この記事では、Azure スポット仮想マシン (VM) 上に構築するためのベスト プラクティスについて説明し、デプロイ可能なシナリオ例を示します。 スポット VM は、通常の VM に対して大幅な割引でコンピューティング容量へのアクセスを提供します。 この割引により、コストを最適化しようとしている組織にとって魅力的なソリューションになりますが、コスト削減には条件が伴います。 スポット VM は、いつでもコンピューティングへのアクセスを失う可能性があります。 このプロセスを削除と呼びます。 スポット VM 上で実行されているワークロードは、コンピューティングでこれらの中断を処理できる必要があります。 適切なワークロードと柔軟なオーケストレーション メカニズムが、成功の鍵となります。 スポット VM 上での構築に関する推奨事項を次に示します。
スポット仮想マシンについて
技術的なレベルでは、スポット VM は通常の VM と同じです。 同じパフォーマンスに変換される同じイメージ、ハードウェア、ディスクを使用します。 スポット VM と通常の VM の違いは、優先順位と可用性に低下します。 スポット VM はコンピューティング容量にアクセスする優先順位がなく、そのコンピューティング容量にアクセスした後の可用性の保証もありません。 優先順位と可用性について詳しく説明しましょう。
優先度アクセスなし。 通常の VM には、コンピューティング容量への優先アクセス権があります。 要求するたびにコンピューティング容量にアクセスします。 一方、スポット VM は、予備のコンピューティング容量がある場合にのみデプロイし、通常の VM が基になるハードウェアを必要としない場合にのみ実行を維持します。
可用性の保証はありません。 スポット VM には可用性の保証はありません。 サービス レベル アグリーメント (SLA) はありません。 スポット VM は、デプロイ (削除) の直後または後の任意の時点で、コンピューティング容量へのアクセスを失う可能性があります。 スポット VM は削除の可能性があるため、コストが安くなります。 Azure でコンピューティング容量が戻る必要がある場合は常に、削除通知が送信され、スポット VM が削除されます。 Azure では、実際の削除が行われる前に、少なくとも 30 秒前の通知が提供されます。 詳細については、この記事の削除を継続的に監視するを参照してください。
スポット仮想マシンの価格について
スポット VM は、通常の (従量課金制) VM よりも最大 90% 安くなる可能性があります。 割引は、需要、VM サイズ、デプロイのリージョン、オペレーティング システムによって異なります。 コスト削減の見積もりを取得するには、Azure Spot VM 価格ツールを使用することをお勧めします。 詳細については、以下を参照してください。
- Azure スポット VM 価格ツールの を
する - スポット VM の価格の概要 の
また、Azure 小売価格 API に対してクエリを実行して、関心のある SKU のスポット価格をプログラムで取得することもできます。
中断可能なワークロードを理解する
割り込み可能なワークロードは、スポット VM に最適なユース ケースです。 割り込み可能なワークロードには、いくつかの一般的な特性があります。 時間の制約が最小限から無く、組織の優先順位が低く、処理時間が短い。 組織の重要なプロセスに損害を与えることなく、突然停止して後で再開できるプロセスを実行します。 中断可能なワークロードの例としては、非運用環境用の継続的インテグレーションの継続的デプロイ エージェントを作成するバッチ処理アプリケーション、データ分析、ワークロードがあります。 これらの機能は、サービス レベル アグリーメント (SLA)、スティッキー セッション、ステートフル データを持つ通常またはミッション クリティカルなワークロードとは対照的です。 この表では、両方のワークロードの種類の例を示します。
| 割り込み可能なワークロード機能 | 通常のワークロード機能 | |
|---|---|---|
| 機能の | 最小から無時間の制約 組織の優先順位が低い 短い処理時間 |
サービス レベル アグリーメント (SLA) スティッキー セッションの要件 ステートフル ワークロード |
中断できないワークロードではスポット VM を使用できますが、コンピューティング容量の単一ソースにすることはできません。 アップタイム要件を満たすために必要な数の通常の VM を使用します。
削除について
スポット VM は、作成後にサービス レベル アグリーメント (SLA) を持たなくなり、いつでもコンピューティングにアクセスできなくなる可能性があります。 このコンピューティング損失を削除と呼びます。 コンピューティングの供給と需要によって、立ち退きが促進されます。 特定の VM サイズの需要が一定のレベルを超えると、Azure はスポット VM を削除して、通常の VM でコンピューティングを使用できるようにします。 需要は場所固有です。 リージョン A の需要の増加は、リージョン B のスポット VM には影響しません。
スポット VM には、削除に影響する 2 つの構成オプションがあります。 これらの構成は、スポット VM の "削除の種類" と "削除ポリシー" です。 これらの構成は、スポット VM を作成するときに設定します。 "削除の種類" は、削除の条件を定義します。 "削除ポリシー" によって、スポット VM に対する削除の動作が決まります。 両方の構成の選択肢に対処しましょう。
削除の種類
容量の変更または価格の変更により、削除が発生します。 容量と価格の変更がスポット VM に与える影響は、VM の作成時に選択された削除の種類によって異なります。 削除の種類は、削除の条件を定義します。 削除の種類は、"容量のみの削除" と "価格または容量の削除" です。
容量の削除のみ: この削除の種類では、過剰なコンピューティング容量がなくなったときに削除がトリガーされます。 既定では、価格は従量課金制の料金で制限されます。 従量課金制 VM の価格まで支払う場合は、この削除の種類を使用します。
価格または容量の削除: この削除の種類には、2 つのトリガーがあります。 過剰なコンピューティング容量が消えるか、VM のコストが設定した最大価格を超えると、Azure によってスポット VM が削除されます。 この削除タイプでは、従量課金制の価格を大幅に下回る最大価格を設定できます。 この削除の種類を使用して、独自の価格上限を設定します。
削除ポリシー
スポット VM に対して選択された削除ポリシーは、そのオーケストレーションに影響します。 オーケストレーションとは、削除を処理するプロセスを意味します。 オーケストレーションについては後で詳しく説明します。 削除ポリシーは、"停止/割り当て解除ポリシー" と "ポリシーの削除" です。
停止/割り当て解除ポリシー: 停止/割り当て解除ポリシーは、ワークロードが同じ場所と VM の種類内のリリース容量を待機できる場合に最適です。 停止/割り当て解除ポリシーは、VM を停止し、基になるハードウェアでリースを終了します。 スポット VM の停止と割り当ての解除は、通常の VM の停止と割り当ての解除と同じです。 VM は Azure で引き続きアクセスでき、後で同じ VM を再起動できます。 停止/割り当て解除ポリシーを使用すると、VM はコンピューティング容量と非静的 IP アドレスを失います。 ただし、VM データ ディスクは残り、料金が発生します。 VM は、サブスクリプション内のコアも占有します。 停止または割り当て解除された場合でも、VM をリージョンまたはゾーンから移動することはできません。 詳細については、VM の電源状態と課金
削除ポリシー: ワークロードで場所または VM のサイズを変更できる場合は、"ポリシーの削除" を使用します。 場所や VM のサイズを変更することで、VM の再デプロイを高速化できます。 削除ポリシーは、VM と任意のデータ ディスクを削除します。 VM はサブスクリプションのコアを占有しません。 削除ポリシーの詳細については、削除ポリシーの
柔軟なオーケストレーションのための設計
オーケストレーションは、削除後にスポット VM を置き換えるプロセスです。 これは、確実に中断可能なワークロードを構築するための基盤です。 優れたオーケストレーション システムには柔軟性が組み込まれています。 柔軟性により、ワークロードの信頼性と速度を向上させるために、オプションを用意し、複数の VM サイズを使用し、異なるリージョンにデプロイし、削除に対応し、さまざまな削除シナリオを考慮するようにオーケストレーションを設計することを意味します。
速度の設計
スポット VM で実行されているワークロードの場合、コンピューティング容量は宝です。 削除の可能性が差し迫っている場合は、割り当てられたコンピューティング時間に対する感謝の気持ちを高め、ワークロードの速度を優先する意味のある設計上の決定に変換する必要があります。 一般に、コンピューティング時間を最適化する必要があります。 必要なすべてのソフトウェアがプレインストールされた VM イメージを構築する必要があります。 プレインストールされたソフトウェアは、削除から完全に実行されているアプリケーションまでの時間を最小限に抑えるのに役立ちます。 ワークロードの目的に寄与しないプロセスでコンピューティング時間を使用しないようにする必要があります。 たとえば、データ分析のワークロードでは、ほとんどのコンピューティング時間をデータ処理に集中し、削除メタデータの収集にできるだけ集中する必要があります。 アプリケーションから不要なプロセスを排除します。
複数の VM のサイズと場所を使用する
柔軟性を高めるために、複数の VM の種類とサイズを使用するオーケストレーションを構築することをお勧めします。 目標は、削除された VM を置き換えるオーケストレーション オプションを提供することです。 Azure には、同じ価格で同様の機能を提供するさまざまな VM の種類とサイズがあります。 VM の最小 vCPU/コア数や最小 RAM、および/または最小価格をフィルター処理して、ワークロードを実行し、予算内に収まる能力を持つ複数の VM を見つける必要があります。
各 VM の種類には、パーセンテージ範囲 (0 から 5%、5 から 10%、10 から 15%、15 から 20%、20+%) で表される削除レートがあります。 削除率はリージョンによって異なる場合があります。 異なるリージョンの同じ VM の種類に対して、より優れた削除率が見つかる場合があります。 ポータルの [基本] タブで、各 VM の種類の削除率を確認できます。[サイズ] リンク ([価格履歴の表示] または [すべてのサイズを表示] ) を選択します。 Azure Resource Graph を使用して、プログラムでスポット VM データを取得することもできます。
さらに、機能スポット配置スコアを使用して、オーケストレーション システムの一部として個々のスポットデプロイが成功する可能性を評価することを検討してください。 詳細については、以下を参照してください。
- 立ち退き率
- Azure Resource Graph の
- スポット配置スコア (プレビュー)
最も柔軟な削除ポリシーを使用する
削除されたスポット VM の削除ポリシーは、置換プロセスに影響します。 削除削除ポリシーは、停止/割り当て解除された削除ポリシーよりも柔軟です。
最初に削除ポリシーを検討: ワークロードで削除を処理できる場合は、削除削除ポリシーを使用することをお勧めします。 削除により、オーケストレーションは代替スポット VM を新しいゾーンとリージョンにデプロイできます。 このデプロイの柔軟性は、ワークロードが停止または割り当て解除された VM よりも高速に予備のコンピューティング容量を見つけるのに役立ちます。 停止/割り当て解除された VM は、作成されたのと同じゾーンで予備のコンピューティング容量を待機する必要があります。 削除ポリシーの場合、アプリケーションの外部にある削除を監視し、異なるリージョンや異なる VM SKU へのデプロイを調整するプロセスが必要です。
停止/割り当て解除ポリシーのを理解する: 停止/割り当て解除されたポリシーは、削除ポリシーよりも柔軟性が低くなります。 スポット VM は、同じリージョンとゾーンに留まる必要があります。 停止または割り当て解除された VM を別の場所に移動することはできません。 VM には固定の場所があるため、コンピューティング容量が使用可能になったときに VM を再割り当てするために何かが必要です。 コンピューティング容量の可用性を予測する方法はありません。 そのため、自動スケジュール パイプラインを使用して、削除後に再デプロイを試みる必要があります。 削除によってスケジュール パイプラインがトリガーされ、再デプロイの試行では、使用可能になるまでコンピューティング容量を継続的にチェックする必要があります。
| 政策 | いつ | |
|---|---|---|
| 削除 | エフェメラル コンピューティングとデータ データ ディスクの料金を支払いたくない 最小予算 |
|
| 停止/割り当て解除 | 特定の VM サイズが必要 場所を変更できない 長いアプリケーション インストール プロセス |
無期限の待機時間 コスト削減だけでは駆動されない |
削除を継続的に監視する
監視は、スポット VM でのワークロードの信頼性の鍵です。 スポット VM は作成後に SLA を持たず、いつでも削除できます。 スポット VM でのワークロードの信頼性を向上させる最善の方法は、いつ削除されるのかを予測することです。 この情報を使用して、ワークロードの正常なシャットダウンを試み、置換を調整する自動化をトリガーできます。
スケジュールされたイベントを使用する: 各 VM に対してスケジュールされたイベント サービスを使用します。 インフラストラクチャのメンテナンスが影響を受けるときに、Azure から VM にシグナルが送信されます。 削除は、インフラストラクチャ メンテナンスの対象となります。 Azure は、削除されるまでの少なくとも 30 秒ですべての VM に Preempt シグナルを送信します。 スケジュール イベントと呼ばれるサービスを使用すると、静的でルーティング不可能な IP アドレス 169.254.169.254でエンドポイントに対してクエリを実行することで、この Preempt 信号をキャプチャできます。
頻繁なクエリを使用: スケジュール イベント エンドポイントに対してクエリを実行して、正常なシャットダウンを調整するのに十分な頻度で実行します。 スケジュールされたイベント エンドポイントは 1 秒ごとにクエリを実行できますが、すべてのユース ケースで 1 秒の頻度は必要ない場合があります。 これらのクエリは、スポット VM で実行されているアプリケーションから取得する必要があります。 クエリは外部ソースから取得できません。 その結果、クエリは VM コンピューティング容量を消費し、メイン ワークロードから処理能力を盗みます。 特定の状況を満たすために、競合する優先順位のバランスを取る必要があります。
オーケストレーションを自動化する: Preempt シグナルを収集したら、オーケストレーションはそのシグナルに基づいて動作する必要があります。 時間の制約がある場合、Preempt シグナルはワークロードの正常なシャットダウンを試み、スポット VM を置き換える自動化されたプロセスを開始する必要があります。 詳細については、以下を参照してください。
- スケジュールされたイベント を
する - スケジュールされたイベントの種類 を
する - エンドポイントのクエリ頻度
デプロイ システムを構築する
オーケストレーションには、削除されたときに新しいスポット VM をデプロイするための自動化されたパイプラインが必要です。 パイプラインは、永続性を確保するために、中断可能なワークロード自体の外部で実行する必要があります。 デプロイ パイプラインの動作方法は、スポット VM に対して選択した削除ポリシーによって異なります。
削除ポリシーの場合は、さまざまな VM サイズを使用し、異なるリージョンにデプロイするパイプラインを構築することをお勧めします。 停止/割り当て解除されたポリシーの場合、デプロイ パイプラインには 2 つの異なるアクションが必要です。 VM を最初に作成するには、パイプラインで適切なサイズの VM を適切な場所にデプロイする必要があります。 削除された VM の場合、パイプラインは動作するまで VM の再起動を試みる必要があります。 Azure Monitor アラートと Azure Functions の組み合わせは、デプロイ システムを自動化するいくつかの方法の 1 つです。 パイプラインでは bicep テンプレートを使用できます。 これらは宣言型でべき等であり、インフラストラクチャのデプロイのベスト プラクティスを表します。
即時削除の準備
作成したスポット VM とワークロードの実行前に、Azure がスポット VM を削除する可能性があります。 スポット VM を作成する容量があったからといって、それが永続化されるわけではありません。 スポット VM には、作成後の可用性保証 (SLA) はありません。 オーケストレーションでは、即時の削除を考慮する必要があります。
Preempt 信号は、削除の少なくとも30秒前の通知を提供します。
VM の正常性チェックをオーケストレーションに組み込み、即時の削除に備えます。 即時削除のオーケストレーションは、スケジュール イベント Preempt シグナルに依存できません。 VM 自体のみが Preempt シグナルに対してクエリを実行でき、アプリケーションの起動、スケジュール イベント エンドポイントのクエリ、および正常なシャットダウンに十分な時間がありません。 そのため、正常性チェックはワークロード環境の外部に存在する必要があります。 正常性チェックでは、スポット VM の状態を監視し、デプロイ パイプラインを開始して、状態が割り当て解除または停止に変わったときにスポット VM を置き換える必要があります。
複数の同時削除を計画する
スポット VM のクラスターを実行している場合は、複数の同時削除に耐えられるようにワークロードを設計する必要があります。 ワークロード内の複数のスポット VM を同時に削除できます。 複数の VM を同時に削除すると、アプリケーションのスループットに影響する可能性があります。 このような状況を回避するには、デプロイ パイプラインで複数の VM からシグナルを収集し、複数の代替 VM を同時にデプロイできる必要があります。
グレースフル シャットダウンの設計
VM のシャットダウン プロセスは 30 秒未満で、削除前に VM をシャットダウンできるようにする必要があります。 シャットダウンにかかる時間は、ワークロードがスケジュールされたイベント エンドポイントに対してクエリを実行する頻度によって異なります。 エンドポイントに対してクエリを実行する頻度が高いほど、シャットダウン プロセスが長くなる可能性があります。 シャットダウン プロセスでは、リソースを解放し、接続をドレインし、イベント ログをフラッシュする必要があります。 コンテキストを保存し、より効率的な復旧戦略を構築するには、チェックポイントを定期的に作成して保存する必要があります。 チェックポイントは、次の VM で開始する必要があるプロセスまたはトランザクションに関する情報にすぎません。 前の VM が中断した場所で VM を再開するか、新しい VM が変更をロールバックしてプロセス全体を再開する必要があるかどうかを示す必要があります。 チェックポイントは、スポット VM 環境の外部に格納する必要があります。 ストレージ アカウントは機能します。
オーケストレーションをテストする
開発/テスト環境でオーケストレーションをテストするには、削除イベントをシミュレートすることをお勧めします。 詳細については、削除
べき等ワークロードを設計する
べき等ワークロードを設計することをお勧めします。 イベントを複数回処理した結果は、1 回の処理と同じである必要があります。 削除は、正常なシャットダウンを確保する努力にもかかわらず、強制的なシャットダウンにつながる可能性があります。 強制シャットダウンでは、完了前にプロセスを終了できます。 べき等ワークロードは同じメッセージを複数回受信でき、結果は変わりません。 詳細については、べき等 を参照してください。
アプリケーションのウォームアップ期間を使用する
割り込み可能なワークロードのほとんどは、アプリケーションを実行します。 アプリケーションのインストールと起動に時間が必要です。 外部ストレージに接続し、チェックポイントから情報を収集する時間が必要です。 アプリケーションのウォームアップ期間を設定してから、処理を開始することをお勧めします。 ウォームアップ期間中、アプリケーションは起動、接続、および貢献の準備を行う必要があります。 アプリケーションの正常性を検証した後にのみ、アプリケーションでデータの処理を開始できるようにする必要があります。
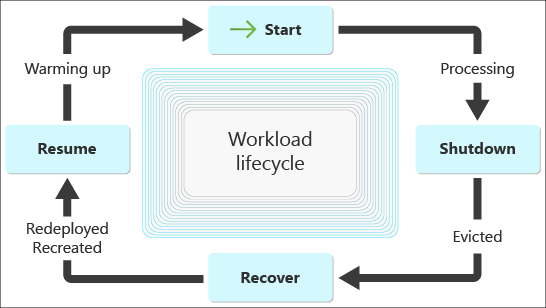 されたワークロード ライフサイクルの図
されたワークロード ライフサイクルの図
ユーザー割り当てマネージド ID の構成
ユーザー割り当てマネージド ID を使用して、認証と承認のプロセスを効率化することをお勧めします。 ユーザー割り当てマネージド ID を使用すると、コードに資格情報を入れることを回避でき、システム割り当てマネージド ID などの単一のリソースに関連付けられません。 ユーザー割り当てマネージド ID には、オーケストレーション中に VM をスポットするために再利用および割り当てることができる、Microsoft Entra ID からのアクセス許可とアクセス トークンが含まれています。 スポット VM 間のトークン整合性は、オーケストレーションとスポット VM が持つワークロード リソースへのアクセスを合理化するのに役立ちます。
システム割り当てマネージド ID では、新しいスポット VM が Microsoft Entra ID とは異なるアクセス トークンを取得する場合があります。 システム割り当てマネージド ID を使用する必要がある場合は、ワークロードに 403 Forbidden Error 応答に対する回復性を持たせることをお勧めします。 オーケストレーションでは、適切なアクセス許可を持つ Microsoft Entra ID からトークンを取得する必要があります。 詳細については、マネージド ID
シナリオの例
このシナリオ例では、中断可能なワークロードとして適格なキュー処理アプリケーションをデプロイします。 シナリオのスクリプトは例示です。 このシナリオでは、リソースをデプロイするための 1 回限りの手動プッシュについて説明します。 この実装を含むデプロイ パイプラインはありません。 ただし、調整プロセスを自動化するには、デプロイ パイプラインが不可欠です。 この図は、シナリオ例のアーキテクチャを示しています。

次のノートでは、アーキテクチャの主な側面について説明します。
- VM アプリケーション定義: VM アプリケーション定義が Azure コンピューティング ギャラリーに作成されます。 アプリケーション名、場所、オペレーティング システム、およびメタデータを定義します。 アプリケーションのバージョンは、VM アプリケーション定義の番号付きバージョンです。 アプリケーションのバージョンは、VM アプリケーションのインスタンス化です。 スポット VM と同じリージョンに存在する必要があります。 アプリケーション バージョンは、ストレージ アカウント内のソース アプリケーション パッケージにリンクされます。
-
ストレージ アカウント: ストレージ アカウントには、ソース アプリケーション パッケージが格納されます。 このアーキテクチャでは、
worker-0.1.0.tar.gzという名前の圧縮 tar ファイルです。 これには 2 つのファイルが含まれています。 1 つのファイルは、.NET worker アプリケーションをインストールするorchestrate.shbash スクリプトです。 - スポット VM : スポット VM がデプロイ。 アプリケーションのバージョンと同じリージョンに存在する必要があります。 デプロイ後に vm に
worker-0.1.0.tar.gzをダウンロードします。 bicep テンプレートは、Standard ファミリ VM に Ubuntu イメージをデプロイします。 これらの構成は、このアプリケーションのニーズを満たし、アプリケーションの一般的な推奨事項ではありません。 - ストレージ キュー:.NET worker で実行されている他のサービスには、メッセージ キュー ロジックが含まれています。 Microsoft Entra ID は、RBAC を使用して、ユーザー割り当て ID を持つストレージ キューへのスポット VM アクセスを許可します。
- .Net worker アプリケーション : orchestrate.sh スクリプトは、2 つのバックグラウンド サービスを実行する .NET worker アプリケーションをインストールします。 最初のサービスは、スケジュール イベント エンドポイントに対してクエリを実行し、
Preemptシグナルを探し、このシグナルを 2 番目のサービスに送信します。 2 番目のサービスは、ストレージ キューからのメッセージを処理し、最初のサービスからのPreemptシグナルをリッスンします。 2 番目のサービスは、シグナルを受信すると、ストレージ キューの処理を中断し、シャットダウンを開始します。 - Query Scheduled Events エンドポイント: API 要求が静的なルーティング不可能な IP アドレス 169.254.169.254 に送信されます。 API 要求は、スケジュールされたイベント エンドポイントに対してインフラストラクチャ メンテナンス シグナルのクエリを実行します。
-
Application Insights: アーキテクチャでは、学習目的でのみ Application Insights が使用されます。 これは、割り込み可能なワークロード オーケストレーションの不可欠なコンポーネントではありません。 これは、.NET worker アプリケーションからのテレメトリを検証するための方法です。 .NET worker アプリケーションは、テレメトリを Application Insights に送信します。 詳細については、.NET アプリケーションからライブ メトリック
有効にする方法に関する説明を参照してください。
このシナリオをデプロイする
次の手順
スポット仮想マシンの詳細については、「Azure スポット仮想マシンの
関連リソース
- マルチテナント ソリューションでのコスト管理と割り当てのためのアーキテクチャ アプローチ
- Azure で Windows VM を実行する
- Azure で Linux VM を実行する