この記事では、さまざまな Azure データ ストアでデータをパーティション分割するためのいくつかの戦略について説明します。 データをパーティション分割するタイミングとベスト プラクティスに関する一般的なガイダンスについては、「データのパーティション分割 を参照してください。
Azure SQL Database のパーティション分割
1 つの SQL データベースには、格納できるデータの量に制限があります。 スループットは、アーキテクチャの要因と、それがサポートする同時接続の数によって制限されます。
エラスティック プール 、SQL データベースの水平方向のスケーリングをサポートします。 エラスティック プールを使用すると、複数の SQL データベースに分散されたシャードにデータをパーティション分割できます。 また、処理する必要があるデータの量の増減に合わせてシャードを追加または削除することもできます。 エラスティック プールは、データベース間で負荷を分散することで競合を減らすのにも役立ちます。
各シャードは SQL データベースとして実装されます。 シャードは複数のデータセット (シャードレットと呼ばれます) を保持できます。 各データベースは、格納されているシャードレットを記述するメタデータを保持します。 シャードレットには、1 つのデータ項目、または同じシャードレット キーを共有する項目のグループを指定できます。 たとえば、マルチテナント アプリケーションでは、シャードレット キーをテナント ID にすることができ、テナントのすべてのデータを同じシャードレットに保持できます。
クライアント アプリケーションは、データセットをシャードレット キーに関連付けます。 別の SQL Database は、グローバル シャード マップ マネージャーとして機能します。 このデータベースには、システム内のすべてのシャードとシャードレットの一覧があります。 アプリケーションはシャード マップ マネージャー データベースに接続して、シャード マップのコピーを取得します。 シャード マップをローカルにキャッシュし、マップを使用してデータ要求を適切なシャードにルーティングします。 この機能は、Java および .NET で使用できる Elastic Database クライアント ライブラリに含まれる一連の API の背後に隠れています。
エラスティック プールの詳細については、「Azure SQL Databaseを使用したスケールアウト」を参照してください。
待機時間を短縮し、可用性を向上させるために、グローバル シャード マップ マネージャー データベースをレプリケートできます。 Premium 価格レベルでは、アクティブ geo レプリケーションを構成して、異なるリージョンのデータベースにデータを継続的にコピーできます。
または、Azure SQL Data Sync 使用するか、Azure Data Factory を して、リージョン間でシャード マップ マネージャー データベースをレプリケートします。 この形式のレプリケーションは定期的に実行され、シャード マップの変更頻度が低く、Premium レベルを必要としない場合に適しています。
Elastic Database には、シャードレットにデータをマッピングし、シャードに格納するための 2 つのスキームが用意されています。
リストシャード マップ は、1 つのキーをシャードレットに関連付けます。 たとえば、マルチテナント システムでは、各テナントのデータを一意のキーに関連付け、独自のシャードレットに格納できます。 分離を保証するために、各シャードレットを独自のシャード内に保持できます。

この図の Visio ファイルをダウンロードします。
範囲シャード マップ は、連続するキー値のセットをシャードレットに関連付けます。 たとえば、同じシャードレット内の一連のテナント (それぞれ独自のキーを持つ) のデータをグループ化できます。 テナントはデータ ストレージを共有するが分離性が低いため、このスキームは最初のスキームよりもコストが低くなります。

この図の Visio ファイル をダウンロード
1 つのシャードに複数のシャードレットのデータを含めることができます。 たとえば、リスト シャードレットを使用して、連続していない異なるテナントのデータを同じシャードに格納できます。 また、範囲シャードレットとリスト シャードレットを同じシャードに混在させることもできますが、異なるマップを介してアドレス指定されます。 次の図は、この方法を示しています。

この図の Visio ファイルをダウンロードします。
エラスティック プールを使用すると、データの量が増減するにつれてシャードを追加および削除できます。 クライアント アプリケーションは、シャードを動的に作成および削除し、シャード マップ マネージャーを透過的に更新できます。 ただし、シャードの削除は破壊的操作であり、そのシャード内のすべてのデータも削除する必要があります。
アプリケーションで 1 つのシャードを 2 つの個別のシャードに分割するか、シャードを結合する必要がある場合は、分割/マージ ツールを使用。 このツールは Azure Web サービスとして実行され、シャード間で安全にデータを移行します。
パーティション分割スキームは、システムのパフォーマンスに大きな影響を与える可能性があります。 また、シャードを追加または削除する必要がある速度や、シャード間でデータを再パーティション分割する必要がある速度にも影響を与える可能性があります。 次の点を考慮してください。
同じシャードで一緒に使用されるデータをグループ化し、複数のシャードのデータにアクセスする操作を回避します。 シャードはそれ自体が SQL データベースであり、データベース間結合はクライアント側で実行する必要があります。
SQL Database ではデータベース間結合はサポートされていませんが、Elastic Database ツールを使用して、マルチシャード クエリを実行できます。 マルチシャード クエリは、個々のクエリを各データベースに送信し、結果をマージします。
シャード間の依存関係を持つシステムを設計しないでください。 あるデータベースの参照整合性制約、トリガー、およびストアド プロシージャは、別のデータベースのオブジェクトを参照できません。
クエリで頻繁に使用される参照データがある場合は、シャード間でこのデータをレプリケートすることを検討してください。 この方法では、データベース間でデータを結合する必要を排除できます。 レプリケーションの労力を最小限に抑え、古くなる可能性を減らすために、このようなデータは静的または低速であることが理想的です。
同じシャード マップに属するシャードレットは、同じスキーマを持つ必要があります。 この規則は SQL Database によって適用されませんが、各シャードレットに異なるスキーマがある場合、データの管理とクエリは非常に複雑になります。 代わりに、スキーマごとに個別のシャード マップを作成します。 異なるシャードレットに属するデータは、同じシャードに格納できることに注意してください。
トランザクション操作は、シャード内のデータに対してのみサポートされ、シャード間ではサポートされません。 トランザクションは、同じシャードの一部である限り、シャードレットにまたがることができます。 そのため、ビジネス ロジックでトランザクションを実行する必要がある場合は、データを同じシャードに格納するか、最終的な整合性を実装します。
シャードを、それらのシャード内のデータにアクセスするユーザーの近くに配置します。 この戦略は、待機時間の短縮に役立ちます。
非常にアクティブなシャードと比較的非アクティブなシャードが混在しないようにします。 負荷をシャード間で均等に分散してみてください。 これにはシャーディング キーのハッシュが必要になる場合があります。 シャードを地理的に検索する場合は、ハッシュされたキーが、そのデータにアクセスするユーザーの近くに格納されているシャードレットにマップされていることを確認します。
Azure Table Storage のパーティション分割
Azure Table Storage は、パーティション分割を中心に設計されたキー値ストアです。 すべてのエンティティはパーティションに格納され、パーティションは Azure Table Storage によって内部的に管理されます。 テーブルに格納されている各エンティティは、次を含む 2 部構成のキーを提供する必要があります。
パーティション キー。 これは、Azure Table Storage によってエンティティが配置されるパーティションを決定する文字列値です。 同じパーティション キーを持つすべてのエンティティは、同じパーティションに格納されます。
行キー。 これは、パーティション内のエンティティを識別する文字列値です。 パーティション内のすべてのエンティティは、このキーによって構文的に昇順に並べ替えられます。 パーティション キーと行キーの組み合わせはエンティティごとに一意である必要があり、長さが 1 KB を超えることはできません。
以前に使用されていないパーティション キーを持つテーブルにエンティティが追加された場合、Azure Table Storage はこのエンティティの新しいパーティションを作成します。 同じパーティション キーを持つ他のエンティティは、同じパーティションに格納されます。
このメカニズムは、自動スケールアウト戦略を効果的に実装します。 各パーティションは、1 つのパーティションからデータを取得するクエリが迅速に実行されるように、Azure データセンター内の同じサーバーに格納されます。
Microsoft は、Azure Storage の スケーラビリティ ターゲットを公開しています。 システムがこれらの制限を超える可能性がある場合は、エンティティを複数のテーブルに分割することを検討してください。 垂直パーティション分割を使用して、一緒にアクセスされる可能性が最も高いグループにフィールドを分割します。
次の図は、ストレージ アカウントの例の論理構造を示しています。 ストレージ アカウントには、顧客情報、製品情報、注文情報の 3 つのテーブルが含まれています。
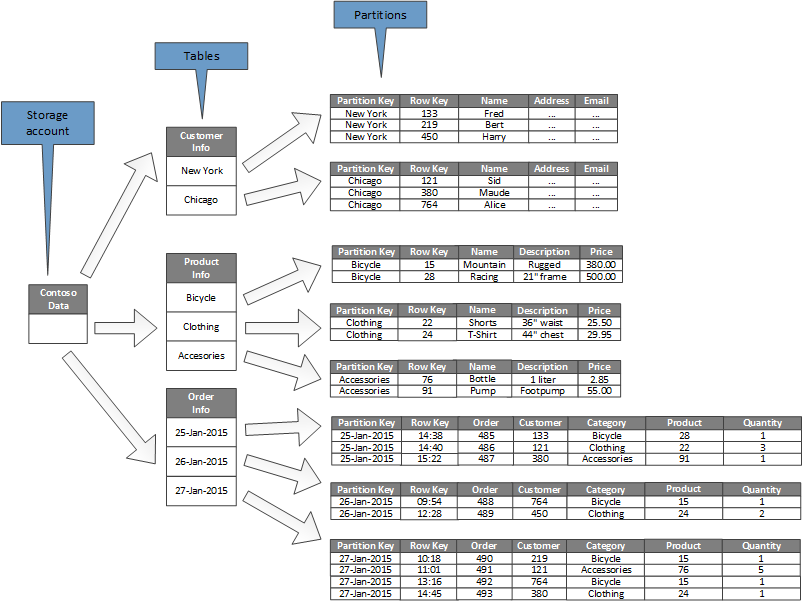
各テーブルには複数のパーティションがあります。
- 顧客情報テーブルでは、顧客が配置されている市区町村に従ってデータがパーティション分割されます。 行キーには顧客 ID が含まれています。
- [製品情報] テーブルでは、製品は製品カテゴリ別にパーティション分割され、行キーには製品番号が含まれます。
- 注文情報テーブルでは、注文は注文日別にパーティション分割され、行キーは注文を受け取った時刻を指定します。 すべてのデータは、各パーティションの行キーによって並べ替えられます。
Azure Table Storage のエンティティを設計するときは、次の点を考慮してください。
データへのアクセス方法によってパーティション キーと行キーを選択します。 クエリの大部分をサポートするパーティション キーと行キーの組み合わせを選択します。 最も効率的なクエリでは、パーティション キーと行キーを指定してデータを取得します。 パーティション キーと行キーの範囲を指定するクエリは、1 つのパーティションをスキャンすることで完了できます。 これは、データが行キーの順序で保持されるため、比較的高速です。 クエリでスキャンするパーティションが指定されていない場合は、すべてのパーティションをスキャンする必要があります。
エンティティに 1 つの自然なキーがある場合は、それをパーティション キーとして使用し、行キーとして空の文字列を指定します。 エンティティに 2 つのプロパティで構成される複合キーがある場合は、変更が最も遅いプロパティをパーティション キーとして選択し、もう一方を行キーとして選択します。 エンティティに複数のキー プロパティがある場合は、プロパティを連結してパーティション キーと行キーを指定します。
パーティションキーと行キー以外のフィールドを使用してデータを検索するクエリを定期的に実行する場合は、インデックス テーブル パターンの実装を検討するか、Azure Cosmos DB などのインデックス作成をサポートする別のデータ ストアの使用を検討してください。
単調なシーケンス ("0001"、"0002"、"0003" など) を使用してパーティション キーを生成し、各パーティションに限られた量のデータのみが含まれている場合、Azure Table Storage では、これらのパーティションを同じサーバー上で物理的にグループ化できます。 Azure Storage では、アプリケーションが連続した範囲のパーティション (範囲クエリ) に対してクエリを実行する可能性が最も高く、この場合に最適化されていることを前提としています。 ただし、新しいエンティティのすべての挿入が連続する範囲の一方の端に集中する可能性があるため、このアプローチはホットスポットにつながる可能性があります。 また、スケーラビリティを低下させることもできます。 負荷をより均等に分散するには、パーティション キーのハッシュを検討してください。
Azure Table Storage では、同じパーティションに属するエンティティのトランザクション操作がサポートされています。 トランザクションに 100 個を超えるエンティティが含まれていないか、要求のペイロードが 4 MB を超えない限り、アプリケーションはアトミック単位として複数の挿入、更新、削除、置換、またはマージ操作を実行できます。 複数のパーティションにまたがる操作はトランザクションではなく、最終的な整合性を実装する必要がある場合があります。 テーブルストレージとトランザクションの詳細については、「エンティティグループトランザクションの実行」を参照してください。
パーティション キーの細分性を考慮してください。
すべてのエンティティに同じパーティション キーを使用すると、1 つのサーバーに保持される 1 つのパーティションになります。 これにより、パーティションがスケールアウトされなくなり、負荷が 1 つのサーバーに集中します。 その結果、このアプローチは少数のエンティティを格納する場合にのみ適しています。 ただし、すべてのエンティティがエンティティ グループ トランザクションに参加できることを保証します。
すべてのエンティティに一意のパーティション キーを使用すると、テーブル ストレージ サービスによってエンティティごとに個別のパーティションが作成され、多数の小さなパーティションが作成される可能性があります。 この方法は、単一のパーティション キーを使用するよりもスケーラブルですが、エンティティ グループ トランザクションは実行できません。 また、複数のエンティティをフェッチするクエリでは、複数のサーバーからの読み取りが必要になる場合があります。 ただし、アプリケーションが範囲クエリを実行する場合、パーティション キーに単調なシーケンスを使用すると、これらのクエリを最適化するのに役立つ場合があります。
エンティティのサブセット間でパーティション キーを共有すると、同じパーティション内の関連エンティティをグループ化できます。 関連エンティティを含む操作は、エンティティ グループ トランザクションを使用して実行できます。また、一連の関連エンティティをフェッチするクエリは、1 つのサーバーにアクセスすることで満たすことができます。
詳細については、Azure Storage テーブルの設計ガイド およびスケーラブルなパーティション分割戦略 を参照してください。
Azure Blob Storage のパーティション分割
Azure Blob Storage を使用すると、大きなバイナリ オブジェクトを保持できます。 大量のデータをすばやくアップロードまたはダウンロードする必要があるシナリオでは、ブロック BLOB を使用します。 データの一部へのシリアル アクセスではなくランダムなアクセスを必要とするアプリケーションには、ページ BLOB を使用します。
各 BLOB (ブロックまたはページ) は、Azure Storage アカウントのコンテナーに保持されます。 コンテナーを使用して、同じセキュリティ要件を持つ関連 BLOB をグループ化できます。 このグループ化は、物理的ではなく論理的です。 コンテナー内では、各 BLOB に一意の名前が付けられます。
BLOB のパーティション キーは、アカウント名 + コンテナー名 + BLOB 名です。 パーティション キーは、データを範囲にパーティション分割するために使用され、これらの範囲はシステム全体で負荷分散されます。 BLOB は、アクセスをスケールアウトするために多数のサーバーに分散できますが、1 つの BLOB は 1 つのサーバーでのみ処理できます。
名前付けスキームでタイムスタンプまたは数値識別子が使用されている場合、1 つのパーティションに過剰なトラフィックが送信され、システムの負荷分散が効果的に制限される可能性があります。 たとえば、yy- mm-ddなどのタイムスタンプを持つ BLOB オブジェクトを使用する毎日の操作がある場合、その操作のすべてのトラフィックは 1 つのパーティション サーバーに送信されます。 代わりに、名前の前に 3 桁のハッシュを付けてみてください。 詳細については、「パーティションの名前付け規則」を参照してください。
1 つのブロックまたはページを書き込む操作はアトミックですが、ブロック、ページ、または BLOB にまたがる操作はアトミックではありません。 ブロック、ページ、BLOB 間で書き込み操作を実行するときに一貫性を確保する必要がある場合は、BLOB リースを使用して書き込みロックを解除します。
Azure Storage キューのパーティション分割
Azure Storage キューを使用すると、プロセス間で非同期メッセージングを実装できます。 Azure Storage アカウントには任意の数のキューを含めることができます。また、各キューには任意の数のメッセージを含めることができます。 唯一の制限は、ストレージ アカウントで使用できる領域です。 個々のメッセージの最大サイズは 64 KB です。 これより大きいメッセージが必要な場合は、代わりに Azure Service Bus キューを使用することを検討してください。
各ストレージ キューには、それを含むストレージ アカウント内の一意の名前があります。 Azure では、名前に基づいてキューがパーティション分割されます。 同じキューのすべてのメッセージは、単一のサーバーによって制御される同じパーティションに格納されます。 負荷のバランスを取るために、異なるサーバーによって異なるキューを管理できます。 サーバーへのキューの割り当ては、アプリケーションとユーザーに対して透過的です。
大規模なアプリケーションでは、アプリケーションのすべてのインスタンスに同じストレージ キューを使用しないでください。この方法では、キューをホストしているサーバーがホット スポットになる可能性があるためです。 代わりに、アプリケーションの機能領域ごとに異なるキューを使用してください。 Azure Storage キューはトランザクションをサポートしていないため、異なるキューにメッセージを送信すると、メッセージングの一貫性にほとんど影響しません。
Azure Storage キューは、1 秒あたり最大 2,000 個のメッセージを処理できます。 これよりも高い速度でメッセージを処理する必要がある場合は、複数のキューを作成することを検討してください。 たとえば、グローバル アプリケーションでは、個別のストレージ アカウントに個別のストレージ キューを作成して、各リージョンで実行されているアプリケーション インスタンスを処理します。
Azure Service Bus のパーティション分割
Azure Service Bus では、メッセージ ブローカーを使用して、Service Bus キューまたはトピックに送信されるメッセージを処理します。 既定では、キューまたはトピックに送信されるすべてのメッセージは、同じメッセージ ブローカー プロセスによって処理されます。 このアーキテクチャでは、メッセージ キューの全体的なスループットに制限を設けることができます。 ただし、キューまたはトピックの作成時にパーティション分割することもできます。 これを行うには、キューまたはトピックの説明の EnablePartitioning プロパティを true 設定します。
パーティション分割されたキューまたはトピックは複数のフラグメントに分割され、それぞれが個別のメッセージ ストアとメッセージ ブローカーによってサポートされます。 Service Bus は、これらのフラグメントの作成と管理を担当します。 アプリケーションがパーティション分割されたキューまたはトピックにメッセージを投稿すると、Service Bus はそのキューまたはトピックのフラグメントにメッセージを割り当てます。 アプリケーションがキューまたはサブスクリプションからメッセージを受信すると、Service Bus は各フラグメントで次に使用可能なメッセージを確認し、処理のためにアプリケーションに渡します。
この構造は、メッセージ ブローカーとメッセージ ストア間で負荷を分散し、スケーラビリティを高め、可用性を向上させるのに役立ちます。 1 つのフラグメントのメッセージ ブローカーまたはメッセージ ストアが一時的に使用できない場合、Service Bus は残りの使用可能なフラグメントのいずれかからメッセージを取得できます。
Service Bus は、次のようにメッセージをフラグメントに割り当てます。
メッセージがセッションに属している場合、SessionId プロパティに対して同じ値を持つすべてのメッセージが同じフラグメントに送信されます。
メッセージがセッションに属していないが、送信者が PartitionKey プロパティの値を指定した場合、同じ PartitionKey 値を持つすべてのメッセージが同じフラグメントに送信されます。
注
SessionId プロパティと PartitionKey プロパティの両方が指定されている場合は、同じ値に設定する必要があります。そうしないと、メッセージは拒否されます。
メッセージの SessionId プロパティと PartitionKey プロパティが指定されていないが、重複検出が有効になっている場合は、MessageId プロパティが使用されます。 同じ MessageId を持つすべてのメッセージは、同じフラグメントに転送されます。
メッセージに SessionId、PartitionKey、、または MessageId プロパティが含まれていない場合、Service Bus はメッセージをフラグメントに順番に割り当てます。 フラグメントが使用できない場合、Service Bus は次のフラグメントに進みます。 つまり、メッセージング インフラストラクチャの一時的な障害によってメッセージ送信操作が失敗することはありません。
Service Bus メッセージ キューまたはトピックをパーティション分割するかどうかを決定する場合は、次の点を考慮してください。
Service Bus のキューとトピックは、Service Bus 名前空間のスコープ内に作成されます。 現在、Service Bus では、名前空間ごとに最大 100 個のパーティション分割されたキューまたはトピックを使用できます。
各 Service Bus 名前空間では、トピックあたりのサブスクリプション数、1 秒あたりの同時送受信要求数、確立できる同時接続の最大数など、使用可能なリソースにクォータが適用されます。 これらのクォータについては、Service Bus クォータに関する記事を参照してください。 これらの値を超えると予想される場合は、独自のキューとトピックを使用して追加の名前空間を作成し、これらの名前空間全体に作業を分散します。 たとえば、グローバル アプリケーションでは、リージョンごとに個別の名前空間を作成し、最も近い名前空間のキューとトピックを使用するようにアプリケーション インスタンスを構成します。
トランザクションの一部として送信されるメッセージでは、パーティション キーを指定する必要があります。 SessionId、PartitionKey 、または MessageId プロパティ できます。 同じトランザクションの一部として送信されるすべてのメッセージは、同じメッセージ ブローカー プロセスで処理する必要があるため、同じパーティション キーを指定する必要があります。 同じトランザクション内の異なるキューまたはトピックにメッセージを送信することはできません。
パーティション分割されたキューとトピックは、アイドル状態になったときに自動的に削除されるように構成することはできません。
クロスプラットフォームまたはハイブリッド ソリューションを構築している場合、パーティション分割されたキューとトピックは、現在、Advanced Message Queuing Protocol (AMQP) では使用できません。
Azure Cosmos DB のパーティション分割
Azure Cosmos DB for NoSQL は、JSON ドキュメントを格納するための NoSQL データベースです。 Azure Cosmos DB データベース内のドキュメントは、オブジェクトまたはその他のデータを JSON でシリアル化した表現です。 すべてのドキュメントに一意の ID を含める必要がある点を除き、固定スキーマは適用されません。
ドキュメントはコレクションに編成されます。 関連するドキュメントをコレクション内でグループ化できます。 たとえば、ブログ投稿を保持するシステムでは、各ブログ投稿の内容をドキュメントとしてコレクションに格納できます。 サブジェクトの種類ごとにコレクションを作成することもできます。 また、さまざまな作成者が自分のブログ投稿を制御および管理するシステムなどのマルチテナント アプリケーションでは、作成者別にブログをパーティション分割し、作成者ごとに個別のコレクションを作成できます。 コレクションに割り当てられるストレージ領域は柔軟であり、必要に応じて縮小または拡張できます。
Azure Cosmos DB では、アプリケーション定義のパーティション キーに基づくデータの自動パーティション分割がサポートされています。 論理パーティション は、1 つのパーティション キー値のすべてのデータを格納するパーティションです。 パーティション キーの同じ値を共有するすべてのドキュメントは、同じ論理パーティション内に配置されます。 Azure Cosmos DB は、パーティション キーのハッシュに従って値を分散します。 論理パーティションの最大サイズは 20 GB です。 そのため、パーティション キーの選択は、設計時の重要な決定です。 幅広い値とアクセス パターンを持つプロパティを選択します。 詳細については、「Azure Cosmos DB でのパーティション分割とスケールの」を参照してください。
注
各 Azure Cosmos DB データベースには、取得するリソースの量を決定する パフォーマンス レベルがあります。 パフォーマンス レベルは、要求ユニット (RU) レート制限に関連付けられています。 RU レート制限では、そのコレクションで排他的に使用するために予約され、使用できるリソースの量を指定します。 コレクションのコストは、そのコレクションに対して選択されているパフォーマンス レベルによって異なります。 パフォーマンス レベル (および RU レート制限) が高いほど、料金が高くなります。 Azure portal を使用して、コレクションのパフォーマンス レベルを調整できます。 詳細については、「Azure Cosmos DBでの要求ユニットの
Azure Cosmos DB が提供するパーティション分割メカニズムが十分でない場合は、アプリケーション レベルでデータをシャード化する必要があります。 ドキュメント コレクションは、1 つのデータベース内でデータをパーティション分割するための自然なメカニズムを提供します。 シャーディングを実装する最も簡単な方法は、シャードごとにコレクションを作成することです。 コンテナーは論理リソースであり、1 つ以上のサーバーにまたがることができます。 固定サイズのコンテナーの最大スループットは 20 GB と 10,000 RU/秒です。 無制限のコンテナーには最大ストレージ サイズはありませんが、パーティション キーを指定する必要があります。 アプリケーションのシャーディングでは、クライアント アプリケーションは、通常、シャード キーを定義するデータの属性に基づいて独自のマッピング メカニズムを実装することによって、要求を適切なシャードに送信する必要があります。
すべてのデータベースは、Azure Cosmos DB データベース アカウントのコンテキストで作成されます。 1 つのアカウントに複数のデータベースを含めることができます。また、データベースを作成するリージョンを指定します。 各アカウントでは、独自のアクセス制御も適用されます。 Azure Cosmos DB アカウントを使用して、アクセスする必要があるユーザーの近くにシャード (データベース内のコレクション) を geo 配置し、それらのユーザーのみがそれらに接続できるように制限を適用できます。
Azure Cosmos DB for NoSQL を使用してデータをパーティション分割する方法を決定するときは、次の点を考慮してください。
Azure Cosmos DB データベースで使用できるリソースには、アカウントのクォータ制限が適用されます。 各データベースは多数のコレクションを保持でき、各コレクションは、そのコレクションの RU レート制限 (予約済みスループット) を制御するパフォーマンス レベルに関連付けられます。 詳細については、「Azure サブスクリプションとサービスの制限、クォータ、制約に関するページを参照してください。
各ドキュメントには、保持されているコレクション内のドキュメントを一意に識別するために使用できる属性が必要です。 この属性は、ドキュメントを保持するコレクションを定義するシャード キーとは異なります。 コレクションには、多数のドキュメントを含めることができます。 理論的には、ドキュメント ID の最大長によってのみ制限されます。 ドキュメント ID は最大 255 文字です。
ドキュメントに対するすべての操作は、トランザクションのコンテキスト内で実行されます。 トランザクションのスコープは、ドキュメントが含まれているコレクションです。 操作が失敗した場合、実行した作業はロールバックされます。 ドキュメントは操作の対象ですが、行われた変更はスナップショット レベルの分離の対象になります。 このメカニズムにより、たとえば、新しいドキュメントの作成要求が失敗した場合、データベースに対して同時にクエリを実行している別のユーザーに、削除された部分ドキュメントが表示されないことが保証されます。
データベース クエリは、コレクション レベルのにスコープも設定されます。 1 つのクエリでは、1 つのコレクションからのみデータを取得できます。 複数のコレクションからデータを取得する必要がある場合は、各コレクションに個別にクエリを実行し、結果をアプリケーション コードにマージする必要があります。
Azure Cosmos DB では、ドキュメントと共にコレクションにすべて格納できるプログラミング可能な項目がサポートされています。 これには、ストアド プロシージャ、ユーザー定義関数、トリガー (JavaScript で記述) が含まれます。 これらの項目は、同じコレクション内の任意のドキュメントにアクセスできます。 さらに、これらの項目は、アンビエント トランザクションのスコープ内で実行されます (ドキュメントに対して実行された作成、削除、または置換操作の結果として発生するトリガーの場合)、または新しいトランザクションを開始する (明示的なクライアント要求の結果として実行されるストアド プロシージャの場合)。 プログラム可能な項目のコードが例外をスローした場合、トランザクションはロールバックされます。 ストアド プロシージャとトリガーを使用して、ドキュメント間の整合性と整合性を維持できますが、これらのドキュメントはすべて同じコレクションに含まれている必要があります。
データベースに保持するコレクションが、コレクションのパフォーマンス レベルで定義されているスループット制限を超える可能性は低いはずです。 詳細については、「Azure Cosmos DBでの要求ユニットの
」を参照してください。 これらの制限に達することが予想される場合は、コレクションごとの負荷を軽減するために、異なるアカウント内のデータベース間でコレクションを分割することを検討してください。
Azure AI Search のパーティション分割
多くの場合、データを検索する機能は、多くの Web アプリケーションによって提供されるナビゲーションと探索の主要な方法です。 検索基準の組み合わせに基づいて、ユーザーがリソース (e コマース アプリケーションの製品など) をすばやく見つけるのに役立ちます。 AI Search サービスは、Web コンテンツに対してフルテキスト検索機能を提供し、先行入力、近くの一致に基づくクエリ候補、ファセット ナビゲーションなどの機能を備えています。 詳細については、「AI Search とは」を参照してください。.
AI Search は、検索可能なコンテンツを JSON ドキュメントとしてデータベースに格納します。 これらのドキュメントで検索可能なフィールドを指定するインデックスを定義し、これらの定義を AI Search に提供します。 ユーザーが検索要求を送信すると、AI Search は適切なインデックスを使用して一致する項目を検索します。
競合を減らすために、AI Search で使用されるストレージを 1、2、3、4、6、または 12 個のパーティションに分割し、各パーティションを最大 6 回レプリケートできます。 パーティションの数にレプリカの数を掛けた積は、検索単位 (SU)と呼ばれます。 AI Search の 1 つのインスタンスには、最大 36 個の SU を含めることができます (12 個のパーティションを持つデータベースでは、最大 3 つのレプリカのみがサポートされます)。
サービスに割り当てられている SU ごとに課金されます。 検索可能なコンテンツの量が増えたり、検索要求の速度が増加したりすると、AI Search の既存のインスタンスに SU を追加して、追加の負荷を処理できます。 AI Search 自体は、ドキュメントをパーティション間で均等に分散します。 現在、手動によるパーティション分割戦略はサポートされていません。
各パーティションには、最大 1,500 万個のドキュメントを含めたり、300 GB の記憶域スペース (どちらか小さい方) を占有したりすることができます。 最大 50 個のインデックスを作成できます。 サービスのパフォーマンスは、ドキュメントの複雑さ、使用可能なインデックス、ネットワーク待機時間の影響によって異なります。 平均すると、1 つのレプリカ (1 SU) で 1 秒あたり 15 個のクエリ (QPS) を処理できる必要がありますが、スループットのより正確な測定を得るために、独自のデータを使用してベンチマークを実行することをお勧めします。 詳細については、「AI Search でのサービスの制限」を参照してください。
注
文字列、ブール値、数値データ、datetime データ、一部の地理的データなど、検索可能なドキュメントに限られたデータ型のセットを格納できます。 詳細については、Microsoft Web サイト サポートされているデータ型 (AI Search) のページを参照してください。
AI Search でサービスの各インスタンスのデータをパーティション分割する方法を制限できます。 ただし、グローバル環境では、次のいずれかの方法を使用してサービス自体をパーティション分割することで、パフォーマンスを向上させ、待機時間と競合をさらに減らすことができます。
各地理的リージョンに AI Search のインスタンスを作成し、クライアント アプリケーションが使用可能な最も近いインスタンスに向けられることを確認します。 この戦略では、検索可能なコンテンツに対する更新が、サービスのすべてのインスタンスにわたってタイムリーにレプリケートされる必要があります。
AI Search の 2 つの層を作成します。
- そのリージョン内のユーザーが最も頻繁にアクセスするデータを含む、各リージョンのローカル サービス。 ユーザーは、速くて限られた結果を得るための要求をここに送ることができます。
- すべてのデータを含むグローバル サービス。 ユーザーは、より遅く、より完全な結果を得るための要求をここに送信できます。
この方法は、検索対象のデータに大きな地域的なバリエーションがある場合に最も適しています。
Azure Cache for Redis のパーティション分割
Azure Cache for Redis は、Redis キー値データ ストアに基づくクラウド内の共有キャッシュ サービスを提供します。 その名前が示すように、Azure Cache for Redis はキャッシュ ソリューションとして意図されています。 永続的なデータ ストアとしてではなく、一時的なデータを保持する場合にのみ使用します。 キャッシュが使用できない場合、Azure Cache for Redis を使用するアプリケーションは引き続き機能できる必要があります。 Azure Cache for Redis では、高可用性を実現するためにプライマリ/セカンダリ レプリケーションがサポートされていますが、現在、最大キャッシュ サイズは 53 GB に制限されています。 これよりも多くの領域が必要な場合は、追加のキャッシュを作成する必要があります。 詳細については、「Azure Cache for Redis」を参照してください。
Redis データ ストアをパーティション分割するには、Redis サービスのインスタンス間でデータを分割する必要があります。 各インスタンスは 1 つのパーティションを構成します。 Azure Cache for Redis では、ファサードの背後にある Redis サービスが抽象化され、直接公開されることはありません。 パーティション分割を実装する最も簡単な方法は、複数の Azure Cache for Redis インスタンスを作成し、それらの間でデータを分散することです。
各データ項目を、データ項目を格納するキャッシュを指定する識別子 (パーティション キー) に関連付けることができます。 クライアント アプリケーション ロジックでは、この識別子を使用して、要求を適切なパーティションにルーティングできます。 このスキームは非常に単純ですが、パーティション分割スキームが変更された場合 (たとえば、追加の Azure Cache for Redis インスタンスが作成された場合)、クライアント アプリケーションの再構成が必要になる場合があります。
(Azure Cache for Redis ではなく) Native Redis では、Redis クラスタリングに基づくサーバー側のパーティション分割がサポートされます。 この方法では、ハッシュ メカニズムを使用して、サーバー間でデータを均等に分割できます。 各 Redis サーバーには、パーティションが保持するハッシュ キーの範囲を記述するメタデータと、他のサーバー上のパーティションに配置されているハッシュ キーに関する情報が格納されます。
クライアント アプリケーションは、参加している任意の Redis サーバー (おそらく最も近いサーバー) に要求を送信するだけです。 Redis サーバーは、クライアント要求を調べます。 ローカルで解決できる場合は、要求された操作を実行します。 それ以外の場合は、要求が適切なサーバーに転送されます。
このモデルは Redis クラスタリングを使用して実装され、Redis Web サイトの Redis クラスターのチュートリアル ページで詳しく説明されています。 Redis クラスタリングは、クライアント アプリケーションに対して透過的です。 クライアントを再構成しなくても、追加の Redis サーバーをクラスターに追加できます (また、データを再パーティション分割することもできます)。
重要
Azure Cache for Redis では現在、Premium レベルでの Redis クラスタリングのみがサポートされています。
パーティション分割 ページ: Redis Web サイトで 複数の Redis インスタンス間でデータを分割する方法については、Redis でのパーティション分割の実装に関する詳細を提供します。 このセクションの残りの部分では、クライアント側またはプロキシ支援型のパーティション分割を実装していることを前提としています。
Azure Cache for Redis を使用してデータをパーティション分割する方法を決定するときは、次の点を考慮してください。
Azure Cache for Redis は永続的なデータ ストアとして機能することを意図していないため、実装するパーティション分割スキームに関係なく、アプリケーション コードはキャッシュではない場所からデータを取得できる必要があります。
頻繁に一緒にアクセスされるデータは、同じパーティションに保持する必要があります。 Redis は、データを構造化するための高度に最適化されたメカニズムを提供する強力なキー値ストアです。 これらのメカニズムは、次のいずれかになります。
- 単純な文字列 (最大 512 MB の長さのバイナリ データ)
- リスト (キューやスタックとして機能できる) などの集計型
- セット (順序付けおよび順序なし)
- ハッシュ (オブジェクト内のフィールドを表す項目など、関連するフィールドをグループ化できます)
集計型を使用すると、多くの関連する値を同じキーに関連付けることができます。 Redis キーは、含まれているデータ項目ではなく、リスト、セット、またはハッシュを識別します。 これらの型はすべて Azure Cache for Redis で使用でき、Redis Web サイトの データ型 ページで説明されています。 たとえば、顧客によって行われた注文を追跡する e コマース システムの一部では、各顧客の詳細を、顧客 ID を使用してキーを設定された Redis ハッシュに格納できます。 各ハッシュは、顧客の注文 ID のコレクションを保持できます。 別の Redis セットは注文を保持でき、再びハッシュとして構造化され、注文 ID を使用してキーが設定されます。 図 8 は、この構造を示しています。 Redis は参照整合性の形式を実装していないため、顧客と注文の間の関係を維持するのは開発者の責任であることに注意してください。
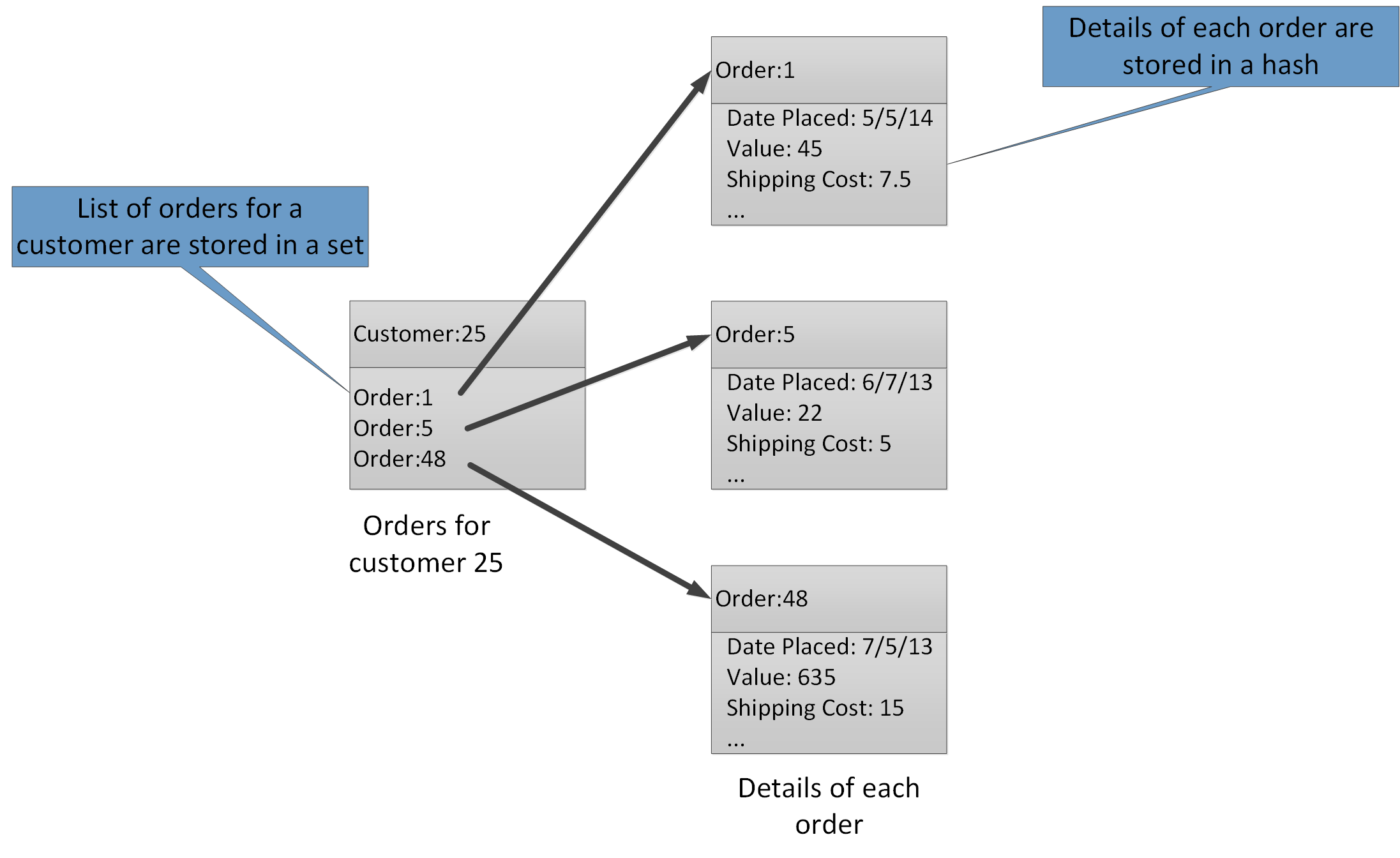
図 8. 顧客の注文とその詳細を記録するための Redis Storage の推奨される構造。
注
Redis では、すべてのキーはバイナリ データ値 (Redis 文字列など) であり、最大 512 MB のデータを含めることができます。 理論上、キーにはほぼすべての情報を含めることができます。 ただし、データの種類を説明し、エンティティを識別するが長すぎるわけではないキーには、一貫した名前付け規則を採用することをお勧めします。 一般的な方法は、"entity_type:ID" という形式のキーを使用することです。 たとえば、"customer:99" を使用して、ID 99 を持つ顧客のキーを示すことができます。
同じデータベース内のさまざまな集計に関連情報を格納することで、垂直パーティション分割を実装できます。 たとえば、eコマース アプリケーションでは、製品に関してよくアクセスされる情報を 1 つの Redis ハッシュに格納し、使用頻度の低い詳細情報を別の Redis ハッシュに格納できます。 どちらのハッシュも、キーの一部として同じ製品 ID を使用できます。 たとえば、製品情報には "product: nn" (nn は製品 ID) を使用し、詳細データには "product_details: nn" を使用できます。 この戦略は、ほとんどのクエリが取得する可能性が高いデータの量を減らすのに役立ちます。
Redis データ ストアは再パーティション分割できますが、複雑で時間のかかる作業であることに注意してください。 Redis クラスタリングではデータを自動的に再パーティション分割できますが、この機能は Azure Cache for Redis では使用できません。 そのため、パーティション分割スキームを設計するときは、時間の経過と同時に予想されるデータの増加を可能にするために、各パーティションに十分な空き領域を残すようにします。 ただし、Azure Cache for Redis はデータを一時的にキャッシュすることを目的としており、キャッシュに保持されるデータの有効期間は、有効期間 (TTL) 値として指定できます。 比較的揮発性のデータの場合、TTL は短くなる可能性がありますが、静的データの場合、TTL は大幅に長くなる可能性があります。 このデータの量がキャッシュに格納される可能性が高い場合は、有効期間の長い大量のデータをキャッシュに格納しないでください。 領域が Premium の場合に Azure Cache for Redis がデータを削除する削除ポリシーを指定できます。
注
Azure Cache for Redis を使用する場合は、適切な価格レベルを選択して、キャッシュの最大サイズ (250 MB から 53 GB) を指定します。 ただし、Azure Cache for Redis が作成された後は、そのサイズを増やしたり減らしたりすることはできません。
Redis バッチとトランザクションは複数の接続にまたがることはできません。そのため、バッチまたはトランザクションの影響を受けるすべてのデータを同じデータベース (シャード) に保持する必要があります。
注
Redis トランザクションでの一連の操作は、必ずしもアトミックであるとは限りません。 トランザクションを構成するコマンドは、実行前に検証され、キューに入れられます。 このフェーズ中にエラーが発生した場合、キュー全体が破棄されます。 ただし、トランザクションが正常に送信されると、キューに登録されたコマンドが順番に実行されます。 いずれかのコマンドが失敗した場合、そのコマンドのみが実行を停止します。 キュー内の前のコマンドとそれ以降のすべてのコマンドが実行されます。 詳細については、Redis Web サイトの Transactions ページを参照してください。
Redis では、限られた数のアトミック操作がサポートされています。 複数のキーと値をサポートするこの型の操作は、MGET 操作と MSET 操作だけです。 MGET 操作は、指定したキーの一覧の値のコレクションを返し、MSET 操作は、指定したキーの一覧の値のコレクションを格納します。 これらの操作を使用する必要がある場合は、MSET コマンドと MGET コマンドによって参照されるキーと値のペアを同じデータベース内に格納する必要があります。
Azure Service Fabric のパーティション分割
Azure Service Fabric は、クラウド内の分散アプリケーションのランタイムを提供するマイクロサービス プラットフォームです。 Service Fabric では、.NET ゲスト実行可能ファイル、ステートフル サービスとステートレス サービス、コンテナーがサポートされます。 ステートフル サービスは、Service Fabric クラスター内のキー値コレクションに永続的にデータを格納する、の信頼できるコレクション を提供します。 Reliable Collection でキーをパーティション分割する方法の詳細については、「azure Service Fabric の Reliable Collection のガイドラインと推奨事項」を参照してください。
次のステップ
Azure Service Fabric の概要は、Azure Service Fabric の概要です。
Partition Service Fabric Reliable Services は、Azure Service Fabric の Reliable Services に関する詳細情報を提供します。
Azure Event Hubs のパーティション分割
Azure Event Hubs は大規模なデータ ストリーミング用に設計されており、パーティション分割はサービスに組み込まれており、水平スケーリングが可能になります。 各コンシューマーは、メッセージ ストリームの特定のパーティションのみを読み取ります。
イベント発行元は、そのパーティション キーのみを認識し、イベントの発行先となるパーティションは認識しません。 このようにキーとパーティションを分離することにより、送信者はダウンストリーム処理について余分な情報を把握しなくてもよくなります。 (特定のパーティションにイベントを直接送信することもできますが、通常は推奨されません)。
パーティション数を選択するときは、長期的なスケールを検討してください。 イベント ハブが作成された後、パーティションの数を変更することはできません。
次のステップ
Event Hubs でのパーティションの使用の詳細については、「Event Hubs とは」を参照してください。.
可用性と整合性のトレードオフに関する考慮事項については、「Event Hubs の可用性と整合性を参照してください。