多くのサービスでは調整パターンを使用して自らが消費するリソースを制御し、他のアプリケーションやサービスからアクセスできるレートに制限を課します。 レート制限パターンを使用すると、これらの調整制限に関連する調整エラーを回避または最小化したり、スループットをより正確に予測したりするのに役立ちます。
レート制限パターンは多くのシナリオに適していますが、バッチ処理などの大規模な反復的自動化タスクで特にその効果を発揮します。
コンテキストと問題
調整されたサービスを使用して多数の操作を実行すると、拒否された要求を追跡してからそれらの操作を再試行する必要が生じ、トラフィックとスループットが増加するおそれがあります。 操作の数の増加に伴い、調整の制限でデータの再送信に複数のパスが必要になり、パフォーマンスに大きな影響が生じるおそれがあります。
一例として、Azure Cosmos DB へのデータの取り込みで、エラーが発生したら再試行するという次の素朴な処理を考えてみます。
- アプリケーションでは 10,000 件のレコードを Azure Cosmos DB に取り込む必要があります。 各レコードの取り込みには 10 個の要求ユニット (RU) が必要で、ジョブを完了するには合計 100,000 個の RU が必要です。
- ご使用の Azure Cosmos DB インスタンスには、20,000 個の RU 容量がプロビジョニングされています。
- 10,000 件すべてのレコードを Azure Cosmos DB に送信します。2,000 件のレコードが正常に書き込まれ、8,000 件のレコードが拒否されます。
- 残りの 8,000 件のレコードを Azure Cosmos DB に送信します。2,000 件のレコードが正常に書き込まれ、6,000 件のレコードが拒否されます。
- 残りの 6,000 件のレコードを Azure Cosmos DB に送信します。2,000 件のレコードが正常に書き込まれ、4,000 件のレコードが拒否されます。
- 残りの 4,000 件のレコードを Azure Cosmos DB に送信します。2,000 件のレコードが正常に書き込まれ、2,000 件のレコードが拒否されます。
- 残りの 2,000 件のレコードを Azure Cosmos DB に送信します。 すべて正常に書き込まれます。
インジェスト ジョブは正常に完了しましたが、データ セット全体の構成レコード数は 10,000 件だけであるにもかかわらず、Azure Cosmos DB に 30,000 件のレコードを送信しなければ完了しませんでした。
上記の例では、他にも考慮すべき要素があります。
- エラーの数が多いと、それらのエラーをログに記録して結果のログ データを処理する作業が増えるおそれがあります。 この素朴なアプローチでは 20,000 件のエラーが処理されることになり、これらのエラーをログに記録するために処理、メモリ、またはストレージ リソースのコストが発生するおそれがあります。
- この素朴なアプローチでは、インジェスト サービスの調整の制限がわからないため、データ処理にかかる時間を予測することができません。 レート制限を使用すると、インジェストに必要な時間を計算できます。
解決策
レート制限を使用すると、特定の期間にサービスに送信されるレコードの数が減るため、トラフィックを減らすことができ、スループットを改善できる可能性があります。
サービスでは、一定の時間のさまざまなメトリックに基づいて調整を行うことができます。次に例を示します。
- 操作の数 (例: 1 秒あたり 20 件の要求)。
- データの量 (例: 1 分あたり 2 GiB)。
- 操作の相対的なコスト (例: 1 秒あたり 20,000 個の RU)。
調整に使用されるメトリックに関係なく、レート制限の実装には、特定の期間にサービスに送信される操作の数とサイズ、またはその一方を制御することや、調整の容量を超えないようにしながらサービスの使用を最適化することが含まれます。
調整されたインジェスト サービスで許可されているよりも API による要求の処理速度が速いシナリオでは、サービスを使用する速度を管理する必要があります。 しかし、調整を単にデータ レートの不一致の問題と見なして、調整されたサービスが追いつくまでインジェスト要求を単純にバッファーリングするのは危険です。 このシナリオでアプリケーションがクラッシュすると、バッファーリングされたこのデータが失われるリスクがあります。
このリスクを回避するには、最大限のインジェスト レートを処理 "できる" 永続的なメッセージング システムへのレコードの送信をご検討ください (Azure Event Hubs などのサービスでは、1 秒間に数百万回の操作を処理できます)。 その後、1 つ以上のジョブ プロセッサを使用して、調整されたサービスの制限内の制御されたレートでメッセージング システムからレコードを読み取ることができます。 メッセージング システムにレコードを送信すると、特定の時間間隔で処理できるレコードのみをデキューすることができるため、内部メモリを節約できます。
Azure には、このパターンで使用できるいくつかの永続的なメッセージング サービスが用意されています。たとえば、次のものがあります。
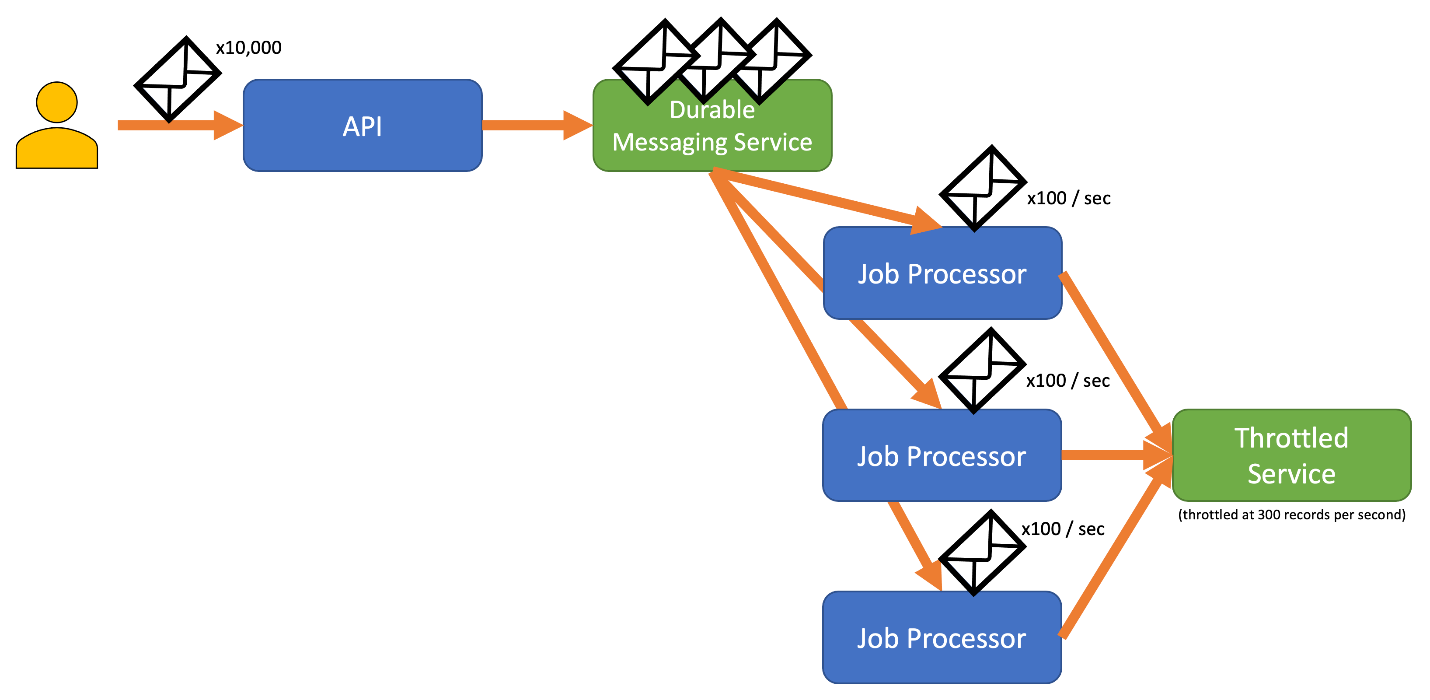
レコードを送信する場合、レコードの解放に使用する期間は、サービスで調整する期間よりも細かくなることがあります。 多くの場合、システムでは、把握しやすく、操作しやすい期間に基づいてスロットルが設定されます。 ただし、サービスを実行しているコンピューターにとって、これらの期間は、情報を処理できる速度に比べて非常に長い可能性があります。 たとえば、システムで 1 秒または 1 分単位で調整される場合でも、通常、コードはナノ秒またはミリ秒単位で処理されます。
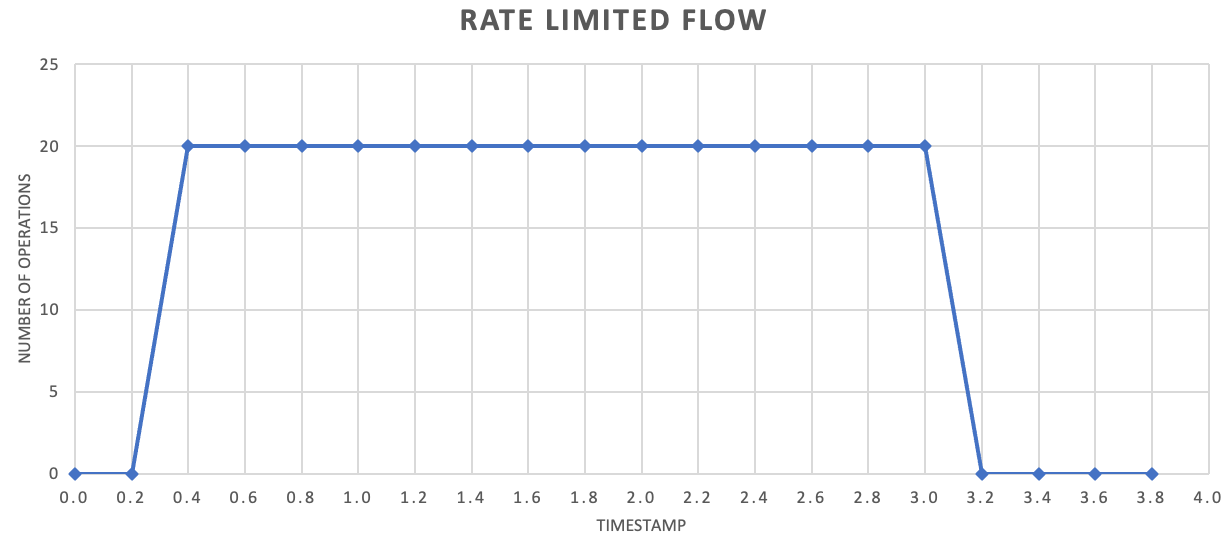
必須ではありませんが、スループットを向上させるために、より少ないレコードをより頻繁に送信することをお勧めします。 したがって、1 秒に 1 回または 1 分に 1 回、リリースのバッチ処理を実行するのではなく、それよりも細かく設定して、リソース消費 (メモリ、CPU、ネットワークなど) の流れをより均一に保ち、突発的な要求の急増によって生じる潜在的なボトルネックを防ぐことができます。 たとえば、サービスで 1 秒あたり 100 回の操作が許可されている場合、レート制限機能の実装で、次のグラフに示すように、200 ミリ秒ごとに 20 回の操作を解放することで、要求を均等にすることができます。
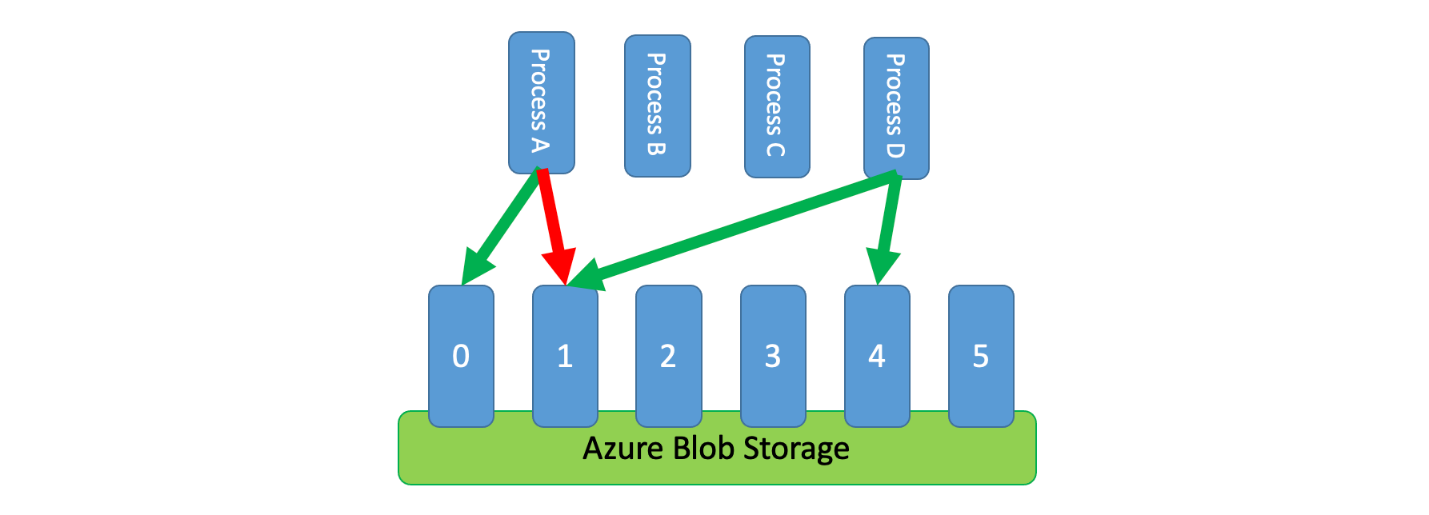
さらに、調整されていない複数のプロセスで、調整されたサービスを共有する必要がある場合もあります。 このシナリオでレート制限を実装するには、サービスの容量を論理的にパーティション分割し、分散相互排他システムを使用してそれらのパーティションに対する排他ロックを管理します。 調整されていないプロセスで容量が必要になる場合はいつでも、それらのパーティションでロックの競合が発生する可能性があります。 プロセスでは、ロックを保持しているパーティションごとに、一定の容量が付与されます。
たとえば、調整されたシステムで毎秒 500 件の要求が許可されている場合、20 個のパーティションを作成し、それぞれ毎秒 25 個の要求を処理できるようにすることができます。 プロセスで 100 件の要求を発行する必要がある場合、分散相互排他システムに 4 つのパーティションを要求します。 このシステムから 10 秒間に 2 つのパーティションが許可されます。 そこで、プロセスは制限を 1 秒あたり 50 件の要求に調整し、2 秒でタスクを完了してから、ロックを解放します。
このパターンを実装する 1 つの方法は、Azure Storage を使用することです。 このシナリオでは、コンテナー内の論理パーティションごとに 0 バイトの BLOB を 1 つ作成します。 その後、アプリケーションは短期間 (たとえば、15 秒) にわたって、これらの BLOB に対する排他的リースを直接取得できます。 アプリケーションは、付与されるリースごとに、そのパーティション分の容量を使用できます。 それから、アプリケーションはリース時間を追跡し、有効期限が切れたら付与された容量の使用を停止できるようにする必要があります。 このパターンの実装でしばしば必要になるのは、容量が必要になったとき、各プロセスでランダムなパーティションのリースを試みることです。
待機時間をさらに短縮するために、プロセスごとに少量の排他容量を割り当てることもできます。 この場合、プロセスでは、予約容量を超える容量が必要な場合にのみ、共有容量のリースを取得しようとします。
Azure Storage の代わりに、Zookeeper、Consul、etcd、Redis/Redsync などのテクノロジを使用して、この種のリース管理システムを実装することもできます。
問題と注意事項
このパターンの実装方法を決めるときには、以下にご注意ください。
- レート制限パターンによって調整エラーの数を減らすことができますが、生じ得るあらゆる調整エラーをアプリケーションで適正に処理する必要があることに変わりはありません。
- お客様のアプリケーションに、調整された同じサービスにアクセスする複数のワークストリームがある場合、それらすべてをお客様のレート制限戦略に統合する必要があります。 たとえば、データベースへのレコードの一括読み込みだけでなく、その同じデータベース内のレコードのクエリもサポートできるかもしれません。 すべてのワークストリームが同じレート制限メカニズムによって制御されるようにすることで、容量を管理することができます。 または、ワークストリームごとに別々の容量プールを予約することもできます。
- 調整されたサービスは、複数のアプリケーションで使用できます。 すべてではありませんが、場合によっては、この使用方法を調整することができます (上記を参照)。 予想よりも多くの調整エラーが発生し始める場合は、1 つのサービスにアクセスするアプリケーション間の競合の兆候である可能性があります。 その場合は、他のアプリケーションからの使用頻度が低くなるまで、レート制限メカニズムによって課されたスループットを一時的に減らすことを検討する必要がある可能性があります。
このパターンを使用する状況
このパターンは次の目的で使用します。
- 調整で制限されているサービスによって発生する調整エラーを削減する。
- エラーが発生したら再試行するという素朴なアプローチよりもトラフィックを削減する。
- レコードを処理する容量がある場合にだけそれをデキューすることで、メモリ消費量を削減する。
ワークロード設計
設計者は、Azure Well-Architected Framework の柱で説明されている目標と原則に対処するために、ワークロードの設計でどのようにレート制限パターンを使用できるかを評価する必要があります。 次に例を示します。
| 重要な要素 | このパターンが柱の目標をサポートする方法 |
|---|---|
| 信頼性 設計の決定により、ワークロードが 誤動作 に対して復元力を持ち、障害発生後も完全に機能する状態に 回復 することができます。 | この戦術では、サービスが過度な使用の回避を求めている場合に、そのサービスと通信するときの制限とコストを確認して尊重することで、クライアントを保護します。 - RE:07 自己保護 |
設計決定と同様に、このパターンで導入される可能性のある他の柱の目標とのトレードオフを考慮してください。
例
次のアプリケーションの例では、ユーザーはさまざまな種類のレコードを API に送信できます。 レコードの種類ごとに、以下の手順を実行する一意のジョブ プロセッサがあります。
- 検証
- エンリッチメント
- データベースへのレコードの挿入
アプリケーションのすべてのコンポーネント (API、ジョブ プロセッサ A、ジョブ プロセッサ B) は、独立的にスケーリングできる別々のプロセスです。 各プロセスが相互に直接通信することはありません。
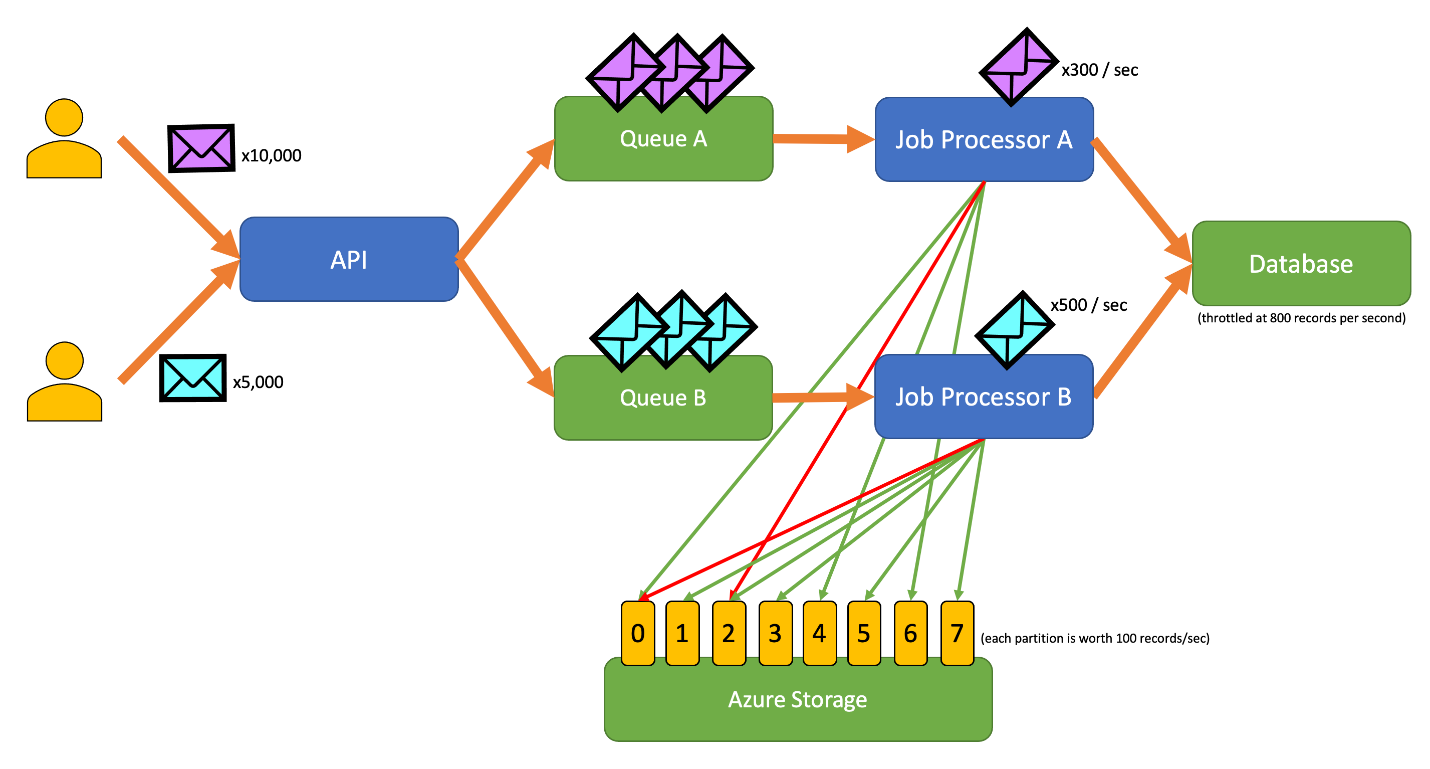
この図には、次のワークフローが組み込まれています。
- ユーザーが A タイプの 10,000 件のレコードを API に送信します。
- API により、これらの 10,000 件のレコードがキュー A にエンキューされます。
- ユーザーが B タイプの 5,000 件のレコードを API に送信します。
- API により、これらの 5,000 件のレコードがキュー B にエンキューされます。
- ジョブ プロセッサ A では、キュー A にレコードがあることを確認し、BLOB 2 の排他的リースの取得を試みます。
- ジョブ プロセッサ B では、キュー B にレコードがあることを確認し、BLOB 2 の排他的リースの取得を試みます。
- ジョブ プロセッサ A では、リースの取得に失敗します。
- ジョブ プロセッサ B では、BLOB 2 のリースを 15 秒間取得します。 これで、データベースへの要求を毎秒 100 件というレートでレート制限できるようになりました。
- ジョブ プロセッサ B では、キュー B から 100 件のレコードをデキューして、それらを書き込みます。
- 1 秒が経過します。
- ジョブ プロセッサ A では、キュー A により多くのレコードがあることを確認し、BLOB 6 の排他的リースの取得を試みます。
- ジョブ プロセッサ B では、キュー B により多くのレコードがあることを確認し、BLOB 3 の排他的リースの取得を試みます。
- ジョブ プロセッサ A では、BLOB 6 のリースを 15 秒間取得します。 これで、データベースへの要求を毎秒 100 件というレートでレート制限できるようになりました。
- ジョブ プロセッサ B では、BLOB 3 のリースを 15 秒間取得します。 これで、データベースへの要求を毎秒 200 件というレートでレート制限できるようになりました (BLOB 2 のリースも保持されます)。
- ジョブ プロセッサ A では、キュー A から 100 件のレコードをデキューして、それらを書き込みます。
- ジョブ プロセッサ B では、キュー B から 200 件のレコードをデキューして、それらを書き込みます。
- 1 秒が経過します。
- ジョブ プロセッサ A では、キュー A により多くのレコードがあることを確認し、BLOB 0 の排他的リースの取得を試みます。
- ジョブ プロセッサ B では、キュー B により多くのレコードがあることを確認し、BLOB 1 の排他的リースの取得を試みます。
- ジョブ プロセッサ A では、BLOB 0 のリースを 15 秒間取得します。 これで、データベースへの要求を毎秒 200 件というレートでレート制限できるようになりました (BLOB 6 のリースも保持されます)。
- ジョブ プロセッサ B では、BLOB 1 のリースを 15 秒間取得します。 これで、データベースへの要求を毎秒 300 件というレートでレート制限できるようになりました (BLOB 2 および 3 のリースも保持されます)。
- ジョブ プロセッサ A では、キュー A から 200 件のレコードをデキューして、それらを書き込みます。
- ジョブ プロセッサ B では、キュー B から 300 件のレコードをデキューして、それらを書き込みます。
- 以降同様
15 秒後も、一方または両方のジョブが完了しません。 リースの有効期限が切れると、プロセッサではデキューおよび書き込みを行う要求の数を減らす必要もあります。
 このパターンの実装は、さまざまなプログラミング言語で使用できます。
このパターンの実装は、さまざまなプログラミング言語で使用できます。
関連リソース
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- 調整: こちらで説明するレート制限パターンは、通常、調整されたサービスに応じて実装されます。
- 再試行する。 調整されたサービスに対する要求によって調整エラーが発生する場合、一般に適切なのは、適切な間隔を空けて再試行することです。
キュー ベースの負荷平準化は、レート制限パターンと似ていますが、いくつかの重要な点で異なります。
- レート制限では負荷の管理に必ずしもキューを使用する必要はないのに対し、こちらでは永続的なメッセージング サービスを使用する必要があります。 たとえば、レート制限パターンでは、Apache Kafka や Azure Event Hubs などのサービスを使用できます。
- レート制限パターンでは、パーティションに対して分散相互排他システムの概念が導入されています。これにより、調整された同じサービスと通信する、調整されていない複数のプロセスの容量を管理できます。
- キュー ベースの負荷平準化パターンは、サービス間でパフォーマンスの不一致がある場合や回復力を向上させる場合にいつでも適用できます。 そのため、これは、調整されたサービスへの効率的なアクセスにより特化しているレート制限に比べて、より幅広いパターンです。