ビッグ データ アーキテクチャは、従来のデータベース システムでは大きすぎるデータや複雑なデータの取り込み、処理、分析を処理するように設計されています。

ビッグ データ ソリューションには、通常、次の種類のワークロードが 1 つ以上含まれます。
- 保存中のビッグ データ ソースのバッチ処理。
- 移動中のビッグ データのリアルタイム処理。
- ビッグ データの対話型探索。
- 予測分析と機械学習。
ほとんどのビッグ データ アーキテクチャには、次のコンポーネントの一部またはすべてが含まれます。
データ ソース: すべてのビッグ データ ソリューションは、1 つ以上のデータ ソースから始まります。 例を次に示します。
- リレーショナル データベースなどのアプリケーション データ ストア。
- Web サーバー ログ ファイルなど、アプリケーションによって生成される静的ファイル。
- IoT デバイスなどのリアルタイム データ ソース。
データ ストレージ: バッチ処理操作のデータは、通常、さまざまな形式で大量の大きなファイルを保持できる分散ファイル ストアに格納されます。 この種のストアは、多くの場合、Data Lakeと呼ばれます。 このストレージを実装するためのオプションには、Azure Data Lake Store または Azure Storage の BLOB コンテナーがあります。
バッチ処理: データ セットは非常に大きいため、多くの場合、ビッグ データ ソリューションでは、実行時間の長いバッチ ジョブを使用してデータ ファイルを処理して、データをフィルター処理、集計、分析用に準備する必要があります。 通常、これらのジョブには、ソース ファイルの読み取り、処理、新しいファイルへの出力の書き込みが含まれます。 オプションには、データフローの使用、Microsoft Fabric のデータ パイプラインなどがあります。
リアルタイム メッセージ インジェスト: ソリューションにリアルタイム ソースが含まれている場合、アーキテクチャには、ストリーム処理のためにリアルタイム メッセージをキャプチャして格納する方法が含まれている必要があります。 これは、受信メッセージが処理用のフォルダーにドロップされる単純なデータ ストアである可能性があります。 ただし、多くのソリューションでは、メッセージのバッファーとして機能し、スケールアウト処理、信頼性の高い配信、およびその他のメッセージ キュー セマンティクスをサポートするために、メッセージ インジェスト ストアが必要です。 オプションには、Azure Event Hubs、Azure IoT Hubs、Kafka などがあります。
ストリーム処理: リアルタイム メッセージをキャプチャした後、ソリューションは、分析のためにデータをフィルター処理、集計、その他の方法で準備して処理する必要があります。 その後、処理されたストリーム データが出力シンクに書き込まれます。 Azure Stream Analytics は、無制限のストリームで動作する永続的に実行される SQL クエリに基づくマネージド ストリーム処理サービスを提供します。 もう 1 つのオプションは、Microsoft Fabric でリアルタイム インテリジェンスを使用することです。これにより、データの取り込み中に KQL クエリを実行できます。
分析データ ストア: 多くのビッグ データ ソリューションは、分析用にデータを準備し、分析ツールを使用してクエリできる構造化された形式で処理されたデータを提供します。 これらのクエリの処理に使用される分析データ ストアは、ほとんどの従来のビジネス インテリジェンス (BI) ソリューションや、medallion アーキテクチャ (Bronze、Silver、Gold) を備えたレイクハウスで見られるように、Kimball スタイルのリレーショナル データ ウェアハウスにすることができます。 Azure Synapse Analytics は、大規模なクラウドベースのデータ ウェアハウス用のマネージド サービスを提供します。 または、Microsoft Fabric には、それぞれ SQL と Spark を使用してクエリを実行できる、ウェアハウスと lakehouse の両方のオプションが用意されています。
分析とレポート: ほとんどのビッグ データ ソリューションの目的は、分析とレポートを通じてデータに関する分析情報を提供することです。 ユーザーがデータを分析できるようにするために、アーキテクチャには、多次元 OLAP キューブや Azure Analysis Services の表形式データ モデルなどのデータ モデリング レイヤーが含まれる場合があります。 また、Microsoft Power BI または Microsoft Excel のモデリングと視覚化テクノロジを使用して、セルフサービス BI をサポートする場合もあります。 分析とレポートは、データ サイエンティストやデータ アナリストによる対話型データ探索の形式を取ることもできます。 これらのシナリオでは、ユーザーが SQL または選択したプログラミング言語を選択できるノートブックなどのツールが Microsoft Fabric に用意されています。
オーケストレーション: ほとんどのビッグ データ ソリューションは、ワークフローにカプセル化された繰り返しデータ処理操作で構成され、ソース データの変換、複数のソースとシンク間でのデータの移動、処理されたデータの分析データ ストアへの読み込み、または結果をレポートまたはダッシュボードに直接プッシュします。 これらのワークフローを自動化するには、Azure Data Factory や Microsoft Fabric パイプラインなどのオーケストレーション テクノロジを使用できます。
Azure には、ビッグ データ アーキテクチャで使用できる多くのサービスが含まれています。 大まかに次の 2 つのカテゴリに分類されます。
- Microsoft Fabric、Azure Data Lake Store、Azure Synapse Analytics、Azure Stream Analytics、Azure Event Hubs、Azure IoT Hub、Azure Data Factory などのマネージド サービス。
- HDFS、HBase、Hive、Spark、Kafka など、Apache Hadoop プラットフォームに基づくオープン ソース テクノロジ。 これらのテクノロジは、Azure HDInsight サービスの Azure で利用できます。
これらのオプションは相互に排他的ではなく、多くのソリューションでオープン ソース テクノロジと Azure サービスが組み合わせられています。
このアーキテクチャを使用する場合
次の必要がある場合は、このアーキテクチャ スタイルを検討してください。
- 従来のデータベースでは大きすぎるボリュームにデータを格納して処理します。
- 分析とレポートのために非構造化データを変換します。
- 無制限のデータ ストリームをリアルタイムで、または低待機時間でキャプチャ、処理、分析します。
- Azure Machine Learning または Azure Cognitive Services を使用します。
利点
- テクノロジの選択肢。 HDInsight クラスターで Azure マネージド サービスと Apache テクノロジを組み合わせて、既存のスキルやテクノロジへの投資を活用できます。
- 並列処理によるパフォーマンスの
。 ビッグ データ ソリューションは並列処理を利用し、大量のデータにスケーリングする高パフォーマンス ソリューションを実現します。 - エラスティック スケールを
します。 ビッグ データ アーキテクチャのすべてのコンポーネントはスケールアウト プロビジョニングをサポートしているため、ソリューションを小規模または大規模なワークロードに調整し、使用するリソースに対してのみ支払うことができます。 - 既存のソリューションとの相互運用性。 ビッグ データ アーキテクチャのコンポーネントは、IoT 処理とエンタープライズ BI ソリューションにも使用されるため、データ ワークロード間で統合ソリューションを作成できます。
課題
- 複雑さの。 ビッグ データ ソリューションは非常に複雑で、複数のデータ ソースからのデータ インジェストを処理する多数のコンポーネントがあります。 ビッグ データ プロセスの構築、テスト、トラブルシューティングは困難な場合があります。 さらに、パフォーマンスを最適化するために使用する必要がある複数のシステム間で多数の構成設定が存在する可能性があります。
- スキルセット. 多くのビッグ データ テクノロジは高度に特殊化されており、より一般的なアプリケーション アーキテクチャでは一般的ではないフレームワークと言語を使用しています。 一方、ビッグ データ テクノロジは、より確立された言語を基盤とする新しい API を進化させています。
- テクノロジの成熟度。 ビッグ データで使用されるテクノロジの多くは進化しています。 Hive や Spark などの主要な Hadoop テクノロジは安定していますが、デルタや氷山などの新しいテクノロジでは、広範な変更と機能強化が導入されています。 Microsoft Fabric などのマネージド サービスは、他の Azure サービスと比較して比較的若く、時間の経過と共に進化する可能性があります。
- セキュリティ。 ビッグ データ ソリューションは、通常、すべての静的データを一元化されたデータ レイクに格納することに依存します。 このデータへのアクセスのセキュリティ保護は、特に複数のアプリケーションとプラットフォームでデータを取り込んで使用する必要がある場合に困難になる場合があります。
ベスト プラクティス
並列処理を活用します。 ほとんどのビッグ データ処理テクノロジは、複数の処理ユニットにワークロードを分散します。 これには、静的データ ファイルが作成され、分割可能な形式で格納されている必要があります。 HDFS などの分散ファイル システムでは、読み取りと書き込みのパフォーマンスを最適化でき、実際の処理は複数のクラスター ノードによって並列に実行されるため、全体的なジョブ時間が短縮されます。 Parquet など、分割可能なデータ形式を使用することを強くお勧めします。
データをパーティション分割します。 バッチ処理は通常、定期的なスケジュール (週単位や月単位など) で行われます。 処理スケジュールに一致する一時的な期間に基づいて、データ ファイルとテーブルなどのデータ構造をパーティション分割します。 これにより、データ インジェストとジョブのスケジュールが簡素化され、エラーのトラブルシューティングが容易になります。 また、Hive、Spark、または SQL クエリで使用されるテーブルをパーティション分割すると、クエリのパフォーマンスが大幅に向上する可能性があります。
読み取り時のスキーマ セマンティクスを適用します。 データ レイクを使用すると、構造化、半構造化、非構造化のいずれであっても、複数の形式のファイルのストレージを結合できます。 スキーマ読み取り セマンティクスを使用します。このセマンティクスは、データの格納時ではなく、データの処理中にデータにスキーマを投影します。 これにより、ソリューションに柔軟性が組み込まれるので、データの検証と型チェックによって発生するデータ インジェスト中のボトルネックを防ぐことができます。
データをインプレース処理します。 従来の BI ソリューションでは、多くの場合、抽出、変換、読み込み (ETL) プロセスを使用してデータ ウェアハウスにデータを移動します。 大量のデータとさまざまな形式を使用するビッグ データ ソリューションでは、一般に、変換、抽出、読み込み (TEL) などの ETL のバリエーションが使用されます。 この方法では、データは分散データ ストア内で処理され、変換されたデータを分析データ ストアに移動する前に、必要な構造に変換されます。
使用率と時間コストのバランスを取ります。 バッチ処理ジョブの場合、2 つの要因を考慮することが重要です。コンピューティング ノードの単位あたりのコストと、それらのノードを使用してジョブを完了するための 1 分あたりのコストです。 たとえば、4 つのクラスター ノードでバッチ ジョブに 8 時間かかる場合があります。 ただし、ジョブでは最初の 2 時間にのみ 4 つのノードがすべて使用され、その後は 2 つのノードのみが必要になることがあります。 その場合、2 つのノードでジョブ全体を実行すると、ジョブの合計時間は増加しますが、2 倍にならないので、合計コストは少なくなります。 一部のビジネス シナリオでは、使用率の低いクラスター リソースを使用するコストが高いほど、処理時間が長くなる場合があります。
リソースを分離します。 可能な限り、ワークロードに基づいてリソースを分離し、1 つのワークロードがすべてのリソースを使用し、他のワークロードが待機しているシナリオを回避することを目的とします。
データ インジェストを調整します。 場合によっては、既存のビジネス アプリケーションがバッチ処理用のデータ ファイルを Azure ストレージ BLOB コンテナーに直接書き込む場合があります。このデータ ファイルは、Microsoft Fabric などのダウンストリーム サービスで使用できます。 ただし、多くの場合、オンプレミスまたは外部のデータ ソースからデータ レイクへのデータの取り込みを調整する必要があります。 オーケストレーション ワークフローまたはパイプライン (Azure Data Factory や Microsoft Fabric でサポートされているものなど) を使用して、予測可能で一元的に管理可能な方法でこれを実現します。
機密データを早期にスクラブします。 データ インジェスト ワークフローでは、データ レイクに格納されないように、プロセスの早い段階で機密データをスクラブする必要があります。
IoT アーキテクチャ
モノのインターネット (IoT) は、ビッグ データ ソリューションの特殊なサブセットです。 次の図は、IoT で使用できる論理アーキテクチャを示しています。 この図は、アーキテクチャのイベント ストリーミング コンポーネントを強調しています。
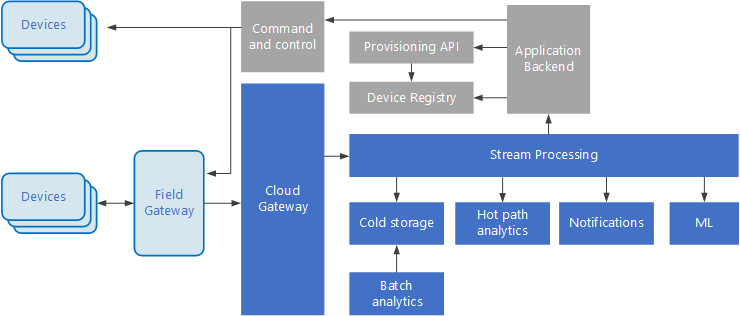 の図
の図
クラウド ゲートウェイ は、信頼性の高い低待機時間メッセージング システムを使用して、クラウド境界でデバイス イベントを取り込みます。
デバイスは、クラウド ゲートウェイに直接、または フィールド ゲートウェイを介してイベントを送信する場合があります。 フィールド ゲートウェイは特殊なデバイスまたはソフトウェアであり、通常はデバイスと併置され、イベントを受信してクラウド ゲートウェイに転送します。 フィールド ゲートウェイでは、未加工のデバイス イベントを前処理して、フィルター処理、集計、プロトコル変換などの機能を実行することもできます。
取り込み後、イベントは、データをルーティング (ストレージなど) したり、分析やその他の処理を実行したりできる 1 つ以上の ストリーム プロセッサ を通過します。
一般的な処理の種類を次に示します。 (このリストは完全ではありません。
アーカイブまたはバッチ分析のために、コールド ストレージにイベント データを書き込みます。
ホット パス分析。イベント ストリームを (ほぼ) リアルタイムで分析し、異常を検出したり、ローリング タイム ウィンドウでのパターンを認識したり、ストリームで特定の条件が発生したときにアラートをトリガーしたりします。
通知やアラームなど、デバイスからの特殊な種類の非テレメトリ メッセージの処理。
機械学習。
灰色で網掛けされたボックスには、イベント ストリーミングに直接関連していない IoT システムのコンポーネントが表示されますが、完全にするためにここに含まれています。
デバイス レジストリ は、プロビジョニングされたデバイスのデータベースであり、デバイス ID と通常はデバイス メタデータ (場所など) を含みます。
プロビジョニング API は、新しいデバイスをプロビジョニングおよび登録するための一般的な外部インターフェイスです。
一部の IoT ソリューションでは、コマンドと制御メッセージ デバイスに送信できます。
このセクションでは、IoT の非常に高いレベルのビューを示しました。考慮すべき微妙な点や課題が多数あります。 詳細については、IoT アーキテクチャのに関するページを参照してください。
次の手順
- ビッグ データ アーキテクチャ
詳細を確認します。 - IoT アーキテクチャのの詳細を確認します。