Azure Monitor メトリックによる集計と表示の説明
この記事では、Azure Monitor のプラットフォーム メトリックおよびカスタム メトリックの基盤となる時系列データベースでのメトリックの集計について説明します。 この記事は、標準の Application Insights のメトリックにも適用されます。
この記事のこの情報は複雑であり、メトリック システムについてさらに詳しく知る必要のある方を対象としています。 これを理解することは、Azure Monitor のメトリックを効果的に使用するための必須要件ではありません。
概要と用語
グラフにメトリックを追加すると、メトリック エクスプローラーによって自動的に既定の集計が選択されます。 基本的なシナリオでは既定値が適していますが、さまざまな集計を使用することで、メトリックに関する分析情報をさらに得ることができます。 グラフ上でさまざまな集計を表示するには、メトリック エクスプローラーで、これらがどのように処理されるかを理解しておく必要があります。
まず、いくつかの用語を明確に定義します。
- メトリック値 – 特定のリソースに対して収集された 1 つの測定値。
- 時系列データベース - 値と対応するタイムスタンプを含むすべてのデータ ポイントを格納および取得するために最適化されたデータベース。
- 期間 – 一般的な期間。
- 時間間隔 – 2 つのメトリック値を収集する間隔。
- 時間の範囲 – グラフに表示される期間。 通常の既定値は 24 時間です。 特定の範囲のみを指定できます。
- 時間粒度または期間粒度 – 値を全部集計してグラフで表示できるようにするために使用される期間。 特定の範囲のみを指定できます。 現在の最小値は 1 分です。 時間粒度の値を役立つものとするには、選択された時間の範囲よりもこの値を小さくする必要があります。そうしない場合、グラフ全体に 1 つの値のみが表示されます。
- 集計の種類 – 複数のメトリック値から計算された統計の種類。
- 集計 – 複数の入力値を取得し、それらを使用して、集計の種類によって定義されたルールによって 1 つの出力値を生成するプロセス。 たとえば、複数の値の平均を取得します。
プロセスの概要
メトリックは、タイムスタンプと共に格納される一連の値です。 Azure では、ほとんどのメトリックは Azure Metrics の時系列データベースに格納されます。 グラフをプロットすると、選択したメトリックの値がデータベースから取得され、選択した時間粒度 (時間グレインとも呼ばれます) に基づいて個別に集計されます。 時間の細分性のサイズを選択するには、メトリックス エクスプローラーの時刻の選択を使用します。 明示的に選択しない場合、時間粒度は現在選択されている時間の範囲に基づいて自動的に選択されます。 選択されると、それぞれの時間粒度の間隔の間にキャプチャされたメトリック値が集計され、間隔ごとに 1 つのデータポイントがグラフに配置されます。
集計タイプ
メトリックス エクスプローラーでは、5 種類の基本的な集計方法を使用できます。 メトリックス エクスプローラーでは、指定されたメトリックに対して無関係で使用できない集計は非表示になります。
- Sum – 集計間隔でキャプチャされたすべての値の合計。 Total 集計とも呼ばれます。
- Count – 集計間隔でキャプチャされた測定値の数。 Count は、測定値ではなくレコード数のみに注目します。
- Average – 集計間隔でキャプチャされたメトリック値の平均。 ほとんどのメトリックでは、この値は Sum/Count です。
- Min –集計間隔でキャプチャされた値の最小値。
- Max –集計間隔でキャプチャされた値の最大値。
たとえば、過去 24 時間の期間における SUM 集計を使用して、VM の送信ネットワーク合計メトリックを示すグラフがあるとします。 時間の範囲と粒度は、次のスクリーンショットに示すように、グラフの右上から変更できます。
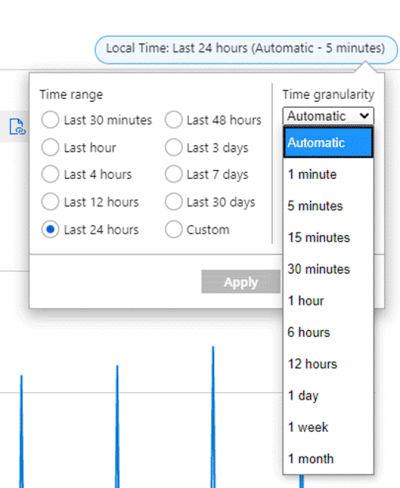
時間粒度が 30 分、時間の範囲が 24 時間の場合:
- グラフは 48 個のデータポイントで描画されます。 つまり、1 分単位のデータポイントが集計されて、24 時間 x 1 時間あたり 2 個 (60 分/30 分) のデータポイントになります。
- 折れ線グラフでは、グラフのプロット エリア上にある 48 個の点が結ばれています。
- 各データポイントは、該当する 30 分の期間ごとに送信されたすべてのネットワーク出力バイト数の合計を表します。

このセクションの画像をクリックすると、より大きなバージョンが表示されます。
時間粒度を 15 分に切り替えると、集計された 96 個のデータポイントからグラフが描画されます。 つまり、60分/15 分 = 4 個 (1 時間あたりのデータポイント) x 24 時間です。

時間粒度が 5 分の場合、24 x (60/5) = 288 ポイントが得られます。
時間粒度が 1 分 (グラフで可能な最小値) の場合、24 x 60/1 = 1440 ポイントが得られます。

これらのグラフは、その合計が、それ以前のスクリーンショットに示すものと異なっています。 この VM では、時間枠のほかの期間に比べて短期間に多数の出力が行われていることに注意してください。
時間の粒度により、グラフの "信号対雑音"比を調整することができます。 集計が大きいほど、雑音が除去されてスパイクが平滑化されます。 一番下の 1 分のグラフの変動の度合いと、粒度の値が大きくなるにつれてこれがどのように平滑化されるかに注目してください。
この平滑化の性質は、このデータを他のシステム (アラートなど) に送信するときに重要です。 通常、短期間に CPU 使用率が 90% を超えるスパイクでは、アラートを受け取る必要はありません。 しかし、CPU 使用率が 5 分間ずっと 90% のままであれば、おそらく重要な情報になります。 CPU (または任意のメトリック) に対してアラート ルールを設定した場合、時間粒度を大きくすると、受信する誤ったアラートの数を減らすことができます。
最適な時間間隔を知るには、ワークロードの "通常の状態" を明確にすることが重要です。 これは動的アラートの利点の 1 つですが、これは別のトピックであり、ここでは取り上げません。
システムがメトリックを収集する方法
データ収集は、メトリックによって異なります。
Note
次の例は図示するために簡略化されており、各集計に含まれる実際のメトリック データは、評価の発生時に使用できるデータの影響を受けます。
測定の収集の頻度
収集期間には 2 つの種類があります。
通常 - 変化しない一定の時間間隔でメトリックが収集されます。
アクティビティ ベース - 特定の種類のトランザクションが発生したタイミングに基づいてメトリックが収集されます。 各トランザクションには、メトリック エントリとタイム スタンプが 1 つずつあります。 これらは一定の間隔で収集されないため、一定の期間に存在するレコード数は一定ではありません。
粒度
最小の時間細分性は 1 分ですが、メトリックによっては、基になるシステムでデータがもっと速くキャプチャされる場合もあります。 たとえば、Azure VM の CPU パーセンテージは 15 秒という時間間隔でキャプチャされます。 HTTP エラーはトランザクションとして追跡されるため、1 分間で 1 個を容易に超える可能性があります。 SQL ストレージなどの他のメトリックは、20 分おきという時間間隔でキャプチャされます。 この選択は、個々のリソース プロバイダーと種類によって決まります。 ほとんどの場合、実行可能な最小時間間隔を指定しようとします。
ディメンション、分割、およびフィルター処理
メトリックは、個々のリソースごとにキャプチャされます。 ただし、メトリックが収集および格納され、グラフ化できるレベルはさまざまである場合があります。 このレベルは、メトリック ディメンションで使用できる他のメトリックによって表現されます。 個々のリソース プロバイダーは、収集するデータの詳細度を定義できます。 Azure Monitor では、そのような詳細データを表示および格納する方法のみが定義されます。
メトリック エクスプローラーでメトリックをグラフ化する場合、グラフをディメンションで "分割" するオプションがあります。 グラフを分割するということは、基になるデータを詳細に調べ、メトリック エクスプローラーでグラフ化またはフィルター処理されたそのデータを表示することを意味します。
たとえば、Microsoft.ApiManagement/service には、多くのメトリックのディメンションとして "場所" があります。
容量は、このようなメトリックの 1 つです。 "場所" ディメンションを持つということは、基になるシステムが、集計量に対して 1 つだけではなく、それぞれの場所の容量のメトリック レコードを格納することを意味します。 次に、その情報をメトリック グラフ内で取得したり分割したりできます。
ゲートウェイ要求の全体の期間を確認すると、"場所" と "ホスト名" の 2 つのディメンションがあります。これにより、ある期間の場所とその元のホスト名がわかります。
より柔軟なメトリックの 1 つである要求には、7 つの異なるディメンションがあります。
各メトリックと使用可能なディメンションの詳細については、Azure Monitor のサポートされているメトリックに関する記事をご覧ください。 さらに、各リソース プロバイダーと種類についてのドキュメントに、ディメンションとその測定対象に関する追加情報が記載されている場合があります。
分割とフィルター処理を併用して、問題を掘り下げることができます。 次に示すのは、リソース グループ内の VM グループの "平均ディスク書き込みバイト数" を示す図の例です。 このメトリックに関するすべての VM がロールアップされていますが、午前 6 時頃のピークの原因が何かを掘り下げて調べたい場合があります。 これらは同じマシンでしょうか。 何台のマシンが関係しているでしょうか。

このセクションの画像をクリックすると、より大きなバージョンが表示されます。
分割を適用すると、基になるデータが表示されますが、表示が少し乱雑になります。 上の図には、20 個の VM が集計されていることがわかります。 この例で、午前 6 時の大きいピークにマウス ポインターを合わせると、CH-DCVM11 が原因であることが示されます。 しかし、他の VM によってグラフが乱雑になっているため、その VM に関連する残りのデータを確認するのは困難です。

フィルターを使用すると、グラフが整理されて、実際に何が起きているかを確認できます。 確認したい VM のチェックボックスをオンまたはオフにすることができます。 点線に注意してください。 これらについては、後のセクションで説明します。

メトリックス エクスプローラーのグラフに分割ディメンション データを表示する方法の詳細については、メトリックス エクスプローラーの高度な機能のフィルターと分割に関する記事を参照してください。
NULL とゼロ値
リソースからメトリック データが来ることが予想されたがシステムで受信されない場合、NULL 値が記録されます。 NULL はゼロ値とは異なり、このことは集計の計算とグラフの作成で重要になります。 NULL 値は有効な測定値としてカウントされません。
NULL は、グラフによって異なる方法で表示されます。 散布図では、グラフ上にドットが表示されません。 横棒グラフでは、バーが表示されません。 折れ線グラフでは、NULL は前のセクションのスクリーンショットに示されているように、点線または破線で表示できます。 NULL を含む平均を計算するとき、平均を取るためのデータポイントの数が少なくなります。 この動作により、グラフ上の値が予期せずに減少することがありますが、値がゼロに変換されて有効なデータポイントとして使用された場合に比べれば、減少はそれほどでもありません。
カスタム メトリックでは、データが受信されない場合は常に NULL を使用します。 プラットフォーム メトリックの場合、各リソース プロバイダーは特定のメトリックにとって最も合理的なものが何であるかに基づいて、0 または NULL のどちらを使用するかを決定します。
Azure Monitor アラートでは、リソース プロバイダーによってメトリック データベースに書き込まれる値が使用されるため、先にデータを表示して、リソース プロバイダーで NULL がどのように処理されるか把握しておくことが重要です。
集計のしくみ
以前のシステムのメトリック グラフには、さまざまな種類の集計データが表示されています。 多数回繰り返される計算なしで要求されたグラフをすばやく表示できるように、システムはデータを事前集計します。
次の点に注意してください。
- HTTP エラーと呼ばれる架空のトランザクション メトリックを収集します
- "サーバー" は HTTP エラー メトリックのディメンションです。
- サーバー A、B、C の 3 つのサーバーがあります。
説明を簡単にするために、最初は SUM 集計の種類のみを使用します。
1 分未満から 1 分単位での集計
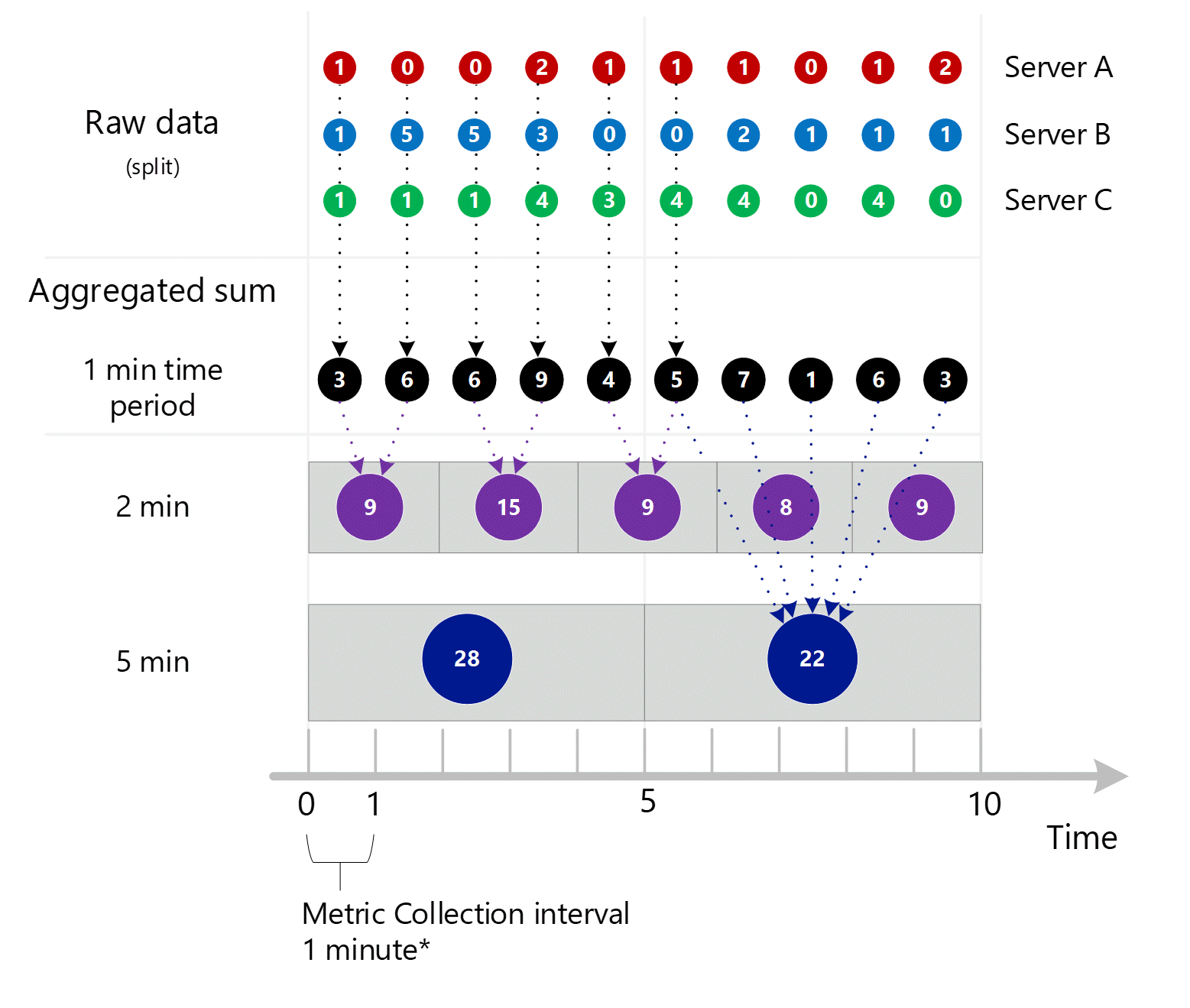
最初の未加工のメトリック データが収集され、Azure Monitor メトリック データベースに格納されます。 この場合、"サーバー" はディメンションであるため、各サーバーにはタイムスタンプが付いたトランザクション レコードが格納されます。 顧客として表示できる最小の期間が 1 分である場合、これらのタイムスタンプは、最初に個々のサーバーに対して 1 分単位のメトリック値に集計されます。 サーバー B についての集計プロセスを下の図に示します。 サーバー A と C についても同じ方法で行われますが、データは異なります。
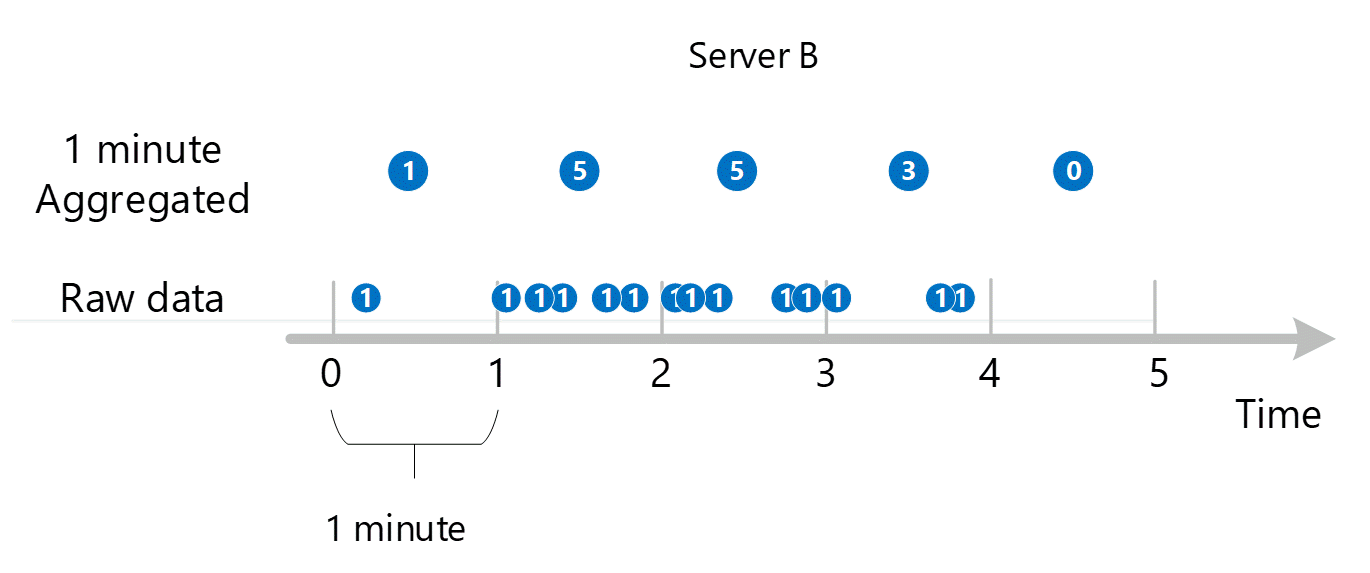
結果として得られた 1 分単位の集計値は新しいエントリとしてメトリック データベースに格納され、後で計算するために収集することができます。
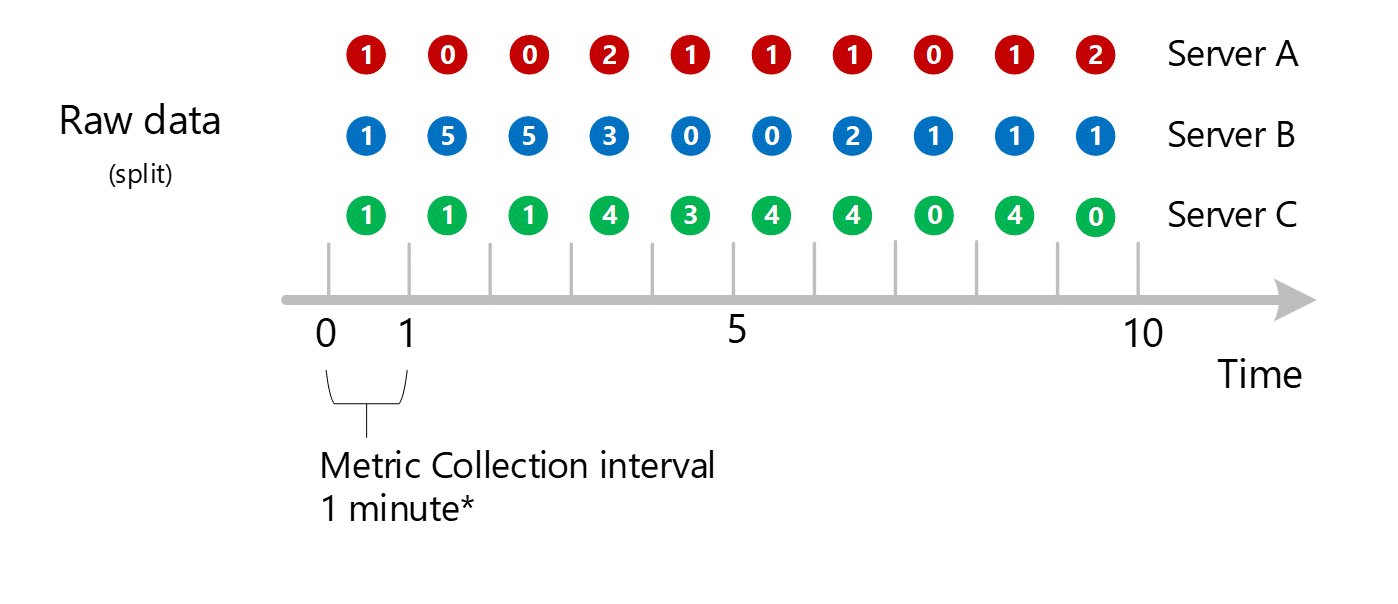
ディメンションの集計
1 分単位の計算値がディメンションで折りたたまれ、再び個別のレコードとして格納されます。 この場合、すべての個々のサーバーからのすべてのデータが、1 分間隔のメトリックに集計され、後の集計で使用できるようにメトリック データベースに格納されます。
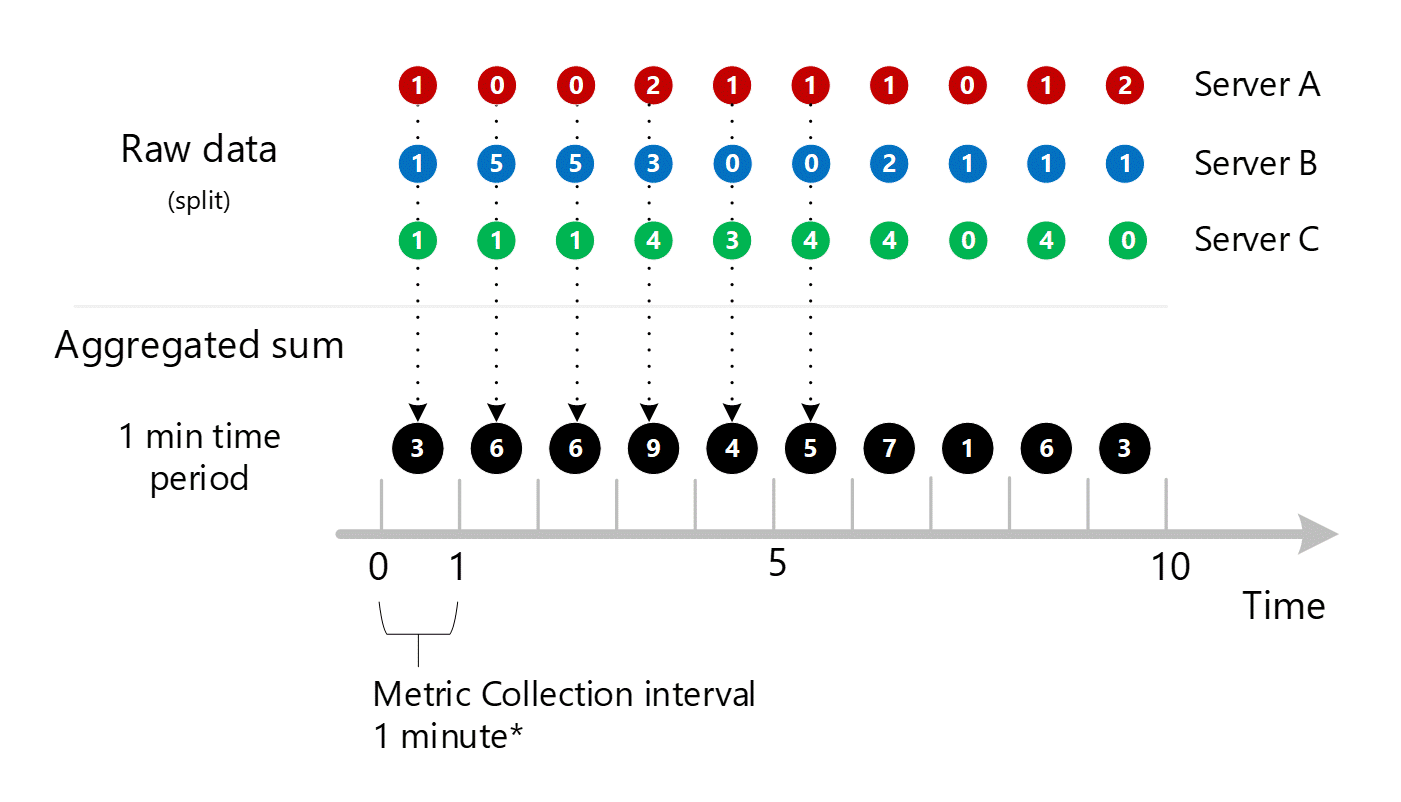
わかりやすくするために、次の表に集計方法を示します。
| 期間 | サーバー A | コンテンツを | コピーする | 合計 (A + B + C) |
|---|---|---|---|---|
| 1 分 | 1 | 1 | 1 | 3 |
| 2 分 | 0 | 5 | 1 | 6 |
| 3 分 | 0 | 5 | 1 | 6 |
| 4 分 | 2 | 3 | 4 | 9 |
| 5 分 | 1 | 0 | 3 | 4 |
| 6 分 | 1 | 0 | 4 | 5 |
| 7 分 | 1 | 2 | 4 | 7 |
| 8 分 | 0 | 1 | 0 | 1 |
| 9 分 | 1 | 1 | 4 | 6 |
| 10 分 | 2 | 1 | 0 | 3 |
上に示すディメンションは 1 つだけですが、メトリックがサポートしているすべてのディメンションに対して、この同じ集計および格納プロセスが発生します。
- そのディメンションによって 1 分単位で集計されたセットに値を収集します。 それらの値を格納します。
- そのディメンションを 1 分単位で集計される SUM に折りたたみます。 それらの値を格納します。
ここで、NetworkAdapter という HTTP エラーの別のディメンションを導入します。 たとえば、サーバーごとに異なる数のアダプターがあるとします。
- サーバー A には 1 つのアダプターがあります
- サーバー B には 2 つのアダプターがあります
- サーバー C には 3 つのアダプターがあります
次のトランザクションのデータを個別に収集します。 次の情報でマークされます。
- 時刻
- 値
- トランザクションの送信元のサーバー
- トランザクションの送信元のアダプター
これらの 1 分未満の各ストリームは、その後 1 分単位の時系列値に集計され、Azure Monitor のメトリック データベースに格納されます。
- サーバー A、アダプター 1
- サーバー B、アダプター 1
- サーバー B、アダプター 2
- サーバー C、アダプター 1
- サーバー C、アダプター 2
- サーバー C、アダプター 3
さらに、次の折りたたまれた集計も格納されます。
- サーバー A、アダプター 1 (折りたたむものがないため再び格納されます)
- サーバー B、アダプター 1+2
- サーバー C、アダプター 1+2+3
- すべてのサーバー、すべてのアダプター
これは、ディメンションの数が多いメトリックは、集計数が多いことを示しています。 すべての順列を理解することは重要ではなく、その理由を理解してください。 システムでは、個々のデータと集計されたデータの両方を格納して、すべてのグラフ上でのアクセスのためにすばやく検索できるようにする必要があります。 システムでは、表示する内容に応じて、最も関連性の高い格納済みの集計か、基になる未加工のデータが選択されます。
ディメンションのない集計
このメトリックには "サーバー" ディメンションがあるため、この記事で既に説明したように、分割とフィルター処理を使用して、上のサーバー A、B、および C の基になるデータにアクセスできます。 このメトリックにディメンションとして "サーバー" が存在しなかった場合、顧客は、図に黒で示した集計された 1 分単位の合計にしかアクセスできません。 つまり、3、6、6、9 といった値です。またシステムでは、分割された値を集計するための基本的な作業が実行されず、メトリック エクスプローラーでそれらが使用されたり、メトリック REST API を使用して送信されたりすることはありません。
1 分より大きい時間粒度の表示
より大きな粒度でメトリックを要求した場合、システムでは 1 分単位の集計合計を使用して、より大きな時間粒度の合計が計算されます。 下の下線は 2 分と 5 分の時間粒度の合計方法を示しています。 ここでも、わかりやすくするために、SUM 集計の種類のみを示しています。
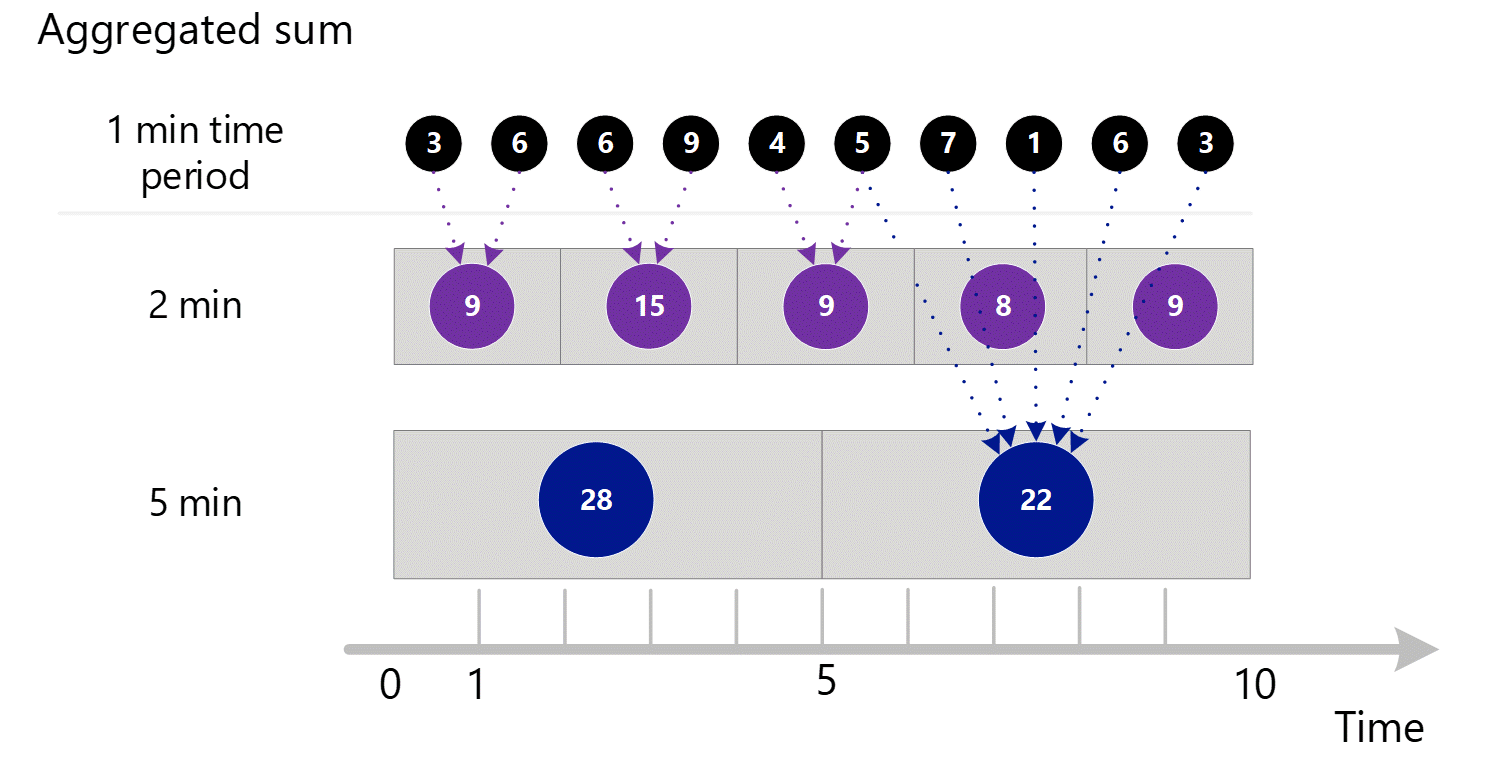
時間粒度が 2 分の場合は、次のようになります。
| 期間 | 合計 |
|---|---|
| 1 分および 2 分 | (3 + 6) = 9 |
| 3 分および 4 分 | (6 + 9) = 15 |
| 4 分および 5 分 | (4 + 5) = 9 |
| 6 分および 7 分 | (7 + 1) = 8 |
| 9 分および 10 分 | (6 + 3) = 9 |
時間粒度が 5 分の場合は、次のようになります。
| 期間 | 合計 |
|---|---|
| 1 分から 5 分 | 3 + 6 + 6 + 9 + 4 = 28 |
| 6 分から 10 分 | 5 + 7 + 1 + 6 + 3 = 22 |
システムは、パフォーマンスが最適となる、格納されている集計データを使用します。
下に示すのは、上記の 1 分単位の集計プロセスの大きな図です。一部の矢印は、読みやすさを向上させるために省略されています。
より複雑な例
次に、HTTP 応答時間と呼ばれる架空のメトリック (ミリ秒単位) の値を使用する、大規模な例を示します。 ここでは、他のレベルの複雑さを導入しています。
- Sum、Count、Min、および Max の集計と平均の計算を示します。
- NULL 値を示し、それらが計算に与える影響について説明します。
各データ メンバー フィールドが JSON オブジェクトにマップされ、フィールド名がオブジェクトの "key" 部分にマップされ、"value" 部分がオブジェクトの値の部分に再帰的にマップされます。 ボックスと矢印は、値の集計および計算方法の例を示しています。
前のセクションで説明したのと同じ 1 分間の事前集計プロセスが、合計、カウント、最小、および最大について実行されます。 ただし、平均は事前集計 "されません"。 計算エラーを回避するために、集計データを使用して再計算されます。

上記で強調表示されているように、1 分単位の集計についての「6 分」目について検討します。 この時間枠は、おそらく再起動が原因でサーバー B がオフラインになり、データのレポートを停止した時点です。
上記の 6 分目に、計算された 1 分単位の集計の種類は次のとおりです。
| 集計の種類 | 値 | メモ |
|---|---|---|
| SUM | 53+20=73 | |
| Count | 2 | NULL の効果を示しています。 サーバーがオンラインになっていれば、値は 3 になります。 |
| 最小値 | 20 | |
| 最大値 | 53 | |
| Average | 73 / 2 | 常に合計をカウントで除算します。 この値は格納されず、常にその時間の粒度の集計値を使用して、時間の粒度ごとに再計算されます。 上記で強調表示されているように、5 分目と 10 分目の時間の粒度の再計算に注意してください。 |
赤色のテキストは、通常の範囲を外れていると見なされる可能性がある値を示し、時間の粒度が大きくなったときに、これらがどのように伝播する (または伝播しない) かを示しています。 "最小値" と "最大値" は、潜在的に異常があることを示していますが、"平均" と "合計" は、時間の粒度が大きくなったときにその情報が失われることに注意してください。
また、NULL を使用すると、代わりにゼロを使用した場合よりも、平均値の計算がより適切になることがわかります。
Note
この例では該当しませんが、メトリックで常に値 1 がキャプチャされる場合、"カウント" は "合計" と等しくなります。 これは、この記事の前の例で説明した HTTP エラーの数など、メトリックでトランザクション イベントの発生が追跡される場合によく見られます。