アプリケーションとサービスが正常に実行されていることを確認するには、正常性エンドポイント監視パターンを使います。 このパターンには、アプリケーションの機能チェックの使用を指定します。 外部ツールは、公開されたエンドポイントを介して、定期的にこれらのチェックにアクセスできます。
コンテキストと問題
Web アプリケーションとバックエンド サービスを監視することをお勧めします。 監視は、アプリケーションとサービスが使用可能であり、正しく動作していることを確認するのに役立ちます。 多くの場合、ビジネス要件には監視が含まれます。
クラウド サービスの監視は、オンプレミスのサービスよりも難しい場合があります。 その理由の 1 つは、ホスティング環境を完全に制御できないことです。 もう 1 つは、通常、このようなサービスは、プラットフォーム ベンダーなどが提供する他のサービスに依存していることです。
多くの要因がクラウドホステッド アプリケーションに影響します。 たとえば、ネットワークの待機時間、基となるコンピューティング システムやストレージ システムのパフォーマンスと可用性、それらの間のネットワーク帯域幅です。 サービスは、これらの要素のいずれかが原因で、完全に失敗することもあれば、部分的に失敗することもあります。 必要なレベルの可用性を確保するには、サービスが正しく動作しているかどうかを定期的に確認する必要があります。 サービス レベル アグリーメント (SLA) には、満たす必要があるレベルが指定されている場合があります。
解決策
アプリケーションのエンドポイントに要求を送信して、稼働状況の監視を実装します。 アプリケーションによって必要なチェックが実行され、その後にその状態を示す値が返されます。
通常、正常性の監視のチェックでは 2 つの要素が組み合わされます。
- 正常性確認エンドポイントへの要求に応じて、アプリケーションまたはサービスによって実行されるチェック (ある場合)
- 正常性確認チェックを実行するツールまたはフレームワークによる結果の分析
応答コードは、アプリケーションの状態を示します。 応答コードで、アプリが使うコンポーネントとサービスの状態が示されることもあります。 監視ツールまたはフレームワークを使って、待機時間または応答時間のチェックを実行できます。
次の図は、パターンの概要を示しています。
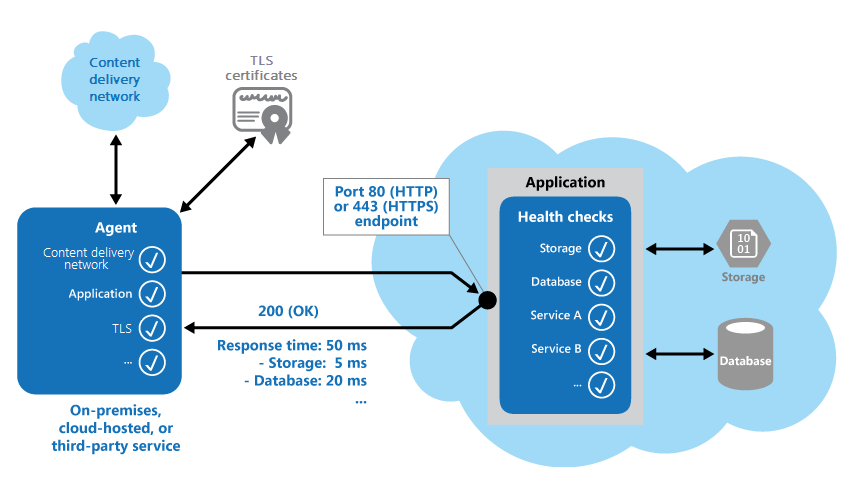
アプリケーションの稼働状況の監視コードを使い、他のチェックを実行して以下を判断することもできます。
- クラウド ストレージまたはデータベースの可用性と応答時間。
- アプリケーションが使う他のリソースまたはサービスの状態。 これらのリソースとサービスは、アプリケーションの内部または外部にあることがあります。
構成可能な一連のエンドポイントに要求を送信することで、Web アプリケーションを監視するサービスとツールを使用できます。 これらのサービスやツールを使って、構成可能な一連の規則に対して結果を評価します。 システムでいくつかの機能テストを実行することだけが目的のサービス エンドポイントの作成は比較的簡単です。
監視ツールが実行する一般的なチェックには、次のようなものがあります。
- 応答コードの確認。 たとえば HTTP 応答 200 (OK) は、アプリケーションがエラーなしで応答したことを示します。 監視システムは、より包括的な結果が得られるように、他の応答コードをチェックする場合もあります。
- 状態コードが 200 (OK) の場合でも、エラーを検出することを目的とした応答の内容の確認。 この内容を確認することにより、返された Web ページまたはサービスの応答の一部にのみ影響するエラーを検出できます。 たとえば、ページのタイトルを確認したり、アプリから正しいページが返されたことを示す特定のフレーズを探したりすることができます。
- 応答時間の測定。 この値には、ネットワークの待機時間と、アプリケーションが要求を発行するのにかかった時間が含まれます。 値が大きくなると、アプリケーションまたはネットワークで新しく発生した問題を示唆している可能性があります。
- アプリケーションの外部にあるリソースまたはサービスの確認。 例として、アプリケーションがグローバル キャッシュからコンテンツを配信するために使うコンテンツ配信ネットワークがあります。
- TLS 証明書の有効期限の確認。
- アプリケーションの URL に対する DNS 参照の応答時間の測定。 このチェックにより、DNS の待機時間と DNS の失敗を測定します。
- DNS 参照から返された URL の検証。 検証することで、エントリが正しいことを確認できます。 また、DNS サーバーに対する攻撃の結果として発生するような、悪意のある要求のリダイレクトを防ぐこともできます。
また、可能であれば、これらのチェックをさまざまなオンプレミスの場所またホストされた場所から実行し、応答時間を比較することも役立ちます。 理想的には、顧客の近い場所からアプリケーションを監視することをお勧めします。 そうすると、各拠点のパフォーマンスを正確に把握できます。 この方法は、より堅牢なチェック メカニズムとして機能します。 また、この結果は、次のような決定にも役立ちます。
- アプリケーションをデプロイする場所
- 複数のデータセンターにデプロイするかどうか
アプリケーションがすべての顧客に対して正常に機能するように確保するには、顧客が使うすべてのサービス インスタンスに対してテストを実行します。 たとえば、顧客のストレージが複数のストレージ アカウントに分散されている場合、監視プロセスでは各アカウントをすべて確認する必要があります。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
応答を検証する方法を考えます。 たとえば、アプリケーションが正常に機能していることを確認するには、200 (OK) 状態コードで十分かどうかを判断します。 状態コードを確認することは、このパターンの最小限の実装です。 状態コードは、アプリケーションの可用性の基本的な尺度として機能します。 ただし、コードでは、アプリケーションの操作、傾向、今後起こりうる問題についての情報がほとんどわかりません。
アプリケーション用に公開するエンドポイント数を決めます。 1 つの方法は、アプリケーションが使うコア サービス用に少なくとも 1 つ、優先順位の低いサービス用にもう 1 つのエンドポイントを公開することです。 この方法では、各監視結果に対してさまざまなレベルの重要度を割り当てることができます。 また、追加のエンドポイントを公開することも検討します。 コア サービスごとに 1 つを公開することで、監視の細分性を高めることができます。 たとえば、正常性確認チェックでは、データベース、ストレージと、アプリケーションが使う外部のジオコーディング サービスを確認できます。 それぞれに必要なレベルのアップタイムと応答タイムは異なることがあります。 ジオコーディング サービスやその他のバックグラウンド タスクは、数分間使用不能になることがあります。 ただし、アプリケーションは正常なままのことがあります。
監視用と一般アクセス用に同じエンドポイントを使うかどうかを決定します。 両方に同じエンドポイントを使うことはできますが、正常性確認チェック専用のパスを設計してください。 たとえば、一般アクセス エンドポイントに /health を使用できます。 この方法の場合、監視ツールはアプリケーションで一部の機能テストを実行できます。 たとえば、新しいユーザーの登録、サインイン、テスト発注などです。 同時に、一般アクセス エンドポイントが使用可能であることも確認できます。
監視要求に応じてサービス内で収集する情報の種類を決定します。 この情報を返す方法も決定する必要があります。 ほとんどの既存のツールとフレームワークでは、エンドポイントから返された HTTP 状態コードしか表示されません。 その他の情報が返されて確認できるようにするには、カスタム監視ユーティリティまたはサービスの作成が必要な場合があります。
収集する情報の量を把握します。 チェック中に過剰な処理を実行すると、アプリケーションのオーバーロードが発生し、他のユーザーに影響が及ぶ可能性があります。 また、処理時間が監視システムのタイムアウトを超える可能性もあります。 その結果、システムによってアプリケーションが使用不可とマークされる可能性があります。 ほとんどのアプリケーションには、エラー ハンドラーやパフォーマンス カウンターなどのインストルメンテーションが含まれています。 これらのツールを使ってパフォーマンスや詳細なエラー情報をログできれば、それで十分な場合があります。 正常性確認チェックから追加情報を返すのではなく、このデータを使うことを検討します。
エンドポイントの状態のキャッシュを検討します。 正常性チェックを頻繁に実行すると、コストが高くなる場合があります。 たとえば、ダッシュボードを介して正常性の状態が報告される場合、ダッシュボードへの要求ごとに正常性チェックをトリガーすることは好ましくありません。 その代わり、定期的にシステム正常性をチェックし、状態をキャッシュします。 キャッシュされた状態を返すエンドポイントを公開します。
監視エンドポイントのセキュリティを構成する方法を計画します。 セキュリティを構成することで、次のような可能性があるパブリック アクセスからエンドポイントを保護できます。
- アプリケーションが悪意のある攻撃にさらされる。
- 機密情報が漏えいする危険がある。
- サービス拒否 (DoS) 攻撃を誘発する。
一般に、セキュリティはアプリケーション構成で構成します。 そうすると、アプリケーションを再起動することなく、簡単に設定を更新できます。 以下の手法を 1 つ以上使用することを検討してください。
認証を要求することでエンドポイントをセキュリティで保護する。 監視サービスまたはツールが認証をサポートしている場合は、要求ヘッダーに認証セキュリティ キーを使用できます。 また、要求と共に資格情報を渡すこともできます。 認証を使う場合は、正常性チェック エンドポイントにアクセスする方法を検討してください。 一例として、Azure App Service の組み込み正常性チェックは、App Service の認証および認可機能と統合されます。
不明瞭なエンドポイントまたは非表示のエンドポイントを使用する。 たとえば、既定のアプリケーション URL が使う IP アドレスとは異なる IP アドレスでエンドポイントを公開します。 標準ではない HTTP ポートでエンドポイントを構成します。 また、テスト ページに複雑なパスを使うことも検討します。 通常、アプリケーションの構成で追加のエンドポイント アドレスとポートを指定できます。 必要に応じて、DNS サーバーにこれらのエンドポイントのエントリを追加できます。 そうすると、IP アドレスを直接指定する必要がなくなります。
キー値や操作モード値などのパラメーターを受け入れるメソッドをエンドポイントで公開する。 要求を受信したら、コードを使って、パラメーターの値に依存する特定のテストを実行できます。 パラメーター値を認識できない場合、コードから 404 (見つかりません) エラーが返されることがあります。 アプリケーション構成でパラメーター値を定義できるようにします。
アプリケーションの動作を損なうことなく、基本的な機能テストを実行する別のエンドポイントを使います。 この方法で、DoS 攻撃の影響を軽減できます。 機密情報の漏洩につながる可能性のあるテストの使用は避けるのが理想的です。 状況によっては、攻撃者にとって役立つ可能性がある情報を返す必要があります。 この場合、不正アクセスからエンドポイントとデータを保護する方法を検討します。 あいまいさに頼るだけでは十分ではありません。 HTTPS 接続を使い、機密データを暗号化することも検討します。ただし、この方法ではサーバーの負荷が増えます。
監視エージェントが正しく実行されるようにする方法を決定します。 1 つの手法として、アプリケーション構成からの値、またはエージェントのテストに使用できるランダムな値を返すエンドポイントを公開します。 また、監視システムが単体でチェックを実行できるようにします。 自己テストまたは組み込みテストを使って、監視システムが擬陽性の結果を出さないようにすることができます。
このパターンを使用する状況
このパターンは次の目的に役立ちます。
- Web サイトと Web アプリケーションを監視して可用性を確認する。
- Web サイトと Web アプリケーションを監視して動作の正常性をチェックする。
- 中間層または共有のサービスを監視し、他のアプリケーションを中断させる可能性があるエラーを検出して分離する。
- アプリケーションの既存のインストルメンテーション (パフォーマンス カウンターやエラー ハンドラーなど) を補完する。 正常性確認チェックは、ログと監査に関するアプリケーションの要件に代わるものではありません。 インストルメンテーションからは、エラーやその他の問題を検出するためにカウンターとエラー ログを監視する既存のフレームワークに関して、有益な情報を提供できます。 ただし、アプリケーションが使用不能になると、インストルメンテーションでは情報を提供できません。
ワークロード設計
設計者は、Azure Well-Architected Framework の柱で説明されている目標と原則に対処するために、ワークロードの設計でどのように正常性エンドポイントの監視パターンを使用できるかを評価する必要があります。 次に例を示します。
| 重要な要素 | このパターンが柱の目標をサポートする方法 |
|---|---|
| 信頼性 設計の決定により、ワークロードが 誤動作 に対して復元力を持ち、障害発生後も完全に機能する状態に 回復 することができます。 | これらのエンドポイントは、ワークロードの信頼性アラートとダッシュボードの処理をサポートします。 また、自己復旧の修復を行うためのシグナルとしても使用できます。 - RE:07 自己復旧と自己保存 - RE:10 監視とアラートの戦略 |
| オペレーショナルエクセレンス は、標準化されたプロセスとチームの結束によってワークロードの品質を提供します。 | 公開する正常性エンドポイントと結果の詳細レベルをワークロード全体で標準化すると、問題のトリアージに役立ちます。 - OE:07 監視システム |
| パフォーマンスの効率化 は、スケーリング、データ、コードを最適化することによって、ワークロードが 効率的にニーズを満たす のに役立ちます。 | 正常性エンドポイントは、正常と確認されたノードのみにトラフィックをルーティングすることで負荷分散ロジックを強化します。 追加構成により、使用可能なノード容量に関するメトリックを取得することもできます。 - PE:05 スケーリングとパーティショニング |
設計決定と同様に、このパターンで導入される可能性のある他の柱の目標とのトレードオフを考慮してください。
例
ASP.NET 正常性チェック ミドルウェアとライブラリを使って、アプリのインフラストラクチャ コンポーネントの正常性を報告できます。 このフレームワークには、一貫した方法で正常性チェックを報告する方法が用意されています。 この記事で説明するプラクティスの多くが実装されています。 たとえば、ASP.NET の正常性チェックには、データベース接続のような外部チェックや、ライブネスや準備状況のプローブのような特定の概念が含まれます。
ASP.NET 正常性チェックを使ういくつかの実装例が GitHub で公開されています。
Azure でホストされているアプリケーションのエンドポイントを監視する
Azure アプリケーションのエンドポイントの監視には、次のようなオプションがあります。
- Azure Monitor などの Azure の組み込み監視機能を使う。
- サードパーティのサービスまたはフレームワークを使う (Microsoft System Center Operations Manager など)。
- 所有するサーバーまたはホステッド サーバーで実行されるカスタム ユーティリティまたはサービスを作成する。
Azure には、包括的な監視オプションが用意されていますが、さらに情報を得るために、その他のサービスとツールを使用できます。 Monitor の機能である Application Insights は、開発チーム向けに設計されています。 この機能は、アプリのパフォーマンスとその使用方法を理解するのに役立ちます。 Application Insights は、要求率、応答時間、失敗率、依存率を監視します。 これは、外部サービスによって速度が低下しているかどうかを判断するのに役立ちます。
監視できる条件は、アプリケーションに選んだホスティング メカニズムによって変わります。 このセクションのすべてのオプションは、警告ルールをサポートしています。 警告ルールは、サービスの設定で指定した Web エンドポイントを使います。 アプリケーションが正常に動作していることをアラート システムが検出できるように、このエンドポイントは迅速に応答する必要があります。 詳細については、「新しいアラート ルールを作成する」を参照してください。
大規模な停止が発生した場合、クライアント トラフィックは、他のリージョンまたはゾーンで使用可能なアプリケーション デプロイにルーティングできる必要があります。 この状況は、クロスプレミス接続とグローバル負荷分散に適したケースです。 どちらを選ぶかは、アプリケーションがインターネットまたは外部に接続するかどうかに応じて決まります。 Azure Front Door、Azure Traffic Manager、コンテンツ配信ネットワークなどのサービスは、正常性プローブから提供されたデータに基づいて、トラフィックをリージョン間でルーティングできます。
Traffic Manager はルーティングと負荷分散のサービスです。 さまざまな規則と設定を使って、アプリケーションの特定のインスタンスに要求を分散できます。 Traffic Manager を使うと、要求をルーティングするだけでなく、URL、ポート、相対パスに対して定期的に ping を送信できます。 アプリケーションのどのインスタンスがアクティブであり、要求に応答しているかを判断することを目標にして、ping のターゲットを指定します。 Traffic Manager で 200 (OK) の状態コードが検出された場合、アプリケーションは使用可能とマークされます。 他のいずれかの状態コードの場合は、アプリケーションはオフラインとしてマークされます。 Traffic Manager コンソールには、各アプリケーションの状態が表示されます。 各規則を構成して、応答しているアプリケーションの他のインスタンスに要求のルートを変更できます。
Traffic Manager は、監視対象の URL からの応答を受け取るために特定の時間を待機します。 正常性確認コードがこの時間内に実行されるようにします。 Traffic Manager からアプリケーションへのラウンド トリップにかかるネットワーク待機時間を考慮します。
次の手順
このパターンの実装には、次のガイダンスが役に立ちます。
- マイクロサービスベース アプリケーションの稼働状況の監視ガイダンス
- 信頼性に対するアプリケーションの正常性を監視する (Azure Well-Architected フレームワークの一部)
- 新しいアラート ルールを作成する
関連リソース
- 外部構成ストア パターン
- サーキット ブレーカー パターン
- Gateway Routing pattern (ゲートウェイ ルーティング パターン)
- ゲートキーパー パターン