ミッション クリティカルな環境のデプロイとテストは、全体的な参照アーキテクチャの重要な部分です。 個々のアプリケーション スタンプは、ソース コード リポジトリのコードとしてインフラストラクチャを使用してデプロイされます。 インフラストラクチャとアプリケーションの更新は、ダウンタイムをゼロにしてアプリケーションにデプロイする必要があります。 リポジトリからソース コードを取得し、個々のスタンプを Azure にデプロイするには、DevOps 継続的インテグレーション パイプラインを使用することをお勧めします。
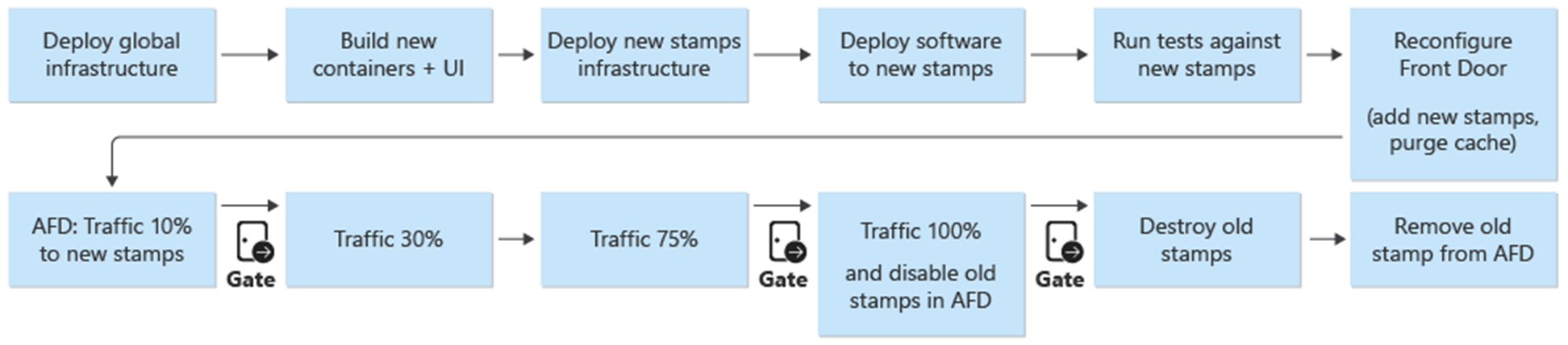
デプロイと更新は、アーキテクチャの中心的なプロセスです。 インフラストラクチャとアプリケーション関連の更新プログラムは、完全に独立したスタンプにデプロイする必要があります。 スタンプ間で共有されるのは、アーキテクチャ内のグローバル インフラストラクチャ コンポーネントだけです。 インフラストラクチャ内の既存のスタンプは操作しません。 インフラストラクチャの更新プログラムは、これらの新しいスタンプにデプロイされます。 同様に、新しいアプリケーション バージョンはこれらの新しいスタンプにデプロイされます。
新しいスタンプが Azure Front Door に追加されます。 トラフィックは徐々に新しいスタンプに移動されます。 新しいスタンプから問題なくトラフィックが処理されると、前のスタンプが削除されます。
デプロイされた環境では、侵入、混乱、ストレス テストをお勧めします。 インフラストラクチャのプロアクティブ テストでは、障害が発生した場合の弱点とデプロイされたアプリケーションの動作を検出します。
配置
参照アーキテクチャでのインフラストラクチャのデプロイは、次のプロセスとコンポーネントに依存します。
DevOps - GitHub のソース コードとインフラストラクチャのパイプライン。
ダウンタイムゼロの更新プログラム - 更新プログラムとアップグレードは、デプロイされたアプリケーションにダウンタイムを発生さささいな状態で環境にデプロイします。
環境 - アーキテクチャに使用される有効期間の短い永続的な環境。
共有リソースと専用リソース - スタンプと全体的なインフラストラクチャに専用および共有される Azure リソース。
詳細については、「Azure でのミッション クリティカルなワークロードのデプロイとテスト : 設計に関する考慮事項
デプロイメント: DevOps
DevOps コンポーネントは、インフラストラクチャと更新プログラムをデプロイするためのソース コード リポジトリと CI/CD パイプラインを提供します。 GitHub と Azure Pipelines がコンポーネントとして選択されました。
GitHub - アプリケーションとインフラストラクチャのソース コード リポジトリが含まれています。
Azure Pipelines - すべてのビルド、テスト、およびリリース タスクに対してアーキテクチャによって使用されるパイプライン。
デプロイに使用される設計の追加コンポーネントは、ビルド エージェントです。 Microsoft ホステッド ビルド エージェントは、インフラストラクチャと更新プログラムをデプロイするために Azure Pipelines の一部として使用されます。 Microsoft Hosted ビルド エージェントを使用すると、開発者がビルド エージェントを維持および更新するための管理上の負担が軽減されます。
Azure Pipelines の詳細については、「Azure Pipelines とは」を参照してください。.

詳細については、「Azure でのミッション クリティカルなワークロードのデプロイとテスト: コードとしてのインフラストラクチャのデプロイ
デプロイ: ダウンタイムなしの更新
参照アーキテクチャのダウンタイムゼロ更新戦略は、ミッション クリティカルなアプリケーション全体の中心です。 スタンプをアップグレードする代わりに置き換える方法により、アプリケーションをインフラストラクチャ スタンプに新たにインストールできます。 参照アーキテクチャでは、青/緑のアプローチを利用し、個別のテスト環境と開発環境を可能にします。
参照アーキテクチャには、次の 2 つの主要なコンポーネントがあります。
インフラストラクチャ - Azure のサービスとリソース。 Terraform とそれに関連付けられている構成を使用してデプロイされます。
アプリケーション - ユーザーにサービスを提供するホステッド サービスまたはアプリケーション。 Dockerコンテナーとnpmでビルドされたアーティファクトに基づいた、HTMLとJavaScriptによるシングルページアプリケーション(SPA)のUIです。
多くのシステムでは、アプリケーションの更新がインフラストラクチャの更新よりも頻繁に行われるという前提があります。 その結果、それぞれ異なる更新手順が開発されます。 パブリック クラウド インフラストラクチャでは、変更はより速いペースで行われる可能性があります。 アプリケーションの更新プログラムとインフラストラクチャの更新プログラムのデプロイ プロセスが 1 つ選択されました。 1 つのアプローチにより、インフラストラクチャとアプリケーションの更新が常に同期されます。この方法では、次のことができます。
一貫したプロセス - インフラストラクチャとアプリケーションの更新が意図的または無意識に一緒にリリースされると、誤りの機会が減少します。
青/緑の展開 を有効にします。すべての更新プログラムは、新しいリリースへのトラフィックの段階的な移行を使用してデプロイされます。
アプリケーションの展開とデバッグが簡単 - スタンプ全体で複数のバージョンのアプリケーションがサイド バイ サイドでホストされることはありません。
単純なロールバック - エラーや問題が発生した場合、トラフィックを以前のバージョンを実行するスタンプに切り替えることができます。
手動による変更と構成の誤差の排除 - すべての環境は新しいデプロイです。
詳細情報については、「Azureでのミッションクリティカルなワークロードのデプロイとテスト: エフェメラルなブルー/グリーンデプロイ」を参照してください。
分岐戦略
更新戦略の基礎は、Git リポジトリ内のブランチの使用です。 参照アーキテクチャでは、次の 3 種類のブランチを使用します。
| [Branch]\(ブランチ) | 説明 |
|---|---|
feature/* と fix/* |
あらゆる変更のためのエントリーポイント。 開発者はこれらのブランチを作成し、feature/catalog-update や fix/worker-timeout-bugなどのわかりやすい名前を付ける必要があります。 変更をマージする準備ができたら、main ブランチに対するプル要求 (PR) が作成されます。 少なくとも 1 人のレビュー担当者が、すべてのプル要求を承認する必要があります。 限られた例外を除き、PR で提案されるすべての変更は、エンド ツー エンド (E2E) 検証パイプラインを通じて実行する必要があります。 開発者は、E2E パイプラインを使用して、完全な環境に対する変更をテストおよびデバッグする必要があります。 |
main |
継続的に前進し、安定したブランチ。 主に統合テストに使用されます。 main に対する変更は、プル要求によってのみ行われます。 ブランチ ポリシーでは、直接書き込みを禁止します。 永続的な integration (int) 環境に対する夜間リリースは、main ブランチから自動的に実行されます。 main ブランチは安定と考えられています。 任意の時点でリリースを作成できることを前提とすることは安全です。 |
release/* |
リリース ブランチは、main ブランチからのみ作成されます。 分岐は release/2021.7.X形式に従います。 ブランチ ポリシーは、リポジトリ管理者のみが release/* ブランチを作成できるように使用されます。 これらのブランチのみが、prod 環境へのデプロイに使用されます。 |
詳細については、「Azure でのミッション クリティカルなワークロードのデプロイとテスト: 分岐戦略
修正プログラム
バグやその他の問題のために緊急に修正プログラムが必要であり、通常のリリース プロセスを実行できない場合は、修正プログラム パスを使用できます。 最初のテスト中に検出されなかったユーザー エクスペリエンスに対する重要なセキュリティ更新プログラムと修正プログラムは、修正プログラムの有効な例と見なされます。
修正プログラムは、新しい fix ブランチで作成し、通常の PR を使用して main にマージする必要があります。 新しいリリース ブランチを作成する代わりに、修正プログラムは既存のリリース ブランチに "チェリーピック" されます。 このブランチは既に prod 環境にデプロイされています。 最初にすべてのテストでリリース ブランチをデプロイした CI/CD パイプラインが再度実行され、パイプラインの一部として修正プログラムがデプロイされます。
大きな問題を回避するには、修正プログラムにいくつかの分離されたコミットが含まれていることが重要です。このコミットは、簡単にチェリーピックしてリリース ブランチに統合できます。 分離されたコミットを厳選してリリース ブランチに統合できない場合、変更が修正プログラムとして適格と認められないことを示しています。 変更を完全な新しいリリースとしてデプロイします。 新しいリリースをデプロイできるようになるまで、以前の安定したバージョンへのロールバックと組み合わせます。
デプロイ: 環境
参照アーキテクチャでは、インフラストラクチャに次の 2 種類の環境が使用されます。
有効期間の短い - E2E 検証パイプラインは、有効期間の短い環境をデプロイするために使用されます。 有効期間の短い環境は、開発者向けの純粋な検証またはデバッグ環境に使用されます。 検証環境は、
feature/*ブランチから作成し、テストを受け、すべてのテストが成功した場合は破棄できます。 デバッグ環境は検証と同じ方法でデプロイされますが、すぐには破棄されません。 これらの環境は数日以上存在する必要はありません。また、機能ブランチの対応する PR がマージされるときに削除する必要があります。永続的な - 永続的な環境には、
integration (int)バージョンとproduction (prod)バージョンがあります。 これらの環境は継続的に稼働しており、破棄されません。 環境では、int.mission-critical.appなどの固定ドメイン名が使用されます。 参照アーキテクチャの実際の実装では、staging(preprod) 環境を追加する必要があります。staging環境は、prod(青/緑のデプロイ) と同じ更新プロセスでreleaseブランチをデプロイおよび検証するために使用されます。統合 (int) -
intバージョンは、prodと同じプロセスでmainブランチから夜間にデプロイされます。 トラフィックの切り替えは、以前のリリース ユニットよりも高速です。prodのように、トラフィックを数日にわたって徐々に切り替える代わりに、intのプロセスは数分以内に完了します。 この高速な切り替えにより、更新された環境は次の朝までに準備が整います。 パイプライン内のすべてのテストが成功すると、古いスタンプが自動的に削除されます。Production (prod) -
prodバージョンは、release/*ブランチからのみデプロイされます。 トラフィックの切り替えでは、より細かい手順が使用されます。 手動承認ゲートは、各ステップの間にあります。 各リリースでは、新しいリージョン スタンプが作成され、新しいアプリケーション バージョンがスタンプにデプロイされます。 既存のスタンプはプロセスで触れられません。prodに関する最も重要な考慮事項は、"常にオン" である必要があるということです。 計画されたダウンタイムや計画外のダウンタイムは発生しません。 唯一の例外は、データベース レイヤーの基本的な変更です。 計画メンテナンス期間が必要な場合があります。
デプロイ: 共有リソースと専用リソース
参照アーキテクチャ内の永続的な環境 (int と prod) には、インフラストラクチャ全体と共有されているか、個々のスタンプ専用であるかに応じて、さまざまな種類のリソースがあります。 リソースは特定のリリース専用にすることができ、次のリリース ユニットが引き継ぐまでしか存在しません。
リリース ユニット
リリース ユニットは、特定のリリース バージョンごとに複数のリージョン スタンプです。 スタンプには、他のスタンプと共有されていないすべてのリソースが含まれます。 これらのリソースは、仮想ネットワーク、Azure Kubernetes Service クラスター、Event Hubs、Azure Key Vault です。 Azure Cosmos DB と ACR は、Terraform データ ソースを使用して構成されます。
グローバルに共有されるリソース
リリース ユニット間で共有されるすべてのリソースは、独立した Terraform テンプレートで定義されます。 これらのリソースは、Front Door、Azure Cosmos DB、コンテナー レジストリ (ACR)、Log Analytics ワークスペース、およびその他の監視関連リソースです。 これらのリソースは、リリース ユニットの最初のリージョン スタンプがデプロイされる前にデプロイされます。 リソースは、スタンプの Terraform テンプレートで参照されます。
フロントドア
Front Door はスタンプ間でグローバルに共有されるリソースですが、その構成は他のグローバル リソースとは若干異なります。 Front Door は、新しいスタンプがデプロイされた後に再構成する必要があります。 Front Door を再構成して、トラフィックを新しいスタンプに徐々に切り替える必要があります。
Front Door のバックエンド構成を Terraform テンプレートで直接定義することはできません。 構成は Terraform 変数と共に挿入されます。 変数の値は、Terraform デプロイが開始される前に構築されます。
Front Door 展開の個々のコンポーネント構成は、次のように定義されます。
フロントエンド - セッション アフィニティは、ユーザーが 1 つのセッション中に異なる UI バージョンを切り替えないように構成されています。
オリジン - Front Door は、次の 2 種類の配信元グループで構成されます。
ユーザーインターフェースを提供する静的ストレージのオリジングループ。 グループには、現在アクティブなすべてのリリース ユニットの Web サイト ストレージ アカウントが含まれています。 異なるリリース ユニットから配信元に異なる重みを割り当てて、トラフィックを新しいユニットに徐々に移動することができます。 リリース ユニットの各配信元には、同じ重みが割り当てられている必要があります。
Azure Kubernetes Service でホストされている API の配信元グループ。 異なる API バージョンのリリース ユニットがある場合は、リリース ユニットごとに API 配信元グループが存在します。 すべてのリリース ユニットが同じ互換性のある API を提供する場合、すべての配信元が同じグループに追加され、異なる重みが割り当てられます。
ルーティング規則 - ルーティング規則には次の 2 種類があります。
UI ストレージの起点グループにリンクされた UI のルーティングルール。
配信元によって現在サポートされている各 API のルーティング規則。 例:
/api/1.0/*と/api/2.0/*.
リリースで新しいバージョンのバックエンド API が導入された場合、変更はリリースの一部としてデプロイされる UI に反映されます。 UI の特定のリリースでは、常に特定のバージョンの API URL が呼び出されます。 UI バージョンによって提供されるユーザーは、それぞれのバックエンド API を自動的に使用します。 API バージョンの異なるインスタンスには、特定のルーティング規則が必要です。 これらのルールは、対応する配信元グループにリンクされます。 新しい API が導入されなかった場合は、API 関連のすべてのルーティング規則が単一の配信元グループにリンクされます。 この場合、ユーザーが API とは異なるリリースから UI を提供するかどうかは関係ありません。
デプロイ: デプロイ プロセス
青/緑のデプロイは、デプロイ プロセスの目標です。 release/* ブランチからの新しいリリースは、prod 環境にデプロイされます。 ユーザー トラフィックは、新しいリリースのスタンプに徐々にシフトされます。
新しいバージョンのデプロイ プロセスの最初の手順として、新しいリリース ユニットのインフラストラクチャが Terraform と共にデプロイされます。 インフラストラクチャ デプロイ パイプラインを実行すると、選択したリリース ブランチから新しいインフラストラクチャがデプロイされます。 インフラストラクチャ のプロビジョニングと並行して、コンテナー イメージがビルドまたはインポートされ、グローバル共有コンテナー レジストリ (ACR) にプッシュされます。 前のプロセスが完了すると、アプリケーションはスタンプにデプロイされます。 実装の観点からは、複数の依存ステージを持つ 1 つのパイプラインです。 修正プログラムの展開に対して同じパイプラインを再実行できます。
新しいリリース ユニットがデプロイされて検証されると、ユーザー トラフィックを受信するために新しいユニットが Front Door に追加されます。
新しい API バージョンを導入するリリースと導入しないリリースを区別するスイッチ/パラメーターを計画する必要があります。 リリースで新しい API バージョンが導入されたかどうかに基づいて、API バックエンドを含む新しい配信元グループを作成する必要があります。 または、新しい API バックエンドを既存の配信元グループに追加することもできます。 新しい UI ストレージ アカウントが、対応する既存の配信元グループに追加されます。 目的のトラフィック分割に従って、新しい配信元の重みを設定する必要があります。 前述のように、適切な配信元グループに対応する新しいルーティング規則を作成する必要があります。
新しいリリース ユニットの追加の一環として、新しい配信元の重みを目的の最小ユーザー トラフィックに設定する必要があります。 問題が検出されない場合は、一定期間にわたって新しい配信元グループへのユーザー トラフィックの量を増やす必要があります。 重みパラメーターを調整するには、同じデプロイ手順を目的の値で再度実行する必要があります。
リリースユニットの分解
リリース ユニットのデプロイ パイプラインの一部として、リリース ユニットが不要になったらすべてのスタンプを削除する破棄ステージがあります。 すべてのトラフィックは、新しいリリース バージョンに移動されます。 このステージには、Front Door からのリリース ユニット参照の削除が含まれます。 この削除は、新しいバージョンのリリースを後日有効にするために重要です。 Front Door は、将来の次のリリースに備えるために、1 つのリリース ユニットを指す必要があります。
チェックリスト
リリース周期の一部として、リリース前とリリース後のチェックリストを使用する必要があります。 次の例は、少なくとも任意のチェックリストに含まれている必要がある項目の例です。
プレリリース チェックリスト - リリースを開始する前に、次の項目を確認してください。
mainブランチの最新の状態が正常にデプロイされ、int環境でテストされたことを確認します。mainブランチに対して PR を使用して変更ログ ファイルを更新します。mainブランチからrelease/ブランチを作成します。
リリース後のチェックリスト - 古いスタンプが破棄され、その参照が Front Door から削除される前に、次のことを確認します。
クラスターは受信トラフィックを受信しなくなりました。
Event Hubs やその他のメッセージ キューには、未処理のメッセージは含まれません。
展開: 更新戦略の制限事項とリスク
この参照アーキテクチャで説明されている更新戦略には、いくつかの制限事項とリスクについて説明する必要があります。
コストの増加 - 更新プログラムをリリースする場合、インフラストラクチャ コンポーネントの多くはリリース期間中に 2 回アクティブになります。
Front Door の複雑さ - Front Door の更新プロセスは、実装と保守が複雑です。 ダウンタイムをゼロにして効果的な青/緑のデプロイを実行する機能は、正常に動作できるかどうかによって異なります。
小さな変更に時間がかかる - 更新プロセスにより、小さな変更のリリース プロセスが長くなります。 この制限は、前のセクションで説明した修正プログラム プロセスで部分的に軽減できます。
デプロイ: アプリケーション データ転送の互換性に関する考慮事項
更新戦略では、同時に実行される API と作業コンポーネントの複数のバージョンをサポートできます。 Azure Cosmos DB は 2 つ以上のバージョン間で共有されるため、1 つのバージョンによって変更されたデータ要素が、それを使用する API またはワーカーのバージョンと常に一致しない可能性があります。 API レイヤーとワーカーは、上位互換性設計を実装する必要があります。 以前のバージョンの API または worker コンポーネントは、新しい API または worker コンポーネントのバージョンによって挿入されたデータを処理します。 理解できない部分は無視されます。
テスティング
参照アーキテクチャには、テスト実装内のさまざまな段階で使用されるさまざまなテストが含まれています。
次のテストが含まれます。
単体テスト - これらのテストは、アプリケーションのビジネス ロジックが期待どおりに動作することを検証します。 参照アーキテクチャには、Azure Pipelines によってすべてのコンテナーがビルドされる前に自動的に実行される単体テストのサンプル スイートが含まれています。 いずれかのテストが失敗した場合、パイプラインは停止します。 ビルドとデプロイが停止します。 開発者は、パイプラインを再度実行する前に問題を修正する必要があります。
ロード テスト - これらのテストは、特定のワークロードまたはスタックの容量、スケーラビリティ、潜在的なボトルネックを評価するのに役立ちます。 参照実装には、実際のトラフィックをシミュレートするために使用できる合成ロード パターンを作成するユーザー ロード ジェネレーターが含まれています。 ロード ジェネレーターは、参照実装とは別に使用することもできます。
スモーク テスト - これらのテストは、インフラストラクチャとワークロードが使用可能で、期待どおりに機能するかどうかを識別します。 スモーク テストは、すべてのデプロイの一部として実行されます。
UI テスト - これらのテストは、ユーザー インターフェイスがデプロイされ、期待どおりに動作することを検証します。 現在の実装では、実際のテストなしで、デプロイ後のいくつかのページのスクリーンショットのみがキャプチャされます。
失敗挿入テスト - これらのテストは、自動化または手動で実行できます。 アーキテクチャの自動テストでは、デプロイ パイプラインの一部として Azure Chaos Studio が統合されます。
詳細については、「Azure でのミッション クリティカルなワークロードのデプロイとテスト: 継続的な検証とテスト に関するページを参照してください。
テスト: フレームワーク
可能な限り、オンライン参照実装の既存のテスト機能とフレームワークを活用します。
| フレームワーク | テスト | 説明 |
|---|---|---|
| NUnit | 単位 | このフレームワークは、実装の .NET Core 部分を単体テストするために使用されます。 Azure Pipelines は、コンテナーのビルド前に単体テストを自動的に実行します。 |
| Azure Load Testing を使用した JMeter | 負荷 | |
| Locust | 負荷 | ラゴトは、Python で記述されたオープンソースのロード テスト フレームワークです。 |
| Playwright | UI とスモーク | Playwright は、Chromium、Firefox、WebKit を 1 つの API で自動化するためのオープン ソース Node.js ライブラリです。 Playwright テスト定義は、参照実装とは別に使用することもできます。 |
| Azure Chaos Studio | エラー インジェクション | 参照実装では、E2E 検証パイプラインの省略可能な手順として Azure Chaos Studio を使用して、回復性検証のエラーを挿入します。 |
テスト: 障害注入テストとカオスエンジニアリング
分散アプリケーションは、サービスやコンポーネントの停止に対する回復性を備える必要があります。 障害挿入テスト (障害注入またはカオス エンジニアリングとも呼ばれます) は、アプリケーションとサービスに実際のストレスと障害を適用する方法です。
回復性はシステム全体のプロパティであり、障害を挿入すると、アプリケーションで問題を見つけるのに役立ちます。 これらの問題に対処すると、信頼性の低い条件、依存関係の不足、その他のエラーに対するアプリケーションの回復性を検証するのに役立ちます。
インフラストラクチャに対して手動テストと自動テストを実行して、実装の障害と問題を見つけることができます。
自動
参照アーキテクチャは、Azure Chaos Studio を統合して、一連の Azure Chaos Studio 実験をデプロイして実行し、スタンプ レベルでさまざまな障害を挿入します。 カオス実験は、E2E デプロイ パイプラインの省略可能な部分として実行できます。 テストが実行されると、オプションのロード テストは常に並列で実行されます。 ロード テストは、クラスターに負荷を作成して、挿入された障害の影響を検証するために使用されます。
手動
手動のエラー インジェクション テストは、E2E 検証環境で行う必要があります。 この環境は、他の環境からの干渉のリスクなしに、完全な代表的なテストを保証します。 テストで生成されたエラーのほとんどは、Application Insights Live メトリック ビューで直接観察できます。 残りのエラーは、[エラー] ビューと対応するログ テーブルで使用できます。 その他のエラーでは、kubectl を使用して Azure Kubernetes Service 内の動作を観察するなど、より詳細なデバッグが必要です。
参照アーキテクチャに対して実行されるエラー挿入テストの 2 つの例を次に示します。
DNS (ドメイン ネーム サービス) に基づく障害注入 - 複数の問題をシミュレートできるテストケース。 DNS サーバーまたは Azure DNS の障害による DNS 解決エラー。 DNS ベースのテストは、BackgroundProcessor が Event Hubs に接続できない場合など、クライアントとサービス間の一般的な接続の問題をシミュレートするのに役立ちます。
単一ホストシナリオでは、ローカル
hostsファイルを変更して DNS 解決を上書きできます。 AKS のような複数の動的サーバーがある大規模な環境では、hostsファイルは実現できません。 Azure プライベート DNS ゾーンの は、障害シナリオをテストする代わりに使用できます。Azure Event Hubs と Azure Cosmos DB は、参照実装内で使用される 2 つの Azure サービスであり、DNS ベースのエラーを挿入するために使用できます。 Event Hubs DNS 解決は、いずれかのスタンプの仮想ネットワークに関連付けられた Azure プライベート DNS ゾーンを使用して操作できます。 Azure Cosmos DB は、特定のリージョン エンドポイントを持つグローバルにレプリケートされたサービスです。 これらのエンドポイントの DNS レコードを操作すると、特定のリージョンのエラーをシミュレートし、クライアントのフェールオーバーをテストできます。
ファイアウォールブロック - ほとんどの Azure サービスでは、仮想ネットワークや IP アドレスに基づくファイアウォール アクセス制限がサポートされています。 参照インフラストラクチャでは、これらの制限を使用して、Azure Cosmos DB または Event Hubs へのアクセスを制限します。 簡単な手順では、既存の 許可 ルールを削除するか、新しい ブロック ルールを追加します。 この手順では、ファイアウォールの構成ミスやサービスの停止をシミュレートできます。
参照実装の次のサンプル サービスは、ファイアウォール テストを使用してテストできます。
Service 結果 Key Vault Key Vault へのアクセスがブロックされている場合、最も直接的な影響は、新しいポッドの生成の失敗でした。 ポッドの起動時にシークレットをフェッチする Key Vault CSI ドライバーは、そのタスクを実行できず、ポッドが起動するのを防ぎます。 対応するエラー メッセージは、 kubectl describe po CatalogService-deploy-my-new-pod -n workloadで確認できます。 既存のポッドは引き続き動作しますが、同じエラー メッセージが表示されます。 シークレットの定期的な更新チェックの結果によって、エラー メッセージが生成されます。 テストは行われませんが、Key Vault にアクセスできない間はデプロイを実行できません。 パイプライン実行内の Terraform タスクと Azure CLI タスクは、Key Vault に要求を行います。Event Hubs Event Hubs へのアクセスがブロックされると、CatalogService および HealthService によって送信された新しいメッセージは失敗します。 BackgroundProcess によるメッセージの取得が遅く失敗し、数分以内に合計エラーが発生します。 Azure Cosmos DB 仮想ネットワークの既存のファイアウォール ポリシーを削除すると、ヘルス サービスは最小ラグで失敗し始めます。 この手順では、特定のケース (Azure Cosmos DB 全体の停止) のみをシミュレートします。 リージョン レベルで発生するほとんどの障害ケースは、クライアントを別の Azure Cosmos DB リージョンに透過的にフェールオーバーすると自動的に軽減されます。 前に説明した DNS ベースの障害挿入テストは、Azure Cosmos DB のより意味のあるテストです。 コンテナー レジストリ (ACR) ACR へのアクセスがブロックされると、AKS ノードで以前にプルおよびキャッシュされた新しいポッドの作成は引き続き機能します。 K8s デプロイ フラグ pullPolicy=IfNotPresentにより、作成は引き続き行われます。 ノードがブロックの前にイメージをプルしてキャッシュしない場合、ノードは新しいポッドを生成できず、ErrImagePullエラーですぐに失敗します。kubectl describe podは、対応する403 Forbiddenメッセージを表示します。AKS イングレス Load Balancer AKS マネージド ネットワーク セキュリティ グループ (NSG) の HTTP(S)(ポート 80 および 443) の受信規則を Deny に変更すると、ユーザーまたは正常性プローブのトラフィックがクラスターに到達できなくなります。 この障害のテストでは、Front Door のネットワーク パスとリージョン スタンプの間のブロックとしてシミュレートされた根本原因を特定することは困難です。 Front Door はすぐにこの障害を検出し、スタンプを回転から取り出します。