Azure AI カスタム翻訳ツール モデルをトレーニングする
Azure AI カスタム翻訳ツール モデルにより、特定の言語ペアの翻訳が提供されます。 適切なトレーニングの成果がモデルです。 カスタム モデルをトレーニングするには、互いに重複しない 3 種類のドキュメント (トレーニング、チューニング、テスト) が必要です。 トレーニングをキューに追加するときにトレーニング データのみ入力した場合、チューニングとテストのデータは、カスタム翻訳ツールによって自動的にアセンブルされます。 トレーニング ドキュメントから文のランダムなサブセットが使用され、これらの文はトレーニング データ自体から除外されます。 完全なモデルをトレーニングするには、少なくとも 1 万の並列トレーニングの文章が必要です。
カスタム モデルの作成
[モデルのトレーニング] ブレードを選択します。
[モデル名]を入力します。
既定の [完全トレーニング] を選択するか、[辞書限定トレーニング] を選択します。
注意
完全トレーニングでは、すべてのアップロードされたドキュメントの種類が表示されます。 辞書限定トレーニングでは、辞書のドキュメントのみが表示されます。
[ドキュメントの選択] で、モデルのトレーニングに使用するドキュメント、たとえば
sample-English-Germanを選択し、選択した文の数に関連するトレーニング コストを確認します。[Train now] (今すぐトレーニング) を選択します。
[Train] (トレーニング) を選択して確定します。
注意
[通知] には、[Submitting data] (データを送信中) の状態など、進行中のモデルのトレーニングが表示されます。 モデルのトレーニングには、選択した文の数に応じて数時間かかります。
![[モデルのトレーニング] ブレードを示すスクリーンショット。](../media/quickstart/train-model.png)
辞書限定トレーニングを選択する場合
より良い結果を得るために、トレーニング データを使用してシステムに学習させることをお勧めします。 ただし、最小要件を満たす 1 万の並列文がない場合、または文と複合名詞をそのままでレンダリングする必要がある場合は、辞書限定トレーニングを使用します。 通常、お客様のモデルのトレーニングは、完全なトレーニングより早く完了します。 結果として得られるモデルでは、ユーザーが追加した辞書に加えて、翻訳用のベースライン モデルが使われます。
BLEU のスコアは表示されず、テスト レポートも受け取りません。
Note
カスタム翻訳ツールでは、辞書ファイルで文章の位置合わせが行われません。 そのため、辞書ドキュメントでソースとターゲットに同数の句および文が存在していること、また正確に位置が合わせられていることが重要です。 これが行われていない場合、ドキュメントのアップロードは失敗します。
モデルの詳細
モデルのトレーニングが成功したら、[モデルの詳細] ブレードを選択します。
モデル名を選択して、トレーニングの日付/時刻、トレーニングの合計時間、トレーニング、チューニング、テスト、辞書に使用される文の数、システムによってテストセットとチューニング セットが生成されたかどうかを確認します。 翻訳要求を行うには、
Category IDを使います。モデルの
BLEUスコアを評価します。 テスト セットの確認: BLEU スコアはカスタム モデルのスコアで、ベースライン BLEU はカスタマイズに使用された事前トレーニング済みのベースライン モデルです。 BLEU スコアが高いほど、カスタム モデルを使用した翻訳品質が高くなります。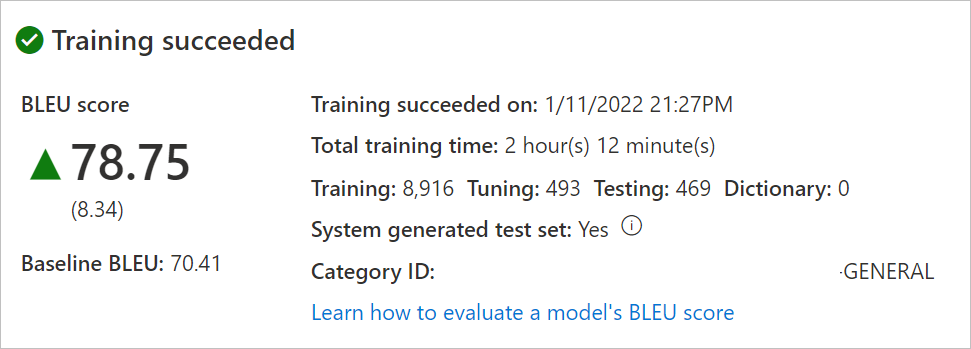
重複するモデル
[モデルの詳細] ブレードを選択します。
モデル名の上にマウス ポインターを置き、[選択] ボタンをオンにします。
[重複] を選択します。
[新しいモデル名] を入力します。
さらにデータを選択またはアップロードしない場合は、[すぐにトレーニング] をオンにします。それ以外の場合は、[下書きとして保存] をオンにします。
保存を選択します
注意
モデルを
Draftとして保存すると、[モデルの詳細] がDraft状態のモデル名で更新されます。ドキュメントをさらに追加するには、モデル名を選んで、「モデルの作成」セクションの手順のようにします。
![[重複するモデル] ブレードを示すスクリーンショット。](../media/how-to/duplicate-model.png)
次の手順
- モデルの品質をテストして評価する方法を学ぶ。
- モデルの公開方法を学ぶ。
- カスタム モデルを使用して翻訳する方法を学ぶ。