Azure Arc 対応 SQL Managed Instance での高可用性
Azure Arc によって有効にされる SQL Managed Instance は、コンテナー化されたアプリケーションとして Kubernetes にデプロイされます。 ステートフル セットや永続ストレージなどの Kubernetes の構造を使って、次の組み込み機能を提供します。
- 正常性の監視
- 障害の検出
- サービスの正常性を維持するための自動フェールオーバー。
信頼性を高めるには、高可用性構成の追加レプリカを使ってデプロイされるように、Azure Arc によって有効にされる SQL Managed Instance を構成することもできます。 Arc データ サービスのデータ コントローラーは、次のものを管理します。
- 監視
- 障害の検出
- 自動フェールオーバー
Arc 対応データ サービスでは、ユーザーの介入なしでこのサービスが提供されます。 サービスによって:
- 可用性グループを設定する
- データベース ミラーリング エンドポイントを構成する
- データベースを可用性グループに追加する
- フェールオーバーとアップグレードを調整する。
このドキュメントでは、両方の種類の高可用性について説明します。
Azure Arc によって有効にされる SQL Managed Instance では、SQL Managed Instance が General Purpose サービス レベルまたは Business Critical サービス レベルとしてデプロイされたかどうかにより、異なるレベルの可用性が提供されます。
General Purpose サービス レベルの高可用性
General Purpose サービス レベルでは、使用可能なレプリカは1つだけであり、Kubernetes オーケストレーションを使用して高可用性が実現されます。 たとえば、マネージド インスタンスのコンテナー イメージを含むポッドまたはノードがクラッシュした場合、Kubernetes は別のポッドまたはノードの起動と、同じ永続ストレージへのアタッチを試みます。 この間、SQL Managed Instance はアプリケーションで使用できなくなります。 新しいポッドが稼働したら、アプリケーションは再接続して、トランザクションを再試行する必要があります。 load balancerが使用されているサービスの種類である場合、アプリケーションは同じプライマリエンドポイントに再接続でき、Kubernetes は新しいプライマリに接続をリダイレクトします。 サービスの種類がnodeportの場合、アプリケーションは新しい IP アドレスに再接続する必要があります。
組み込みの高可用性を検証する
Kubernetes によって提供される組み込みの高可用性は、次のようにして検証できます。
- 既存のマネージド インスタンスのポッドを削除します
- Kubernetes がこのアクションから回復することを確認します
回復の間に、Kubernetes は別のポッドをブートストラップして、永続ストレージをアタッチします。
前提条件
- Kubernetes クラスターには、共有されたリモート ストレージが必要です
- 1 つのレプリカでデプロイされた、Azure Arc によって有効にされる SQL Managed Instance (既定)
ポッドを表示します。
kubectl get pods -n <namespace of data controller>マネージド インスタンスのポッドを削除します。
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>次に例を示します。
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedポッドを表示して、マネージド インスタンスが回復していることを確認します。
kubectl get pods -n <namespace of data controller>次に例を示します。
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
ポッド内のすべてのコンテナーが回復したら、マネージド インスタンスに接続できます。
Business Critical サービス レベルの高可用性
Business Critical サービス レベルでは、Kubernetes オーケストレーションによってネイティブに提供される機能に加え、Azure Arc 対応 SQL Managed Instance によって包含可用性グループが提供されます。 包含型可用性グループは SQL Server Always On のテクノロジに基づいて構築されています。 より高いレベルの可用性が提供されます。 Business Critical サービス レベルでデプロイされる Azure Arc によって有効にされる SQL Managed Instance は、2 つまたは 3 つのレプリカでデプロイできます。 これらのレプリカは常に相互に同期されます。
包含可用性グループを使うと、アプリケーションはポッドのクラッシュやノードの障害の影響を受けなくなります。 包含可用性グループによって、プライマリからのすべてのデータを保持し、接続を実行する準備ができている、少なくとも 1 つの他のポッドが提供されます。
含まれている可用性グループ
可用性グループは、1 つまたは複数のユーザー データベースを論理グループにバインドします。これにより、フェールオーバーが発生したときに、データベースのグループ全体がセカンダリ レプリカに 1 つのユニットとしてフェールオーバーされます。 可用性グループは、ユーザー データベース内のデータのみをレプリケートしますが、ログイン、アクセス許可、エージェント ジョブなどのシステム データベースのデータはレプリケートしません。 包含可用性グループには、msdbや master データベースなどのシステム データベースのメタデータが含まれています。 プライマリ レプリカで作成または変更されたログインは、セカンダリ レプリカにも自動的に作成されます。 同様に、プライマリ レプリカでエージェント ジョブが作成または変更された場合、セカンダリ レプリカもこれらの変更を受け取ります。
Azure Arc によって有効にされる SQL Managed Instance は、含まれる可用性グループのこの概念を採用し、Kubernetes オペレーターを追加して、これらを大規模にデプロイして管理できるようにします。
包含可用性グループによって有効になる機能は次のとおりです。
複数のレプリカを使用してデプロイする場合、Arc 対応 SQL Managed Instance と同じ名前の単一の可用性グループが作成されます。 既定では、包含 AG には、プライマリを含む 3 つのレプリカがあります。 可用性グループの CRUD 操作はすべて内部的に管理されます。これには、可用性グループの作成や作成された可用性グループへのレプリカの参加が含まれます。 1 つのインスタンスにさらに多くの可用性グループを作成することはできません。
データベースはすべて可用性グループに自動的に追加されます。これには、すべてのユーザーおよびシステム データベース (
masterやmsdbなど) が含まれます。 この機能により、可用性グループ レプリカ全体で単一システム ビューが提供されます。 インスタンスに直接接続する場合は、containedag_masterデータベースとcontainedag_msdbデータベースの両方に注意してください。containedag_*データベースは、可用性グループ内のmasterとmsdbを表します。外部エンドポイントは、可用性グループ内のデータベースへの接続用に自動的にプロビジョニングされます。 このエンドポイント
<managed_instance_name>-external-svcは、可用性グループ リスナーの役割を果たします。
Azure portal を使用して複数のレプリカを含む Azure Arc 対応 SQL Managed Instance をデプロイする
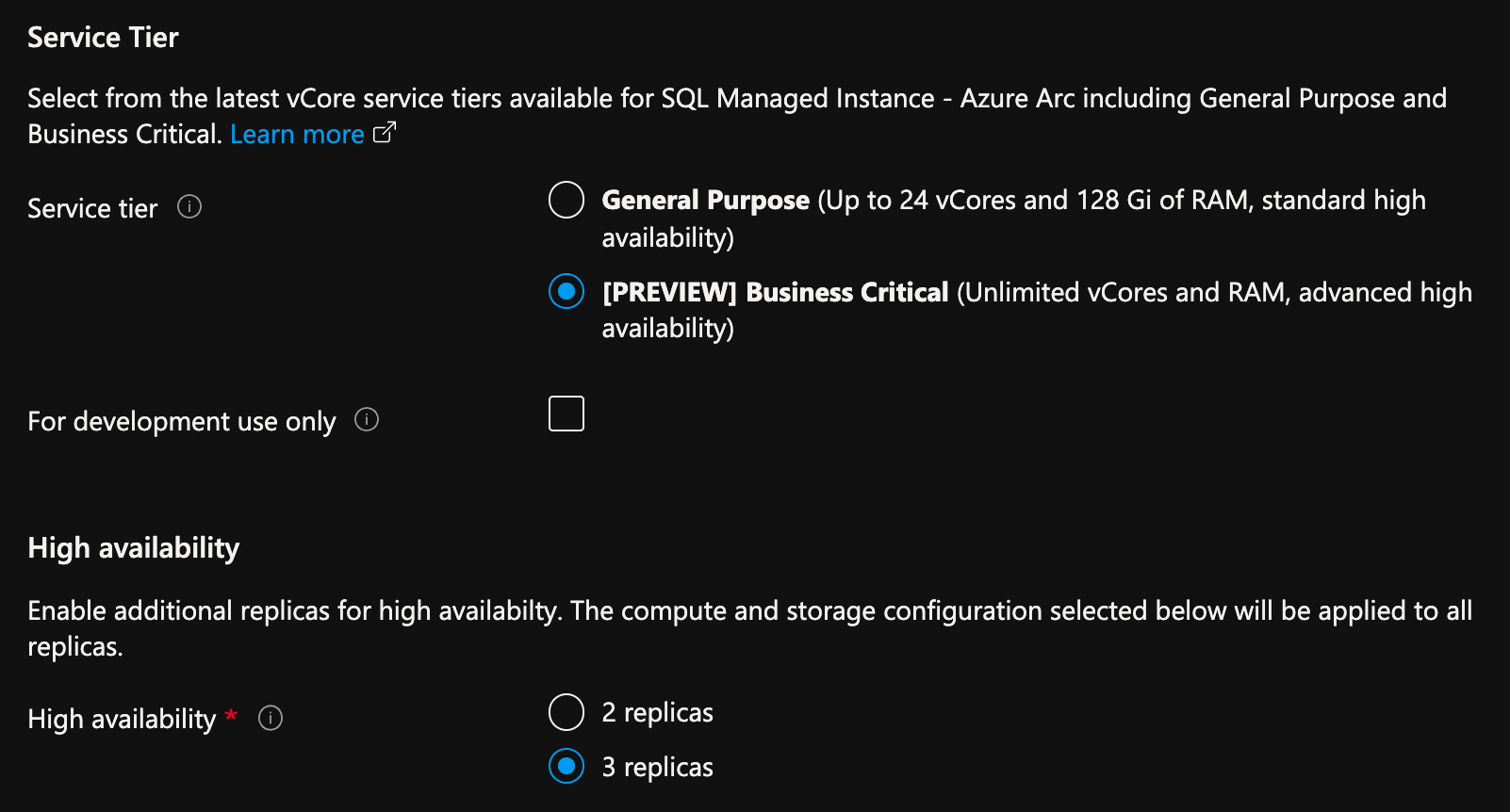
Azure portal の Azure Arc 対応 SQL Managed Instance 作成ページで次のようにします。
- [Compute + Storage] で [Compute + Storage の構成] を選択します。 ポータルに詳細設定が表示されます。
- [サービス レベル] で、[Business Critical] を選択します。
- 開発目的でを使用している場合は、"開発にのみ使用する" をオンにします。
- [高可用性] で、 2 つのレプリカ または 3 つのレプリカのいずれかを選択します。
Azure CLI を使用して複数のレプリカでデプロイする
Azure Arc 対応 SQL Managed Instance が Business Critical サービス レベルにデプロイされると、デプロイによって複数のレプリカが作成されます。 これらのインスタンスの中に含まれる可用性グループの設定と構成は、プロビジョニング中に自動的に実行されます。
たとえば、次のコマンドは、3 つのレプリカを持つマネージド インスタンスを作成します。
間接接続モード:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
例:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
直接接続モード:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
例:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
既定では、すべてのレプリカは同期モードで構成されます。 つまり、プライマリ インスタンスでのすべての更新は、各セカンダリ インスタンスに同期的にレプリケートされます。
高可用性の状態を表示および監視する
デプロイが完了したら、SQL Server Management Studio からプライマリ エンドポイントに接続します。
プライマリ レプリカのエンドポイントを確認して取得し、SQL Server Management Studio から接続します。
たとえば、SQL インスタンスがservice-type=loadbalancerを使用してデプロイされている場合は、次のコマンドを実行して、接続先のエンドポイントを取得します。
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
または
kubectl get sqlmi -A
プライマリ エンドポイント、セカンダリ エンドポイント、AG の状態を取得する
kubectl describe sqlmi または az sql mi-arc show コマンドを使用して、プライマリ エンドポイントとセカンダリ エンドポイント、高可用性の状態を表示します。
例:
kubectl describe sqlmi sqldemo -n my-namespace
または
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
出力例:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
SQL Server Management Studio を使ってプライマリ エンドポイントに接続し、次のように DMV を確認できます。
SELECT * FROM sys.dm_hadr_availability_replica_states
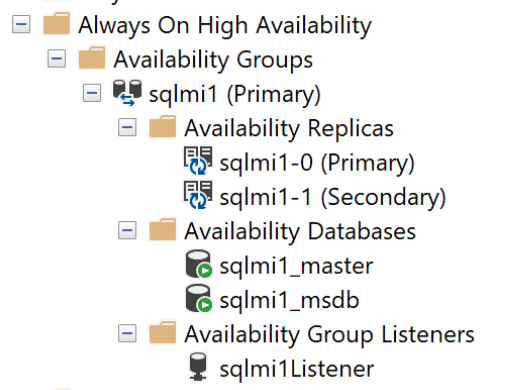
また、包含可用性ダッシュボードは次のようになります。
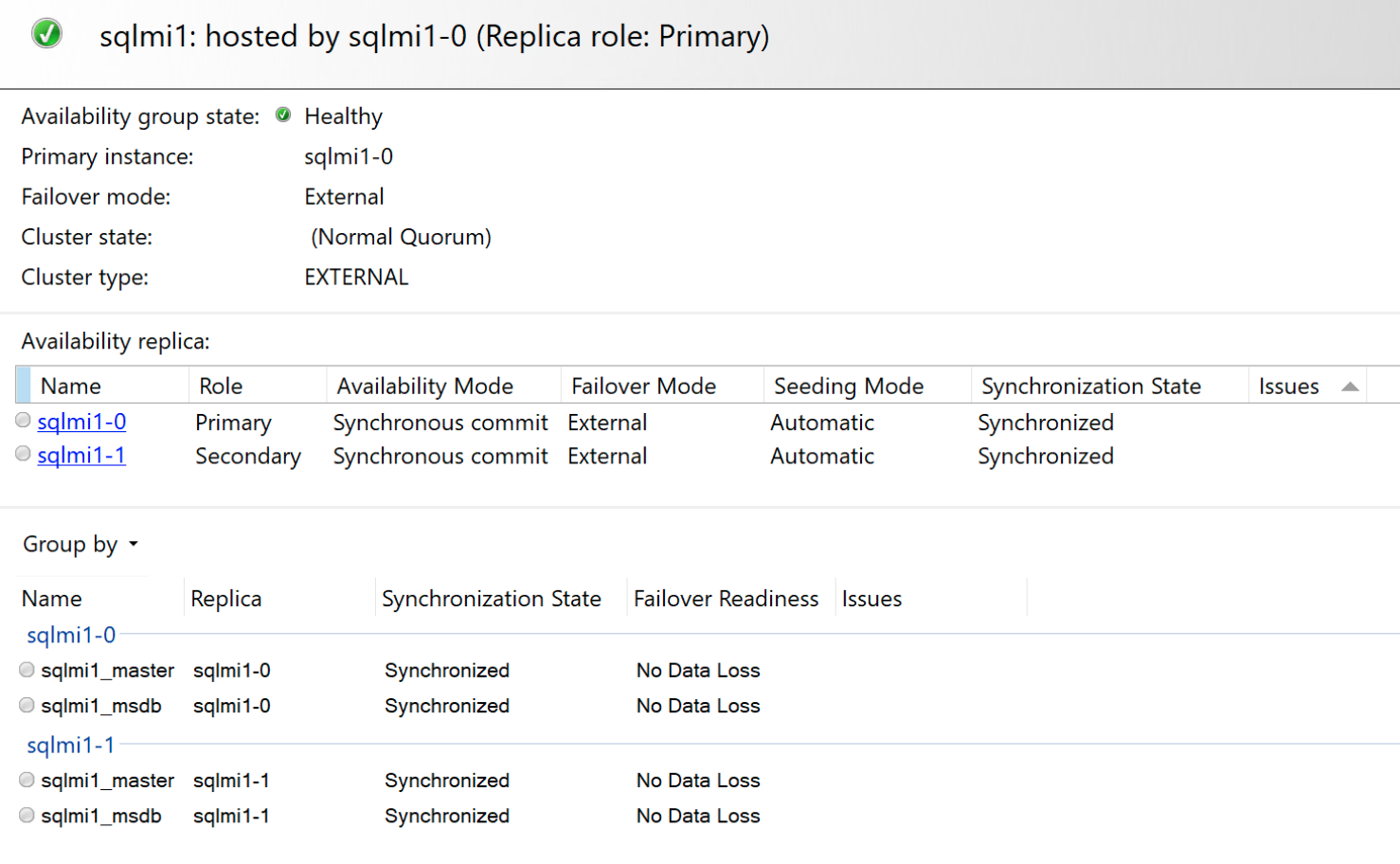
フェールオーバーのシナリオ
SQL Server Always On 可用性グループとは異なり、包含可用性グループは、管理された高可用性ソリューションです。 そのため、フェールオーバー モードは、SQL Server Always On 可用性グループで使用できる一般的なモードと比較して制限されます。
2 つのレプリカ構成または 3 つのレプリカ構成で、Business Critical サービス レベルの SQL マネージインスタンスにデプロイします。 障害とその後の回復性の影響は、構成ごとに異なります。 3 つのレプリカ インスタンスは、2 つのレプリカ インスタンスより高いレベルの可用性と回復を実現します。
2 つのレプリカ構成では、両方のノードの状態が SYNCHRONIZED である場合、プライマリレプリカが使用できなくなると、セカンダリレプリカが自動的にプライマリに昇格されます。 障害が発生したレプリカが使用可能になると、保留中のすべての変更で更新されます。 レプリカ間に接続の問題がある場合、プライマリ レプリカは、プライマリで成功が返される前に両方のレプリカでコミットする必要があるため、トランザクションをコミットできない可能性があります。
3 つのレプリカ構成では、トランザクションを 3 つのうち少なくとも 2 つ以上のレプリカでコミットしてから、アプリケーションに成功メッセージを返す必要があります。 障害が発生した場合、Kubernetes は、障害が発生したレプリカの復旧を試行している間に、セカンダリの 1 つを自動的にプライマリに昇格させます。 使用可能になったレプリカは、包含可用性グループに自動的に組み込まれて、保留中の変更が同期されます。 レプリカ間に接続の問題があり、2 つより多くのレプリカが同期されていない場合、プライマリ レプリカはトランザクションをコミットしません。
Note
データの損失をほぼゼロにするためには、2 つのレプリカ構成で Business Critical SQL Managed Instance を展開することをお勧めします。
プライマリ レプリカからセカンダリの 1 つにフェールオーバーするには、計画されたイベントに対して次のコマンドを実行します。
プライマリに接続する場合は、次の T-SQL を使用して、SQL インスタンスをセカンダリの 1 つにフェールオーバーできます。
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
セカンダリに接続する場合は、次の T-SQL を使用して、目的のセカンダリをプライマリ レプリカに昇格できます。
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
推奨されるプライマリ レプリカ
次のように、AZ CLI を使用して、特定のレプリカをプライマリ レプリカに設定することもできます。
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
例:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Note
Kubernetes は優先レプリカの設定を試みますが、それは保証されていません。
マルチレプリカ インスタンスへのデータベースの復元
可用性グループにデータベースを復元するには、追加の手順が必要となります。 次の手順では、データベースをマネージド インスタンスに復元し、可用性グループに追加する方法について説明します。
新しい Kubernetes サービスを作成して、プライマリ インスタンスの外部エンドポイントを公開します。
プライマリ レプリカをホストするポッドを特定します。 マネージド インスタンスに接続し、以下を実行します。
SELECT @@SERVERNAMEこのクエリでは、プライマリ レプリカをホストするポッドが返されます。
Kubernetes クラスターで
NodePortサービスが使われている場合は、次のコマンドを実行して、プライマリ インスタンスに対する Kubernetes サービスを作成します。<podName>を前の手順で返されたサーバーの名前に、<serviceName>を作成された Kubernetes サービスに使用する名前に置き換えます。kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortLoadBalancer サービスについても、作成されるサービスの種類が
LoadBalancerであることを除き、同じコマンドを実行します。 次に例を示します。kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerAzure Kubernetes Service に対してこのコマンドを実行する例を以下に示します。この場合、プライマリをホストしているポッドは
sql2-0です。kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancer作成された Kubernetes サービスの IP を取得します。
kubectl get services -n <namespaceName>プライマリ インスタンスのエンドポイントにデータベースを復元します。
データベースのバックアップ ファイルをプライマリ インスタンスのコンテナーに追加します。
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>例
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arc次のコマンドを実行して、データベースのバックアップ ファイルを復元します。
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GO例
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GO可用性グループにデータベースを追加します。
データベースを AG に追加するには、完全復旧モードで実行する必要があり、ログ バックアップを作成する必要があります。 次の TSQL ステートメントを実行して、復元されたデータベースを可用性グループに追加します。
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>以下の例では、インスタンスで復元された
WideWorldImportersという名前のデータベースを追加します。ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
重要
ベスト プラクティスとして、このコマンドを実行し、上記で作成された Kubernetes サービスを削除する必要があります。
kubectl delete svc sql2-0-p -n arc
制限事項
Azure Arc によって有効にされる SQL Managed Instance の可用性グループには、ビッグ データ クラスターの可用性グループと同じ制限があります。 「高可用性を使用して SQL Server ビッグ データ クラスターを展開する」を参照してください。
関連するコンテンツ
Azure Arc によって有効にされる SQL Managed Instance の機能についてさらに詳しく理解する