Language Studio でデータにラベルを付ける
モデルをトレーニングする前に、抽出するカスタム エンティティでドキュメントにラベルを付ける必要があります。 データのラベル付けは、開発ライフサイクルにおける重要なステップです。 このステップでは、データから抽出するエンティティ型を作成し、ドキュメント内でこれらのエンティティにラベルを付けることができます。 このデータは次のステップで使用され、ラベル付けされたデータから学習できるようにモデルをトレーニングします。 データが既にラベル付けされている場合は、プロジェクトに直接インポートできますが、データが、許容されるデータ形式に従っていることを確認する必要があります。 ラベル付けされたデータをプロジェクトにインポートする方法の詳細については、「プロジェクトの作成」を参照してください。
カスタム NER モデルを作成する前に、まずラベル付けされたデータが必要です。 データがまだラベル付けされていない場合は、Language Studio でラベルを付けることができます。 ラベル付けされたデータは、テキストの解釈方法をモデルに示し、トレーニングと評価に使用されます。
前提条件
データにラベルを付けるには、以下が必要です。
- 構成済みの Azure Blob Storage アカウントで正常に作成されたプロジェクト
- ストレージ アカウントにアップロードされたテキスト データ。
詳細については、「プロジェクト開発ライフサイクル」を参照してください。
データのラベル付けガイドライン
データを準備し、スキーマを設計し、プロジェクトを作成した後、データにラベルを付ける必要があります。 データのラベル付けは、抽出する必要のあるエンティティ型に関連する単語をモデルから認識できるようにするために重要です。 Language Studio でデータにラベルを付ける (またはラベル付きデータをインポートする) と、これらのラベルは、このプロジェクトに接続したストレージ コンテナーの JSON ドキュメントに格納されます。
データにラベルを付けるときは、次のことに注意してください。
一般に、データが正確にラベル付けされていれば、ラベル付けされたデータが多いほど良い結果が得られます。
ラベル付けされたデータの正確性、一貫性、完全性が、モデルのパフォーマンスを決定する重要な要因です。
- 正確なラベル付け: 各エンティティを適切な型に常にラベル付けします。 ラベルには、抽出するデータのみを含め、不要なデータを入れないでください。
- 一貫したラベル付け: すべてのドキュメントで、同じエンティティに同じラベルが付いているようにします。
- 完全なラベル付け: すべてのドキュメントに含まれるエンティティのすべてのインスタンスにラベルを付けます。 自動ラベル付け機能を使用して、完全なラベル付けを保証できます。
注意
ご自分のモデルが最高のパフォーマンスを発揮することを保証できる決まったラベルの数はありません。 モデルのパフォーマンスは、スキーマで生じる可能性があるあいまいさと、ラベル付けされたデータの品質に依存します。 それでも、エンティティ型ごとに約 50 個のラベル付きインスタンスを用意することをお勧めします。
データにラベルを付ける
次の手順に従って、データにラベルを付けます。
Language Studio でプロジェクトのページに移動します。
左側のメニューから、[データのラベル付け] を選択します。 ストレージ コンテナー内のすべてのドキュメントのリストを見つけることができます。
ヒント
上部のメニューのフィルターを使用して、ラベル付けされていないドキュメントを表示し、ラベル付けを開始できます。 フィルターを使用して、特定のエンティティ型でラベル付けされているドキュメントを表示することもできます。
上部のメニューの左側から単一のドキュメント ビューに変更するか、ラベル付けを開始する特定のドキュメントを選択します。 左側で、プロジェクトで使用できるすべての
.txtドキュメントのリストを確認できます。 ページの下部にある[戻る] と[次へ] のボタンを使用して、ドキュメント間を移動できます。注意
プロジェクトで複数の言語を有効にした場合は、上部のメニューに [言語] ドロップダウンがあり、ドキュメントごとに言語を選択できます。
右側のペインで、プロジェクトにエンティティ型を追加して、データのラベル付けを開始できるようにします。
ドキュメントにラベルを付けるには、2 つのオプションがあります。
オプション 説明 ブラシを使ってラベルを付ける 右側のペインでエンティティ型の横にあるブラシ アイコンを選択し、ドキュメント内で、このエンティティ型で注釈を付けるテキストを強調表示します。 メニューを使ってラベルを付ける エンティティとしてラベルを付ける単語を強調表示すると、メニューが表示されます。 このエンティティに割り当てるエンティティ型を選択します。 次のスクリーンショットは、ブラシを使ったラベル付けを示したものです。
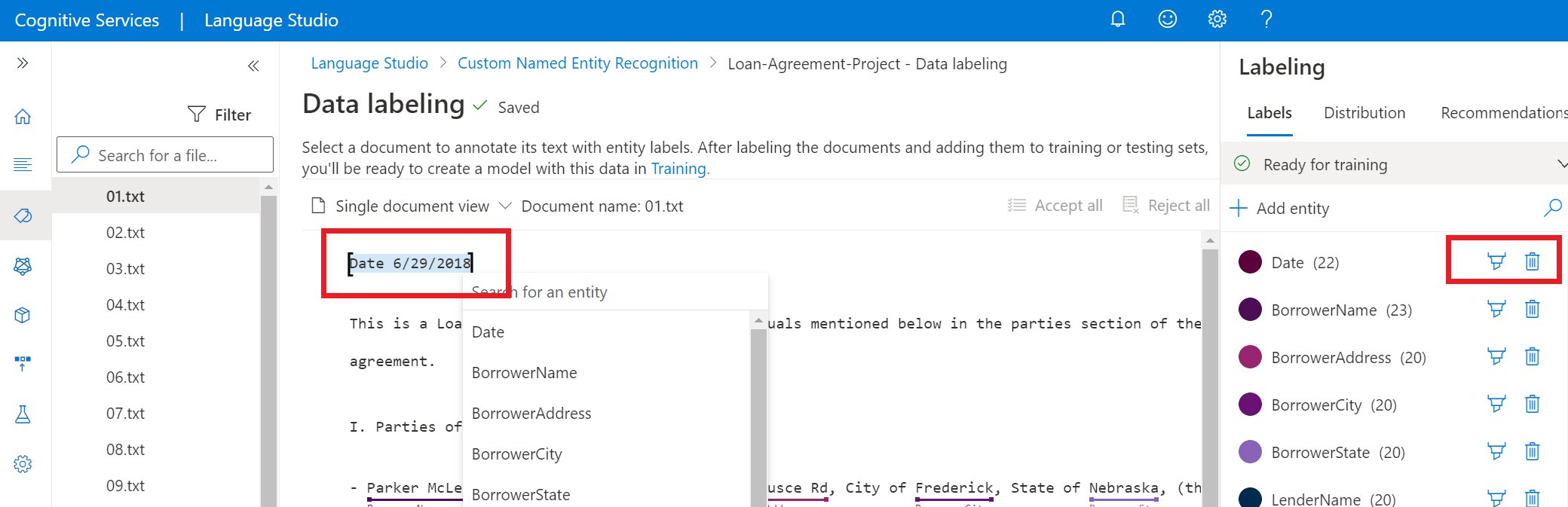
右側のペインの [ラベル] ピボットで、プロジェクト内のすべてのエンティティ型と、それぞれのラベル付きインスタンスの数を確認できます。
右側のペインの下部セクションで、表示している現在のドキュメントをトレーニング用セットまたはテスト用セットに追加できます。 既定では、すべてのドキュメントがトレーニング セットに追加されます。 トレーニング用セットとテスト用セットの詳細と、モデルのトレーニングと評価に使用される方法について説明します。
ヒント
自動データ分割の使用を計画している場合は、すべてのドキュメントをトレーニング用セットに割り当てる既定のオプションを使用します。
[分布] ピボットの下で、トレーニング用セットとテスト用セット全体の分布を表示できます。 表示には、2 つのオプションがあります。
- "インスタンスの合計数"。特定のエンティティの種類のすべてのラベル付きインスタンスの数を表示できます。
- "少なくとも 1 つのラベルが付いたドキュメント"。このエンティティのラベル付きインスタンスが少なくとも 1 つ含まれている場合、各ドキュメントがカウントされます。
ラベルを付けているとき、変更は定期的に同期され、まだ保存していない場合は、ページの上部に警告が表示されます。 手動で保存する場合は、ページの下部にある [ラベルの保存] ボタンを選択します。

ラベルを削除する
ラベルを削除するには、次のようにします。
- ラベルを削除するエンティティを選択します。
- 表示されるメニューをスクロールして、[ラベルの削除] を選択します。
エンティティの削除
エンティティを削除するには、削除するエンティティの横にある削除アイコンを選択します。 エンティティを削除すると、すべてのラベル付きインスタンスがデータセットから削除されます。
次の手順
データのラベル付けが完了したら、データに基づいて学習するモデルのトレーニングを始めることができます。