チュートリアル:Azure Notebook で Personalizer を使用する
重要
2023 年 9 月 20 日以降は、新しい Personalizer リソースを作成できなくなります。 Personalizer サービスは、2026 年 10 月 1 日に廃止されます。
このチュートリアルでは、Azure Notebook で Personalizer ループを実行し、Personalizer ループのエンド ツー エンドのライフ サイクルを示します。
このループでは、顧客が注文すべきコーヒーの種類が提案されます。 ユーザーとその好みはユーザー データセットに格納されます。 コーヒーに関する情報はコーヒー データセットに格納されます。
ユーザーとコーヒー
このノートブックは、ユーザーが Web サイトで行う対話操作をシミュレートし、データセットからランダムなユーザー、時間帯、天気の種類を選択します。 ユーザー情報の概要は次のとおりです。
| 顧客 - コンテキストの特徴 | 時間帯 | 天気の種類 |
|---|---|---|
| Alice Bob Cathy Dave |
朝 午後 夜 |
晴れ 雨 雪 |
Personalizer が時間の経過と共に学習できるよう、この "システム" は各人物のコーヒーの選択に関する情報も把握しています。
| コーヒー - アクションの特徴 | temperature の種類 | 原産地 | 焙煎の種類 | オーガニック |
|---|---|---|---|---|
| カプチーノ | ホット | ケニア | ダーク | オーガニック |
| コールド ブリュー | アイス | ブラジル | 浅煎り | オーガニック |
| アイス モカ | アイス | エチオピア | 浅煎り | オーガニックでない |
| ラテ | ホット | ブラジル | ダーク | オーガニックでない |
Personalizer ループの目的は、できるだけ多くの場合にユーザーと最も相性の良いコーヒーを見つけることです。
このチュートリアルのコードは、Personalizer Samples GitHub リポジトリで入手できます。
シミュレーションの動作
実行中のシステムの開始時点では、Personalizer からの提案がうまくいくのはたった 20% から 30% です。 この成功は、Personalizer Reward API に返される報酬 (スコアは 1) によって示されます。 いくつかの Rank と Reward の呼び出しの後、システムは改善されます。
最初の要求の後、オフライン評価を実行します。 これにより、Personalizer はデータを確認し、より適切な学習ポリシーを提案することができます。 新しい学習ポリシーを適用し、前の要求数の 20% を指定してこのノートブックを再実行します。 新しい学習ポリシーにより、このループのパフォーマンスは向上します。
Rank と Reward の呼び出し
Personalizer サービスに対するこの数千もの呼び出しそれぞれでは、Azure Notebook が REST API に Rank 要求を送信します。
- Rank または Request イベントの一意の ID
- コンテキスト機能 - ランダムに選択したユーザー、天気、時間帯。Web サイトまたはモバイル デバイスでユーザーをシミュレーションします。
- アクションと特徴 - Personalizer が提案する際に基づく "すべて" のコーヒー データ
このシステムでは、要求を受け取った後、その予測内容と、時間帯と天気が同じ場合のユーザーによる既知の選択を比較します。 既知の選択が予測した選択と同じ場合は、Reward 1 が Personalizer に送り返されます。 それ以外の場合は、送り返される報酬が 0 になります。
Note
これはシミュレーションであるため、報酬のアルゴリズムはシンプルです。 実際のシナリオでは、このアルゴリズムは、報酬スコアを決定するためにビジネス ロジックを使用する必要があります (場合によっては、顧客の経験のさまざまな側面に対する重みが使用されます)。
前提条件
- Azure Notebook アカウント。
- Azure AI Personalizer リソース。
- Personalizer リソースを既に使用している場合は、必ず Azure portal でそのリソースのデータをクリアしてください。
- このサンプルのファイルすべてを Azure Notebook プロジェクトにアップロードします。
ファイルの説明:
- Personalizer.ipynb は、このチュートリアル用の Jupyter ノートブックです。
- ユーザー データセットは、JSON オブジェクトに格納されます。
- コーヒー データセットは、JSON オブジェクトに格納されます。
- 要求例の JSON は、Rank API に対する POST 要求に必要な形式です。
Personalizer リソースを構成する
Azure portal で、[モデルの更新頻度] が 15 秒に設定され、[報酬の待機時間] が 10 秒に設定された Personalizer リソースを構成します。 これらの値は、 [構成] ページで確認できます。
| 設定 | 値 |
|---|---|
| モデルの更新頻度 | 15 秒 |
| 報酬の待機時間 | 10 分 |
このチュートリアルでは、変化を示すために、これらの値には非常に短い期間が設定されています。 これらの値は、Personalizer ループで目標を達成することを確認できない場合、運用環境のシナリオで使用しないでください。
Azure Notebook を設定する
- カーネルを
Python 3.6に変更します。 Personalizer.ipynbファイルを開きます。
Notebook セルを実行する
実行可能な各セルを実行し、制御が返されるまで待ちます。 これは、セルの横にある角かっこに * ではなく数値が表示されると実行されることがわかります。 以降のセクションでは、各セルがプログラムで実行する内容と出力に期待する内容について説明します。
Python モジュールを含める
必要な Python モジュールを含めます。 このセルには出力がありません。
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Personalizer リソースのキーと名前を設定する
Azure portal で、お使いの Personalizer リソースの [クイックスタート] ページでキーとエンドポイントを確認します。 <your-resource-name> の値を実際の Personalizer リソースの名前に変更します。 <your-resource-key> の値を実際の Personalizer のキーに変更します。
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
現在の日付と時刻を出力する
この関数を使用して、反復関数の繰り返しの開始時刻と終了時刻を記録します。
これらのセルには出力がありません。 この関数は、呼び出されたときに現在の日時を出力します。
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
前回のモデル更新時刻を取得する
get_last_updated 関数は呼び出されると、モデルが更新された最終更新日時を出力します。
これらのセルには出力がありません。 この関数は、呼び出されたときに、前回モデルをトレーニングした日付を出力します。
この関数では、GET REST API を使用して、モデルのプロパティを取得します。
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
ポリシーとサービスの構成を取得する
次の 2 つの REST 呼び出しを使用して、サービスの状態を確認します。
これらのセルには出力がありません。 この関数は、呼び出されたときに、サービス設定を出力します。
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
URL を構築して JSON データ ファイルを読み取る
このセルは次を実行します。
- REST 呼び出しで使用される URL を構築する
- Personalizer リソースのキーを使用してセキュリティ ヘッダーを設定する
- Rank イベント ID のランダム シードを設定する
- JSON データ ファイルで読み取る
get_last_updatedメソッドを呼び出す (出力例では、学習ポリシーが削除されています)get_service_settingsメソッドを呼び出す
このセルには、get_last_updated および get_service_settings 関数の呼び出しからの出力が含まれます。
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
出力の rewardWaitTime が 10 分に設定されており、modelExportFrequency が 15 秒に設定されていることを確認します。
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
最初の REST 呼び出しのトラブルシューティングを行う
この前のセルは、Personalizer を呼び出す最初のセルです。 出力内の REST の状態コードが <Response [200]> であることを確認します。 404 などのエラーが表示されても、お使いのリソースのキーと名前が正しいことがわかっている場合は、このノートブックを再度読み込んでください。
コーヒーとユーザーの数がどちらも 4 であることを確認します。 エラーが発生した場合は、3 つの JSON ファイルをすべてアップロードしたことを確認してください。
Azure portal でメトリック グラフを設定する
このチュートリアルの後半では、10,000 件の要求の実行時間が長いプロセスを、更新するテキスト ボックスを使用してブラウザーに表示できます。 実行時間の長いプロセスが終了すると、グラフまたは合計で見やすくなる場合があります。 この情報を表示するには、このリソースで提供されているメトリックを使用します。 これで、サービスへの要求を完了したグラフを作成し、実行時間の長いプロセスの進行中にそのグラフを定期的に更新できるようになりました。
Azure portal で、お使いの Personalizer リソースを選択します。
リソースのナビゲーションで、[監視] の下にある [メトリック] を選択します。
グラフで、 [メトリックの追加] を選択します。
リソースとメトリックの名前空間は既に設定されています。 必要なのは、メトリックに [成功した呼び出し] 、集計に [合計] を選択することだけです。
時間フィルターを直近 4 時間に変更します。
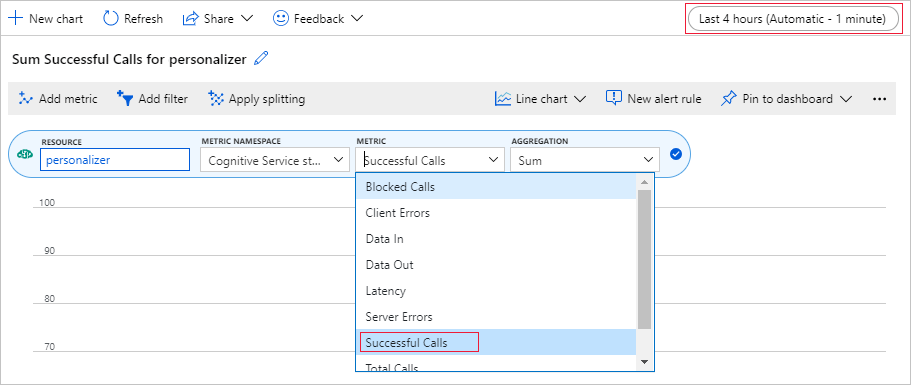
このグラフには、成功した呼び出しが 3 件表示されるはずです。
一意のイベント ID を生成する
この関数は、各ランク呼び出しに一意の ID を生成します。 この ID は、ランクと報酬の呼び出しに関する情報を識別するために使用されます。 この値は、Web ビュー ID やトランザクション ID など、ビジネス プロセスから生成される場合があります。
このセルには出力がありません。 この関数は、呼び出されたときに、一意の ID を出力します。
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
ランダムなユーザー、天気、時間帯を取得する
この関数は、一意のユーザー、天気、および時間帯を選択した後、ランク要求に送信する JSON オブジェクトにそれらの項目を追加します。
このセルには出力がありません。 この関数が呼び出されると、ランダムなユーザーの名前、ランダムな天気、ランダムな時間帯が返されます。
4 人のユーザーと彼らの好みのリストです。簡潔にするために、好みは一部しか表示されていません。
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
コーヒー データをすべて追加する
この関数は、ランク要求に送信する JSON オブジェクトにすべてのコーヒーのリストを追加します。
このセルには出力がありません。 この関数は、呼び出されたときに、rankjsonobj を変更します。
1 つのコーヒーの特徴の例を次に示します。
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
予測を既知のユーザーの好みと比較する
この関数は、反復するたびに、Rank API が呼び出された後に呼び出されます。
この関数は、天気と時間帯に基づくユーザーのコーヒーの好みを、Personalizer がこれらのフィルターに関してそのユーザーに提案する内容と比較します。 提案が一致した場合はスコア 1 が返され、それ以外の場合はスコアが 0 になります。 このセルには出力がありません。 この関数は、呼び出されたときに、スコアを出力します。
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
Rank と Reward の呼び出しをループ処理する
次のセルは、Notebook の "主な" 処理で、ランダムなユーザーを取得し、コーヒー リストを取得して、その両方を Rank API に送信します。 予測をユーザーの既知の好みと比較した後、その報酬を Personalizer サービスに返します。
このループは、num_requests の回数だけ実行されます。 Personalizer では、モデルを作成するために、Rank と Reward の呼び出しが数千回必要です。
Rank API に送信される JSON の例を次に示します。 簡潔にするため、コーヒーのリストは一部のみです。 コーヒーに関する JSON 全体は、coffee.json で確認できます。
Rank API に送信される JSON:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
Rank API からの JSON 応答:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
最後に、各ループでは、ランダムに選択されたユーザー、天気、時間帯、および決定した報酬が表示されます。 報酬が 1 の場合は、Personalizer リソースによって、特定のユーザー、天気、時間帯に適切なコーヒーの種類が選択されたことを示します。
1 Alice Rainy Morning Latte 1
この関数では、以下を使用します。
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
10,000 回の反復に対して実行する
10,000 回の反復処理に対して Personalizer ループを実行します。 これは、実行時間の長いイベントです。 ノートブックを実行しているブラウザーを閉じないでください。 Azure portal のメトリック グラフを定期的に更新して、サービスに対する呼び出しの合計を確認します。 約 20,000 万件の呼び出し (ループを反復するたびにランクと報酬の呼び出しが 1 回) がある場合は、反復処理が行われます。
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
結果をグラフにして改善点を確認する
count と rewards からグラフを作成します。
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
10,000 件のランク要求のグラフを実行する
createChart 関数を実行します。
createChart(count,rewards)
グラフを読み取る
このグラフには、現在の既定の学習ポリシーのモデルが成功したことが示されています。

理想的な目標は、テストが終了するまでに、このループの平均成功率が 100% から探索を差し引いた割合に近くなることです。 探索の既定値は 20% です。
100-20=80
この探索値は、Azure portal の Personalizer リソースの [構成] ページで確認できます。
より適切な学習ポリシーを見つけるには、Rank API へのデータに基づいて、ポータルで Personalizer ループに対してオフライン評価を実行します。
オフライン評価を実行する
Azure portal で、Personalizer リソースの [評価] ページを開きます。
[評価の作成] を選択します。
評価名に必要なデータ、ループ評価の日付範囲を入力します。 この日付範囲には、評価の対象とする日のみを含める必要があります。
![Azure portal で、Personalizer リソースの [評価] ページを開きます。 [評価の作成] を選択します。 評価名と日付範囲を入力します。](media/tutorial-azure-notebook/create-offline-evaluation.png)
このオフライン評価を実行する目的は、このループで使用される特徴とアクションにより適切な学習ポリシーがあるかどうかを判断することです。 より適切な学習ポリシーを見つけるには、 [最適化の検出] が有効になっていることを確認します。
[OK] を選択して、評価を開始します。
この [評価] ページに、新しい評価とその現在の状態が表示されます。 使用しているデータの量に応じて、この評価には時間がかかる場合があります。 数分後にこのページに戻ると、結果を確認できます。
評価が完了したら、この評価を選択し、 [さまざまな学習ポリシーの比較] を選択します。 これで、利用可能な学習ポリシーと、それらがデータによってどのように動作するかが示されます。
テーブルの最上位の学習ポリシーを選択し、 [適用] を選択します。 これにより、"最適な" 学習ポリシーがモデルに適用され、再トレーニングが行われます。
モデルの更新頻度を 5 分に変更する
- Azure portal で、引き続き Personalizer リソースで [構成] ページを選択します。
- [モデルの更新頻度] と [報酬の待機時間] を 5 分に変更し、 [保存] を選択します。
#Verify new learning policy and times
get_service_settings()
出力の rewardWaitTime と modelExportFrequency の両方が 5 分に設定されていることを確認します。
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
新しい学習ポリシーを確認する
Azure Notebooks ファイルに戻り、同じループ (ただし、反復処理は 2,000 回のみ) を実行して続行します。 Azure portal のメトリック グラフを定期的に更新して、サービスに対する呼び出しの合計を確認します。 約 4,000 万件の呼び出し (ループを反復するたびにランクと報酬の呼び出しが 1 回) がある場合は、反復処理が行われます。
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
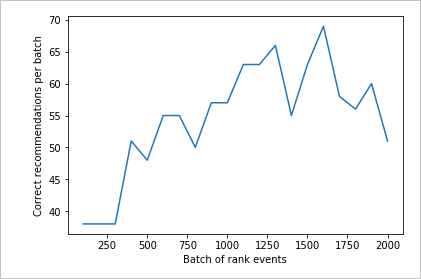
2,000 件のランク要求のグラフを実行する
createChart 関数を実行します。
createChart(count2,rewards2)
2 つ目のグラフを確認する
2 つ目のグラフでは、ユーザーの好みに合ったランクの予測が明らかに増加していることが示されます。
リソースをクリーンアップする
このチュートリアル シリーズを続行しない場合は、次のリソースをクリーンアップしてください。
- Azure Notebook プロジェクトを削除します。
- Personalizer リソースを削除します。
次のステップ
このサンプルで使用されている Jupyter ノートブックとデータ ファイルは、Personalizer 向けの GitHub リポジトリで入手できます。