在、これらの機能はサポートされていないか、部分的にのみサポートされています。
機能 サポート 補助テーブル プラン サポートされていません。 Azure Monitor では、補助ログ プランを使用してテーブル内のデータがセカンダリ ワークスペースにレプリケートされることはありません。 そのため、当該データは、リージョンでの障害が発生した場合のデータ損失から保護されず、セカンダリ ワークスペースに切り替えても使用できません。 ジョブの検索、復元 部分的にサポート - 検索ジョブと復元操作では、テーブルが作成され、それらに検索結果または復元されたデータが入力されます。 ワークスペースのレプリケーションを有効にすると、これらの操作用に作成された新しいテーブルが、セカンダリ ワークスペースにレプリケートされます。 レプリケーションを有効にする前に入力されたテーブルは、レプリケートされません。 切り替えるときにこれらの操作が進行中の場合、予期しない結果が生じます。 正常に完了する可能性もありますが、ワークスペースの正常性とそのタイミングによっては、レプリケートされない、または失敗する場合があります。 Log Analytics ワークスペースに対する Application Insights サポートされていません VM Insights サポートされていません Container Insights サポートされていません プライベート リンク フェールオーバー中はサポートされません
サポートされているリージョン
現在、ワークスペース レプリケーションは、リージョン グループ (地理的に隣接するリージョンのグループ) 別に編成された、限られた一連のリージョン内のワークスペースでサポートされています。 レプリケーションを有効にするときは、ワークスペースのプライマリの場所と同じリージョン グループ内でサポートされているリージョンの一覧からセカンダリの場所を選択します。 たとえば、西ヨーロッパのワークスペースは北ヨーロッパでレプリケートできますが、米国西部 2 ではレプリケートできません。これらのリージョンは異なるリージョン グループ内にあるためです。
現在、次のリージョン グループとリージョンがサポートされています。
| リージョン グループ | 地域 | メモ | ||
|---|---|---|---|---|
| 北米 | 米国東部 | 米国東部リージョンと米国東部 2 および米国中南部リージョンとの間で、レプリケートはできません。 | ||
| 米国東部 2 | 米国東部 2 リージョンと米国東部および米国中南部リージョンとの間で、レプリケートはできません。 | |||
| 米国西部 | ||||
| 米国西部 2 | ||||
| 米国中部 | ||||
| 米国中南部 | 米国中南部リージョンと米国東部および米国東部 2 リージョンとの間で、レプリケートはできません。 | |||
| カナダ中部 | ||||
| ヨーロッパ | 西ヨーロッパ | |||
| 北ヨーロッパ | ||||
| 英国南部 | ||||
| 英国西部 | ||||
| ドイツ中西部 | ||||
| フランス中部 |
データ所在地の要件
お客様によってデータ所在地の要件が異なるため、データの格納場所を制御することが重要です。 Azure Monitor は、選択したプライマリ リージョンとセカンダリ リージョンにログを処理して格納します。 詳細については、「サポートされているリージョン」を参照してください。
Microsoft Sentinel とその他のサービスのサポート
Log Analytics ワークスペースを使用するさまざまなサービスと機能は、ワークスペースのレプリケーションおよび切り替えと互換性があります。 これらのサービスと機能は、セカンダリ ワークスペースに切り替えたときに引き続き機能します。
たとえば、ログ取り込みの待機時間を引き起こす地域ネットワークの問題は、Microsoft Sentinel のユーザーに影響を与える可能性があります。 レプリケートされたワークスペースを使用しているお客様は、セカンダリ リージョンに切り替えて、Log Analytics ワークスペースと Sentinel での処理を続行できます。 ただし、ネットワークの問題が Sentinel サービスの正常性に影響する場合、別のリージョンに切り替えても問題は軽減されません。
現在、Application Insights や VM Insights を含む一部の Azure Monitor エクスペリエンスは、ワークスペースのレプリケーションおよび切り替えと部分的な互換性のみがあります。 完全な一覧については、「展開に関する考慮事項」を参照してください。
価格モデル
ワークスペースのレプリケーションを有効にすると、ワークスペースに取り込むすべてのデータのレプリケーションに対して課金されます。
重要
Azure Monitor エージェント、ログ インジェスト API、Azure Event Hubs、またはデータ収集ルールを使用するその他のデータ ソースを使用してワークスペースにデータを送信する場合は、データ収集ルールをワークスペースのデータ収集エンドポイントに関連付ける必要があります。 この関連付けにより、取り込んだデータがセカンダリ ワークスペースにレプリケートされます。 データ収集ルールをワークスペース データ収集エンドポイントに関連付けないと、データがレプリケートされていない場合でも、ワークスペースに取り込むすべてのデータに対して課金されます。
必要なアクセス許可
| アクション | 必要なアクセス許可 |
|---|---|
| ワークスペースのレプリケーションを有効にする |
Microsoft.OperationalInsights/workspaces/write と Microsoft.Insights/dataCollectionEndpoints/write のアクセス許可。これは、たとえば、監視共同作成者の組み込みロールによって提供されます |
| 切り替えのスイッチオーバーとスイッチバック (フェールオーバーとフェールバックのトリガー) |
Microsoft.OperationalInsights/locations/workspaces/failover、Microsoft.OperationalInsights/workspaces/failback、Microsoft.Insights/dataCollectionEndpoints/triggerFailover/action、および Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action のアクセス許可。これは、たとえば、監視共同作成者の組み込みロールによって提供されます |
| ワークスペースの状態を確認する | たとえば、監視共同作成者の組み込みロールによって提供される、Log Analytics ワークスペースに対する Microsoft.OperationalInsights/workspaces/read 権限 |
ワークスペース レプリケーションを有効または無効にする
REST コマンドを使用して、ワークスペースのレプリケーションを有効または無効にします。 このコマンドは実行時間の長い操作をトリガーします。つまり、新しい設定が適用されるまでに数分かかる場合があります。 レプリケーションを有効にした後、すべてのテーブル (データ型) のレプリケーションが開始するまでに最大 1 時間かかる場合があり、データ型によっては、レプリケーションを開始するタイミングが異なる場合があります。 ワークスペースのレプリケーションを有効にした後にテーブル スキーマに加えた変更 (作成した新しいカスタム ログ テーブルやカスタム フィールド、新しいリソースの種類のために設定された診断ログなど) は、レプリケーションが開始するまでに最大 1 時間かかることがあります。
ワークスペースのレプリケーションを有効にする
Log Analytics ワークスペースでレプリケーションを有効にするには、PUT コマンドを使用します。
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
ここで:
-
<subscription_id>: ワークスペースに関連するサブスクリプション ID。 -
<resourcegroup_name>: Log Analytics ワークスペース リソースを含むリソース グループ。 -
<workspace_name>: ワークスペースの名前。 -
<primary_region>: Log Analytics ワークスペースのプライマリ リージョン。 -
<secondary_region>: Azure Monitor がセカンダリ ワークスペースを作成するリージョン。
サポートされる location 値については、「サポートされているリージョン」を参照してください。
この PUT コマンドは実行時間の長い操作であり、完了するまでに時間がかかる場合があります。 呼び出しが成功すると、200 状態コードが返されます。
要求のプロビジョニング状態の確認の記載に従って、要求のプロビジョニング状態を追跡できます。
要求のプロビジョニング状態を確認する
要求のプロビジョニング状態を確認するには、この GET コマンドを実行します。
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
ここで:
-
<subscription_id>: ワークスペースに関連するサブスクリプション ID。 -
<resourcegroup_name>: Log Analytics ワークスペース リソースを含むリソース グループ。 -
<workspace_name>: Log Analytics ワークスペースの名前。
GET コマンドを使用して、ワークスペースのプロビジョニング状態が Updating から Succeeded に変更され、セカンダリ リージョンが想定どおりに設定されていることを確認します。
Note
Sentinel と対話するワークスペースのレプリケーションを有効にすると、ウォッチリストと脅威インテリジェンスのデータがセカンダリ ワークスペースに完全にレプリケートされるまでに最大 12 日かかることがあります。
データ収集ルールをワークスペース データ収集エンドポイントに関連付ける
Azure Monitor エージェント、ログ インジェスト API、Azure Event Hubs は、設定されたデータ収集ルール (DCR) に基づいて、データを収集し、指定した宛先に送信します。
プライマリ ワークスペースにデータを送信するデータ収集規則がある場合は、システム データ収集エンドポイント (DCE) にルールを関連付ける必要があります。このポイントは、ワークスペースのレプリケーションを有効にすると、Azure Monitor によって作成されます。 ワークスペース データ収集エンドポイントの名前は、ワークスペース ID と同じです。 ワークスペース データ収集エンドポイントに関連付けるデータ収集ルールのみが、レプリケーションと切り替えを有効にします。 この動作により、レプリケートするログ ストリームのセットを指定できるため、レプリケーション コストを抑制するのに役立ちます。
データ収集ルールを使用して収集したデータをレプリケートするには、データ収集ルールをワークスペース データ収集エンドポイントに関連付けます。
Azure portal で、[データ収集ルール] を選択します。
[データ収集ルール] 画面で、プライマリ Log Analytics ワークスペースにデータを送信するデータ収集ルールを選択します。
[データ収集ルール] [概要] ページで、[DCE 構成] を選択し、使用可能な一覧からワークスペース データ収集エンドポイントを選択します。
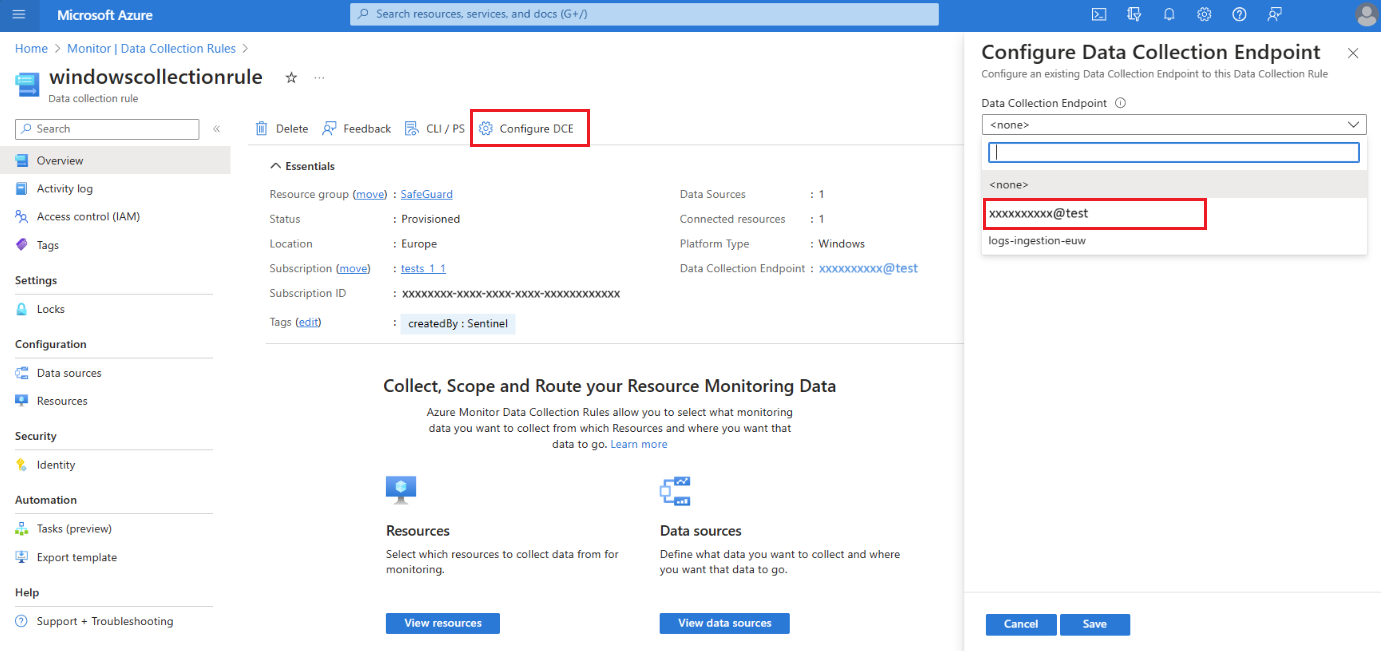 システム DCE の詳細については、ワークスペース オブジェクトのプロパティを確認してください。
システム DCE の詳細については、ワークスペース オブジェクトのプロパティを確認してください。

重要
ワークスペース データ収集エンドポイントに接続されているデータ収集ルールは、その特定のワークスペースのみを対象にすることができます。 データ収集規則は、他のワークスペースや Azure Storage アカウントなどの他の宛先を対象にすることはできません。
ワークスペースのレプリケーションを無効にする
ワークスペースのレプリケーションを無効にするには、PUT コマンドを使用します。
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
ここで:
-
<subscription_id>: ワークスペースに関連するサブスクリプション ID。 -
<resourcegroup_name>: お使いのワークスペース リソースを含むリソース グループ。 -
<workspace_name>: ワークスペースの名前。 -
<primary_region>: ワークスペースのプライマリ リージョン。
この PUT コマンドは実行時間の長い操作であり、完了するまでに時間がかかる場合があります。 呼び出しが成功すると、200 状態コードが返されます。
要求のプロビジョニング状態の確認の記載に従って、要求のプロビジョニング状態を追跡できます。
ワークスペースとサービスの正常性を監視する
インジェストの待機時間やクエリの失敗は、セカンダリ リージョンにフェールオーバーすることによって対処できる可能性がある問題の例です。 このような問題は、Service Health 通知とログ クエリを使用して検出できます。
Service Health 通知は、サービス関連の問題に役立ちます。 特定のワークスペースに影響を与える問題 (サービス全体ではない場合もあります) を特定するには、次のような他のメジャーを使用できます。
- ワークスペース リソースの正常性に基づいてアラートを作成する
- ワークスペースの正常性メトリックに独自のしきい値を設定する
-
クエリを使用したワークスペース パフォーマンスの監視に関する説明に従って、ワークスペースのカスタム正常性インジケーターとして機能する独自の監視クエリを作成します。
- テーブルあたりのインジェスト待機時間を測定する
- 待機時間の原因がコレクション エージェントかインジェスト パイプラインかを特定する
- テーブルとリソースごとのインジェスト量の異常を監視する
- テーブル、ユーザー、リソースごとのクエリの成功率を監視する
- クエリに基づいてアラートを作成する
Note
ログ クエリを使用してセカンダリ ワークスペースを監視することもできますが、ログ レプリケーションはバッチ操作で行われることに注意してください。 測定された待機時間は変動する可能性があり、セカンダリ ワークスペースの正常性の問題を示すわけではありません。 詳細については、非アクティブなワークスペースの監査に関する記事を参照してください。
セカンダリ ワークスペースに切り替える
切り替え中、ほとんどの操作はプライマリ ワークスペースとプライマリ リージョンの使用中と同様に動作します。 ただし、一部の操作に若干異なる動作があるか、ブロックされていることがあります。 詳しくは、「デプロイに関する考慮事項」を参照してください。
切り替える必要がある場面の判断
セカンダリ ワークスペースに切り替える場合を判断し、継続的なパフォーマンスと正常性の監視とシステム標準と要件に基づいて、スイッチバックしてプライマリ ワークスペースに戻します。
次のサブセクションで説明するように、切り替えの計画で考慮すべき点がいくつかあります。
問題の種類とスコープ
切り替えプロセスでは、インジェストとクエリ要求がセカンダリ リージョンにルーティングされます。通常、プライマリ リージョンで待機時間や障害の原因となっている障害のあるコンポーネントがバイパスされます。 その結果、次の場合、切り替えが有効であるとは考えられません。
- 基になるリソースにリージョン間の問題があります。 たとえば、プライマリ リージョンとセカンダリ リージョンの両方で同じリソースの種類に障害がある場合です。
- ワークスペースの保持期間の変更など、ワークスペース管理に関連する問題が発生しています。 ワークスペース管理操作は、常にプライマリ リージョンで処理されます。 切り替え中、ワークスペース管理操作はブロックされます。
問題の期間
切り替えは瞬時には行われません。 要求を再ルーティングするプロセスは DNS の更新に依存します。クライアントによっては数分以内に取得できますが、時間がかかるクライアントもあります。 そのため、その問題が、数分以内に解決できるものかどうかを理解すると役立ちます。 観察された問題が一貫しているか継続的である場合は、切り替えを待つ必要はありません。 次に例をいくつか示します。
インジェスト: プライマリ リージョンのインジェスト パイプラインに関する問題は、セカンダリ ワークスペースへのデータ レプリケーションに影響する可能性があります。 切り替え中は、代わりにセカンダリ リージョンのインジェスト パイプラインにログが送信されます。
クエリ: プライマリ ワークスペース内のクエリが失敗またはタイムアウトした場合、ログ検索アラートが影響を受ける可能性があります。 このシナリオでは、セカンダリ ワークスペースに切り替えて、すべてのアラートが正しくトリガーされるようにします。
セカンダリ ワークスペース データ
レプリケーションを有効にする前にプライマリ ワークスペースに取り込まれたログは、セカンダリ ワークスペースにコピーされません。 3 時間前にワークスペース レプリケーションを有効にし、これからセカンダリ ワークスペースに切り替える場合、クエリは過去 3 時間のデータのみを返します。
切り替え中にリージョンを切り替える前に、セカンダリ ワークスペースに有用なログのボリュームが含まれている必要があります。 レプリケーションを有効にして少なくとも 1 週間が経過してから、切り替えをトリガーすることをお勧めします。 7 日間あれば、セカンダリ リージョンで十分なデータを使用できるようになります。
切り替えをトリガーする
切り替える前に、ワークスペースのレプリケーション操作が正常に完了したことを確認します。 切り替えは、セカンダリ ワークスペースが正しく構成されている場合にのみ成功します。
セカンダリ ワークスペースに切り替えるには、POST コマンドを使用します。
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
ここで:
-
<subscription_id>: ワークスペースに関連するサブスクリプション ID。 -
<resourcegroup_name>: お使いのワークスペース リソースを含むリソース グループ。 -
<secondary_region>: 切り替え中の切り替え先の領域。 -
<workspace_name>: 切り替え中の切り替え先ワークスペースの名前。
この POST コマンドは実行時間の長い操作であり、完了するまでに時間がかかる場合があります。 呼び出しが成功すると、202 状態コードが返されます。
要求のプロビジョニング状態の確認の記載に従って、要求のプロビジョニング状態を追跡できます。
プライマリ ワークスペースへのスイッチバック
スイッチバック プロセスでは、セカンダリ ワークスペースへのクエリとログ インジェスト要求の再ルーティングが取り消されます。 スイッチバックすると、Azure Monitor はクエリのルーティングとインジェスト要求のログ記録をプライマリ ワークスペースに戻します。
セカンダリ リージョンに切り替えると、Azure Monitor はセカンダリ ワークスペースからプライマリ ワークスペースにログをレプリケートします。 障害がプライマリ リージョンのログ インジェスト プロセスに影響する場合、Azure Monitor がプライマリ ワークスペースへのレプリケートされたログの取り込みを完了するまでに時間がかかる場合があります。
スイッチバックすべきタイミングの判断
次のサブセクションで説明するように、スイッチバックの計画で考慮すべき点がいくつかあります。
ログ レプリケーションの状態
スイッチバックする前に、プライマリ リージョンへの切り替え中に取り込まれたすべてのログのレプリケーションが、Azure Monitor によって完了したことを確認します。 すべてのログがプライマリ ワークスペースにレプリケートされる前にスイッチバックすると、ログ インジェストが完了するまでは、クエリで部分的な結果が返されることがあります。
非アクティブなワークスペースの監査に関する説明に従って、Azure portal で非アクティブなリージョンのプライマリ ワークスペースに対してクエリを実行できます。
プライマリ ワークスペースの正常性
プライマリ ワークスペースへのスイッチバックの準備として、次の 2 つの重要な正常性項目をチェックインします。
- プライマリ ワークスペースとリージョンに対する未解決の Service Health 通知がないことを確認します。
- プライマリ ワークスペースがログを取り込み、クエリを想定どおりに処理することを確認します。
セカンダリ ワークスペースがアクティブなときにプライマリ ワークスペースに対してクエリを実行し、セカンダリ ワークスペースへの要求の再ルーティングをバイパスする方法の例については、非アクティブなワークスペースの監査に関する記事を参照してください。
スイッチバックをトリガーする
スイッチバックする前に、プライマリ ワークスペースの正常性を確認し、ログのレプリケーションを完了します。
スイッチバック プロセスによって、DNS レコードが更新されます。 DNS レコードの更新後、すべてのクライアントが更新された DNS 設定を受信し、プライマリ ワークスペースへのルーティングを再開するまでに時間がかかる場合があります。
プライマリ ワークスペースにスイッチバックするには、POST コマンドを使用します。
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
ここで:
-
<subscription_id>: ワークスペースに関連するサブスクリプション ID。 -
<resourcegroup_name>: お使いのワークスペース リソースを含むリソース グループ。 -
<workspace_name>: スイッチバック中の切り替え先ワークスペースの名前。
この POST コマンドは実行時間の長い操作であり、完了するまでに時間がかかる場合があります。 呼び出しが成功すると、202 状態コードが返されます。
要求のプロビジョニング状態の確認の記載に従って、要求のプロビジョニング状態を追跡できます。
非アクティブなワークスペースを監査する
既定では、ワークスペースのアクティブなリージョンはワークスペースを作成するリージョンです。非アクティブなリージョンはセカンダリ リージョンであり、Azure Monitor でレプリケートされたワークスペースが作成されます。
フェールオーバーをトリガーすると、これが切り替わります。つまり、セカンダリ リージョンがアクティブになり、プライマリ リージョンが非アクティブになります。 非アクティブと呼ぶのは、ログ インジェストとクエリ要求の直接のターゲットではないためです。
リージョンを切り替える前に非アクティブ リージョンにクエリを実行して、非アクティブ リージョン内のワークスペースに、そこに表示されるはずのログがあることを確認すると便利です。
非アクティブなリージョンにクエリを実行する
非アクティブ リージョンのログ データに対してクエリを実行するには、次の GET コマンドを使用します。
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
たとえば、セカンダリ リージョンで過去 1 日の Perf | count のような単純なクエリを実行するには、以下を使用します。
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Azure Monitor が目的のリージョンでクエリを実行していることを確認するには、Log Analytics ワークスペース内でクエリ監査を有効にしたときに作成される LAQueryLogs テーブル内でこれらのフィールドを確認します。
-
isWorkspaceInFailover: クエリ中にワークスペースが切り替えモードであったかどうかを示します。 データ型はブール値 (True、False) です。 -
workspaceRegion: クエリの対象となるワークスペースのリージョン。 データ型は String です。
クエリを使用してワークスペースのパフォーマンスを監視する
このセクションのクエリを使用して、ワークスペースの正常性またはパフォーマンスの問題の可能性を通知するアラート ルールを作成することをお勧めします。 ただし、切り替えの決定には慎重な検討が必要であり、自動的に切り替えるようにするべきではありません。
このクエリ ルールでは、指定した数の違反の後にセカンダリ ワークスペースに切り替えるように条件を定義できます。 詳細については、「ログ検索アラート ルールを作成または編集する」を参照してください。
ワークスペースのパフォーマンスの 2 つの重要な測定値には、インジェストの待機時間とインジェストの量が含まれます。 次のセクションでは、これらの監視オプションについて説明します。
エンド ツー エンドのインジェスト待機時間を監視する
インジェスト待機時間は、ログをワークスペースに取り込むのにかかる時間を測定します。 この時間の測定は、ログに記録された最初のイベントが発生したときに開始され、ログがワークスペースに格納されるときに終了します。 インジェストの合計待機時間は、次の 2 つの部分で構成されます。
- エージェントの待機時間: エージェントがイベントを報告するために必要な時間。
- インジェスト パイプライン (バックエンド) の待機時間: インジェスト パイプラインがログを処理してワークスペースに書き込むのに必要な時間。
データ型が異なると、インジェストの待機時間が異なります。 データ型ごとにインジェストを個別に測定する、すべての型に対してジェネリック クエリを作成する、重要度の高い特定の型に対してより詳細なクエリを作成するなどが行えます。 インジェスト待機時間の 90 パーセンタイルを測定することをお勧めします。これは、平均または 50 パーセンタイル (中央値) よりも、変化の影響を受けやすい測定ポイントです。
次のセクションでは、クエリを使用してワークスペースのインジェストの待機時間を確認する方法について説明します。
特定のテーブルのベースライン インジェスト待機時間を評価する
最初に、数日間にわたる特定のテーブルのベースライン待機時間を決定します。
次のクエリ例では、Perf テーブルでインジェスト待機時間の 90 パーセンタイルのグラフを作成します。
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
クエリを実行した後、結果とレンダリングされたグラフを確認して、そのテーブルに予想される待機時間を判断します。
現在のインジェスト待機時間の監視とアラート
特定のテーブルのベースライン インジェスト待機時間を確立したら、短時間の待機時間の変化に基づいて、テーブルのログ検索アラート ルールを作成します。
このクエリでは、過去 20 分間のインジェスト待機時間が計算されます。
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
変動が予想されるため、アラート ルールの条件を作成して、クエリがベースラインより大幅に大きい値を返すかどうかを確認します。
インジェスト待機時間の原因を特定する
インジェストの合計待機時間が増加していることに気付いたら、クエリを使用して、待機時間の原因がエージェントかインジェスト パイプラインかを判断できます。
このクエリでは、エージェントとパイプラインの 90 パーセンタイル待機時間を個別にグラフ化します。
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Note
グラフには 90 パーセンタイル データが積み上げ列として表示されますが、2 つのグラフのデータの合計は、インジェストの 90 パーセンタイルの合計と等しくありません。
インジェスト量を監視する
インジェスト量の測定値は、ワークスペースの合計またはテーブル固有のインジェスト量に対する予期しない変更を特定するのに役立ちます。 クエリ量の測定値は、ログ インジェストに関するパフォーマンスの問題を特定するのに役立ちます。 役立つボリューム測定には、次のようなものがあります。
- テーブルあたりのインジェスト量の合計
- 一定のインジェスト量 (停止)
- インジェストの異常 - インジェスト量の急増と急減
次のセクションでは、クエリを使用してワークスペースのインジェスト量を確認する方法について説明します。
テーブルあたりのインジェストの合計量を監視する
ワークスペース内のテーブルごとに、インジェスト量を監視するクエリを定義できます。 クエリには、合計またはテーブル固有のボリュームに対する予期しない変更をチェックするアラートを含められます。
このクエリでは、テーブルあたりの過去 1 時間のインジェスト量の合計がメガバイト/秒 (MB) で計算されます。
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
インジェストの停止を確認する
エージェントを介してログを取り込む場合は、エージェントのハートビートを使用して接続を検出できます。 停止したハートビートは、ワークスペースへのログ インジェストの停止を示す場合があります。 クエリ データによってインジェストの停止が明らかになった場合は、目的の応答をトリガーする条件を定義できます。
次のクエリでは、エージェントのハートビートをチェックして、接続の問題を検出します。
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
インジェストの異常を監視する
さまざまな方法で、ワークスペース インジェスト量データの急増と急減を特定できます。 series_decompose_anomalies() 関数を使用して、ワークスペースで監視するインジェスト量から異常を抽出するか、独自の異常検出機能を作成して独自のワークスペース シナリオをサポートします。
series_decompose_anomalies を使用して異常を特定する
series_decompose_anomalies() 関数は、一連のデータ値の異常を識別します。 このクエリは、Log Analytics ワークスペース内の各テーブルの 1 時間ごとのインジェスト量を計算し、異常を特定するために series_decompose_anomalies() を使用します。
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
series_decompose_anomalies() を使用してログ データの異常を検出する方法の詳細については、「Azure Monitor で KQL 機械学習機能を使用して異常を検出して分析する」を参照してください。
独自の異常検出機能を作成する
カスタム異常検出機能を作成して、ワークスペース構成のシナリオ要件をサポートできます。 このセクションでは、その過程の例を示します。
次のクエリでは、次の計算が行われます。
- 予想されるインジェスト量: 1 時間あたりのテーブル別 (中央値の中央値に基づきますが、このロジックはカスタマイズできます)
- 実際のインジェスト量: 1 時間あたりのテーブル別
予想されるインジェスト量と実際のインジェスト量の間の意味のない違いを除外するために、クエリは次の 2 つのフィルターを適用します。
- 変化率: 予想される量の 150% を超える、または 66% 未満 (テーブルあたり)
- 変化量: 増加または減少した量が、そのテーブルの月次量の 0.1% を超えているかどうかを示す
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
クエリの成功と失敗を監視する
各クエリは、成功または失敗を示す応答コードを返します。 クエリが失敗したときは、応答にエラーの種類も含まれます。 エラーの急増は、ワークスペースの可用性またはサービスのパフォーマンスに問題があることを示している可能性があります。
このクエリは、サーバー エラー コードを返したクエリの数をカウントします。
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count