Kubernetes クラスターの推奨されるアラート ルール
Azure Monitor のアラートは、Azure リソースの正常性とパフォーマンスに関連する問題を事前に識別します。 この記事では、Kubernetes クラスターのために事前に定義されている一連の推奨されるメトリック アラート ルールを有効にしたり、編集したりする方法について説明します。
推奨されるアラート ルールを有効化
クラスターの推奨されるアラート ルールを有効にするには、次の方法のいずれかを使用します。 同じクラスターに対して Prometheus とプラットフォームの両方のメトリック アラート ルールを有効にすることができます。
Note
ARM テンプレートは、Arc 対応 Kubernetes クラスターで推奨されるアラートを有効にするためにサポートされている唯一の方法です。
Azure portal を使用すると、Prometheus ルール グループは、クラスターと同じリージョンに作成されます。
クラスターの [アラート] メニューから、[推奨事項の設定] を選択します。
![[推奨事項の設定] ボタンを示す AKS クラスターのスクリーンショット。](media/kubernetes-metric-alerts/setup-recommendations.png)
使用可能な Prometheus とプラットフォームのアラート ルールが、ポッド、クラスター、ノード レベル別に整理された Prometheus ルールと共に表示されます。 Prometheus ルールのグループを切り替えて、その一連のルールを有効にします。 グループを展開して、個々のルールを確認します。 既定値のままにするか、または個々のルールを無効にして、その名前と重大度を編集できます。
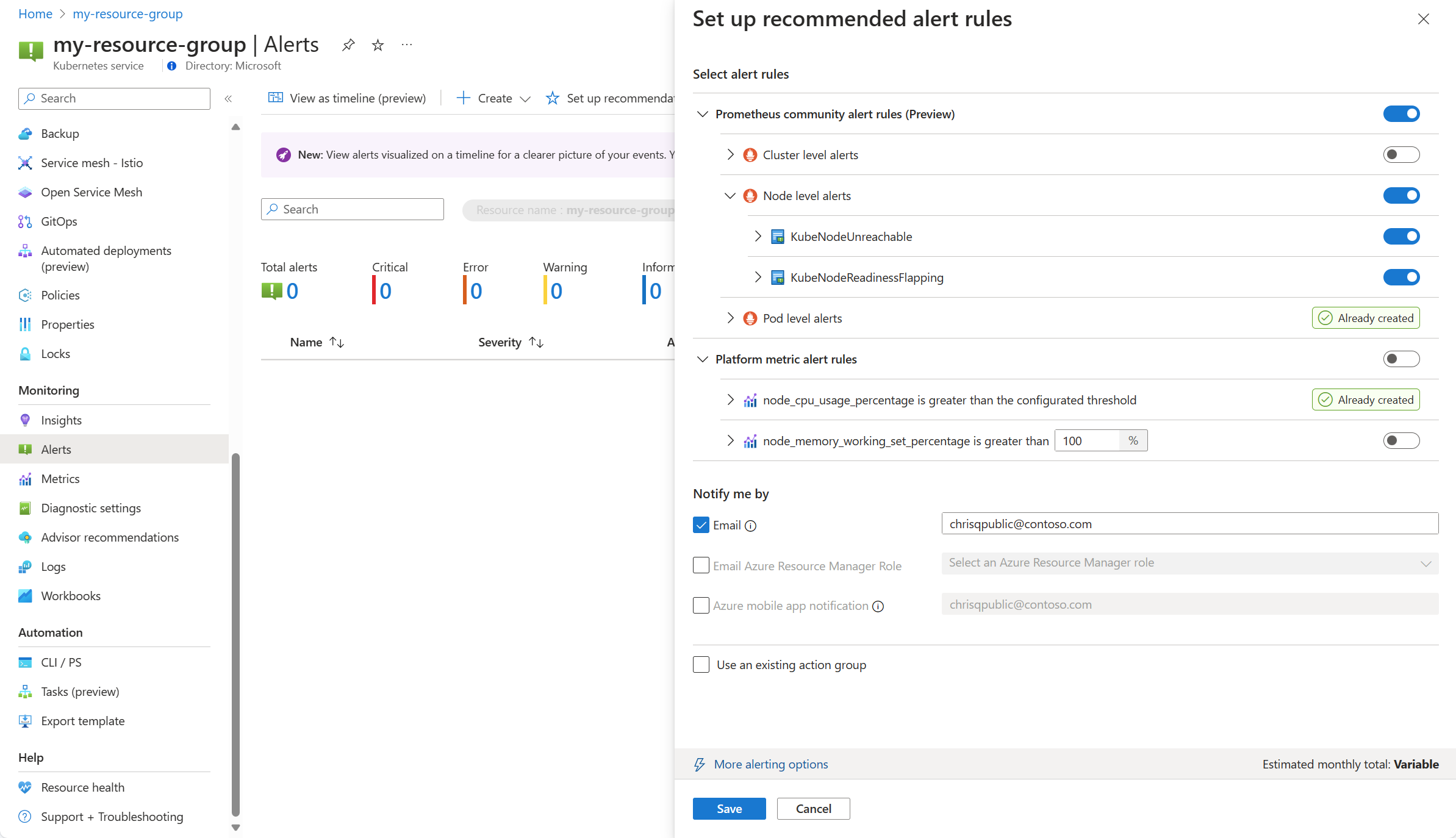
プラットフォームのメトリック ルールを切り替えて、そのルールを有効にします。 ルールを展開して、その詳細 (名前、重大度、しきい値など) を変更できます。

1 つ以上の通知方法を選択して新しいアクション グループを作成するか、またはこの一連のアラート ルールの通知の詳細を含む既存のアクション グループを選択します。
[保存] をクリックしてルール グループを保存します。
![[推奨事項の設定] ボタンを示す AKS クラスターのスクリーンショット。](media/kubernetes-metric-alerts/setup-recommendations.png#lightbox)


推奨されるアラート ルールを編集する
ルール グループが作成された後に、ポータルの同じページを使用してルールを編集することはできません。 Prometheus メトリックの場合、グループ内のルールを変更するには (まだ有効にしていなかったルールの有効化を含む)、そのルール グループを編集する必要があります。 プラットフォームのメトリックの場合は、各アラート ルールを編集できます。
クラスターの [アラート] メニューから、[推奨事項の設定] を選択します。 既に作成されているルールまたはルール グループにはすべて、[既に作成済み] のラベルが付けられます。
ルールまたはルール グループを展開します。 Prometheus の場合は [ルール グループの表示] を、プラットフォームのメトリックの場合は [アラート ルールの表示] をクリックします。
![[ルール グループの表示] オプションのスクリーンショット。](media/kubernetes-metric-alerts/recommended-alert-rules-already-enabled.png)
Prometheus ルール グループの場合は、次の操作を行います。
[ルール] を選択して、グループ内のアラート ルールを表示します。
変更するルールの横にある [編集] アイコンをクリックします。 [アラート ルールを作成する] にあるガイダンスを使用してルールを変更します。

グループ内のルールの編集を完了したら、[保存] をクリックしてルール グループを保存します。
プラットフォームのメトリックの場合は、次の操作を行います。
[編集] をクリックして、アラート ルールの詳細を開きます。 [アラート ルールを作成する] にあるガイダンスを使用してルールを変更します。

![[ルール グループの表示] オプションのスクリーンショット。](media/kubernetes-metric-alerts/recommended-alert-rules-already-enabled.png#lightbox)


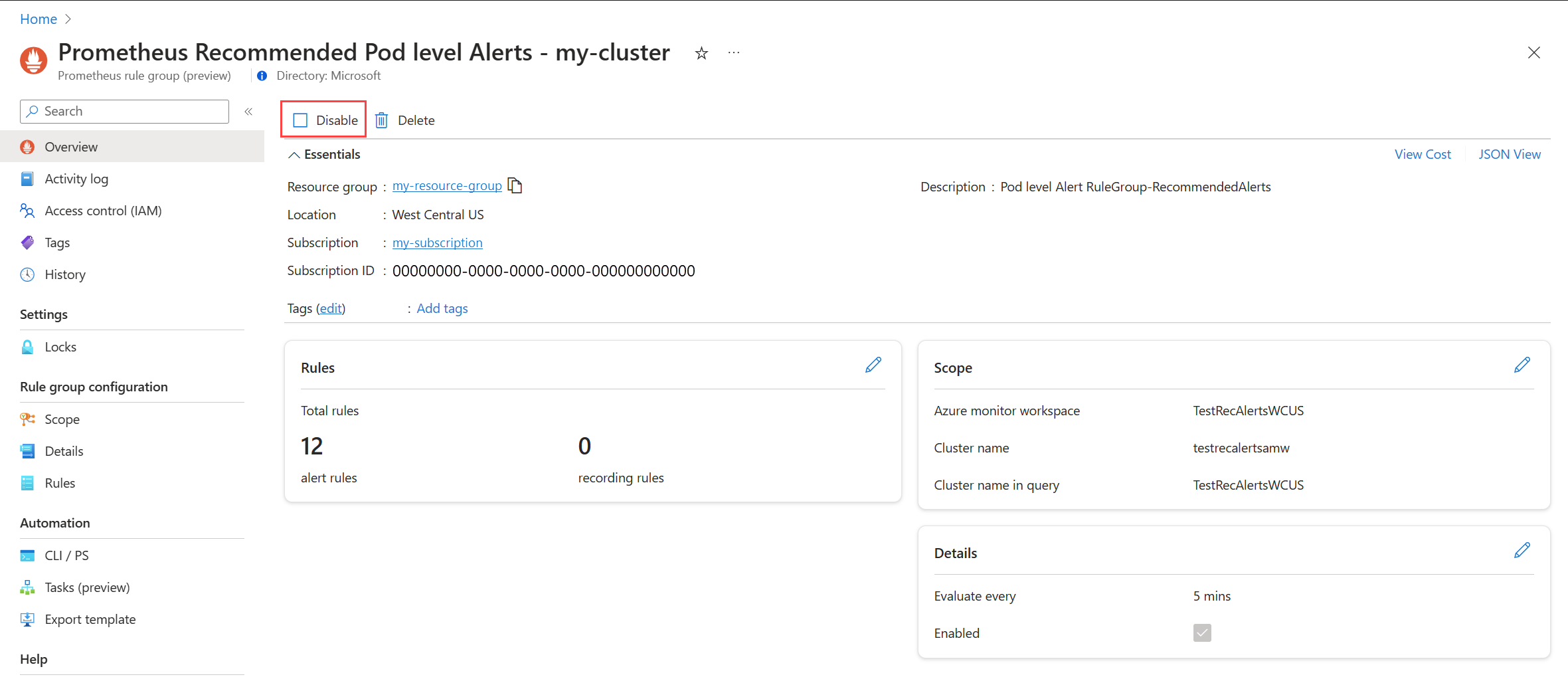
アラート ルール グループを無効にする
ルール グループを無効にして、その中のルールからのアラートの受信を停止します。
「推奨されるアラート ルールを編集する」の説明に従って、Prometheus アラート ルール グループまたはプラットフォームのメトリック アラート ルールを表示します。
[概要] メニューから、[無効にする] を選択します。

推奨されるアラート ルールの詳細
次の表には、推奨される各アラート ルールの詳細が一覧表示されています。 それぞれのソース コードは、GitHub のほか、Prometheus コミュニティのトラブルシューティング ガイドで入手できます。
Prometheus コミュニティのアラート ルール
クラスター レベルのアラート
| アラート名 | 説明 | 既定のしきい値 | 時間枠 (分) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | 名前空間に割り当てられている CPU リソース クォータが、過去 5 分間にクラスターのノード上の使用可能な CPU リソースを 50% 以上超えています。 | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | 名前空間に割り当てられているメモリ リソース クォータが、過去 5 分間にクラスターのノード上の使用可能なメモリ リソースを 50% 以上超えています。 | >1.5 | 5 |
| KubeContainerOOMKilledCount | 過去 5 分間にポッド内の 1 つ以上のコンテナーがメモリ不足 (OOM) イベントのために強制終了されました。 | >0 | 5 |
| KubeClientErrors | Kubernetes API 要求でのクライアント エラー (5xx で始まる HTTP 状態コード) の割合が、過去 15 分間に合計 API 要求レートの 1% を超えています。 | >0.01 | 15 |
| KubePersistentVolumeFillingUp | 永続ボリュームがいっぱいになっており、使用可能な領域の比率、使用済み領域、過去 6 時間の使用可能な領域の予測される線形傾向で評価された使用可能な領域に対して不足することが予想されます。 これらの条件は、過去 60 分にわたって評価されます。 | 該当なし | 60 |
| KubePersistentVolumeInodesFillingUp | 過去 15 分間に永続ボリューム内の inode の 3% 未満が使用可能です。 | <0.03 | 15 |
| KubePersistentVolumeErrors | 過去 5 分間に 1 つ以上の永続ボリュームが失敗または保留中フェーズにあります。 | >0 | 5 |
| KubeContainerWaiting | 過去 60 分間に Kubernetes ポッド内の 1 つ以上のコンテナーが待機状態にあります。 | >0 | 60 |
| KubeDaemonSetNotScheduled | 過去 15 分間に 1 つ以上のポッドがどのノードでもスケジュールされていません。 | >0 | 15 |
| KubeDaemonSetMisScheduled | 過去 15 分間に 1 つ以上のポッドがクラスター内で誤ってスケジュールされています。 | >0 | 15 |
| KubeQuotaAlmostFull | Kubernetes リソース クォータの使用率が、過去 15 分間にハード制限の 90% から 100% までの間にあります。 | >0.9 <1 | 15 |
ノード レベルのアラート
| アラート名 | 説明 | 既定のしきい値 | 時間枠 (分) |
|---|---|---|---|
| KubeNodeUnreachable | 過去 15 分間にノードに到達できませんでした。 | 1 | 15 |
| KubeNodeReadinessFlapping | ノードの準備状態が、過去 15 分間に 3 回以上変更されました。 | 2 | 15 |
ポッド レベルのアラート
| アラート名 | 説明 | 既定のしきい値 | 時間枠 (分) |
|---|---|---|---|
| KubePVUsageHigh | ポッド上の永続ボリューム (PV) の平均使用率が、過去 15 分間に 80% を超えています。 | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | 目的のレプリカの数と過去 10 分間の使用可能なレプリカの数の間に不一致があります。 | 該当なし | 10 |
| KubeStatefulSetReplicasMismatch | StatefulSet 内の準備完了レプリカの数が、過去 15 分間の StatefulSet 内のレプリカの合計数と一致しません。 | 該当なし | 15 |
| KubeHpaReplicasMismatch | クラスター内のポッドの水平オートスケーラーが、過去 15 分間に目的のレプリカの数に適合しませんでした。 | 該当なし | 15 |
| KubeHpaMaxedOut | クラスター内のポッドの水平オートスケーラー (HPA) が、過去 15 分間にレプリカの最大数で実行されました。 | 該当なし | 15 |
| KubePodCrashLooping | 1 つ以上のポッドが CrashLoopBackOff 状態にあります。ここで、このポッドは起動後も継続的にクラッシュし、過去 15 分間正常に回復できていません。 | >=1 | 15 |
| KubeJobStale | 過去 6 時間に少なくとも 1 つのジョブ インスタンスが正常に完了しませんでした。 | >0 | 360 |
| KubePodContainerRestart | Kubernetes クラスターのポッド内の 1 つ以上のコンテナーが、過去 1 時間以内に少なくとも 1 回再起動されました。 | >0 | 15 |
| KubePodReadyStateLow | 準備完了状態にあるポッドの割合が、過去 5 分間に Kubernetes クラスター内のすべてのデプロイまたはデーモンセットで 80% を下回っています。 | <0.8 | 5 |
| KubePodFailedState | 過去 5 分間に 1 つ以上のポッドがエラー状態にあります。 | >0 | 5 |
| KubePodNotReadyByController | 過去 15 分間に 1 つ以上のポッドが準備完了状態にありません (つまり、"保留中" または "不明" フェーズ)。 | >0 | 15 |
| KubeStatefulSetGenerationMismatch | Kubernetes StatefulSet の観察された生成が、過去 15 分間にそのメタデータの生成に適合しません。 | 該当なし | 15 |
| KubeJobFailed | 過去 15 分以内に 1 つ以上の Kubernetes ジョブが失敗しました。 | >0 | 15 |
| KubeContainerAverageCPUHigh | コンテナーあたりの平均 CPU 使用率が、過去 5 分間に 95% を超えています。 | >0.95 | 5 |
| KubeContainerAverageMemoryHigh | コンテナーあたりの平均メモリ使用率が、過去 5 分間に 95% を超えています。 | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | 過去 10 分間にポッドの起動時の待ち時間の 99 パーセンタイルが 60 秒を超えています。 | >60 | 10 |
プラットフォームのメトリック アラート ルール
| アラート名 | 説明 | 既定のしきい値 | 時間枠 (分) |
|---|---|---|---|
| ノード CPU の割合が 95% を超えている | ノード CPU の割合が、過去 5 分間に 95% を超えています。 | 95 | 5 |
| ノードのメモリ ワーキング セットの割合が 100% を超えている | ノード メモリワーキング セットの割合が、最後の 5 分間に 100% を超えています。 | 100 | 5 |
コンテナー分析情報の従来のメトリック アラート (プレビュー)
Container insights のメトリック ルールは、2024 年 5 月 31 日に廃止されました。 これらのルールはパブリック プレビュー段階にありましたが、この記事で説明されている新しい推奨されるメトリック アラートが使用可能になったため、一般提供に達することなく廃止される予定です。
これらの従来のアラート ルールを既に有効にしている場合は、それらを無効にして、新しいエクスペリエンスを有効にする必要があります。
メトリック警告ルールを無効にする
- クラスターの [分析情報] メニューから、[推奨されるアラート (プレビュー)] を選択します。
- 各アラート ルールの状態を [無効] に変更します。
レガシのアラート マッピング
次の表では、それぞれのレガシの Container Insights メトリック アラートを、同等の推奨される Prometheus メトリック アラートにマップします。
| カスタム メトリック推奨アラート | 同等の Prometheus/プラットフォーム メトリック推奨アラート | 条件 |
|---|---|---|
| Completed job count (完了したジョブの数) | KubeJobStale (ポッド レベルのアラート) | 過去 6 時間に少なくとも 1 つのジョブ インスタンスが正常に完了しませんでした。 |
| コンテナー CPU % | KubeContainerAverageCPUHigh (ポッド レベルのアラート) | コンテナーあたりの平均 CPU 使用率が、過去 5 分間に 95% を超えています。 |
| コンテナー作業セット メモリ (%) | KubeContainerAverageMemoryHigh (ポッド レベルのアラート) | コンテナーあたりの平均メモリ使用率が、過去 5 分間に 95% を超えています。 |
| 失敗したポッド数 | KubePodFailedState (ポッド レベルのアラート) | 過去 5 分間に 1 つ以上のポッドがエラー状態にあります。 |
| ノード CPU % | ノード CPU 使用率が 95% より大きい (プラットフォーム メトリック) | ノード CPU の割合が、過去 5 分間に 95% を超えています。 |
| ノード ディスク使用率 % | 該当なし | ノードの平均ディスク使用量が 80% より大きい。 |
| Node NotReady status (NotReady 状態のノード) | KubeNodeUnreachable (ノード レベルのアラート) | 過去 15 分間にノードに到達できませんでした。 |
| ノード ワーキング セット メモリ % | ノードのメモリ ワーキング セットの割合が 100% を超えている | ノード メモリワーキング セットの割合が、最後の 5 分間に 100% を超えています。 |
| OOM Killed Containers (OOM により中止されたコンテナー) | KubeContainerOOMKilledCount (クラスター レベルのアラート) | 過去 5 分間にポッド内の 1 つ以上のコンテナーがメモリ不足 (OOM) イベントのために強制終了されました。 |
| 永続ボリューム使用率 % | KubePVUsageHigh (ポッド レベルのアラート) | ポッド上の永続ボリューム (PV) の平均使用率が、過去 15 分間に 80% を超えています。 |
| Pods ready % (準備完了ポッドの割合 %) | KubePodReadyStateLow (ポッド レベルのアラート) | 準備完了状態にあるポッドの割合が、過去 5 分間に Kubernetes クラスター内のすべてのデプロイまたはデーモンセットで 80% を下回っています。 |
| Restarting container count (コンテナーの再起動回数) | KubePodContainerRestart (ポッド レベルのアラート) | Kubernetes クラスターのポッド内の 1 つ以上のコンテナーが、過去 1 時間以内に少なくとも 1 回再起動されました。 |
従来のメトリックのマッピング
次の表では、各レガシの Container Insights カスタム メトリックを同等の Prometheus メトリックにマップしています。
| カスタム メトリック | 同等の Prometheus メトリック |
|---|---|
| cpuUsageMillicores | rate(container_cpu_usage_seconds_total[5m]) * 1000 |
| cpuUsagePercentage | 100 * rate(container_cpu_usage_seconds_total{cluster="$cluster"}[5m]) |
| cpuUsageAllocatablePercentage | 100 * ( sum by (cluster) (node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{cluster="$cluster"}) / sum by (cluster) (instance:node_num_cpu:sum{cluster="$cluster"}) ) |
| memoryRssByte | container_memory_rss{cluster="$cluster"} |
| memoryRssPercentage | 100 * (sum by (instance, cluster) (container_memory_rss{job="cadvisor", cluster="$cluster"}) / sum by (instance, cluster) (machine_memory_bytes{job="cadvisor", cluster="$cluster"})) |
| memoryRssAllocatablePercentage | 100 * (sum by (node, cluster) (container_memory_rss{cluster="$cluster"}) / sum by (node, cluster) (node_memory_MemTotal_bytes{cluster="$cluster"})) |
| memoryWorkingSetBytes | container_memory_working_set_bytes{cluster="$cluster"} |
| memoryWorkingSetPercentage | 100 * (sum by (node, cluster) (container_memory_working_set_bytes{cluster="$cluster"}) / sum by (node, cluster) (node_memory_MemTotal_bytes{cluster="$cluster"})) |
| nodesCount | count(kube_node_status_condition{condition="Ready", status="true", cluster="$cluster"}) |
| diskUsedPercentage | 100 * (node_filesystem_size_bytes{cluster="$cluster"} - node_filesystem_free_bytes{cluster="$cluster"}) / node_filesystem_size_bytes{cluster="$cluster"} |
| podCount | count(count by (pod, namespace, cluster) (kube_pod_info{cluster="$cluster"})) |
| completedJobsCount | count(kube_job_status_succeeded{status="true", cluster="$cluster"} and time() - kube_job_status_start_time > 6 * 3600) |
| restartingContainerCount | sum by(container, namespace, cluster) (rate(kube_pod_container_status_restarts_total{cluster="$cluster"}[5m])) |
| oomKilledContainerCount | sum by(container, namespace, cluster) (kube_pod_container_status_terminated_reason{reason="OOMKilled", cluster="$cluster"}) |
| podReadyPercentage | 100 * (sum(kube_pod_status_phase{phase="Running", cluster="$cluster"}) by (namespace, cluster) / sum(kube_pod_status_phase{phase!="Succeeded", cluster="$cluster"}) by (namespace, cluster)) |