Document Intelligence 読み取りモデル
このコンテンツの適用対象:![]() v4.0 (GA) | 以前のバージョン:
v4.0 (GA) | 以前のバージョン:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Note
ラベル、道路標識、ポスターなどの外部画像からテキストを抽出するには、パフォーマンスが向上した同期 API を使用して、一般的な (ドキュメント以外の) 画像用に最適化された Azure AI Image Analysis v4.0 読み取り機能を使用します。 この機能により、リアルタイムのユーザー エクスペリエンス シナリオに OCR を簡単に埋め込むことができます。
Document Intelligence の読み取り光学式文字認識 (OCR) モデルは、Azure AI Vision の読み取りよりも高解像度で動作し、PDF ドキュメントやスキャン画像から印刷テキストや手書きテキストを抽出します。 また、Microsoft Word、Excel、PowerPoint、HTML ドキュメントからテキストを抽出するためのサポートも含まれています。 段落、テキスト行、単語、場所、言語が検出されます。 この読み取りモデルは、カスタム モデルに加えて、レイアウト、一般ドキュメント、請求書、領収書、身分証明書 (ID)、医療保険カード、W2 など、他の Document Intelligence 事前構築済みモデルの基になる OCR エンジンです。
光学式文字認識とは
ドキュメントの光学式文字認識 (OCR) は、複数のファイル形式とグローバル言語の大きなテキスト負荷の高いドキュメントに最適化されています。 これには、ドキュメント画像の高解像度スキャンによる小さな文字や密集した文字の優れた処理、段落検出、入力可能なフォーム管理などの機能が含まれています。 OCR 機能には、1 文字のボックスや、請求書、領収書、その他の事前構築済みのシナリオでよく見られるキー フィールドの正確な抽出などの高度なシナリオも含まれます。
開発オプション (v4)
Document Intelligence v4.0: 2024-11-30 (GA) は、次のツール、アプリケーション、ライブラリをサポートします:
| 機能 | リソース | モデル ID |
|---|---|---|
| OCR 読み取りモデル | • ドキュメントインテリジェンススタジオ • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
入力の要件 (v4)
サポートされているファイル形式:
| モデル | 画像: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Microsoft Office: Word ( DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML |
|
|---|---|---|---|
| 読み込み | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| 一般的なドキュメント | ✔ | ✔ | |
| 事前構築済み | ✔ | ✔ | |
| カスタム抽出 | ✔ | ✔ | |
| カスタム分類 | ✔ | ✔ | ✔ |
最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
PDF および TIFF の場合、最大 2,000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは
4MB です。画像のディメンションは、50 ピクセル x 50 ピクセルから 10,000 ピクセル x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、150 DPI (1 インチあたりのドット数) で約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は
1GB です。カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GB で、最大 10,000 ページです。 2024-11-30 (GA) の場合、トレーニング データの合計サイズは2GB で、最大 10,000 ページです。
Read モデルの概要 (v4)
Document Intelligence Studio を使用して、フォームやドキュメントからテキストを抽出してみてください。 次の資産が必要になります。
Azure サブスクリプション - 無料で作成できます。
Azure portal の Document Intelligence Studio インスタンス。 Free 価格レベル (
F0) を利用して、サービスを試用できます。 リソースがデプロイされたら、[リソースに移動] を選択してキーとエンドポイントを取得します。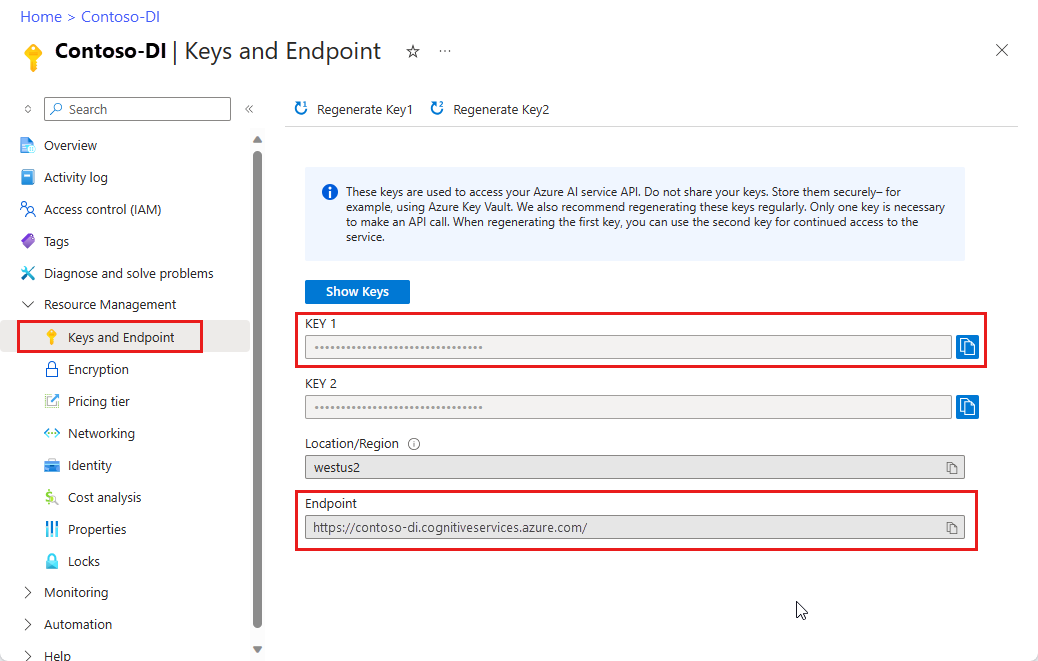
Note
現在、Document Intelligence Studio では、Microsoft Word、Excel、PowerPoint、HTML のファイル形式はサポートされていません。
"Document Intelligence Studio で処理されたサンプル ドキュメント"
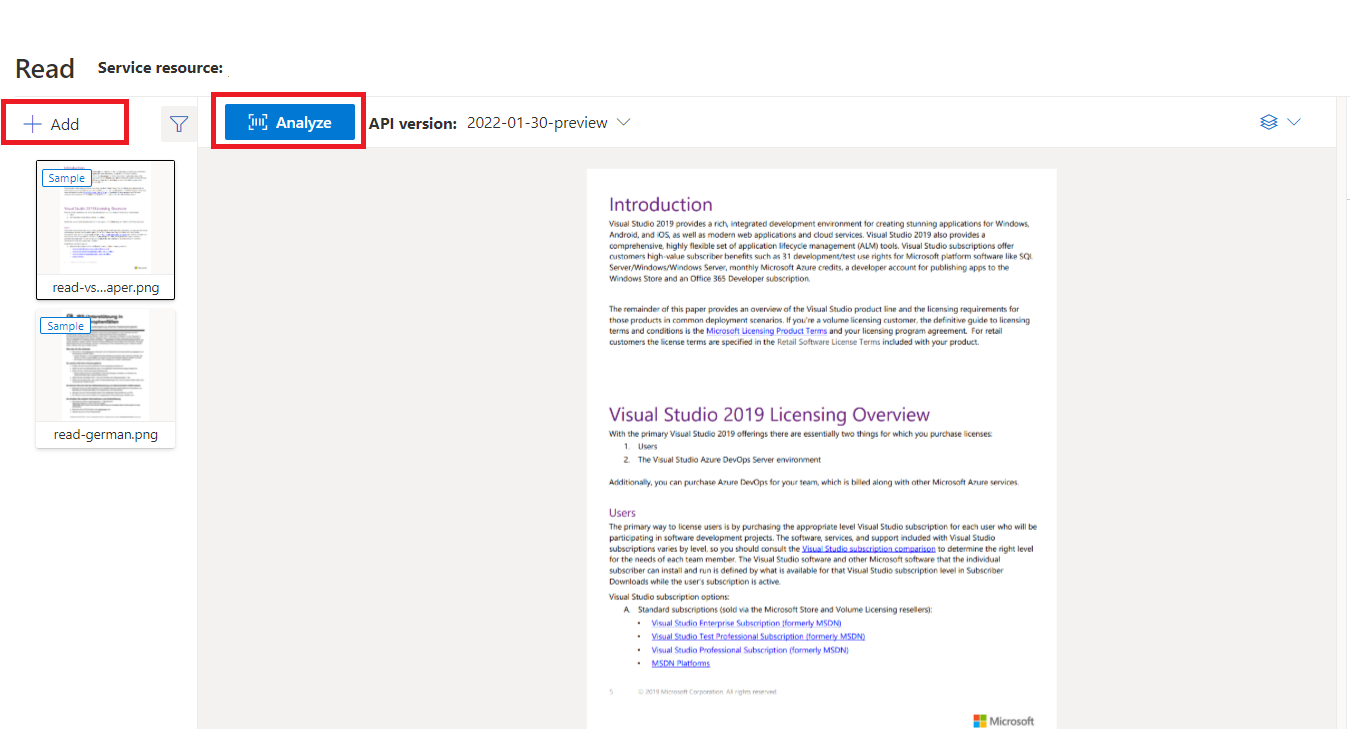
Document Intelligence Studio ホーム ページで、[読み取り] を選択します。
サンプル ドキュメントを分析したり、独自のファイルをアップロードしたりできます。
[分析の実行] ボタンを選択し、必要に応じて [分析オプション] を構成します。
![Document Intelligence Studio の [分析の実行] と [分析オプション] ボタンのスクリーンショット。](../media/studio/run-analysis-analyze-options.png?view=doc-intel-4.0.0)
サポートされている言語とロケール (v4)
サポートされている言語の完全なリストについては、言語サポート - ドキュメント解析モデルのページを参照してください。
データの抽出 (v4)
Note
Microsoft Word および HTML ファイルは、v4.0 でサポートされています。 次の機能は現在、サポートされていません。
- 各ページ オブジェクトの角度、幅と高さ、単位は返されません。
- 検出される各オブジェクトには、境界多角形も境界領域もありません。
- ページ範囲 (
pages) はパラメーターとして返されません。 -
linesオブジェクトはありません。
検索可能な PDF
検索可能な PDF 機能を使用すると、スキャン画像の PDF ファイルなどのアナログ PDF をテキストが埋め込まれた PDF に変換できます。 埋め込みテキストにして、検出されたテキスト エンティティを画像ファイルの上にオーバーレイすることで、PDF の抽出されたコンテンツ内でディープ テキスト検索を実行できるようになります。
重要
- 現時点では、読み取り OCR モデル
prebuilt-readのみが検索可能な PDF 機能をサポートしています。 この機能を使用する場合は、modelIdをprebuilt-readとして指定してください。 このプレビュー バージョンの他のモデルの種類では、エラーが返されます。 - 検索可能な PDF は
2024-11-30GAprebuilt-readモデルに含まれており、検索可能な PDF 出力の生成に追加コストはかかりません。
検索可能な PDF を使用する
検索可能な PDF を使用するには、Analyze 操作を使用して POST 要求を作成し、出力形式を pdf と指定します。
POST {endpoint}/documentintelligence/documentModels/prebuilt-read:analyze?_overload=analyzeDocument&api-version=2024-11-30&output=pdf
{...}
202
Analyze 操作の完了をポーリングします。 操作が完了したら、GET 要求を発行して、PDF 形式の Analyze 操作結果を取得します。
正常に完了すると、PDF を取得して application/pdf としてダウンロードできます。 この操作により、Base64 でエンコードされた JSON ではなく、埋め込みテキスト形式の PDF を直接ダウンロードできます。
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET {endpoint}/documentintelligence/documentModels/prebuilt-read/analyzeResults/{resultId}/pdf?api-version=2024-11-30
URI Parameters
Name In Required Type Description
endpoint path True
string
uri
The Document Intelligence service endpoint.
modelId path True
string
Unique document model name.
Regex pattern: ^[a-zA-Z0-9][a-zA-Z0-9._~-]{1,63}$
resultId path True
string
uuid
Analyze operation result ID.
api-version query True
string
The API version to use for this operation.
Responses
Name Type Description
200 OK
file
The request has succeeded.
Media Types: "application/pdf", "application/json"
Other Status Codes
DocumentIntelligenceErrorResponse
An unexpected error response.
Media Types: "application/pdf", "application/json"
Security
Ocp-Apim-Subscription-Key
Type: apiKey
In: header
OAuth2Auth
Type: oauth2
Flow: accessCode
Authorization URL: https://login.microsoftonline.com/common/oauth2/authorize
Token URL: https://login.microsoftonline.com/common/oauth2/token
Scopes
Name Description
https://cognitiveservices.azure.com/.default
Examples
Get Analyze Document Result PDF
Sample request
HTTP
HTTP
Copy
GET https://myendpoint.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-invoice/analyzeResults/3b31320d-8bab-4f88-b19c-2322a7f11034/pdf?api-version=2024-11-30
Sample response
Status code:
200
JSON
Copy
"{pdfBinary}"
Definitions
Name Description
DocumentIntelligenceError
The error object.
DocumentIntelligenceErrorResponse
Error response object.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
DocumentIntelligenceError
The error object.
Name Type Description
code
string
One of a server-defined set of error codes.
details
DocumentIntelligenceError[]
An array of details about specific errors that led to this reported error.
innererror
DocumentIntelligenceInnerError
An object containing more specific information than the current object about the error.
message
string
A human-readable representation of the error.
target
string
The target of the error.
DocumentIntelligenceErrorResponse
Error response object.
Name Type Description
error
DocumentIntelligenceError
Error info.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
Name Type Description
code
string
One of a server-defined set of error codes.
innererror
DocumentIntelligenceInnerError
Inner error.
message
string
A human-readable representation of the error.
In this article
URI Parameters
Responses
Security
Examples
200 OK
Content-Type: application/pdf
pages パラメーター
ページ コレクションは、ドキュメント内のページの一覧です。 各ページはドキュメント内で順番に表示され、ページが回転しているかどうかを示す方向角度と、幅と高さ (ピクセル単位の寸法) が含まれます。 モデル出力のページ単位は、次のように計算されます。
| ファイル形式 | 計算されるページ単位 | [総ページ数] |
|---|---|---|
| 画像 (JPEG/JPG、PNG、BMP、HEIF) | 各画像 = 1 ページ単位 | 画像の合計 |
| PDF の各ページ = 1 ページ単位 | PDF のページの合計数 | |
| TIFF | TIFF の各画像 = 1 ページ単位 | TIFF の画像の合計数 |
| Word (DOCX) | 最大 3,000 文字 = 1 ページ単位、埋め込みまたはリンクされた画像はサポートされません | 最大 3,000 文字ずつのページの合計数 |
| Excel (XLSX) | 各ワークシート = 1 ページ単位、埋め込みまたはリンクされた画像はサポートされていません | 合計ワークシート数 |
| PowerPoint (PPTX) | 各スライド = 1 ページ単位、埋め込みまたはリンクされた画像はサポートされていません | 合計スライド数 |
| HTML | 最大 3,000 文字 = 1 ページ単位、埋め込みまたはリンクされた画像はサポートされません | 最大 3,000 文字ずつのページの合計数 |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
テキスト抽出に pages を使用する
複数ページの大きい PDF ドキュメントの場合は、pages クエリ パラメーターを使用して、テキストを抽出する特定のページ番号またはページ範囲を示します。
段落の抽出
Document Intelligence の読み取り OCR モデルは、analyzeResults の最上位オブジェクトとして、paragraphs コレクション内の識別されたテキスト ブロックすべてを抽出します。 このコレクション内の各エントリはテキスト ブロックを表し、抽出されたテキスト (content) と境界 polygon 座標を含みます。
span情報は、ドキュメントのテキスト全体を含む最上位contentプロパティ内のテキスト フラグメントを指します。
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
テキスト、行、単語の抽出
読み取り OCR モデルでは、印刷と手書きのスタイルのテキストをlinesおよびwordsとして抽出します。 このモデルでは、抽出された単語の境界 polygon 座標と confidence を出力します。
styles コレクションには、行の手書きスタイル (関連するテキストを指すスパンと共に検出された場合) が含まれます。 この機能は、サポートされている手書き言語に適用されます。
Microsoft Word、Excel、PowerPoint、HTML の場合、Document Intelligence Read モデル v3.1 以降のバージョンでは、すべての埋め込みテキストがそのまま抽出されます。 テキストは単語と段落として抽出されます。 埋め込み画像はサポートされません。
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
手書きスタイルの抽出
応答では、各テキスト行が手書きスタイルであるかどうかと、信頼度スコアが分類されます。 詳細については、手書き言語サポートに関するページを "参照" してください。 次の例は、JSON スニペットの例を示しています。
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
フォントとスタイルのアドオン機能を有効にすると、styles オブジェクトの一部としてフォントとスタイルの結果も取得されます。
次のステップ v4.0
Document Intelligence のクイックスタートを完了します。
REST API を調べる:
その他のサンプルを GitHub でご覧ください。
Note
ラベル、道路標識、ポスターなどの外部画像からテキストを抽出するには、パフォーマンスが向上した同期 API を使用して、一般的な (ドキュメント以外の) 画像用に最適化された Azure AI Image Analysis v4.0 読み取り機能を使用します。 この機能により、リアルタイムのユーザー エクスペリエンス シナリオに OCR を簡単に埋め込むことができます。
Document Intelligence の読み取り光学式文字認識 (OCR) モデルは、Azure AI Vision の読み取りよりも高解像度で動作し、PDF ドキュメントやスキャン画像から印刷テキストや手書きテキストを抽出します。 また、Microsoft Word、Excel、PowerPoint、HTML ドキュメントからテキストを抽出するためのサポートも含まれています。 段落、テキスト行、単語、場所、言語が検出されます。 この読み取りモデルは、カスタム モデルに加えて、レイアウト、一般ドキュメント、請求書、領収書、身分証明書 (ID)、医療保険カード、W2 など、他の Document Intelligence 事前構築済みモデルの基になる OCR エンジンです。
ドキュメントの OCR とは
ドキュメントの光学式文字認識 (OCR) は、複数のファイル形式とグローバル言語の大きなテキスト負荷の高いドキュメントに最適化されています。 これには、ドキュメント画像の高解像度スキャンによる小さな文字や密集した文字の優れた処理、段落検出、入力可能なフォーム管理などの機能が含まれています。 OCR 機能には、1 文字のボックスや、請求書、領収書、その他の事前構築済みのシナリオでよく見られるキー フィールドの正確な抽出などの高度なシナリオも含まれます。
開発オプション
ドキュメント インテリジェンス v3.1 では、次のツール、アプリケーション、およびライブラリがサポートされています:
| 機能 | リソース | モデル ID |
|---|---|---|
| OCR 読み取りモデル | • ドキュメントインテリジェンススタジオ • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
ドキュメント インテリジェンス v3.0 では、次のツール、アプリケーション、およびライブラリがサポートされています:
| 機能 | リソース | モデル ID |
|---|---|---|
| OCR 読み取りモデル | • ドキュメントインテリジェンススタジオ • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
入力の要件
サポートされているファイル形式:
| モデル | 画像: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Microsoft Office: Word ( DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML |
|
|---|---|---|---|
| 読み込み | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| 一般的なドキュメント | ✔ | ✔ | |
| 事前構築済み | ✔ | ✔ | |
| カスタム抽出 | ✔ | ✔ | |
| カスタム分類 | ✔ | ✔ | ✔ |
最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
PDF および TIFF の場合、最大 2,000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは
4MB です。画像のディメンションは、50 ピクセル x 50 ピクセルから 10,000 ピクセル x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、150 DPI (1 インチあたりのドット数) で約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は
1GB です。カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GB で、最大 10,000 ページです。 2024-11-30 (GA) の場合、トレーニング データの合計サイズは2GB で、最大 10,000 ページです。
Read モデルの概要
Document Intelligence Studio を使用して、フォームやドキュメントからテキストを抽出してみてください。 次の資産が必要になります。
Azure サブスクリプション - 無料で作成できます。
Azure portal の Document Intelligence Studio インスタンス。 Free 価格レベル (
F0) を利用して、サービスを試用できます。 リソースがデプロイされたら、[リソースに移動] を選択してキーとエンドポイントを取得します。
Note
現在、Document Intelligence Studio では、Microsoft Word、Excel、PowerPoint、HTML のファイル形式はサポートされていません。
"Document Intelligence Studio で処理されたサンプル ドキュメント"
Document Intelligence Studio ホーム ページで、[読み取り] を選択します。
サンプル ドキュメントを分析したり、独自のファイルをアップロードしたりできます。
[分析の実行] ボタンを選択し、必要に応じて [分析オプション] を構成します。
サポートされている言語とロケール
サポートされている言語の完全なリストについては、言語サポート - ドキュメント解析モデルのページを参照してください。
データの抽出
Note
Microsoft Word および HTML ファイルは、v4.0 でサポートされています。 次の機能は現在、サポートされていません。
- 各ページ オブジェクトの角度、幅と高さ、単位は返されません。
- 検出される各オブジェクトには、境界多角形も境界領域もありません。
- ページ範囲 (
pages) はパラメーターとして返されません。 -
linesオブジェクトはありません。
検索可能な PDF
検索可能な PDF 機能を使用すると、スキャン画像の PDF ファイルなどのアナログ PDF をテキストが埋め込まれた PDF に変換できます。 埋め込みテキストにして、検出されたテキスト エンティティを画像ファイルの上にオーバーレイすることで、PDF の抽出されたコンテンツ内でディープ テキスト検索を実行できるようになります。
重要
- 現時点では、読み取り OCR モデル
prebuilt-readのみが検索可能な PDF 機能をサポートしています。 この機能を使用する場合は、modelIdをprebuilt-readとして指定してください。 その他のモデルの種類では、エラーが返されます。 - 検索可能な PDF は
2024-11-30prebuilt-readモデルに含まれており、検索可能な PDF 出力の生成に追加コストはかかりません。- 検索可能な PDF では現在、入力として PDF ファイルのみをサポートしています。
検索可能な PDF を使用する
検索可能な PDF を使用するには、Analyze 操作を使用して POST 要求を作成し、出力形式を pdf と指定します。
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Analyze 操作の完了をポーリングします。 操作が完了したら、GET 要求を発行して、PDF 形式の Analyze 操作結果を取得します。
正常に完了すると、PDF を取得して application/pdf としてダウンロードできます。 この操作により、Base64 でエンコードされた JSON ではなく、埋め込みテキスト形式の PDF を直接ダウンロードできます。
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
ページ
ページ コレクションは、ドキュメント内のページの一覧です。 各ページはドキュメント内で順番に表示され、ページが回転しているかどうかを示す方向角度と、幅と高さ (ピクセル単位の寸法) が含まれます。 モデル出力のページ単位は、次のように計算されます。
| ファイル形式 | 計算されるページ単位 | [総ページ数] |
|---|---|---|
| 画像 (JPEG/JPG、PNG、BMP、HEIF) | 各画像 = 1 ページ単位 | 画像の合計 |
| PDF の各ページ = 1 ページ単位 | PDF のページの合計数 | |
| TIFF | TIFF の各画像 = 1 ページ単位 | TIFF の画像の合計数 |
| Word (DOCX) | 最大 3,000 文字 = 1 ページ単位、埋め込みまたはリンクされた画像はサポートされません | 最大 3,000 文字ずつのページの合計数 |
| Excel (XLSX) | 各ワークシート = 1 ページ単位、埋め込みまたはリンクされた画像はサポートされていません | 合計ワークシート数 |
| PowerPoint (PPTX) | 各スライド = 1 ページ単位、埋め込みまたはリンクされた画像はサポートされていません | 合計スライド数 |
| HTML | 最大 3,000 文字 = 1 ページ単位、埋め込みまたはリンクされた画像はサポートされません | 最大 3,000 文字ずつのページの合計数 |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
テキスト抽出対象のページを選びます
複数ページの大きい PDF ドキュメントの場合は、pages クエリ パラメーターを使用して、テキストを抽出する特定のページ番号またはページ範囲を示します。
段落
Document Intelligence の読み取り OCR モデルは、analyzeResults の最上位オブジェクトとして、paragraphs コレクション内の識別されたテキスト ブロックすべてを抽出します。 このコレクション内の各エントリはテキスト ブロックを表し、抽出されたテキスト (content) と境界 polygon 座標を含みます。
span情報は、ドキュメントのテキスト全体を含む最上位contentプロパティ内のテキスト フラグメントを指します。
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
テキスト、行、単語
読み取り OCR モデルでは、印刷と手書きのスタイルのテキストをlinesおよびwordsとして抽出します。 このモデルでは、抽出された単語の境界 polygon 座標と confidence を出力します。
styles コレクションには、行の手書きスタイル (関連するテキストを指すスパンと共に検出された場合) が含まれます。 この機能は、サポートされている手書き言語に適用されます。
Microsoft Word、Excel、PowerPoint、HTML の場合、Document Intelligence Read モデル v3.1 以降のバージョンでは、すべての埋め込みテキストがそのまま抽出されます。 テキストは単語と段落として抽出されます。 埋め込み画像はサポートされません。
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
テキスト行の手書きスタイル
応答では、各テキスト行が手書きスタイルであるかどうかと、信頼度スコアが分類されます。 詳細については、手書き言語サポートに関するページを "参照" してください。 次の例は、JSON スニペットの例を示しています。
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
フォントとスタイルのアドオン機能を有効にすると、styles オブジェクトの一部としてフォントとスタイルの結果も取得されます。
次のステップ
Document Intelligence のクイックスタートを完了します。
REST API を調べる:
その他のサンプルを GitHub でご覧ください。