複数のタスクまたは操作を 1 つのコンピューティング単位に統合します。 これにより、コンピューティング リソースの使用率を高め、クラウドでホストされるアプリケーションでコンピューティング処理を実行することに関連するコストと管理オーバーヘッドを削減できます。
コンテキストと問題
多くの場合、クラウド アプリケーションはさまざまな操作を実装しています。 一部のソリューションでは、最初に問題分離の設計原則に従い、これらの操作を、独立してホストされ、デプロイされる別個のコンピューティング単位 (別個の App Service Web アプリまたは別個の仮想マシンなど) に分割するのが理にかなっています。 ただしこの戦略は、ソリューションの論理設計を簡略化する助けにはなりますが、多数のコンピューティング単位を同じアプリケーションの一部としてデプロイすることで、実行時のホストのコストが増加し、システムの管理がより複雑になる可能性があります。
例として、図に、複数のコンピューティング単位を使用して実装された、クラウドでホストされるソリューションの簡略化された構造を示します。 各コンピューティング単位は、独自の仮想環境で実行されます。 各機能は、独自のコンピューティング単位で実行される別個のタスク (タスク A からタスク E までラベル付けされてます) として実装されています。
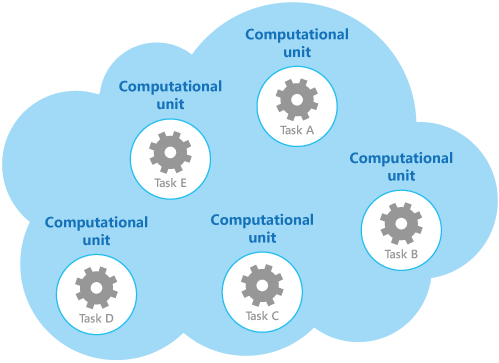
各コンピューティング単位は、アイドル状態や軽い負荷で使用されているときでも課金対象のリソースを消費します。 そのため、これが常に最もコスト効果の高いソリューションであるとは限りません。
Azure では、この問題は App Services、Container Apps、および仮想マシンに当てはまります。 これらの項目は、独自の環境で実行されます。 適切に定義された操作のセットを実行するために設計されていても、単一ソリューションの一部として通信し、連携する必要がある別個の Web サイト、マイクロサービス、または仮想マシンのコレクションを実行すると、リソースを非効率的に使用することになる可能性があります。
解決策
コストの削減、使用率の向上、通信速度の向上、および管理の削減に役立つように、複数のタスクや操作を 1 つのコンピューティング単位に統合することが可能です。
タスクは、環境によって提供される機能と、それらの機能に関連するコストに基づく条件に従ってグループ化できます。 よく使われるのは、スケーラビリティ、有効期間、および処理の要件に関するプロファイルが類似しているタスクを探す方法です。 これらを一緒にグループ化すると、単位としてスケールできます。 多くのクラウド環境で提供される柔軟性により、コンピューティング単位の追加インスタンスをワークロードに従って開始および停止できます。 たとえば Azure には、App Services および Virtual Machine Scale Sets に適用できる自動スケールが用意されています。 詳細については、「自動スケールのガイダンス」を参照してください。
どの操作を一緒にグループ化してはいけないかを確認するため、スケーラビリティをどう使用できるかを示す逆の例として、次の 2 つのタスクについて考えてみてください。
- タスク 1 では、低い頻度でキューに送信される、時間的区別がないメッセージをポーリングします。
- タスク 2 では、急増する大量のネットワーク トラフィックを処理します。
2 番目のタスクでは、コンピューティング単位の多数のインスタンスの開始と停止を伴うことがある弾力性が求められます。 同じスケールを最初のタスクに適用すると、同じキューで頻度が低いメッセージをリッスンするタスクが増える結果となるだけで、それはリソースの無駄です。
多くのクラウド環境では、CPU コアの数、メモリ、ディスク領域などの点で、コンピューティング単位が使用できるリソースを指定することが可能です。 一般に、多くのリソースを指定するだけコストが増加します。 コストを節約するには、高価なコンピューティング単位が実行する作業を最大化し、長期間にわたってコンピューティング単位が非アクティブにならないようにすることが重要です。
短時間に CPU パワーを大量に必要とする複数のタスクがある場合、それらのタスクを、必要なパワーを提供する 1 つのコンピューティング単位に統合することを検討してください。 ただし、高価なリソースをビジー状態に維持する必要性と、リソースに負荷が掛りすぎた場合に発生する可能性がある競合とのバランスを取ることが重要です。 たとえば、実行時間が長く、多くのコンピューティング処理を要するタスクで同じコンピューティング単位を共有しないでください。
問題と注意事項
このパターンを実装するときには、以下の点を考慮に入れてください。
スケーラビリティと弾力性。 多くのクラウド ソリューションでは、単位のインスタンスを開始および停止することで、コンピューティング単位のレベルでスケーラビリティと弾力性を実装しています。 スケーラビリティの要件が競合するタスクを、同じコンピューティング単位内にグループ化することは避けてください。
有効期間。 クラウド インフラストラクチャは、コンピューティング単位をホストする仮想環境を定期的にリサイクルします。 コンピューティング単位内に実行時間の長いタスクが多数あるときには、これらのタスクが完了するまで単位が再利用されないように単位を構成することが必要な場合があります。 または、チェックポイント型のアプローチを使用してタスクを設計します。これは、タスクを正常に停止し、コンピューティング単位が再開されたときにタスクの中断点から続行できるようにするアプローチです。
リリースの周期。 タスクの実装や構成が頻繁に変更される場合、更新されたコードをホストしているコンピューティング単位を停止し、単位の再構成と再デプロイをしてから、単位を再開する必要が生じることがあります。 このプロセスでは、同じコンピューティング単位内の他のタスクをすべて停止、再デプロイ、および再開することも必要になります。
セキュリティ。 同じコンピューティング単位内のタスクは、同じセキュリティ コンテキストを共有していて、同じリソースにアクセスできる可能性があります。 タスク間には高いレベルの信頼性があり、1 つのタスクが壊れたり他方に悪影響を及ぼしたりしないという確実性が存在する必要があります。 さらに、コンピューティング単位内で実行されるタスクの数を増やすことで、単位の攻撃対象領域が拡大します。 各タスクは、最も脆弱性が多いタスクと同じだけ安全です。
フォールト トレランス。 1 つのコンピューティング単位が失敗したり異常動作を起こしたりした場合、同じ単位内で実行中の他のタスクに影響する可能性があります。 たとえば、1 つのタスクが正常に起動できなかった場合、そのコンピューティング単位のスタートアップ ロジック全体の失敗が発生し、同じ単位内の他のタスクが実行されない可能性があります。
競合。 同じコンピューティング単位内のリソースに対して競合する、タスク間の競合が引き起こされないようにしてください。 理想的には、同じコンピューティング単位を共有するタスクは、異なるリソース使用率の特性を示す必要があります。 たとえば、多くのコンピューティング処理を要するタスクが 2 つある場合、それらはおそらく同じコンピューティング単位内にあってはならず、2 つのタスクはどちらも大量のメモリを消費してはいけません。 ただし、多くのコンピューティング処理を要するタスクと、大量のメモリを必要とするタスクは、混在を実現できる組み合わせです。
注意
オペレーターや開発者がシステムを監視し、各タスクが異なるリソースをどのように使用しているかを識別するヒート マップを作成できるように、一定期間にわたって運用環境にあったシステムだけのためにコンピューティング リソースを統合することを検討してください。 このマップを使用して、どのタスクがコンピューティング リソースを共有するのに適した候補であるかを特定できます。
複雑さ。 複数のタスクを 1 つのコンピューティング単位に組み合わせると、単位のコードの複雑さを高めることになり、テスト、デバッグ、および管理がより難しくなる可能性があります。
安定した論理アーキテクチャ。 タスクが実行される物理環境が実際に変わった場合でもコードの変更が必要にならないように、各タスクのコードを設計して実装します。
その他の戦略。 コンピューティング リソースの統合は、複数のタスクを同時に実行することに関連するコストの削減に役立つ方法の 1 つにすぎません。 それが効果的なアプローチであり続けるようにするには、慎重な計画と監視が必要です。 作業の性質や、これらのタスクを実行しているユーザーの所在地によっては、他の戦略がより適切な場合もあります。 たとえば (「計算分割ガイダンス」で説明されている) ワークロードの機能的分解が、より適したオプションとなる場合があります。
このパターンを使用する状況
このパターンは、独自のコンピューティング単位で実行されるとコスト効果が高くないタスクに使用してください。 タスクがその時間の多くをアイドル状態で費やしている場合、このタスクを専用の単位で実行するのはコスト高の可能性があります。
このパターンは、重要なフォールト トレランス操作を実行するタスクや、機密性の高いデータまたはプライベート データを処理し、独自のセキュリティ コンテキストを必要とするタスクには適さない場合があります。 これらのタスクは、別個のコンピューティング単位で、独自の分離された環境において実行する必要があります。
ワークロード設計
設計者は、Azure Well-Architected Framework の柱で説明されている目標と原則に対処するために、コンピューティングリソース統合パターンをワークロードの設計でどのように使用できるかを評価する必要があります。 次に例を示します。
| 重要な要素 | このパターンが柱の目標をサポートする方法 |
|---|---|
| コスト最適化は、ワークロードの投資収益率の維持と改善に重点を置いています。 | このパターンは、プールされたインフラストラクチャ上のコンポーネントまたはワークロード全体を集約することによって、使用されていないプロビジョニングされた容量を回避することで、コンピューティングリソースの使用率を最大限に高めます。 - CO: 14 統合 |
| オペレーショナルエクセレンス は、標準化されたプロセスとチームの結束によってワークロードの品質を提供します。 | 統合によって、より均質なコンピューティングプラットフォームが実現する可能性があります。これにより、管理と監視のシンプル化、運用タスクへの異なるアプローチの削減、および必要なツールの使用量を削減できます。 - OE:07 監視システム - OE:10 自動化設計 |
| パフォーマンスの効率化は、スケーリング、データ、コードを最適化することによって、ワークロードが効率的にニーズを満たすのに役立ちます。 | 統合により、スペアノード容量を使用し、過剰なプロビジョニングの必要性を軽減することで、コンピューティングリソースの利用率が最大化されます。 これらのインフラストラクチャのリソースプールでは、大規模な(垂直的に拡張された)コンピューティングインスタンスがよく使用されます。 - PE:02 容量計画 - PE:03 サービスの選択 |
設計決定と同様に、このパターンで導入される可能性のある他の柱の目標とのトレードオフを考慮してください。
アプリケーション プラットフォームの選択
このパターンは、使用するコンピューティング サービスに応じて、さまざまな方法で実現できます。 次のサービスの例を参照してください。
- Azure App Service と Azure Functions: ホスティング サーバー インフラストラクチャを表す共有 App Service プランをデプロイします。 1 つまたは複数のアプリを同じコンピューティング リソース (または、同じ App Service プラン) で実行するように構成することができます。
- Azure Container Apps: 同じ共有環境にコンテナー アプリをデプロイします。特に、関連するサービスを管理する必要がある場合や、異なるアプリケーションを同じ仮想ネットワークにデプロイする必要がある場合です。
- Azure Kubernetes Service (AKS): AKS は、コンテナーベースのホスティング インフラストラクチャーであり、複数のアプリケーションまたはアプリケーション コンポーネントを同じコンピューティングリ ソース (ノード) に併置して実行するように構成でき、CPU やメモリのニーズ (ノード プール) などの計算要件によってグループ化されます。
- 仮想マシン: すべてのテナントで使用する仮想マシンの 1 つのセットをデプロイします。これにより、管理コストがテナント間で共有されます。 Virtual Machine Scale Sets は、仮想マシンの共有リソース管理、負荷分散、水平スケーリングをサポートする機能です。
関連リソース
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
自動スケール ガイダンス。 処理で予想される需要に応じて、コンピューティング リソースをホストしているサービスのインスタンスを開始および停止するために、自動スケールを使用できます。
計算分割ガイダンス。 サービスのスケーラビリティ、パフォーマンス、可用性、およびセキュリティを維持しながら実行コストを最小限に抑える 1 つの方法として、クラウド サービスのサービスとコンポーネントを割り当てる方法について説明します。
マルチテナント ソリューションでのコンピューティングのアーキテクチャに関するアプローチ。 ソリューション アーキテクトがマルチテナント ソリューションのコンピューティング サービスについて計画している場合に重要となる、考慮事項と要件に関するガイダンスを示します。