Azure Durable Functions のディザスター リカバリーと地理的分散
Microsoft は、Azure サービスを常に使用できるようにする作業に取り組んでいます。 そうはいっても、計画されていないサービスの停止が発生する可能性はあります。 アプリケーションで回復性が必要な場合は、geo 冗長性を確保するようにアプリを構成することをお勧めします。 さらに、お客様は、リージョン規模のサービス停止に対処するため、ディザスター リカバリー計画を用意する必要があります。 ディザスター リカバリー計画の重要な部分は、プライマリ レプリカが使用できなくなった場合に、アプリとストレージのセカンダリ レプリカにフェールオーバーするための準備をすることです。
Durable Functions では、すべての状態が既定で Azure Storage に保持されます。 タスク ハブは、オーケストレーションとエンティティに使用される Azure Storage リソースの論理コンテナーです。 オーケストレーター関数、アクティビティ関数、エンティティ関数は、同じタスク ハブに属しているときに限り、情報をやり取りすることができます。 このドキュメントでは、これらの Azure Storage リソースの高可用性を保つためのシナリオを説明するときに、タスク ハブを参照します。
Note
この記事のガイダンスでは、Durable Functions のランタイム状態を格納するために既定の Azure Storage プロバイダーを使用していることを想定しています。 ただし、状態を他の場所に格納する代替の記憶域プロバイダー (SQL Server データベースなど) を構成することもできます。 代替の記憶域プロバイダーの場合は、異なるディザスター リカバリーと地理的分散の戦略が必要になる場合があります。 代替の記憶域プロバイダーの詳細については、Durable Functions 記憶域プロバイダーに関するドキュメントを参照してください。
オーケストレーションとエンティティは、HTTP またはサポートされている他の Azure Functions トリガーの種類のいずれかを使用してトリガーされるクライアント関数を使用してトリガーできます。 これらは、組み込みの HTTP API を使用してトリガーすることもできます。 わかりやすくするために、この記事では Azure Storage と HTTP ベースの関数トリガーが関係するシナリオと、ディザスター リカバリー アクティビティ中の可用性を向上させ、ダウンタイムを最小限に抑えるオプションに焦点を当てています。 Service Bus トリガーや Azure Cosmos DB トリガーなどの他のトリガーの種類は、明確には取り上げません。
次のシナリオでは、Azure Storage の使用を前提としたアクティブ/パッシブ構成が使用されていることにご注意ください。 このパターンは、異なるリージョンに、バックアップ (パッシブ) 関数アプリを展開することで構成されます。 Traffic Manager により、プライマリ (アクティブ) 関数アプリの HTTP 可用性が監視されます。 プライマリに障害が発生した場合、バックアップ関数アプリにフェールオーバーします。 詳細については、Azure Traffic Manager の「優先順位トラフィック ルーティング方法」をご覧ください。
Note
- 提案されているアクティブ/パッシブ構成では、クライアントは常に HTTP 経由で新しいオーケストレーションをトリガーできます。 ただし、2 つの関数アプリがストレージ内の同じタスク ハブを共有するため、一部のバックグラウンド ストレージ トランザクションがこれらの関数アプリに分散されます。 そのため、この構成では、セカンダリ関数アプリのエグレス コストが追加で発生します。
- 基になるストレージ アカウントとタスク ハブは、プライマリ リージョンで作成され、2 つの関数アプリによって共有されます。
- 冗長的に展開されているすべての関数アプリが、HTTP 経由でアクティブ化されている場合、同じ関数アクセス キーを共有する必要があります。 関数ランタイムでは、コンシューマー がプログラミングによって関数キーを追加、削除、および更新を有効化できるよう、管理 API を使用します。 Azure Resource Manager API を使用してキーを管理することもできます。
シナリオ 1: 共有ストレージを使用して負荷分散されたコンピューティング
Azure のコンピューティング インフラストラクチャに障害が発生した場合、関数アプリが使用できなくなる危険性があります。 このようなダウンタイムの危険性を最小限に抑えるため、このシナリオでは、異なるリージョンに展開された 2 つの関数アプリを使用します。 Traffic Manager は、プライマリ関数アプリの問題を検出し、自動的にセカンダリ リージョンにある関数アプリにトラフィックをリダイレクトするように構成されます。 この関数アプリは、タスク ハブと同じ Azure Storage アカウントを共有します。 これにより、関数アプリの状態の損失が防止され、作業が正常に再開できます。 プライマリ リージョンの正常性が復元されると、Azure Traffic Manager はその関数アプリへのルーティング要求を自動的に開始します。
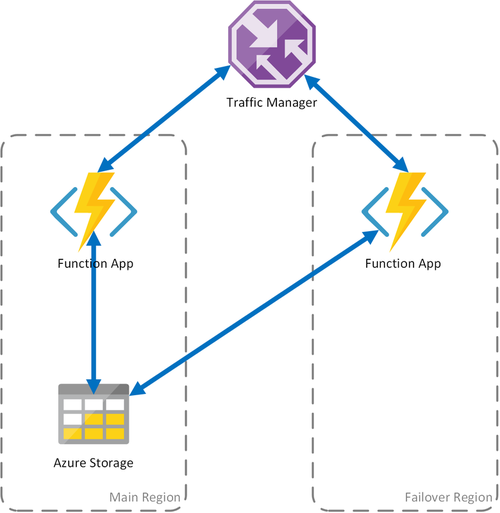
この展開シナリオを使用する利点は、いくつかあります。
- コンピューティング インフラストラクチャで障害が発生した場合、データを失うことなく、フェールオーバー リージョンで作業を再開できます。
- Traffic Manager によって、正常な関数アプリへの自動フェールオーバーが自動的に実行されます。
- 障害から復旧すると、Traffic Manager によってプライマリ関数アプリへのトラフィックが自動的に再確立されます。
ただし、このシナリオを使用する場合は、以下の点を検討してください。
- 専用の App Service プランを使用して関数アプリを展開している場合には、フェールオーバー データ センター内のコンピューティング インフラストラクチャをレプリケートするとコストが増加します。
- このシナリオでは、コンピューティング インフラストラクチャの障害には対応できますが、ストレージ アカウントが関数アプリの単一障害点であることに変わりはありません。 ストレージで障害が発生した場合、アプリケーションではダウンタイムが発生します。
- 関数アプリがフェールオーバーしても、リージョンを超えてストレージ アカウントにアクセスするため、待機時間は増加します。
- ストレージが存在するリージョンと異なるリージョンからストレージ サービスにアクセスすると、ネットワーク エグレス トラフィックのため、コストが増加します。
- このシナリオは、Traffic Manager に依存します。 Traffic Manager のしくみを考えると、Durable Function を使用するクライアント アプリケーションが 関数アプリのアドレスを Traffic Manager から再取得するまで時間がかかる可能性があります。
Note
Durable Functions 拡張機能の v 2.3.0 以降では、同じストレージ アカウントとタスク ハブ構成で、2 つの関数アプリを同時に、かつ安全に実行できます。 最初に起動するアプリによって、アプリケーションレベルの BLOB リースが取得されます。これにより、他のアプリによってタスク ハブのキューからメッセージが盗まれるのを防ぐことができます。 この最初のアプリの実行が停止すると、そのリースは期限切れになり、2 つ目のアプリで取得できるようになります。その後、タスク ハブ メッセージの処理に進みます。
v2.3.0 より前のバージョンでは、同じストレージ アカウントを使用するように構成されている関数アプリによって、メッセージが処理され、ストレージの成果物が同時に更新されるため、全体的な待機時間とエグレス コストが大幅に増加します。 プライマリ アプリとレプリカ アプリに異なるコードが一時的にでも配置されたことがある場合は、2 つのアプリ間のオーケストレーター関数の不整合により、オーケストレーションが正常に実行されないこともあります。 そのため、ディザスター リカバリーのために地理的分散を必要とするすべてのアプリで、v2.3.0 以上の Durable Functions 拡張機能を使用することをお勧めします。
シナリオ 2: リージョンのストレージを使用して負荷分散されたコンピューティング
上記のシナリオでは、コンピューティング インフラストラクチャの障害の場合のみ対応できます。 ストレージ サービスで障害が発生すると、関数アプリのダウンタイムが発生します。 Durable Functions の運用を続けるため、このシナリオでは、関数アプリが展開されている各リージョンのローカル ストレージ アカウントを使用します。
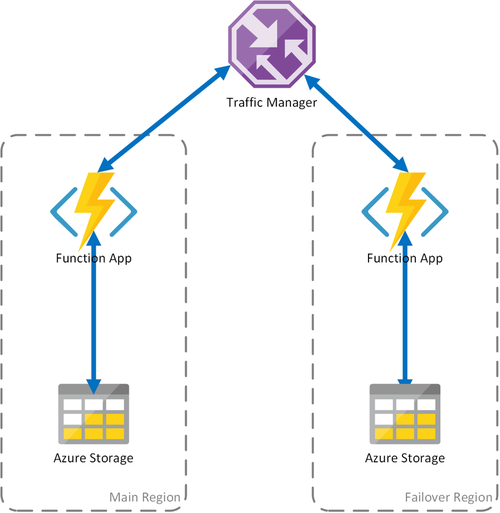
この方法は、前述のシナリオを改善します。
- 関数アプリで障害が発生した場合、Traffic Manager によって、セカンダリ リージョンにフェールオーバーします。 ただし、関数アプリは専用のストレージを使用しているため、Durable Functions は実行され続けます。
- 関数アプリとストレージ アカウントは併置されているため、フェイル オーバー中、フェールオーバーするリージョンでの待機時間は増加しません。
- ストレージ層で障害が発生すると Durable Functions が失敗し、これによりフェールオーバー リージョンへのリダイレクトが開始されます。 この場合も、関数アプリとストレージは異なるリージョンにあるため、Durable Functions の実行は継続されます。
このシナリオの重要な注意事項を以下に示します。
- 専用の App Service プランを使用して関数アプリを展開している場合には、フェールオーバー データ センター内のコンピューティング インフラストラクチャをレプリケートするとコストが増加します。
- 現在の状態はフェールオーバーされません。これは、プライマリ リージョンが復旧するまで、既存のオーケストレーションとエンティティが実質的に一時停止して使用できなくなることを意味します。
要約すると、最初のシナリオと 2 番目のシナリオのトレードオフは、待機時間が維持され、エグレス コストが最小限に抑えられますが、ダウンタイム中は既存のオーケストレーションとエンティティが使用できなくなることです。 これらのトレードオフが許容できるかどうかは、アプリケーションの要件によって異なります。
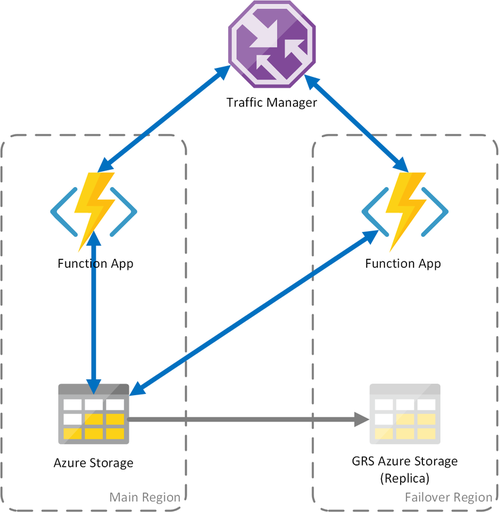
シナリオ 3: GRS 共有ストレージを使用した負荷分散
このシナリオは最初のシナリオの変形版で、共有ストレージ アカウントを実装します。 主な違いは、geo レプリケーションを有効にしてストレージ アカウントが作成されることです。 機能的には、このシナリオにはシナリオ 1 と同じ利点がありますが、データ復旧という利点が追加されます。
- 読み取りアクセス GRS (RA-GRS) アクセスおよび geo 冗長ストレージ (GRS) は、ストレージ アカウントの可用性を最大化します。
- ストレージ サービスのリージョンで障害が発生した場合は、セカンダリ レプリカへのフェールオーバーを手動で開始することができます。 大きな災害のためにリージョンが失われるような極端な状況では、Microsoft がリージョン間のフェールオーバーを開始できます。 この場合、ユーザーによる操作は必要ありません。
- フェールオーバーが発生すると、Durable Functions の状態が、ストレージ アカウントのレプリケーションの最近のレプリケーションまで保存されます。これは通常、数分ごとに実行されます。
他のシナリオと同様、このシナリオにも重要な注意事項があります。
- レプリカへのフェールオーバーには時間がかかることがあります。 フェールオーバーが完了し Azure Storage DNS レコードが更新されるまで、関数アプリは停止します。
- geo レプリケートされたストレージ アカウントを使用するには追加のコストがかかります。
- GRS レプリケーションによりデータが非同期的にコピーされます。 レプリケーション処理の遅延のため、最近のトランザクションが失われている危険性があります。
Note
シナリオ 1 で説明したように、この方法でデプロイされる関数アプリでは、Durable Functions 拡張機能の v 2.3.0 以降を使用することを強くお勧めします。
詳細については、Azure Storage の「ディザスター リカバリーとストレージ アカウントのフェールオーバー」のドキュメントを参照してください。