カスタム テキスト読み上げアバターを作成する方法
カスタム テキスト読み上げアバターの使用開始は簡単なプロセスです。 必要なものは、アクターのいくつかのビデオ クリップのみです。 同じアクターに対してカスタム音声をトレーニングする場合、別々にそれを行うことができます。
Note
カスタム アバターのアクセスは、資格と使用条件に基づいて制限されます。 入力フォームで アクセスを要求します。
前提条件
カスタム アバターのトレーニングをサポートするリージョンのいずれかに Speech リソースが必要です。 カスタム アバターでは、標準 (S0) Speech リソースのみがサポートされます。
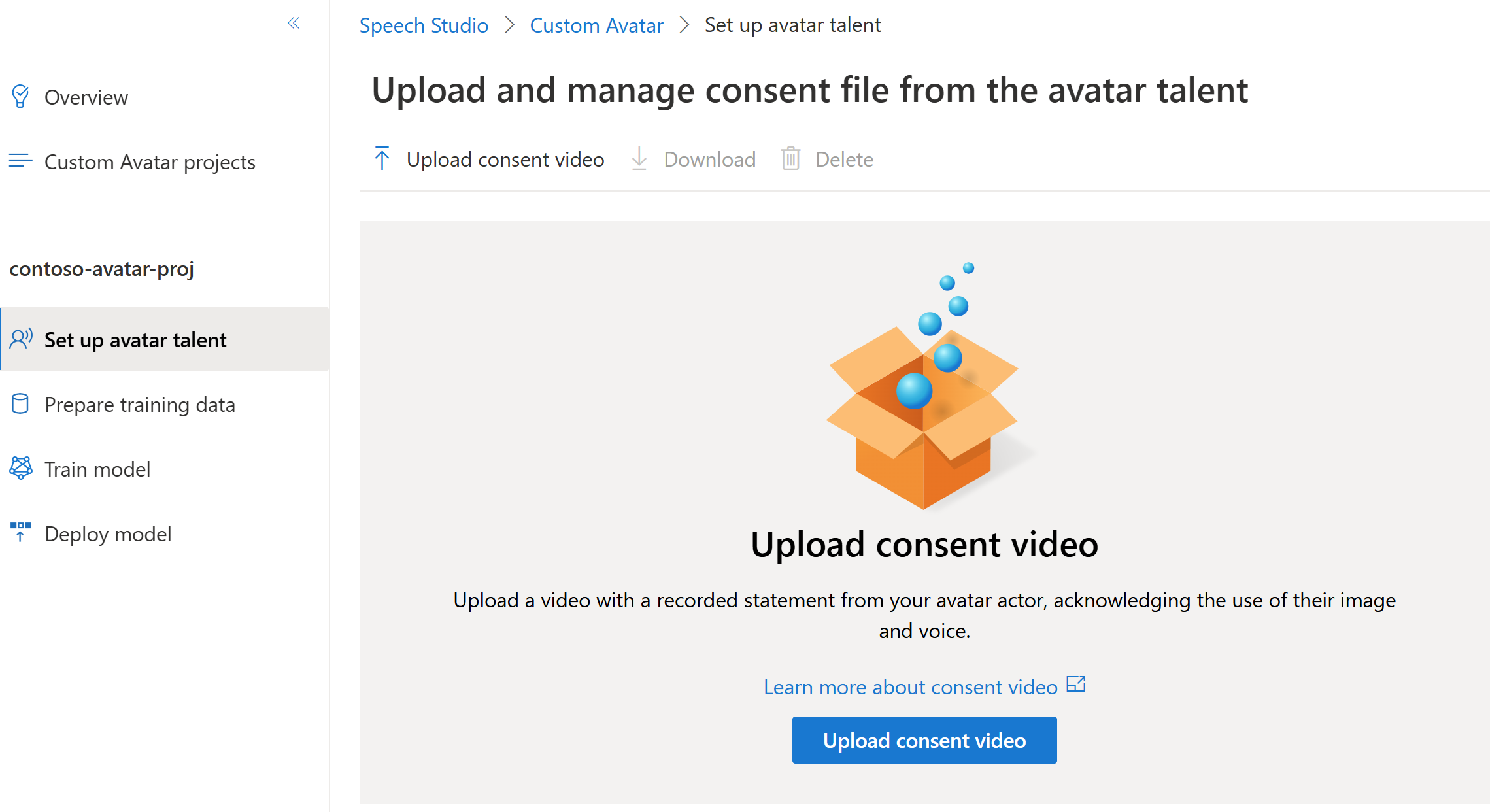
タレントが、自身の画像と音声の使用を認める同意ステートメントを読んでいるビデオ録画が必要です。 このビデオは、アバター タレントを設定するときにアップロードします。 詳細については、「アバター タレントの同意を追加する」を参照してください。
トレーニング データとしてアバター タレントのビデオ録画が必要です。 これらのビデオは、トレーニング データを準備するときにアップロードします。 詳細については、「トレーニング データを追加する」を参照してください。
手順 1: カスタム アバター プロジェクトを作成する
カスタム アバター プロジェクトを作成するには、次の手順に従います。
Speech Studio にサインインし、サブスクリプションと Speech リソースを選択します。
[カスタム アバター] (プレビュー) を選択します。
[+ プロジェクトの作成] を選択します。
ウィザードの手順に従ってプロジェクトを作成します。
ヒント
1 つのプロジェクトで異なるアバターのデータを混在させないでください。 新しいアバターに対しては、常に新しいプロジェクトを作成します。
新しいプロジェクトを名前で選択します すると、左側のパネルには、[アバター タレントの設定]、[トレーニング データの準備]、[モデルのトレーニング]、[モデルのデプロイ] というメニュー項目が表示されます。

手順 2: アバター タレントの同意を追加する
アバター タレントは、スピーキング ビデオがレコーディングされている個人またはターゲット アクターであり、ニューラル アバター モデルの作成に使用されます。 関連するあらゆる法律と規制の下、カスタム テキスト読み上げアバターの作成に動画を使用するための十分な同意をアバター タレントから取得する必要があります。
動画ファイルは、イメージと声の使用を認めるアバター タレントからの声明動画付きで提供する必要があります。 Microsoft は、Microsoft が提供する事前定義済みのスクリプトと記録内のコンテンツが一致することを確認します。 Microsoft は、声明動画ファイルに記録されているアバター タレントの顔と、トレーニング データセットから無作為に選択された動画を比較し、動画のアバター タレントと声明動画ファイルのアバター タレントが同じ人物であることを確認します。
Azure-Samples/cognitive-services-speech-sdk GitHub リポジトリを使用して、複数の言語で音声による同意ステートメントを見つけることができます。 口頭によるステートメントの言語は、録音の言語と同じである必要があります。 「ボイス タレント向けの開示」も参照してください。
同意ビデオのレコーディングに関する詳細については、「ビデオ サンプルをレコーディングする方法」を参照してください。
アバター タレント プロファイルを追加し、同意ステートメントをプロジェクトにアップロードするには、次の手順に従います。
Speech Studio にサインインします。
[カスタム アバター]><プロジェクト名>>[アバター タレントの設定]>[同意ビデオのアップロード] の順に選択します。
[同意ビデオのアップロード] ページで、指示に従って、事前にレコーディングしたアバター タレントの同意ビデオをアップロードします。
- アバター タレントによってレコーディングされた口述の同意ステートメントの会話の言語を選択します。
- アバター タレント名と会社名を、レコーディングされたステートメントと同じ言語で入力します。
- アバター タレント名は、同意ステートメントをレコーディングした人の名前でなければなりません。
- 会社名は、録音されたステートメントで読み上げられた会社名と一致する必要があります。
- データのアップロードを、ローカル ファイルから行うか、または Azure BLOB を使用して共有ストレージから行うかを選択できます。

[アップロード] を選択します。

アバター タレントの同意を問題なくアップロードできたら、カスタム アバター モデルのトレーニングに進むことができます。
手順 3: トレーニング データを追加する
Speech サービスでは、トレーニング データを使用して、レコーディング内の人物の外観に合わせて調整された固有のアバターを作成します。 アバター モデルをトレーニングしたら、アバター ビデオの合成を開始したり、アプリケーション内のライブ チャットに使用したりできます。
アップロードするすべてのデータは、選択したデータの種類の要件を満たしている必要があります。 Speech サービスによってデータが正確に処理されるようにするためには、データをアップロードする前に適切にフォーマットすることが重要です。 データが正しくフォーマットされていることを確認するには、「データの要件」を参照してください。
データをアップロードする
データをアップロードする準備ができたら、[トレーニング データの準備] タブに移動して、データを追加します。
トレーニング データをアップロードするには、次の手順に従います。
Speech Studio にサインインします。
[カスタム アバター]><プロジェクト名>>[トレーニング データの準備]>[データのアップロード] の順に選択します。
![トレーニング データをアップロードするためのボタンがある [トレーニング データの準備] ページのスクリーンショット。](media/custom-avatar/upload-training-data.png)
[データのアップロード] ウィザードで、データ型を選択し、[次へ] を選択します。 データ型 ([自然読み上げ]、[サイレント]、[ジェスチャ]、[状態 0 の発話] など) の詳細については、「レコーディングするビデオ クリップ」を参照してください。
コンピューターからローカル ファイルを選択するか、データが格納されている Azure BLOB ストレージの URL を入力します。
[次へ] を選択します。
アップロードの詳細を確認し、[送信] を選択します。
![トレーニング データをアップロードするためのボタンがある [トレーニング データの準備] ページのスクリーンショット。](media/custom-avatar/upload-training-data.png#lightbox)
[送信] を選択すると、データ ファイルが自動的に検証されます。 データ検証には、ファイル形式、サイズ、合計ボリュームを確認する、ビデオ ファイルの一連のチェックが含まれます。 エラーが見つかった場合は、修正して再度送信します。
データをアップロードしたら、トレーニングを開始するのに十分なデータを提供したかどうかを示すデータの概要を確認できます。 このスクリーンショットは、他のジェスチャなしでアバターをトレーニングするために追加された十分なデータの例を示しています。

手順 4: アバター モデルをトレーニングする
重要
プロジェクト内のすべてのトレーニング データがトレーニングに含まれます。 モデルの品質は、提供したデータに大きく依存しており、ビデオ品質に関する責任はデータの提供者にあります。 「ビデオ サンプル ガイドをレコーディングする方法」に従ってトレーニング ビデオをレコーディングしてください。
Speech Studio でカスタム アバターを作成するには、次のいずれかの方法の次の手順に従います。
Speech Studio にサインインします。
[カスタム アバター]><プロジェクト名>>[モデルのトレーニング]>[モデルのトレーニング] の順に選択します。
モデルを識別しやすい [名前] を入力します。 名前は慎重に選択します。 モデル名は、SDK と SSML 入力を使用した合成要求のアバター名として使用されます。 使用できるのは英字、数字、ハイフン、アンダースコアのみです。 各モデルに一意の名前を使用します。
重要
アバター モデル名は、同一の Speech または AI Services リソース内で一意である必要があります。
モデルのトレーニングを開始するには、トレーニングを選択します。
トレーニング期間は、使用するデータ量によって異なります。 カスタム アバターをトレーニングするには、通常約 20 ~ 40 コンピューティング時間かかります。 トレーニングの課金のしくみについては、「価格に関する注意」を確認してください。
カスタム アバター モデルを別のプロジェクトにコピーする (省略可能)
カスタム アバターのトレーニングは、現在一部のリージョンでのみ使用できます。 サポートされているリージョンでトレーニングが完了したアバター モデルは、必要に応じて別のリージョンの Speech リソースにコピーできます。 詳細については、リージョン テーブルの脚注を参照してください。
カスタム アバター モデルを別のプロジェクトにコピーするには、次のようにします。
- [モデルのトレーニング] タブで、コピーするアバター モデルを選択し、[プロジェクトにコピー] を選択します。
- モデルをコピーするサブスクリプション、リージョン、Speech リソース、プロジェクトを選択します。 ターゲット リージョンに Speech リソースとプロジェクトが存在する必要があります。存在しない場合は、先に作成する必要があります。
- [送信] を選択してモデルをコピーします。
モデルのコピーが完了すると、Speech Studio に通知が表示されます。
モデルのコピーをデプロイするためにモデルをコピーしたプロジェクトに移動します。
手順 5: アバター モデルをデプロイして使用する
アバター モデルを正常に作成してトレーニングしたら、それをエンドポイントにデプロイします。
アバターをデプロイするには次のようにします。
- Speech Studio にサインインします。
- [カスタム アバター]><プロジェクト名>>[モデルのデプロイ] の順に選択します。
- [モデルのデプロイ] を選択し、デプロイするモデルを選択します。
-
[デプロイ] を選んで、デプロイを始めます。
重要
モデルがデプロイされると、当該エンドポイントとのやり取りの有無に関わらず、エンドポイントの継続的なアップタイムに対して料金が発生します。 モデルのデプロイの課金のしくみについては、価格に関する注意を確認してください。 モデルが使用されていないときにはデプロイを削除することで、支出を削減し、リソースを節約できます。
カスタム アバターをデプロイすると、Speech Studio または API で使用できるようになります。
- アバターは、Speech Studio のテキスト読み上げアバターのアバター リストに表示されます。
- アバターは、Speech Studio のライブ チャット アバターのアバター リストに表示されます。
- アバター モデル名を指定することで、SDK および SSML 入力からアバターを呼び出すことができます。 詳細については、「アバターのプロパティ」を参照してください。
デプロイの削除
デプロイを削除するには、次の手順に従います。
- Speech Studio にサインインします。
- [カスタム アバター]><プロジェクト名>>[モデルのデプロイ] の順に移動します。
- [モデルのデプロイ] ページでデプロイを選択します。 ステータスが "Succeeded" の場合、モデルはアクティブにホストされています。
- [デプロイの削除] ボタンを選択し、削除を確認してホスティングを削除できます。
ヒント
デプロイが削除されると、そのホスティングに対する支払いはなくなります。 デプロイを削除しても、モデルが削除されることはありません。 モデルを再度使用する場合は、新しいデプロイを作成します。
カスタム音声を使用する (省略可能)
アクター用にカスタム ニューラル音声 (CNV) も作成することで、アバターは非常に写実的になります。 詳細については、「カスタム テキスト読み上げアバターとは」を参照してください。
カスタム音声とカスタム テキスト読み上げアバターは、個別の機能です。 これらを個別に使用することも、一緒に使用することもできます。
カスタム音声を作成し、それをカスタム アバターと使用する場合は、次の点に注意してください。
- カスタム音声エンドポイントがカスタム アバター エンドポイントと同じ Speech リソースに作成されていることを確認します。 必要に応じて、「プロフェッショナル音声モデルをトレーニングする」を参照して、カスタム音声モデルをカスタム アバター エンドポイントと同一の Speech リソースにコピーします。
- カスタム音声オプションは、[アバター コンテンツ生成ページ] と、[ライブ チャットの音声設定] の音声一覧に表示されます。
- アバター API のバッチ合成を使用している場合は、
"customVoices"プロパティを追加して、カスタム音声モデルのデプロイ ID を要求の音声名に関連付けます。 詳細については、「テキスト読み上げプロパティ」を参照してください。 - アバター API にリアルタイム合成を使用している場合は、GitHub のサンプル コードを参照して、カスタム音声を設定してください。