データ ストアを水平方向のパーティションまたはシャードのセットに分割します。 これにより、データを大量に保存したり、膨大なデータにアクセスするときのスケーラビリティを改善できます。
コンテキストと問題
データ ストアが1台のサーバーにホストされている場合、次の制限が適用される可能性があります。
記憶域スペース 大規模なクラウド アプリケーションのデータ ストアには膨大なデータが保存され、その量は時間の経過とともに増大することが想定されます。 基本的にサーバーによって提供されるディスク記憶域には制限がありますが、データ量が増加するのに合わせて既存のディスクをより大型のディスクと置き換えたり、マシンにディスクをさらに追加したりできます。 しかし、最終的にシステムはある制限に達し、使用しているサーバーでは簡単にこれ以上記憶域の容量を増やすことができなくなります。
コンピューティング リソース クラウド アプリケーションでは、同時に多数のユーザーをサポートすることが要求され、こうしたユーザーは、データ ストアから情報を取得するクエリをそれぞれ実行します。 データ ストアをホストするサーバーが 1 台しかない場合、サーバーはこうした負荷をサポートするために必要な処理能力を提供できず、その結果、データの保存や取得を試みたアプリケーションがタイムアウトして、ユーザーへの応答時間が遅くなったり、頻繁に障害が発生したりする可能性があります。メモリの追加やプロセッサのアップグレードが可能な場合もありますが、システムはいずれ限界に達し、コンピューティング リソースをそれ以上増加できなくなります。
ネットワーク帯域幅 サーバー 1 台で動作しているデータ ストアのパフォーマンスは、リクエストを受信して応答を送信するサーバーのレートにより最終的に決定します。 ネットワーク トラフィックの量が、サーバーへの接続に使用するネットワークの容量を超える可能性もあり、その結果、リクエストに障害が発生します。
地理的な場所 ある特定のユーザーが生成したデータを、同じリージョン内に格納する必要がある場合があります。これは、法律、法令遵守、パフォーマンスに関する理由、またはデータ アクセスの待ち時間を減らすためです。 ユーザーが異なる国や地域にわたって分散しており、アプリケーションが単一のデータ ストアにしかない場合には、データ全体を保存できない可能性があります。
ディスク容量、処理能力、メモリ、ネットワーク接続をさらに追加して垂直にスケールすることで、こうした制限がもたらす影響の発生を遅らせることができますが、これは一時的な解決策にしかならない可能性があります。 多数のユーザーと膨大なデータをサポートできる商用クラウド アプリケーションは、ほぼ無制限にスケールできることになっているため、垂直にスケールすることは必ずしも最適な解決策ではありません。
解決策
データ ストアを水平方向のパーティションやシャードに分割します。 各シャードにはスキーマがありますが、それぞれ特定のデータのサブセットを保持しています。 シャードは、自身の権限を持つデータ ストア (異なる種類の多数のエンティティのデータを格納できます) で、ストレージ ノードとして機能するサーバー上で動作します。
このパターンには次のような利点があります。
別のストレージ ノード上で動作するシャードをさらに追加して、システムをスケールアウトすることができます。
システムには、各ストレージ ノード専用の高価なコンピューターではなく、既製品のハードウェアを使用できます。
シャード間の作業負荷を分散させることにより、競合を少なくし、パフォーマンスを向上させることができます。
クラウドでは、データにアクセスするユーザーに対して物理的に近い距離にシャードを配置できます。
データ ストアをシャーディングするときには、どのデータを各シャードに配置するかを決定します。 通常、シャードには、複数のデータ属性により決定された特定の範囲に該当する項目が含まれます。 こうした属性により、シャード キー (パーティション キーとも呼ばれます) が設定されます。 シャード キーは、静的である必要があります。 変更の可能性があるデータに基づくことはできません。
シャーディングにより、データは物理的に整理されます。 アプリケーションがデータを格納したり取得したりするときに、シャーディングのロジックにより、アプリケーションは適切なシャードへ割り当てられます。 このシャーディングのロジックは、アプリケーションのデータ アクセス コードの一部、またはデータ記憶域システムが透過的にシャーディングをサポートする場合には、そのシステムによって実装できます。
シャーディングのロジックでデータの物理的な場所をあいまいにすることで、シャードへのデータ保存先に対して高度に制御できます。 また、シャードの負荷が不均一であるために後からシャードの分散を設定しなおす必要がある場合には、ビジネス ロジックを再度やり直すことなくシャード間でのデータ移行が可能になります。 トレードオフは、各データを取得するときに、その保存先を決める上でデータ アクセスのオーバーヘッドがさらに発生することです。
最適なパフォーマンスとスケーラビリティを確保するためには、アプリケーションが実行するクエリのタイプに適した方法でデータを分割することが重要です。 ほとんどの場合、シャーディング スキームが各クエリの要件と完全に一致することはありません。 たとえば、マルチテナント システムでアプリケーションがテナント データを取得するときには、テナント ID を使用するだけでなく、テナントの名前や場所といった他の属性にも基づいてこのデータを検索しなければならない場合があります。 このような状況を処理するためには、最も頻繁に実行されるクエリをサポートするシャード キーを使用した、シャーディング戦略を実装します。
属性値の組み合わせを使用してクエリが頻繁にデータを取得する場合には、属性値をリンクすることで複合のシャード キーを定義できる可能性があります。 または、 インデックス テーブル といったパターンを使用して、シャード キーが対応していない属性に基づいたデータで検索を高速に行うことができます。
シャーディング戦略
シャードを選択しデータを分配する方法を決定する場合に、3 つの戦略がよく使用されます。 シャードとそれをホストするサーバーが 1 対 1 で対応していなければならないわけではありません。サーバー 1 台で複数のシャードをホストできます。 戦略は次のとおりです。
Lookup 戦略 この戦略では、シャード キーを使用して、データのリクエストをそのデータが格納されたシャードまでルーティングするマップが、シャーディング ロジックによって実装されます。 マルチテナント アプリケーションでは、テナント ID をシャード キーとして、あるテナントのすべてのデータが 1 つのシャードにまとめて格納されている場合があります。 複数のテナントで同じシャードを共有する可能性はありますが、1 つのテナントのデータが複数のシャードにまたがることはありません。 この図表は、テナント ID によるテナント データのシャーディングを示しています。
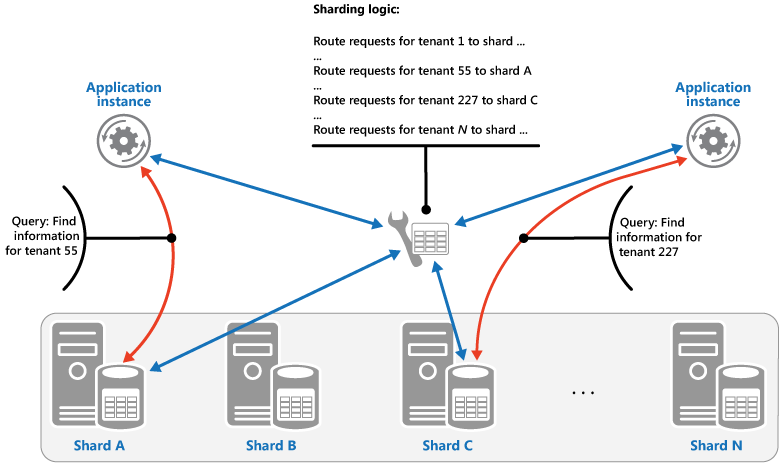
シャード キー値とデータが存在している物理的な保存スペースのマッピングは、各シャード キー値が物理的なパーティションに対しマッピングされている物理的なシャードによる場合があります。 または、より柔軟にシャードの負荷を分散する方法として、仮想パーティション分割があります。この方法では、シャード キー値は同じ数の仮想シャードにマッピングされ、その結果マッピングされる物理パーティションの数が少なくなります。 このアプローチでは、仮想シャードを参照するシャード キー値を使用してアプリケーションがデータを配置し、システムが透過的に仮想シャードを物理パーティションにマッピングします。 仮想シャードと物理パーティションのマッピングは、アプリケーション コードを修正して異なるシャード キー値を使用しなくても変更できます。
範囲戦略 この方法では、関連するアイテムが同じシャードにまとめられ、アイテムはシャード キー順に整列されます。シャード キーは、順番になっています。 範囲クエリ (ある範囲に該当するシャード キーに対してデータ項目を返すクエリ) を使用して、項目を頻繁に取得するアプリケーションにおいて便利な方法です。 たとえば、ある月に発生した注文をすべてアプリケーションが定期的に検索しなければならない場合に、月の注文がすべて同じシャード内に日時順で格納されていれば、より迅速にデータを取得できます。 各注文が異なるシャードに保存されていると、膨大な数のポイント クエリ (1 つのデータ項目を返すクエリ) を実行して個別に取得しなければなりません。 次の図表は、順番に並んだデータセット (範囲) をシャードに保存する状態を示しています。
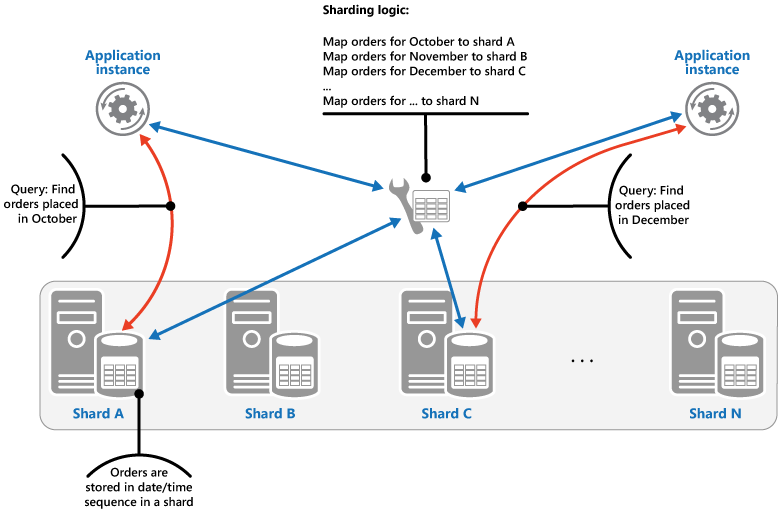
この例でのシャード キーは、注文月そして注文日時の順に、最上位要素としている複合キーです。 新しい注文が作成されシャードに追加されると、注文データは自然に並べ替えられます。 一部のデータ ストアでは、2 つのパートから成るシャード キーをサポートしており、このキーにはシャードを識別するパーティション キー要素と、シャード内のアイテムを一意に識別する行キーが含まれています。 データは通常、シャードで行キーの順番に保持されています。 範囲クエリの対象でグループ化される必要のある項目は、パーティション キーに対して同じ値を持ち、行キーに対して一意の値を持つシャード キーを使用できます。
ハッシュ戦略 この戦略の目的は、ホットスポット (過剰な負荷を受けるシャード) の可能性を減らすことです。 各シャードのサイズとシャードに対する平均負荷でバランスを取るように、シャード間でデータが分散されます。 シャーディング ロジックにより、1 つ以上のデータの属性のハッシュに基づいて、項目をシャードに格納するよう計算されます。 選択されたハッシュ関数により、ランダムな要素を計算に導入することで、データはシャード間で均等に分配されます。 次の図表は、テナント ID のハッシュに基づいたテナント データのシャーディングを示しています。
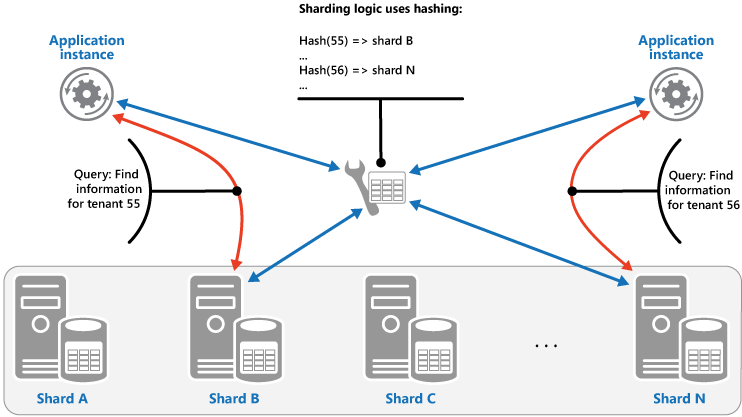
ハッシュ戦略が他のシャーディング戦略より優れている点を理解するために、新しいテナントを順番に登録するマルチテナント アプリケーションが、どのようにテナントをデータ ストアのシャードに割り当てるかを考えます。 範囲戦略では、テナント 1 から n のデータはすべてシャード A に、テナント (n+1) のデータはすべてシャード B にといったように格納されます。 最後に登録したテナントが最もアクティブな場合、多くのデータ操作は少ない数のシャードで行われることとなり、ホット スポットの原因となる可能性があります。 一方ハッシュ戦略では、テナントはテナント ID のハッシュに基づいてシャードに割り当てられます。 これにより、順に並んだテナント同士は別々のシャードに割り当てられる可能性が最も高く、負荷がシャード間で分散されます。 前の図表は、テナント 55 と 56 についてこれを示しています。
3 つのシャーディング戦略の利点と注意点は、次のとおりです。
Lookup この方法では、シャードの構成と使用方法について詳細に制御できます。 仮想シャードを使用すると、新しい物理パーティションが追加して負荷を均等するため、負荷を調整するときの影響を抑えることができます。 仮想シャードとシャードを実装する物理パーティション間のマッピングは、データの格納や取得にシャード キーを使用するアプリケーション コードに影響を与えずに変更できます。 シャードの場所を検索すると、追加のオーバーヘッドが適用される場合があります。
範囲 これは簡単に実装でき、1 回の操作で 1 つのシャードから複数のデータ項目を取得できることが多いため、範囲クエリに適しています。 この戦略を採用すると、データ管理がより容易になります。 たとえば、同じリージョン内のユーザーが同じシャードにある場合、その地域の負荷や要求パターンに基づいて、各タイム ゾーンで更新プログラムをスケジュールできます。 ただし、この戦略では、シャード間での分散は最適化されません。 シャードの再調整は難しく、アクティビティの大部分が隣接するシャード キーの場合、不均一な負荷の問題を解決できない可能性があります。
ハッシュ この方法によって、データと負荷の配分がより均等になる可能性が高くなります。 ハッシュ関数を使用して、直接ルーティングを要求できる可能性があります。 マップを管理する必要はありません。 ハッシュの計算により、オーバー ヘッドが追加される可能性があることにご注意ください。 また、シャードを再調整することは困難です。
最も一般的なシャーディング システムは上記のいずれかのアプローチを実装しますが、アプリケーションのビジネス要件とデータの使用状況のパターンも考慮する必要があります。 たとえば、マルチテナント アプリケーションでは次のような点を考慮します。
ワークロードに基づいてデータをシャーディングできます。 変動が大きいテナントのデータを別のシャードに分離できる場合があります。 その結果、その他のテナントに対するデータ アクセスの速度が向上する可能性があります。
テナントの場所に基づいてデータをシャーディングできます。 特定の地理的リージョンにおけるテナントのデータをオフラインでバックアップとして取得し、その地域のオフピーク時間内にメンテナンスできます。この間に、他のリージョンのテナントのデータをオンラインにし、業務時間内にアクセスできるようにしておけます。
重要なテナントは、高性能で軽負荷の独自のシャードに割り当てることができ、反対に重要度の低いテナントは、より密度と使用率の高いシャードを共有することができます。
高度なデータの分離とプライバシーを必要とするテナントのデータは、完全に別のサーバーに格納できます。
スケーリングとデータ移動の操作
それぞれのシャーディング戦略は、スケールイン、スケールアウト、データ移動の管理と状態の維持において、それぞれ異なる機能と複雑性のレベルを含んでいます。
Lookup 戦略では、オンラインまたはオフライン問わずユーザー レベルでスケーリングとデータ移動を行うことができます。 このテクニックでは、一部またはすべてのユーザー アクティビティを中断し (オフピーク時)、データを新しい仮想パーティションまたは物理シャードに移動し、マッピングを変更して、このデータを保持するキャッシュを無効にするか、更新してから、ユーザー アクティビティの再開を許可します。 ほとんどの場合、このタイプの操作は一元的に管理できます。 Lookup 戦略では、キャッシュ可能かつレプリカしやすい状態が必要です。
範囲戦略では、シャード全体でデータを分割したり統合したりする必要があるため、データ ストアの一部や全体がオフラインのときに実行する必要のあるスケーリングやデータ移動の操作に一部の制限がかかります。 アクティビティの大半が隣接するシャード キーまたは同じ範囲内にあるデータの識別子の場合、シャードを再調整するためにデータを移動しても、不均一な負荷の問題を解決できない場合があります。 また、範囲戦略では範囲を物理パーティションにマップするために、一部の状態を保持しておく必要があることがあります。
ハッシュ戦略では、パーティション キーがシャード キーまたはデータ識別子のハッシュであるため、スケーリングとデータ移動がさらに複雑になります。 各シャードの新しい場所は、ハッシュ関数または正しいマッピングを提供するために修正された関数から特定する必要があります。 ただし、ハッシュ戦略では、状態のメンテナンスは不要です。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
シャーディングは、垂直的パーティション分割や機能的パーティション分割といったパーティション分割の他の形式を補完するものです。 たとえば、1 つのシャードに垂直方向にパーティション分割されているエンティティを含めたり、機能パーティションを複数のシャードとして実装したりできます。 パーティション分割の詳細については、「データのパーティション分割のガイダンス」をご覧ください。
I/O の同様のボリュームを処理するために分散されたシャードを保持します。 データの挿入や削除に際し、シャードを定期的に再調整して、均等な配分を保証し、ホットスポットの可能性を軽減する必要があります。 再調整はコストのかかる操作です。 再調整の必要性を減らすには、予想されるボリュームの変化に対応できるよう各シャードに十分な空き領域を持たせ、拡張に備えます。 再調整が必要になったときに備えて、迅速にシャードを再調整するための戦略とスクリプトを作成しておくことも必要です。
シャード キーには安定したデータを使用します。 シャード キーが変更された場合は、対応するデータ項目をシャード間で移動する必要が生じ、更新作業が増える場合があります。 このため、不安定な情報に基づいてシャードを作成しないようにします。 代わりに、バリアントではない、または自然にキーを形成する属性を探します。
シャード キーは必ず一意である必要があります。 たとえば、自動増分されるフィールドをシャード キーとして使用しないでください。 一部のシステムでは、自動増分されるフィールドをシャード全体で調整することができないため、異なるシャードに同じシャード キーがあるという状態になる場合があります。
シャード キー以外でも、他のフィールドで自動増分される値がある場合は問題の原因となることがあります。 たとえば、自動増分されるフィールドを使って一意の ID を作成した場合、異なるシャード内の異なる 2 つのアイテムに、同じ ID が割り当てられる可能性があります。
データに対するすべてのクエリの要件に一致するシャード キーを設計できない可能性があります。 データをシャーディングして最も頻繁に実行されるクエリに対応し、必要に応じてセカンダリのインデックス テーブルを作成して、シャード キーの一部ではない属性に基づいた条件を使ってデータを取得するクエリをサポートします。 詳細については、「Index Table Pattern (インデックス テーブル パターン)」をご覧ください。
1 つのシャードのみにアクセスするクエリは、複数のシャードからデータを取得するクエリよりも効率的であるため、アプリケーションが別のシャードにあるデータを結合するような大量のクエリを実行することになるシャーディング システムは実施しないようにします。 1 つのシャードには、複数のエンティティ タイプを含めることができます。 データを非正規化して、同時に照会されることの多い、関連するエンティティ (顧客やその注文の詳細など) を同じシャードに維持することで、アプリケーションが実行する個別の読み取り数を減らします。
1 つのシャード内のエンティティが別のシャードにあるエンティティを参照する場合、2 つ目のエンティティのシャード キーを、1 つ目のエンティティのスキーマの一部に含めます。 これは、シャード間で関連するデータを参照するクエリのパフォーマンス向上に役立ちます。
アプリケーションが複数のシャードからデータを取得するクエリを実行する必要がある場合は、並列タスクを使用してこのデータを取得できる場合があります。 例として、複数のシャードからのデータを並列で取得し、1 つの結果に集計するファンアウト クエリなどがあります。 ただし、この方法では必然的にソリューションのデータ アクセス ロジックが複雑化します。
多くのアプリケーションでは、小さなシャードを多数作成する方が、負荷分散のチャンスが増加するため、大きなシャードを少数持つよりも効果的になります。 これは、シャードを物理的な場所から別の場所に移行させる予定がある場合に特に便利です。 シャードの移動は、大きいよりも小さいほうが早く行えます。
各シャード ストレージ ノードで利用できるリソースが、データ サイズとスループットの観点で拡張性の要件を満たすことを確認します。 詳細については、「データのパーティション分割ガイダンス」の「拡張性の観点でのパーティション分割の設計」セクションをご覧ください。
すべてのシャードへの参照データのレプリケーションをご検討ください。 シャードからデータを取得する操作で、同じクエリの一部として静的データまたは低速データも参照する場合は、このデータをシャードに追加します。 そうすれば、アプリケーションが別のデータ ストアにラウンド トリップすることなくクエリのすべてのデータを簡単に取得できるようになります。
複数のシャードにある参照データが変更された場合、システムはその変更点をすべてのシャードで同期する必要があります。 この同期処理中に、ある程度の不整合が発生することがあります。 この操作を行う場合は、それを処理できるアプリケーションを設計する必要があります。
参照の整合性とシャード間の一貫性を維持するのは難しいため、複数のシャードのデータに影響を与える操作は最小限に抑える必要があります。 アプリケーションでシャード間のデータを修正する必要がある場合は、完全なデータの整合性が必要かどうかを評価します。 クラウドでの一般的な手法では、強力な整合性の代わりに、結果整合性を実装します。 各パーティションのデータは個別に更新され、アプリケーションのロジックですべての更新が正常に完了したことを確認する必要があります。また、結果整合性の操作が実行している間、データをクエリすることにより発生する可能性のある不整合を処理することができます。 結果整合性を実装する方法の詳細については、「Data consistency primer (データ整合性入門)」をご覧ください。
多数のシャードの構成と管理は難しい作業です。 監視、バックアップ、一貫性のチェック、ログ記録、監査などのタスクは、複数のシャード、サーバー、場合によっては複数の場所で実施する必要があります。 これらのタスクはスクリプトや他の自動化ソリューションを使用して実施されることがよくありますが、それでも追加の管理要件が必要になる場合があります。
シャードに含まれるデータを、それを使用するアプリケーションのインスタンスの近くに置くことができます。 この方法によってパフォーマンスを大幅に向上させることができますが、異なる場所にある複数のシャードにアクセスする必要のあるタスクの場合、考慮すべき点もあります。
このパターンを使用する状況
データ ストアを 1 つのストレージ ノードで利用できるリソースの範囲を超えて拡張する必要がある場合、またはデータ ストア内の競合を減らすことでパフォーマンスを向上させる場合に、このパターンを使用します。
注意
シャーディングの主な目的は、パフォーマンスとシステムのスケーラビリティを向上させることですが、同時に、データがどのように別のパーティションに分けられるかによって可用性も改善される場合があります。 1 つのパーティションで障害が起こったとしても、アプリケーションから他のパーティションにあるデータには問題なくアクセスできる場合があり、すべてのデータをアクセス不可にすることなく、1 つまたは複数のパーティションのメンテナンスやリカバリを実行できます。 詳細については、「データのパーティション分割のガイダンス」をご覧ください。
ワークロード設計
設計者は、 Azure Well-Architected Framework の柱 で説明されている目標と原則に対処するために、ワークロードの設計でどのようにシャーディング パターンを使用できるかを評価する必要があります。 次に例を示します。
| 重要な要素 | このパターンが柱の目標をサポートする方法 |
|---|---|
| 信頼性 設計の決定により、ワークロードが 誤動作 に対して 復元力 を持ち、障害発生後も完全に機能する状態に 回復 することができます。 | データや処理はシャードに分離されているため、1 つのシャードで誤動作が発生しても、障害はそのシャードに分離された状態に保たれます。 - RE:06 データパーティショニング - RE:07 自己保護 |
| コスト最適化 は、ワークロードの 投資収益率の 維持と改善 に重点を置いています。 | シャードを実装するシステムでは、多くの場合、コストの高い単一のリソースを使用するのではなく、よりコストの低いコンピューティング リソースやストレージ リソースの複数のインスタンスを使用することができます。 多くの場合、この構成によってコストを節約できます。 - CO:07 コンポーネントコスト |
| パフォーマンスの効率化 は、スケーリング、データ、コードを最適化することによって、ワークロードが 効率的にニーズを満たす のに役立ちます。 | スケーリング戦略でシャーディングを使用すると、データや処理が 1 つのシャードに分離されるため、リソースの競合は同じシャードに送信された他の要求との間でしか発生しなくなります。 シャーディングは、地理に基づいた最適化のためにも使用できます。 - PE:05 スケーリングとパーティショニング - PE:08 データパフォーマンス |
設計決定と同様に、このパターンで導入される可能性のある他の柱の目標とのトレードオフを考慮してください。
例
世界中で発行された書籍に関する広範な情報のコレクションを表示する Web サイトについて考えてみましょう。 このワークロードでカタログ化できる書籍の数と、一般的なクエリ/使用パターンは、書籍情報を格納するための単一のリレーショナル データベースの使用を示します。 ワークロード アーキテクトは、シャード キーとして書籍の静的な国際標準図書番号 (ISBN) を使用して、複数のデータベース インスタンスにわたってデータをシャーディングすることを決定します。 具体的には、ISBN の チェック桁 (0 ~ 10) を使用します。これは、可能な論理シャードが 11 個与えられるため、データは各シャード間で均等に分散されます。 まず、11 個の論理シャードを 3 つの物理シャード データベースに併置することにしました。 検索 シャーディング アプローチを使用し、キーとサーバーのマッピング情報をシャード マップ データベースに保存します。
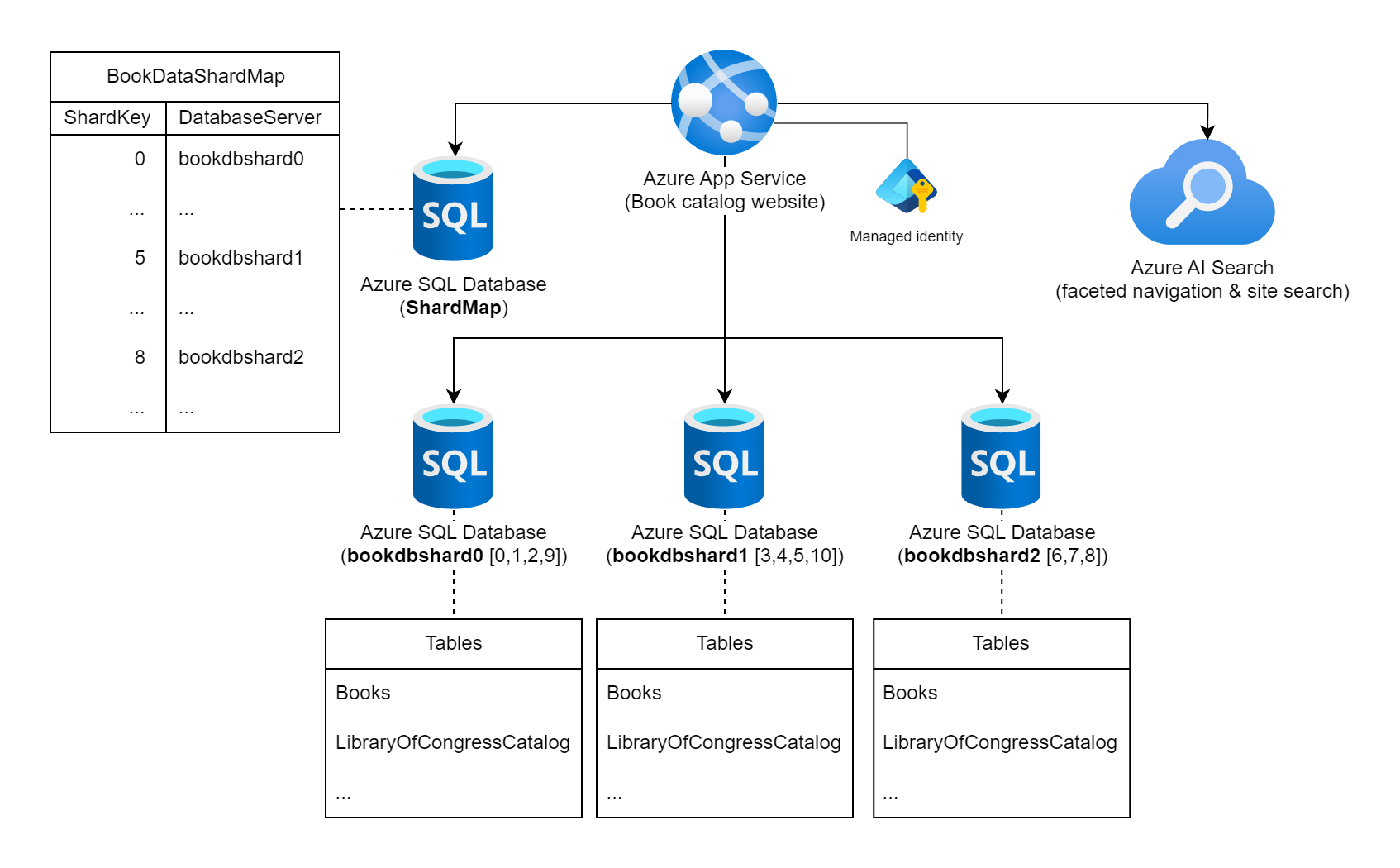
複数の Azure SQL データベース インスタンスと Azure AI 検索 インスタンスに接続されている「書籍カタログ Web サイト」というラベルの付いた Azure App Services を示す図。 データベースの 1 つは ShardMap データベースとしてラベル付けされており、マッピング テーブルの一部をミラーするサンプル テーブルもこのドキュメントに記載されています。 bookdbshard0、bookdbshard1、bookdbshard2 の 3 つのシャード データベース インスタンスも一覧表示されています。 各データベースには、その下にテーブルのリストの例があります。 3 つの例はすべて同じです。"Books" と "LibraryOfCongressCatalog" のテーブルと、その他のテーブルのインジケーターが一覧表示されます。 Azure AI 検索アイコンは、ファセット ナビゲーションとサイト検索に使用されていることを示します。 マネージド ID は、Azure App Servicesに関連付けられている状態で表示されます。
検索シャード マップ
シャード マップ データベースには、次のシャード マッピング テーブルとデータが含まれています。
SELECT ShardKey, DatabaseServer
FROM BookDataShardMap
| ShardKey | DatabaseServer |
|----------|----------------|
| 0 | bookdbshard0 |
| 1 | bookdbshard0 |
| 2 | bookdbshard0 |
| 3 | bookdbshard1 |
| 4 | bookdbshard1 |
| 5 | bookdbshard1 |
| 6 | bookdbshard2 |
| 7 | bookdbshard2 |
| 8 | bookdbshard2 |
| 9 | bookdbshard0 |
| 10 | bookdbshard1 |
Web サイト コードの例 - シングル シャード アクセス
Web サイトは、物理シャード データベースの数 (この場合は 3 つ) も、シャード キーをデータベース インスタンスにマップするロジックも認識していませんが、Web サイトでは、書籍の ISBN のチェック桁をシャード キーと見なす必要があることを認識しています。 Web サイトには、シャード マップ データベースへの読み取り専用アクセスと、すべてのシャード データベースへの読み取り/書き込みアクセス権があります。 この例では、web サイトは、接続文字列からシークレットを保持する承認のために Web サイトをホストしているAzure App Servicesのシステム マネージド ID を使用しています。
Web サイトは、次の接続文字列で構成されています。この例のような appsettings.json ファイル内、または App Services アプリの設定を使用します。
{
...
"ConnectionStrings": {
"ShardMapDb": "Data Source=tcp:<database-server-name>.database.windows.net,1433;Initial Catalog=ShardMap;Authentication=Active Directory Default;App=Book Site v1.5a",
"BookDbFragment": "Data Source=tcp:SHARD.database.windows.net,1433;Initial Catalog=Books;Authentication=Active Directory Default;App=Book Site v1.5a"
},
...
}
シャード マップ データベースへの接続情報を使用できる場合、Web サイトによってワークロードのデータベース シャード プールに対して実行される更新クエリの例は、次のコードのようになります。
...
// All data for this book is stored in a shard based on the book's ISBN check digit,
// which is converted to an integer 0 - 10 (special value 'X' becomes 10).
int isbnCheckDigit = book.Isbn.CheckDigitAsInt;
// Establish a pooled connection to the database shard for this specific book.
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: isbnCheckDigit, cancellationToken))
{
// Update the book's Library of Congress catalog information
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"UPDATE LibraryOfCongressCatalog
SET ControlNumber = @lccn,
...
Classification = @lcc
WHERE BookID = @bookId";
cmd.Parameters.AddWithValue("@lccn", book.LibraryOfCongress.Lccn);
...
cmd.Parameters.AddWithValue("@lcc", book.LibraryOfCongress.Lcc);
cmd.Parameters.AddWithValue("@bookId", book.Id);
await cmd.ExecuteNonQueryAsync(cancellationToken);
}
...
前のコード例では、 book.Isbn が 978-8-1130-1024-6の場合、 isbnCheckDigit は 6にする必要があります。 通常、 OpenShardConnectionForKeyAsync(6) 呼び出しはキャッシュ アサイド アプローチで実装されます。 シャード キー 6のシャード情報がキャッシュされていない場合は、接続文字列 ShardMapDb で識別されたシャード マップ データベースに対してクエリを実行します。 アプリケーションのキャッシュまたはシャード データベースのいずれかから、値 bookdbshard2 が BookDbFragment 接続文字列における SHARD の代わりに使用されます。 プールされた接続は bookdbshard2.database.windows.netに対して (再) 確立され、開いてから呼び出しコードに返されます。 その後、コードは、そのデータベース インスタンスの既存のレコードを更新します。
Web サイト コードの例 - 複数のシャード アクセス
まれに、Web サイトで直接のクロスシャード クエリが必要な場合、アプリケーションはすべてのシャードで並列ファンアウト クエリを実行します。
...
// Retrieve all shard keys
var shardKeys = shardedDatabaseConnections.GetAllShardKeys();
// Execute the query, in a fan-out style, against each shard in the shard list.
Parallel.ForEachAsync(shardKeys, async (shardKey, cancellationToken) =>
{
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: shardKey, cancellationToken))
{
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"SELECT ...
FROM ...
WHERE ...";
SqlDataReader reader = await cmd.ExecuteReaderAsync(cancellationToken);
while (await reader.ReadAsync(cancellationToken))
{
// Read the results in to a thread-safe data structure.
}
reader.Close();
}
});
...
このワークロードのクロスシャード クエリの代わりに、サイト検索やファセット ナビゲーション機能など、Azure AI 検索で外部メイン包含インデックスを使用する場合があります。
シャード インスタンスの追加
ワークロード チームは、データ カタログまたはその同時使用が大幅に増加した場合、3 つ以上のデータベース インスタンスが必要になる可能性があることを認識しています。 ワークロード チームは、データベース サーバーを動的に追加することは想定せず、新しいシャードをオンラインにする必要がある場合はワークロードのダウンタイムに耐えます。 新しいシャード インスタンスをオンラインにするには、シャード マップ テーブルの更新と共に、既存のシャードから新しいシャードにデータを移動する必要があります。 このかなり静的なアプローチにより、ワークロードは Web サイト コード内のシャード キー データベース マッピングを確実にキャッシュできます。
この例のシャード キー ロジックのハード上限は、物理シャードの最大 11 個です。 ワークロード チームが負荷見積もりテストを実行し、最終的に 11 を超えるデータベース インスタンスが必要になると評価した場合は、シャード キー ロジックに対する侵入的な変更を行う必要があります。 この変更には、コード変更の慎重な計画と、新しいキー ロジックへのデータ移行が含まれます。
SDK の機能
Azure SQL データベース インスタンスへのシャード管理とクエリ ルーティング用のカスタム コードを記述する代わりに、 Elastic Database クライアント ライブラリを評価します。 このライブラリは、C# と Java の両方でシャード マップ管理、データ依存クエリ ルーティング、およびクロスシャード クエリをサポートします。
次のステップ
このパターンを実装する場合は、次のガイダンスも関連している可能性があります。
- Data consistency primer (データ整合性入門)。 異なるシャード間に分散したデータの一貫性を維持する必要がある場合があります。 分散型データの一貫性の維持にまつわる問題と、異なる一貫性モデルのメリットとトレードオフについて説明します。
- データのパーティション分割のガイダンス。 データ ストアのシャーディングでは、新しい問題が発生する場合があります。 スケーラビリティの向上、競合の削減、パフォーマンスの最適化のため、クラウドのデータ ストアのパーティション分割に関する問題について説明します。
関連リソース
このパターンを実装する場合は、次のパターンも関連している可能性があります。
- Index Table Pattern (インデックス テーブル パターン)。 場合によっては、シャード キーの設計だけでクエリを完全にサポートできないことがあります。 シャード キー以外のキーを指定して、アプリケーションが大規模なデータ ストアからデータを簡単に取得できるようにします。
- Materialized View Pattern (具体化されたビュー パターン) クエリ操作のパフォーマンスを維持するには、特に、サマリー データがシャード全体に分散された情報に基づいている場合は、データを集計、要約する具体化されたビューを作成すると便利です。 これらのビューの生成、作成方法について説明します。