DISKSPD を使用してワークロード ストレージのパフォーマンスをテストする
適用対象: Azure Stack HCI バージョン 22H2 および 21H2。Windows Server 2022、Windows Server 2019
重要
Azure Stack HCI が Azure Local の一部になりました。 製品ドキュメントの名前変更が進行中です。 ただし、古いバージョンの Azure Stack HCI (22H2 など) は引き続き Azure Stack HCI を参照し、名前の変更は反映されません。 詳細情報。
このトピックでは、DISKSPD を使用して、ワークロード ストレージのパフォーマンスをテストする方法に関するガイダンスを提供します。 Azure Stack HCI クラスターのセットアップが終わり、すべての準備が整ったとします。 それはすばらしいことですが、待機時間、スループット、IOPS など、約束されたパフォーマンス メトリックを獲得できているかどうかは、どのようにして知ることができるのでしょうか。 DISKSPD は、このような時に役立ちます。 このトピックを読み終えると、DISKSPD を実行する方法を知り、パラメーターのサブセットについて理解し、出力を解釈し、ワークロード ストレージのパフォーマンスに影響を与える変数について全体的に理解することができます。
DISKSPD とは
DISKSPD は、I/O を生成する、マイクロベンチマークのためのコマンドライン ツールです。 では、これらの用語の意味は何でしょうか。 Azure Stack HCI クラスターまたは物理サーバーを設定するすべてのユーザーには、それを行う理由があります。 これは、Web ホスティング環境を設定したり、従業員の仮想デスクトップを実行したりすることなどです。 実際のユース ケースにかかわらず、ユーザーは実際のアプリケーションをデプロイする前にテストをシミュレートしたいと考えるでしょう。 しかし、多くの場合、実際のシナリオでアプリケーションをテストすることは困難です。ここで、DISKSPD の出番となります。
DISKSPD は、カスタマイズして独自の合成ワークロードを生成し、アプリケーションをデプロイする前にテストすることができるツールです。 このツールの優れた点は、実際のワークロードに似た特定のシナリオを作成するために、パラメーターの構成と調整を自由に行うことができる点です。 DISKSPD を使用することで、システムをデプロイする前に、その能力をおおまかに把握することができます。 DISKSPD によって行われるのは、根本的には数多くの読み取りと書き込み操作の発行です。
DISKSPD について理解したところで、この使用タイミングについて見ていきましょう。 DISKSPD は、複雑なワークロードのエミュレーションにはあまり適していません。 しかし、ワークロードがシングルスレッドのファイル コピーによって密接に近似しておらず、許容可能なベースラインとなる結果を出すシンプルなツールが必要な場合には、DISKSPD は最適です。
クイック スタート: DISKSPD をインストールして実行する
DISKSPD をインストールして実行するには、管理 PC で管理者として PowerShell を開き、次の手順に従います。
DISKSPD ツールの ZIP ファイルをダウンロードして展開するには、次のコマンドを実行します。
# Define the ZIP URL and the full path to save the file, including the filename $zipName = "DiskSpd.zip" $zipPath = "C:\DISKSPD" $zipFullName = Join-Path $zipPath $zipName $zipUrl = "https://github.com/microsoft/diskspd/releases/latest/download/" +$zipName # Ensure the target directory exists, if not then create if (-Not (Test-Path $zipPath)) { New-Item -Path $zipPath -ItemType Directory | Out-Null } # Download and expand the ZIP file Invoke-RestMethod -Uri $zipUrl -OutFile $zipFullName Expand-Archive -Path $zipFullName -DestinationPath $zipPathdisksPD ディレクトリを
$PATH環境変数に追加するには、次のコマンドを実行します。$diskspdPath = Join-Path $zipPath $env:PROCESSOR_ARCHITECTURE if ($env:path -split ';' -notcontains $diskspdPath) { $env:path += ";" + $diskspdPath }次の PowerShell コマンドを使用して DISKSPD を実行します。 角かっこを適切な設定に置き換えます。
diskspd [INSERT_SET_OF_PARAMETERS] [INSERT_CSV_PATH_FOR_TEST_FILE] > [INSERT_OUTPUT_FILE.txt]実行できるコマンドの例を次に示します。
diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c5G C:\ClusterStorage\test01\targetfile\IO.dat > test01.txtNote
テスト ファイルがない場合は、-c パラメーターを使用して作成します。 このパラメーターを使用する場合は、パスを定義するときにテスト ファイル名を含めてください。 例: [INSERT_CSV_PATH_FOR_TEST_FILE] = C:\ClusterStorage\CSV01\IO.dat。 このコマンド例において、IO.dat はテスト ファイル名で、test01.txt は DISKSPD 出力ファイル名です。
キー パラメーターを指定する
ここまでの手順は、シンプルだったかと思います。 残念ながら、それ以上のものがあります。 ここまでの作業を紐解いていきましょう。 まず、細かく調整することが可能な様々なパラメーターが提供されており、これによってより具体的に指定することができます。 しかし、ここでは以下のような一連の基準パラメーターを使用しました。
Note
DISKSPD パラメーターでは大文字と小文字が区別されます。
-t2: ターゲット/テスト ファイルあたりのスレッド数を示します。 この数は多くの場合、CPU コアの数に基づいています。 ここでは、すべての CPU コアに負荷をかけるため、2 つのスレッドが使用されました。
-o32: スレッドあたりのターゲットあたりの未処理の I/O 要求の数を示します。 これは、キューの深さとも呼ばれます。ここでは、CPU に負荷をかけるため、32 個が使用されました。
-b4K: ブロック サイズ (バイト、KiB、MiB、または GiB) を示します。 ここでは、ランダム I/O テストをシミュレートするために 4K ブロック サイズが使用されました。
-r4K: 指定したサイズ (バイト、KiB、MiB、Gib、またはブロック) にアラインされたランダム I/O を示します ( -s パラメーターをオーバーライドします)。 一般的な4K バイト サイズは、ブロック サイズに適切に対応するために使用されていました。
-w0: 書き込み要求である操作の割合を指定します (-w0 は読み取り 100% に相当します)。 ここでは、単純なテストの目的で 0% 書き込みが使用されました。
-d120: これは、クールダウンやウォームアップを含まない、テストの期間を指定します。 既定値は 10 秒ですが、重要なワークロードには少なくとも 60 秒を使用することをお勧めします。 ここでは、外れ値を最小化するために 120 秒が使用されました。
-Suw: ソフトウェアとハードウェアの書き込みキャッシュを無効にします ( Sh と同等)。
-D: 標準偏差などの IOPS 統計をミリ秒単位 (スレッドごと、ターゲットごと) でキャプチャします。
-L: 待機時間の統計情報を測定します。
-c5g: テストで使用されるサンプル ファイル サイズを設定します。 これは、バイト、KiB、MiB、GiB、またはブロックで設定できます。 ここでは、5 GB のターゲット ファイルが使用されました。
パラメーターの完全な一覧については、GitHub リポジトリを参照してください。
環境を理解する
パフォーマンスは環境によって大きく異なります。 では、Microsoft の環境はどのようなものなのでしょうか。 Microsoft の仕様には、記憶域プールと記憶域スペース ダイレクト (S2D) を備えた Azure Stack HCI クラスターが含まれています。 具体的には、DC、node1、node2、node3、および管理ノードの 5 つの VM があります。 クラスター自体は、3 方向ミラーによる回復性構造を備えた 3 ノード クラスターです。 そのため、3 つのデータ コピーが保持されます。 クラスター内の各 "ノード" は、最大 IOPS 制限が1920 の Standard_B2ms VM です。 各ノード内には、最大 IOPS 制限が 5000 の 4 つの premium P30 SSD ドライブがあります。 最後に、各 SSD ドライブには 1 TB のメモリがあります。
ドライブのプール全体を使用するため、クラスターの共有ボリューム (CSV) で提供される統一名前空間 (C:\ClusteredStorage) の下にテスト ファイルを生成します。
Note
この例の環境には、Hyper-V または入れ子になった仮想化構造は "ありません"。
後で説明するように、VM やドライブの制限で IOPS や帯域幅の上限に個別に到達する可能性はあります。 そのため、VM のサイズとドライブの種類を理解することが重要です。これは、どちらも最大 IOPS 制限と帯域幅上限があるためです。 この知識は、ボトルネックを特定し、パフォーマンスの結果を理解する上で役立ちます。 ワークロードに適したサイズの詳細については、次のリソースを参照してください。
出力を理解する
パラメーターと環境について理解できたので、出力を解釈する準備が整いました。 まず、前のテストの目的は、待機時間を考えずに IOPS を最大化することでした。 これにより、Azure 内の人為的な IOPS の上限に達しているかどうかを視覚的に確認できます。 合計 IOPS をグラフィックで視覚化するには、Windows Admin Center またはタスク マネージャーを使用します。
次の図は、この例の環境における DISKSPD プロセスがどのように見えるかを示しています。 ここでは、コーディネーター以外のノードからの 1 MiB 書き込み操作の例が示されています。 3 方向の回復性構造は、コーディネーター以外のノードからの操作と共に 2 つのネットワーク ホップにつながるため、パフォーマンスが低下します。 コーディネーター ノードについて知らなくても問題ありません。 これについては、「考慮事項」セクションで説明します。 赤い四角形は VM とドライブのボトルネックを表します。

視覚的に理解できたところで、次は .txt ファイル出力の 4 つの主要なセクションを確認してみましょう。
入力設定
このセクションでは、実行したコマンド、入力パラメーター、およびテストの実行に関する他の詳細について説明します。
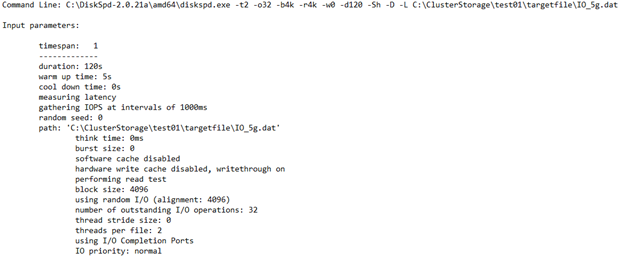
CPU 使用率の詳細
このセクションでは、テスト時のテスト時間、スレッドの数、使用可能なプロセッサの数、および CPU コアごとの平均使用率などの情報について説明します。 ここでは、使用率の平均が 4.67% の CPU コアが 2 つあります。
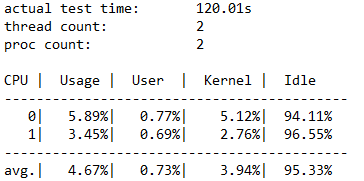
I/O の合計数
このセクションには、3 つのサブセクションが含まれます。 最初のセクションでは、読み取り操作と書き込み操作の両方を含む、全体的なパフォーマンス データに注目します。 2 番目と 3 番目のセクションでは、読み取り操作と書き込み操作を別々のカテゴリに分けています。
この例では、120 秒間の I/O 数の合計が 234408 であったことがわかります。 したがって、IOPS = 234408 /120 = 1953.30 です。 平均待機時間は 32.763 ミリ秒で、スループットは 7.63 MiB/秒でした。 前の情報から、この 1953.30 IOPS は Standard_B2ms VM の IOPS 上限である 1920 に近いことがわかります。 信じられないでしょうか。 キューの深さを増やすなどして、別のパラメーターを使用してこのテストを再実行すると、結果がこの数に制限されたままであることがわかります。
最後の 3 列は、17.72 の IOPS の標準偏差 (-D パラメーター)、20.994 ミリ秒の待機時間の標準偏差 (-L パラメーター)、およびファイル パスを示しています。
結果から、クラスター構成が非常に良くないことがすぐに判断できます。 SSD の制限である 5000 に達する前に、VM の制限である 1920 に達していることが確認できます。 VM ではなく SSD によって制限された場合、テスト ファイルを複数のドライブに行き渡らせることで、最大 20000 IOPS (4 ドライブ * 5000) の利点を利用することができます。
最終的には、実際のワークロードに対してどのような値が許容されるかを決定する必要があります。 次の図は、トレードオフを検討するのに役立ついくつかの重要な関係性を示しています。
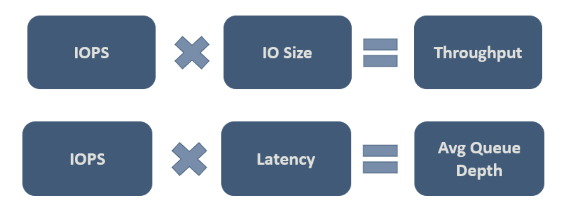
図の 2 番目の関係性は重要であり、これはリトルの法則とも呼ばれています。 この法則では、プロセスの行動を支配する 3 つの特性があり、1 つを変えるだけで他の 2 つに影響を与え、ひいてはプロセス全体に影響を与えることができるという考え方が取り入れられました。 そのため、システムのパフォーマンスに不満がある場合、これに影響を与える自由には 3 つの次元があります。 リトルの法則では、この例における IOPS は "スループット" (1 秒あたりの入力出力操作) であり、待機時間は "キュー時間" であり、キューの深さは "インベントリ "であることが規定されています。
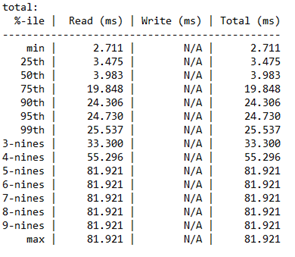
待機時間のパーセンタイル分析
この最後のセクションでは、ストレージのパフォーマンスにおける操作の種類ごとに示されたパーセンタイルの待機時間の詳細を、最小値から最大値まで詳しく説明します。
このセクションは IOPS の "品質" を決定するため、重要です。 これによって、I/O 操作の内、特定の待機時間の値を達成することができた数を確認できます。 そのパーセンタイルにおいて許容できる待機時間は、ユーザーの判断に委ねられます。
さらに、"nines" は、9 の数を意味します。 たとえば、“3-nines” は 99 パーセンタイルに相当します。 9 の数は、そのパーセンタイルで実行された I/O 操作の数を表します。 最終的には、遅延値を重要視しても意味がない段階に到達します。 ここでは、待機時間の値が "4-nines" 以降は横ばいであることがわかります。 この段階において、待機時間の値は、234408 回の操作ごとに 1 回の I/O 操作に基づきます。





考慮事項
DISKSPD の使用を開始したところで、実際のテスト結果を取得するために考慮すべき点がいくつかあります。 これには、設定したパラメーターに細心の注意を払うこと、記憶域スペースの正常性と変数、CSV の所有権、DISKSPD とファイル コピーの違いなどが含まれます。
DISKSPD と実際の環境
DISKSPD の人工的なテストでは、実際のワークロードと比べて近い結果が得られます。 しかし、設定したパラメーターと、それが実際のシナリオに一致するかどうかに注意する必要があります。 合成ワークロードでは、デプロイ時におけるアプリケーションの実際のワークロードを完全には再現できないことを理解することが重要です。
準備
DISKSPD テストを実行する前に行うことが推奨される、いくつかのアクションがあります。 これには、記憶域スペースの正常性の確認、別のプログラムがテストに干渉しないためのリソースの使用状況の確認、および追加データを収集する必要がある場合はパフォーマンス マネージャーの準備などが含まれます。 しかし、このトピックの目的は DISKSPD をすばやく実行することであるため、これらの操作の詳細については説明しません。 詳細については、「Windows Server で合成ワークロードを使用して記憶域スペースのパフォーマンスをテストする」を参照してください。
パフォーマンスに影響を与える変数
ストレージのパフォーマンスは、非常に繊細です。 つまり、これはパフォーマンスに影響を与える可能性のある変数が多数あることを意味します。 そのため、期待通りではない数字に遭遇することも稀ではないでしょう。 次に、パフォーマンスに影響を与えるいくつかの変数を示します。ただし、これはすべての一覧ではありません。
- ネットワーク帯域幅
- 回復性の選択
- ストレージ ディスクの構成: NVME、SSD、HDD
- I/O バッファー
- キャッシュ
- RAID 構成
- ネットワーク ホップ
- ハード ドライブのスピンドル速度
CSV の所有権
ノードは、ボリューム所有者または coordinator ノードと呼ばれます (コーディネーター以外のノードは、特定のボリュームを所有していないノードになります)。 すべての Standard ボリュームにはノードが割り当てられ、他のノードからはネットワーク ホップを介してこの Standard ボリュームにアクセスできますが、この結果としてパフォーマンスが低下します (待機時間が長くなります)。
同様に、クラスターの共有ボリューム (CSV) にも "所有者" がいます。 ただし、CSV は、システムを再起動するたびにホップされ、所有権が変わるという意味で "動的" です (RDP)。 そのため、CSV を所有しているコーディネーター ノードから DISKSPD が実行されていることを確認することが重要です。 それ以外の場合は、CSV の所有権を手動で変更しなければならないことがあります。
CSV の所有権を確認するには:
次の PowerShell コマンドを実行して、所有権を確認します。
Get-ClusterSharedVolumeCSV の所有権が正しくない場合 (たとえば、Node1 を使用しているが、Node2 によって CSV が所有されている場合)、次の PowerShell コマンドを実行して CSV を適切なノードに移動します。
Get-ClusterSharedVolume <INSERT_CSV_NAME> | Move-ClusterSharedVolume <INSERT _NODE_NAME>
ファイル コピーと DISKSPD
巨大なファイルをコピーして貼り付け、そのプロセスにかかる時間を測定することで、"ストレージのパフォーマンスをテストする" ことができると考える人もいます。 このアプローチを取る主な理由は、シンプルで速いからというのが主でしょう。 この考え方は、特定のワークロードをテストするという意味では間違っていませんが、この方法を "ストレージのパフォーマンスのテスト" として分類するのは困難です。
実際の目標がファイル コピーのパフォーマンスをテストすることである場合、この方法を使用する理由としては非常に有効なものになるかもしれません。 しかし、ストレージのパフォーマンスを測定することが目的の場合は、この方法を使用しないことをお勧めします。 ファイル コピーのプロセスには、ファイル サービスに固有の異なる一連の "パラメーター" (キュー、並列化など) が使用されていると考えることができます。
次の簡単な概要では、ファイル コピーを使ってストレージのパフォーマンスを測定しても、求めている結果が得られない場合がある理由を説明しています。
ファイルのコピーが最適化されていない可能性がある並列処理には、内部と外部の 2 つのレベルがあります。 内部的には、リモート ターゲットに対するファイル コピーが行われている場合、CopyFileEx エンジンにはいくつかの並列処理が適用されます。 外部的には、CopyFileEx エンジンを呼び出すにはさまざまな方法があります。 たとえば、ファイル エクスプローラーからのコピーはシングル スレッドですが、Robocopy はマルチスレッドです。 このような理由から、テストが意味することが自分の求めているものなのかどうかを理解することが大切です。
すべてのコピーには 2 つの側がある。 ファイルをコピーして貼り付けるときに、ソース ディスクとコピー先ディスクの 2 つのディスクを使用している可能性があります。 ある一方の速度がもう一方より遅い場合、基本的にはより遅い方のディスクのパフォーマンスを測定することになります。 他にも、ソース、コピー先、およびコピー エンジン間の通信が、独自の方法でパフォーマンスに影響を与える場合があります。
詳細については、ファイル コピーを使用してストレージのパフォーマンスを測定する方法に関するページを参照してください。
実験と一般的なワークロード
このセクションには、他のいくつかの例、実験、およびワークロードの種類が含まれています。
コーディネーター ノードを確認する
前述のように、現在テストしている VM が CSV を所有していない場合は、ノードが CSV を所有しているときにテストするのではなく、パフォーマンスの低下 (IOPS、スループット、待機時間) が表示されます。 これは、I/O 操作を発行するたびに、システムではコーディネーター ノードへのネットワーク ホップを実行してその操作を実行するためです。
3 ノードの 3 方向ミラーの場合、3 ノードにまたがるすべてのドライブにデータを保存する必要があるため、書き込み操作では常にネットワーク ホップが行われます。 そのため、書き込み操作では関係なくネットワーク ホップが発生します。 ただし、別の回復性構造を使用すると、これが変わる場合があります。
次に例を示します。
- ローカル ノードでの実行: diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
- 非ローカル ノードでの実行: diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
この例では、下の図の結果に表れているように、コーディネーター ノードによって CSV が所有されている場合、待機時間が減少し、IOPS が増加し、スループットが向上していることがよくわかります。

オンライン トランザクション処理 (OLTP) ワークロード
オンライン トランザクション処理 (OLTP) ワークロード クエリ (Update、Insert、Delete) は、トランザクション指向のタスクに重点を置いています。 OLTP はオンライン分析処理 (OLAP) と比較して、ストレージの待機時間に依存します。 操作ごとに発生する I/O は少ないので、ここで注目すべきは 1 秒あたりに維持できる操作の数です。
ランダムで小規模な I/O パフォーマンスに焦点を当てた OLTP ワークロード テストを設計することができます。 これらのテストでは、許容できる待機時間を維持しつつ、スループットをどこまで向上させることができるかに焦点を当てます。
このワークロード テストの基本的な設計には、少なくとも次のものが必要です。
- 8 KB のブロック サイズ => SQL Server でデータ ファイルに使用されるページ サイズに似ています
- 70% 読み取り、30% 書き込み => 一般的な OLTP 動作に似ています
オンライン分析処理 (OLAP) ワークロード
OLAP ワークロードはデータ取得と分析に重点を置いており、これによりユーザーは多次元データを抽出するための複雑なクエリを実行することができます。 OLTP とは対照的に、これらのワークロードはストレージの待機時間の影響を受けません。 帯域幅を気にせずに多くの操作をキューに追加することを重視しています。 その結果、OLAP ワークロードの処理時間は長くなる傾向にあります。
シーケンシャルで大規模な I/O パフォーマンスに焦点を当てた OLAP ワークロード テストを設計することができます。 これらのテストでは、IOPS の数ではなく、1 秒あたりに処理されるデータの量に注目します。 待機時間の要件もあまり重要ではありませんが、これは主観的なものです。
このワークロード テストの基本的な設計には、少なくとも次のものが必要です。
512 KB ブロック サイズ => SQL Server が先読み技術を使用して 64 データ ページを一括で読み込んでテーブル スキャンするときの一般的な I/O のサイズに似ています。
1 ファイルあたり 1 スレッド => 現在は、複数のシーケンシャル スレッドをテストするときに DISKSPD で問題が発生するおそれがあるため、テストはファイルごとに 1 つのスレッドに制限する必要があります。 2 つ以上のスレッド、例えば 2 つ のスレッドと -s パラメーターを使用すると、スレッドは、同じ場所にある I/O 操作を相互に発行するために、非決定論的に開始されます。 これは、それぞれが独自のシーケンシャル オフセットを追跡するためです。
この問題を解決するには、次の 2 つの "解決策" があります。
最初の解決策では、-si パラメーターを使用します。 このパラメータを使用すると、両方のスレッドで 1 つのインタロックされたオフセットが共有され、スレッドが協力してターゲット ファイルへのアクセスの 1 つのシーケンシャル パターンを発行するようになります。 これにより、ファイル内の特定の 1 点が 1 回以上操作されることがなくなります。 ただし、I/O 操作をキューに発行するための競合は発生するため、操作が順番に受信されないことがあります。
このソリューションは、1 つのスレッドが CPU によって制限されるようになった場合に適しています。 2 番目の CPU コアに 2 つ目のスレッドを連携して、より多くのストレージ I/O をCPU システムに供給することで、さらに飽和させることができます。
2 番目のソリューションでは、-T<offset> を使用します。 これを使用すると、異なるスレッドによって同じターゲット ファイルで実行される I/O 操作間のオフセット サイズ (I/O 間隔) を指定できます。 たとえば、スレッドは通常オフセット 0 から開始されますが、この仕様を使用することで、2 つのスレッドが互いに重ならないように距離を離すことができます。 マルチスレッド環境では、スレッドが動作中のターゲットの異なる部分にある可能性が高いため、これはそのような状況をシミュレートするための方法です。
次のステップ
回復性の設定を最適化する方法と、その詳細な例については、以下も参照してください。