Azure Managed Redis (プレビュー) のフェールオーバーとファイルの部分置換
回復性の高い優れたクライアント アプリケーションを構築するには、Azure Managed Redis (プレビュー) サービスでのフェールオーバーを理解することが重要です。 フェールオーバーは、計画された管理操作の一環であることも、計画外のハードウェアやネットワーク障害で発生することもあります。 一般的にキャッシュ フェールオーバーは、管理サービスが Azure Managed Redis バイナリに修正プログラムを適用するときに使用します。
この記事では、次の情報を確認します。
- フェールオーバーとは
- 修正プログラムの適用中にフェールオーバーがどのように発生するか。
- 回復性があるクライアント アプリケーションを構築する方法。
フェールオーバーとは
まず、Azure Managed Redis のフェールオーバーの概要について説明します。
キャッシュ アーキテクチャの簡単な概要
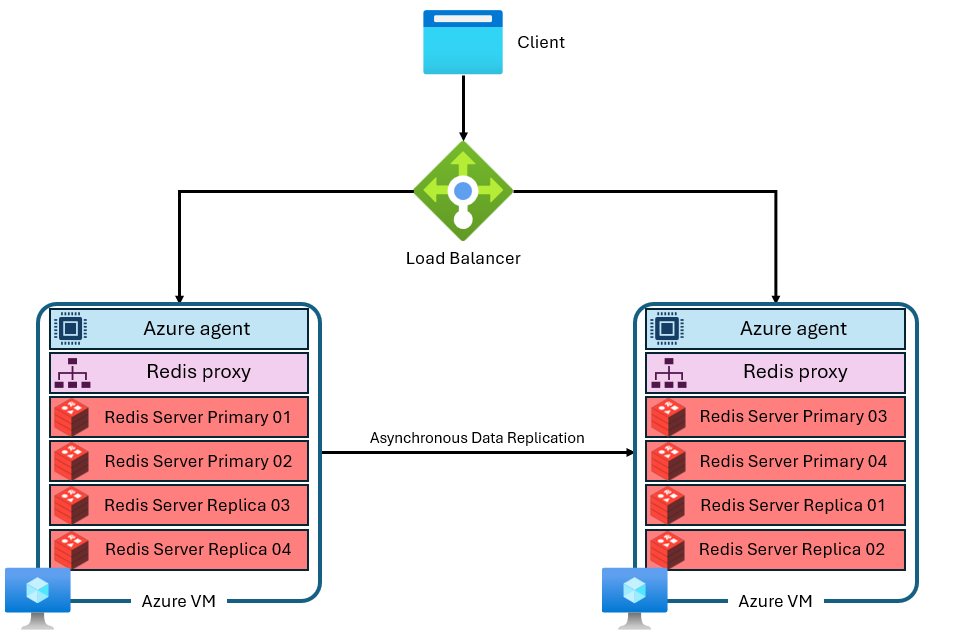
キャッシュは、個別のプライベート IP アドレスを持つ複数の仮想マシンで構成されます。 各仮想マシン (または "ノード") は、複数の Redis サーバー プロセス ("シャード" と呼ばれる) を並列で実行します。 複数のシャードを使用すると、各仮想マシンで vCPU をより効率的に使用し、パフォーマンスを向上させることができます。 すべてのプライマリ Redis シャードが同じ VM/ノード上にあるわけではありません。 そうではなく、プライマリ シャードとレプリカ シャードは両方のノードに分散されます。 プライマリ シャードはレプリカ シャードよりも多くの CPU リソースを使用するため、この方法では、より多くのプライマリ シャードを並列で実行できます。 各ノードには、シャードの管理、接続管理の処理、自己復旧のトリガーを行う高パフォーマンス プロキシ プロセスがあります。 他のシャードが使用可能な状態であるとき、1 つのシャードがダウンしている場合があります。
Azure Managed Redis アーキテクチャの詳細については、ここを参照してください。
フェールオーバーの説明
1 つ以上のレプリカ シャードが自身をプライマリ シャードに昇格させ、古いプライマリ シャードが既存の接続を閉じると、フェールオーバーが発生します。 フェールオーバーは、計画されている場合とされていない場合があります。
"計画されたフェールオーバー" は、次の 2 つの異なるときに実行されます。
- Redis の修正プログラムの適用や OS のアップグレードなどのシステムの更新時。
- スケーリングや再起動などの管理操作時。
ノードには更新が事前通知されているため、ロールを協調的に交換し、ロード バランサーをすばやく変更で更新できます。 計画フェールオーバーは通常 1 秒未満で終了します。
計画外のフェールオーバーは、ハードウェア障害、ネットワーク障害、またはクラスター内の 1 つ以上のノードに対するその他の予期しない停止が原因で発生する場合があります。 残っているノードのレプリカ シャードは、可用性を維持するために自身をプライマリに昇格させますが、プロセスには時間がかかります。 レプリカ シャードでは、フェールオーバー プロセスを開始する前に、そのプライマリ シャードが使用できないことを最初に検出する必要があります。 また、不要なフェールオーバーがなされないよう、この計画外の障害が一時的なものでもローカルのものでもないことをレプリカ シャードで確認することも必要です。 検出が遅れるということは、計画外のフェールオーバーは通常 10 秒から 15 秒以内に完了することを意味します。
修正プログラムの適用はどのように行われますか?
Azure Managed Redis サービスでは、お使いのキャッシュを最新のプラットフォーム機能と修正プログラムで定期的に更新します。 このサービスは、キャッシュへの修正プログラムの適用を次の手順で実行します。
- このサービスでは、修正プログラムが適用されているすべての VM を置き換えるために、新しい最新の VM が作成されます。
- 次に、新しい VM の 1 つをクラスター リーダーとして昇格させます。
- パッチが適用されているすべてのノードがクラスターから 1 つずつ削除されます。 これらの VM 上のすべてのシャードは降格され、新しい VM のいずれかに移行されます。
- 最後に、置き換えられたすべての VM が削除されます。
クラスター化されたキャッシュの各シャードには個別にパッチが適用され、別のシャードへの接続は閉じられません。
同じリソー スグループとリージョン内の複数のキャッシュにも、一度に 1 つずつ修正プログラムが適用されます。 異なるリソース グループまたは異なるリージョンにあるキャッシュには、同時に修正プログラムが適用できる場合があります。
プロセスが繰り返される前に完全な同期が行われるため、キャッシュでデータ損失が発生する可能性はほとんどありません。 データをエクスポートして、永続化を有効にすると、データの損失をさらに防御できます。
追加のキャッシュの負荷
フェールオーバーが発生するたびに、キャッシュでは、ノード間でデータをレプリケートする必要があります。 このレプリケーションによって、サーバーのメモリと CPU の両方で負荷が増加します。 キャッシュ インスタンスに既に大きな負荷がかかっている場合は、クライアント アプリケーションの待機時間が長くなることがあります。 極端な場合、クライアント アプリケーションがタイムアウト例外を受け取ることがあります。
フェールオーバーはクライアント アプリケーションにどのような影響を与えますか?
クライアント アプリケーションは、Azure Managed Redis インスタンスからいくつかのエラーを受信することがあります。 クライアント アプリケーションで確認されるエラーの数は、フェールオーバー時にその接続で保留になっている操作の数によって異なります。 接続が閉じられているノード経由でルーティングされている接続ではエラーが発生します。
接続が中断されると、多くのクライアント ライブラリでは、次のようなさまざまな種類のエラーがスローされます。
- タイムアウト例外
- 接続例外
- ソケット例外
例外の数と種類は、キャッシュで接続が閉じられたときに、その要求がコード パス内のどこにあるかによって異なります。 たとえば、要求を送信した操作が、フェールオーバーの発生で応答を受信しない場合、タイムアウト例外を取得する可能性があります。 接続が閉じられたオブジェクトは、再接続が正常に行われるまで、新しい要求で接続例外を受け取ります。
ほとんどのクライアント ライブラリは、構成されている場合、キャッシュへの再接続を試みます。 ただし、予期しないバグによってライブラリ オブジェクトが回復不能な状態になることがあります。 エラーが事前構成された時間を超えて続く場合は、接続オブジェクトを再作成する必要があります。 Microsoft .NET およびその他のオブジェクト指向言語では、ForceReconnect パターンを使用することで、アプリケーションを再起動せずに接続を再作成できます。
メンテナンスに含まれる更新プログラムは何ですか?
メンテナンスには、次の更新プログラムが含まれます:
- Redis Server の更新プログラム: Redis サーバー バイナリの更新プログラムまたはパッチ。
- 仮想マシン (VM) の更新プログラム: Redis サービスをホストしている仮想マシンのすべての更新。 VM の更新プログラムには、ホスト環境のソフトウェア コンポーネントにパッチを適用して、ネットワーク コンポーネントのアップグレードや使用停止が含まれます。
メンテナンスは、パッチの前に Azure portal のサービス正常性に表示されますか?
いいえ。メンテナンスは、ポータルのサービス正常性の下やその他の場所には表示されません。
クライアントのネットワーク構成の変更
クライアント側の特定のネットワーク構成の変更によって、接続が使用できません というエラーが発生することがあります。 このような変更には、次のものが含まれます。
- クライアント アプリケーションの仮想 IP アドレスをステージング スロットと運用スロット間で交換しました。
- お使いのアプリケーションのインスタンスのサイズまたは数をスケーリングしました。
このような変更により、通常は 1 分未満の接続の問題が発生する可能性があります。 お使いのクライアント アプリケーションからは、Azure Managed Redis サービスに加え、他の外部のネットワークのリソースにも接続できなくなる場合があります。
回復性を組み込む
フェールオーバーを完全に回避することはできません。 接続の中断や要求の失敗への回復性を備えるようにクライアント アプリケーションを作成してください。 ほとんどのクライアント ライブラリは自動的にキャッシュ エンドポイントに再接続できますが、少数は失敗した要求を再試行します。 アプリケーションのシナリオによっては、バックオフによる再試行ロジックが理にかなっている場合があります。
アプリケーションの回復性を高める方法
回復性があるクライアントを作成するには、これらの設計パターン、特にサーキット ブレーカー パターンや再試行パターンを参照してください。