このコンテンツの適用対象: ![]() v2.1 | 最新バージョン:
v2.1 | 最新バージョン: ![]() v4.0 (GA)
v4.0 (GA)
Azure AI Document Intelligence は、アプリとフローにインテリジェントなドキュメント処理を追加できる、さまざまなモデルをサポートしています。 事前構築済みのドメイン固有のモデルを使うか、特定のビジネス ニーズとユース ケースに合わせてカスタム モデルをトレーニングできます。 Document Intelligence は、REST API または Python、C#、Java、JavaScript の各クライアント ライブラリで使用できます。
Note
- 財務データ、保護された健康データ、個人データ、または機密性の高いデータを含むドキュメント処理プロジェクトには、細心の注意が必要です。
- すべての国/地域の要件および業界固有の要件に必ず従うようにしてください。
モデルの概要
次の表は、安定版の API ごとに使用可能なモデルを示しています。
| モデルの種類 | モデル | • 2024-11-30 (GA) | 2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| ドキュメント分析モデル | 読み取り | ✔️ | ✔️ | ✔️ | 該当なし |
| ドキュメント分析モデル | レイアウト | ✔️ | ✔️ | ✔️ | ✔️ |
| ドキュメント分析モデル | 一般的なドキュメント | レイアウトに移動** | ✔️ | ✔️ | 該当なし |
| 事前構築済みのモデル | 銀行小切手 | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 口座取引明細書 | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | Paystub | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | コントラクト | ✔️ | ✔️ | 該当なし | 該当なし |
| 事前構築済みのモデル | 医療保険カード | ✔️ | ✔️ | ✔️ | 該当なし |
| 事前構築済みのモデル | 身分証明書 | ✔️ | ✔️ | ✔️ | ✔️ |
| 事前構築済みのモデル | 請求書 | ✔️ | ✔️ | ✔️ | ✔️ |
| 事前構築済みのモデル | 領収書 | ✔️ | ✔️ | ✔️ | ✔️ |
| 事前構築済みのモデル | 米国統一税* | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 米国 1040 税* | ✔️ | ✔️ | 該当なし | 該当なし |
| 事前構築済みのモデル | 米国 1095 税* | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 米国 1098 税* | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 米国 1099 税* | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 米国 W2 税 | ✔️ | ✔️ | ✔️ | 該当なし |
| 事前構築済みのモデル | 米国 W4 税 | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 米国住宅ローン 1003 URLA | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 米国住宅ローン 1004 URAR | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 米国住宅ローン 1005 | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 米国住宅ローン 1008 概要 | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 米国住宅ローン決算開示 | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 結婚証明書 | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | クレジット カード | ✔️ | 該当なし | なし | 該当なし |
| 事前構築済みのモデル | 名刺 | deprecated | ✔️ | ✔️ | ✔️ |
| カスタム分類モデル | カスタム分類子 | ✔️ | ✔️ | 該当なし | 該当なし |
| カスタム抽出モデル | カスタム ニューラル | ✔️ | ✔️ | ✔️ | 該当なし |
| カスタム抽出モデル | カスタム テンプレート | ✔️ | ✔️ | ✔️ | ✔️ |
| カスタム抽出モデル | カスタム構成済み | ✔️ | ✔️ | ✔️ | ✔️ |
| すべてのモデル | アドオン機能 | ✔️ | ✔️ | 該当なし | 該当なし |
* - サブモデルを含みます。 サポートされているバリエーションとサブタイプについては、モデル固有の情報を参照してください。
**- 一般的なドキュメント モデルのすべての機能は、レイアウト モデルで使用できます。 一般モデルはサポートされなくなりました。
Latency
待機時間は、API サーバーが受信要求を処理し、クライアントに送信応答を配信するためにかかる時間です。 ドキュメントの分析にかかる時間は、サイズ(例えばページ数)や各ページの関連コンテンツによって異なります。 Document Intelligence は、類似したドキュメントの待ち時間が同等であるが、必ずしも同じとは限らないマルチテナント サービスです。 待ち時間やパフォーマンスにおける不定期の変動は、画像や大きなドキュメントを大規模に処理するマイクロサービス ベースのステートレスなすべての非同期サービスに固有のものです。 Microsoft では、ハードウェア、容量、スケーリング機能を継続的にスケールアップしていますが、実行時に待ち時間の問題が発生する可能性は依然として存在します。
アドオン機能
Document Intelligence で使用できるアドオン機能を次に示します。 名刺モデルを除くすべてのモデルについて、Document Intelligence では、より高度な分析を可能にするアドオン機能がサポートされるようになりました。 これらのオプション機能は、ドキュメント抽出のシナリオに応じて有効または無効にすることができます。 2023-07-31 (GA) 以降の API バージョンでは 7 つのアドオン機能を利用できます。
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairsqueryFieldsNot available with the US.Tax modelssearchablePDFOnly available for Read Model
| アドオン機能 | アドオン/無料 | • 2024-11-30 (GA) | 2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Font プロパティの抽出 | アドオン | ✔️ | ✔️ | 該当なし | 該当なし |
| 数式の抽出 | アドオン | ✔️ | ✔️ | 該当なし | 該当なし |
| 高解像度の抽出 | アドオン | ✔️ | ✔️ | 該当なし | 該当なし |
| バーコード抽出 | Free | ✔️ | ✔️ | 該当なし | 該当なし |
| 言語検出 | Free | ✔️ | ✔️ | 該当なし | 該当なし |
| キーと値のペア | Free | ✔️ | 該当なし | なし | 該当なし |
| クエリ フィールド | アドオン* | ✔️ | 該当なし | なし | 該当なし |
| 検索可能な PDF | アドオン* | ✔️ | 該当なし | なし | 該当なし |
モデル分析機能
| モデル ID | テキストの抽出 | クエリ フィールド | 段落 | 段落の役割 | 選択マーク | テーブル | キーと値のペア | 言語 | バーコード | ドキュメント分析 | 数式* | スタイルのフォント* | 高解像度* | 検索可能な PDF |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| prebuilt-read | ✓ | ✓ | O | O | O | O | O | O | ||||||
| 事前構築済みレイアウト | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | O | ||
| prebuilt-contract | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | ||||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-invoice | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | |||
| prebuilt-receipt | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-creditCard | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-check.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-payStub.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-bankStatement | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1003 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1004 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1005 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1008 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w4 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us.1040 (各種) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1095A | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us.1095C | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1099 (各種) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1099SSA | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ - 有効
O - 省略可能
* - 追加コストが発生する Premium 機能
アドオン* - クエリ フィールドは、他のアドオン機能とは価格設定が異なります。 詳細については、価格のページを参照してください。
境界ボックスと多角形の座標
境界ボックス (v3.0 以降のバージョンの polygon) は、ドキュメントのテキスト要素を囲む抽象的な四角形であり、オブジェクト検出の参照ポイントとして使用されます。
境界ボックスでは、4 つの数値ペアの配列で表される xy 座標平面を使用して位置を指定します。 各ペアが、左上、右上、右下、左下の順序でこのボックスの角を表します。
画像の座標はピクセル単位で表示されます。 PDF の場合、座標はインチ単位で表示されます。
サポートされている言語
Document Intelligence のディープ ラーニング ベースのユニバーサル モデルでは、画像やドキュメント (言語が混在しているテキスト行を含む) から多言語テキストを抽出できる多くの言語がサポートされています。 言語サポートは、Document Intelligence サービスの機能によって異なります。 完全な一覧については、以下の記事を参照してください。
リージョン別の提供状況
Document Intelligence は、60 以上の Azure グローバル インフラストラクチャ リージョンの多くで一般提供されています。
詳細については、Azure の地域に関するページを参照して、ご自身と顧客にとって最適なリージョンを選択してください。
モデルの詳細
このセクションでは、各モデルで期待できる出力について説明します。 大部分のモデルの出力はアドオン機能を使用することで拡張できます。
OCR の読み取り

Read API を使用すると、テキスト行、単語、その場所、検出された言語、および手書きのスタイル (検出された場合) を分析および抽出することができます。
Document Intelligence Studio を使用して処理されたサンプル ドキュメント:
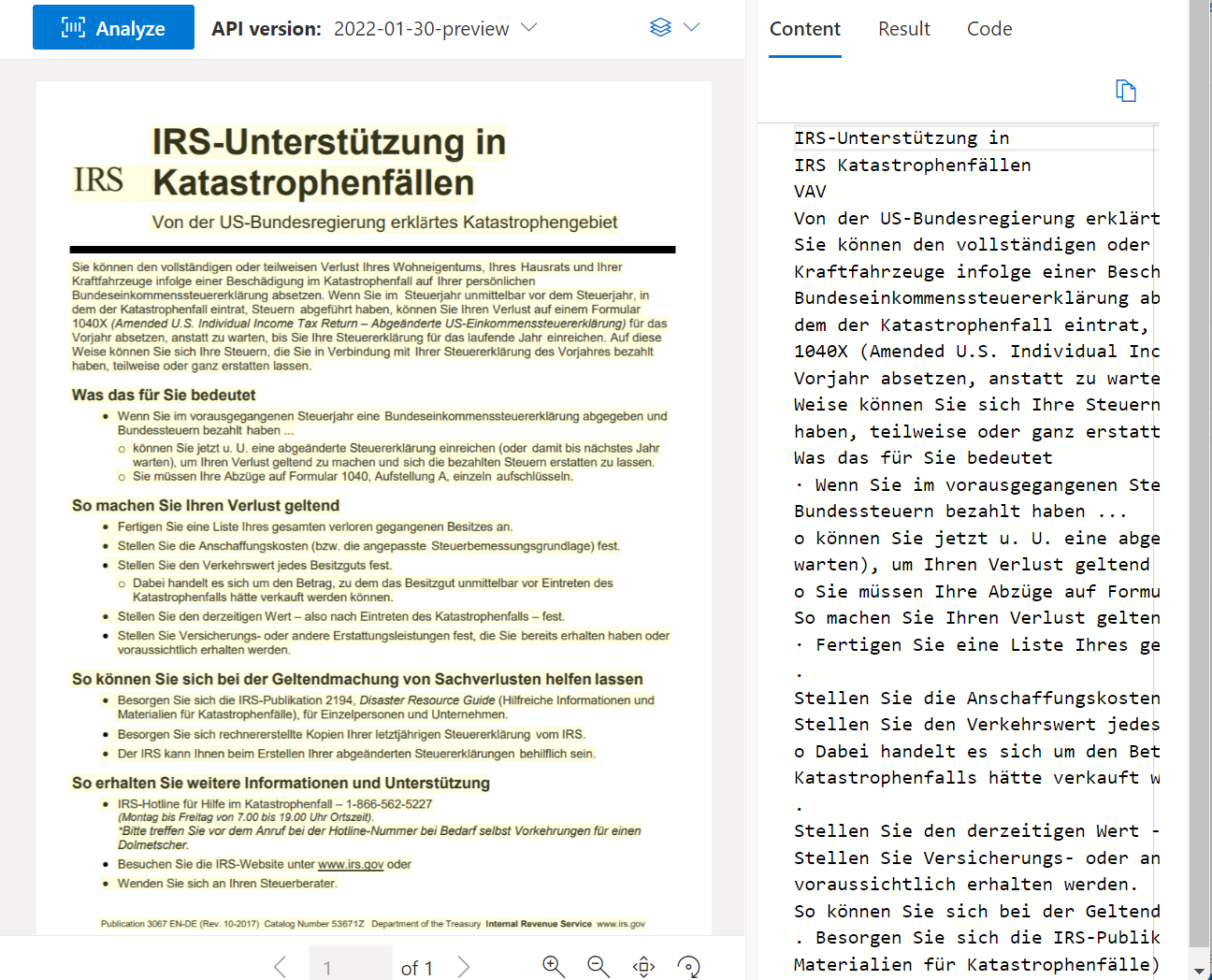
レイアウト分析

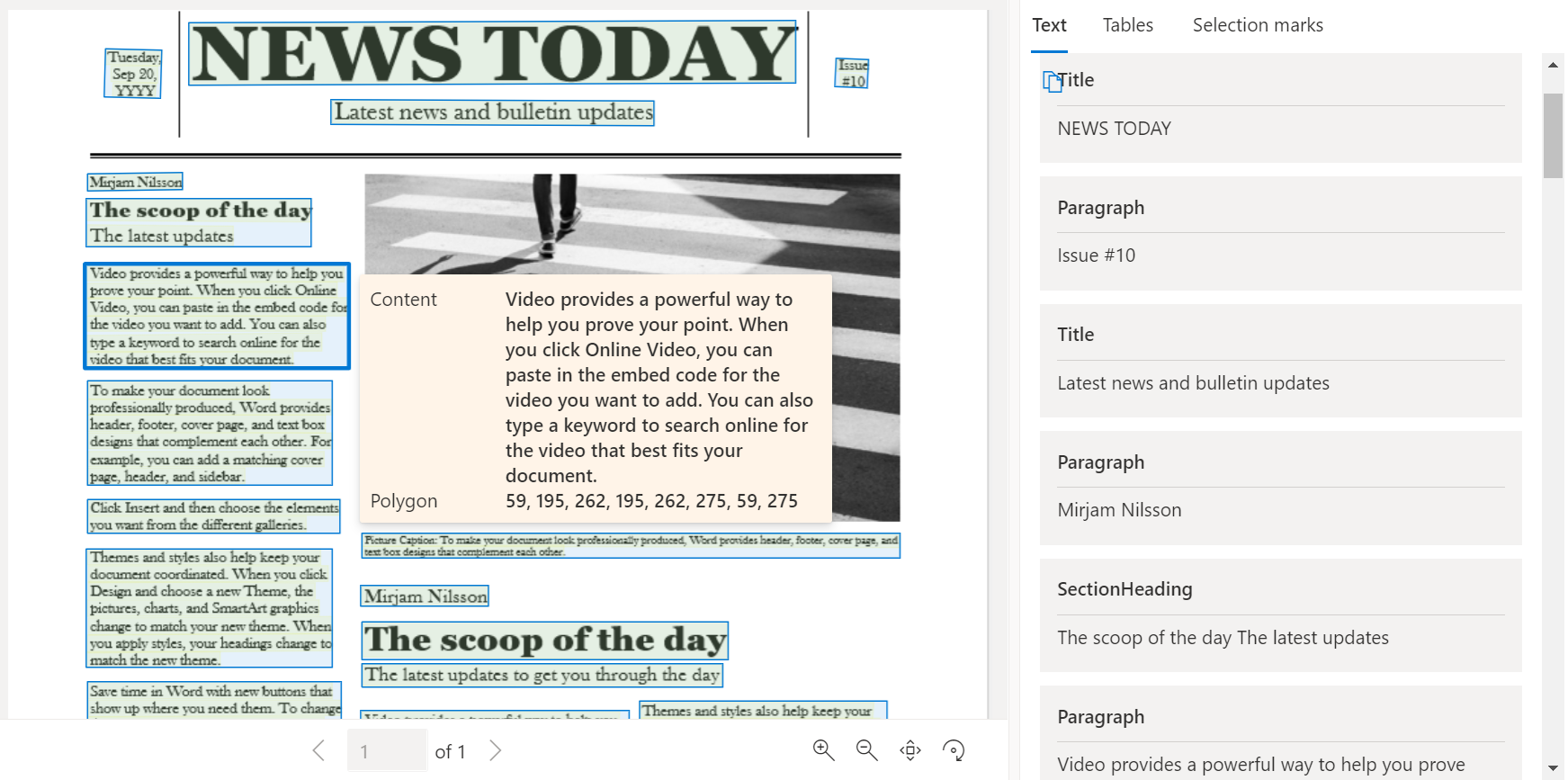
レイアウト分析モデルは、テキスト、テーブル、選択マーク、およびタイトル、セクション見出し、ページ ヘッダー、ページ フッターなどのその他の構造要素を分析して抽出します。
Document Intelligence Studio を使用して処理されたサンプル ドキュメント:
医療保険カード
![]()
医療保険カード モデルでは、強力な光学式文字認識 (OCR) 機能と、ディープ ラーニング モデルの組み合わせにより、米国の医療保険カードが分析されて、重要な情報が抽出されます。
Document Intelligence Studio を使用して処理された米国の医療保険カードのサンプル:

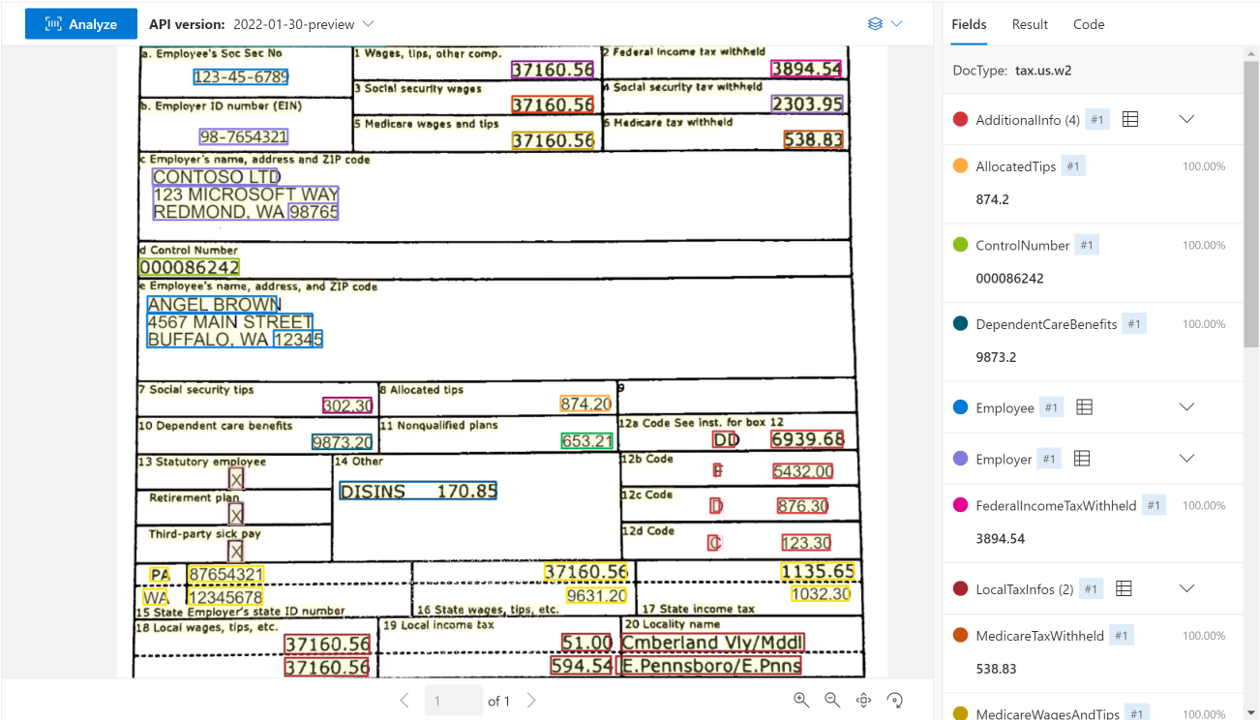
米国税務書類
米国税務書類モデルでは、税務書類の選択グループから主要なフィールドと明細を分析して抽出します。 この API は、電話でキャプチャされた画像、スキャンされたドキュメント、デジタル PDF など、さまざまな形式や品質の英語の米国税務書類の分析をサポートします。 現在サポートされているモデルは次のとおりです。
| モデル | 説明 | ModelID |
|---|---|---|
| 米国税 W-2 | 課税対象の報酬の詳細を抽出します。 | prebuilt-tax.us.w2 |
| 米国税 W-4 | 課税対象の報酬の詳細を抽出します。 | prebuilt-tax.us.w4 |
| 米国税 1040 | 住宅ローンの利息の詳細を抽出します。 | prebuilt-tax.us.1040(variations) |
| 米国税 1095 | 健康保険の詳細を抽出します。 | prebuilt-tax.us.1095 (バリエーション) |
| 米国税 1098 | 住宅ローンの利息の詳細を抽出します。 | prebuilt-tax.us.1098(variations) |
| 米国税 1099 | 雇用主以外のソースから受け取った所得を抽出します。 | prebuilt-tax.us.1099 (バリエーション) |
Document Intelligence Studio を使用して処理された W-2 ドキュメントのサンプル:
米国の住宅ローン ドキュメント

米国の住宅ローン ドキュメント モデルは、住宅ローン ドキュメントの選択されたグループから、借り手、ローン、不動産情報を含む主要なフィールドの分析と抽出を行います。 この API では、電話でキャプチャされた画像、スキャンされたドキュメント、デジタル PDF など、さまざまな形式や品質の英語の米国住宅ローン ドキュメントの分析がサポートされます。 現在サポートされているモデルは次のとおりです。
| モデル | 説明 | ModelID |
|---|---|---|
| 1003 使用許諾契約書 (EULA) | ローン、借り手、不動産の詳細を抽出します。 | prebuilt-mortgage.us.1003 |
| 1004 統一住宅評価報告書 (URAR) | ローン、借り手、不動産の詳細を抽出します。 | prebuilt-mortgage.us.1004 |
| 1005 在籍証明書 | ローン、借り手、不動産の詳細を抽出します。 | prebuilt-mortgage.us.1005 |
| 1008 概要ドキュメント | 借り手、売り手、不動産、住宅ローン、引受の詳細を抽出します。 | prebuilt-mortgage.us.1008 |
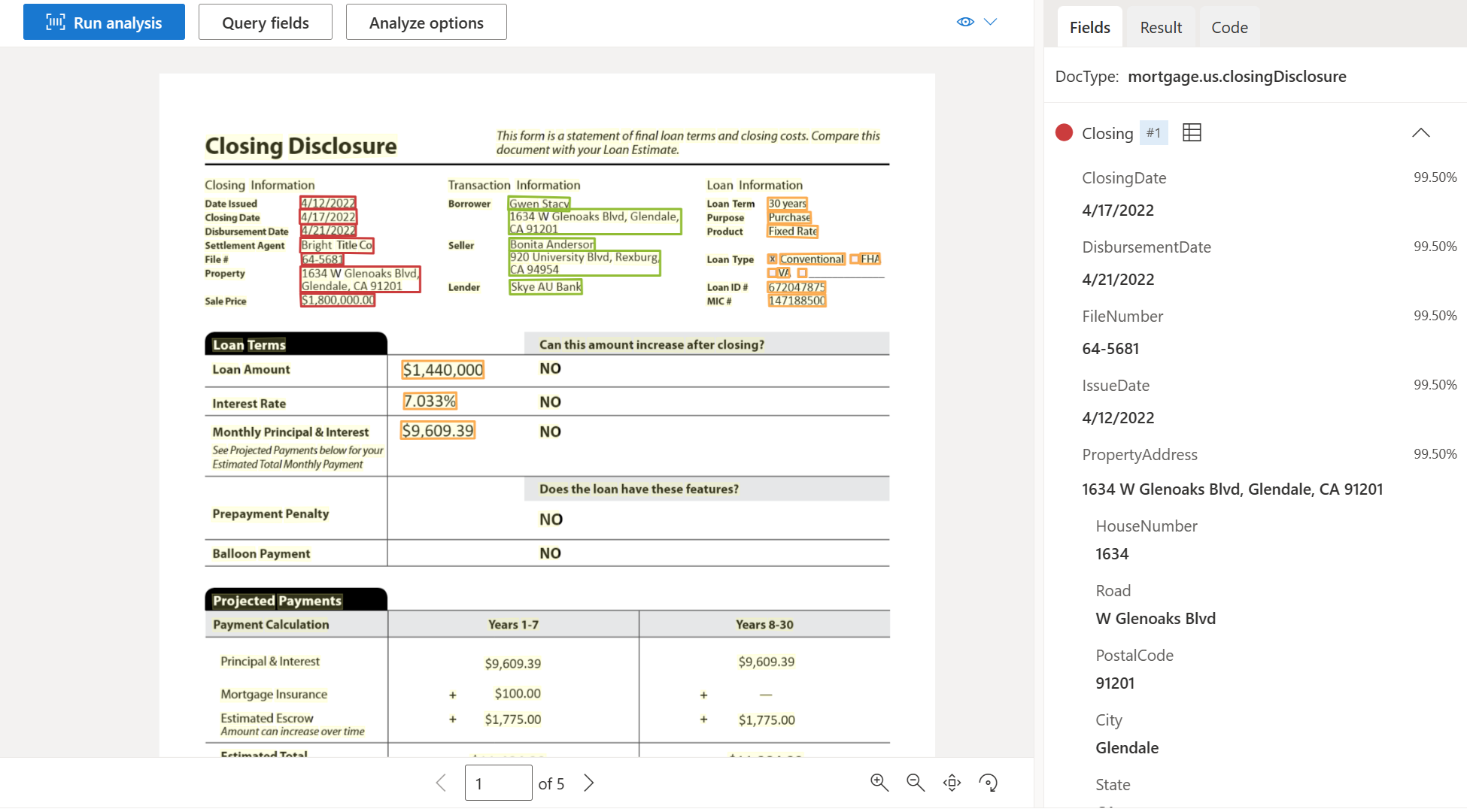
| 決算開示 | 決算、取引コスト、ローンの詳細を抽出します。 | prebuilt-mortgage.us.closingDisclosure |
"Document Intelligence Studio を使用して処理された決済開示ドキュメントのサンプル":
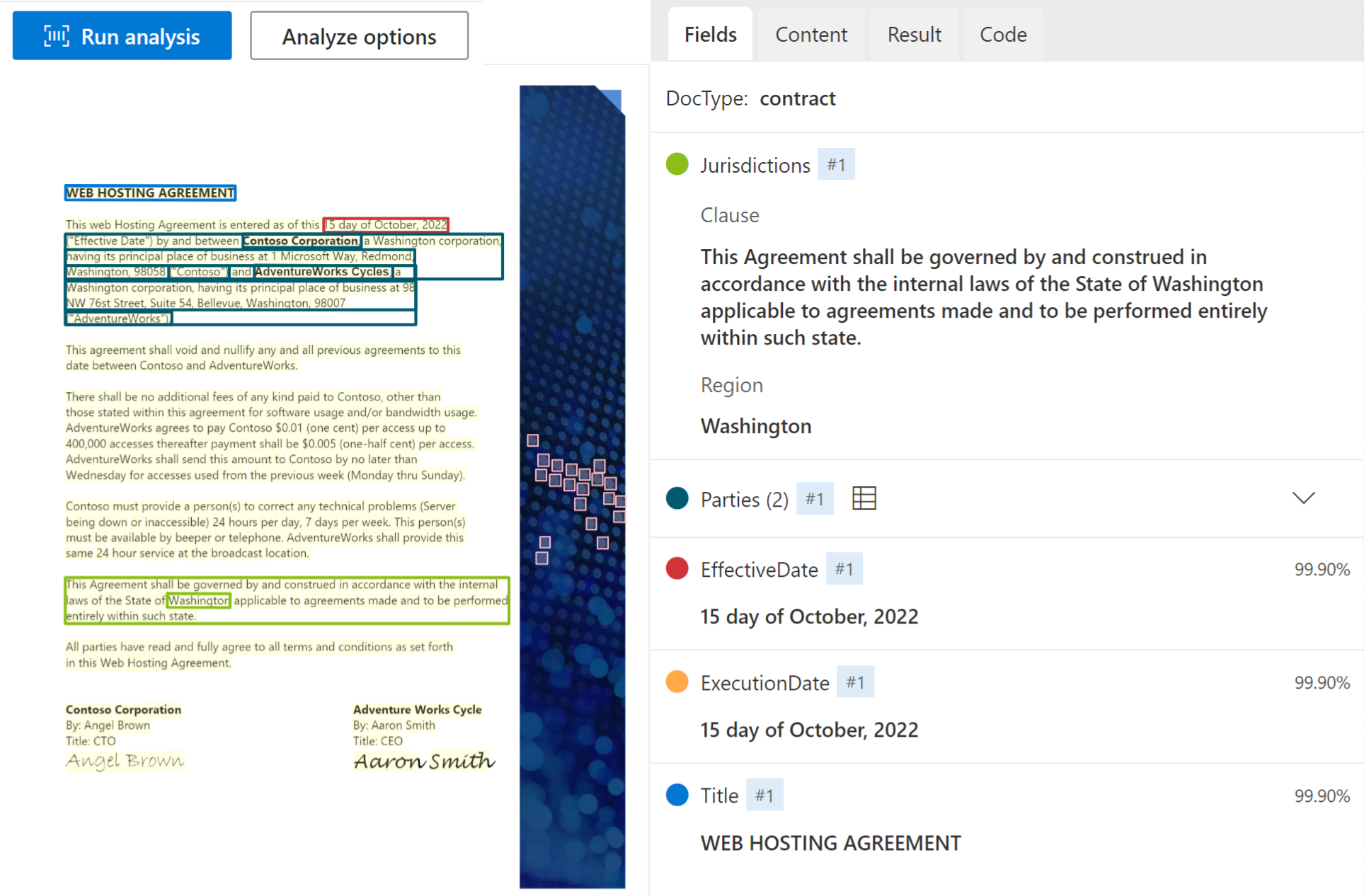
コントラクト
![]()
契約モデルは、当事者、管轄区域、契約 ID、役職を含む契約の主要なフィールドと品目を分析して抽出します。 このモデルでは現在、英語の契約文書がサポートされています。
Document Intelligence Studio を使用して処理された契約書のサンプル:
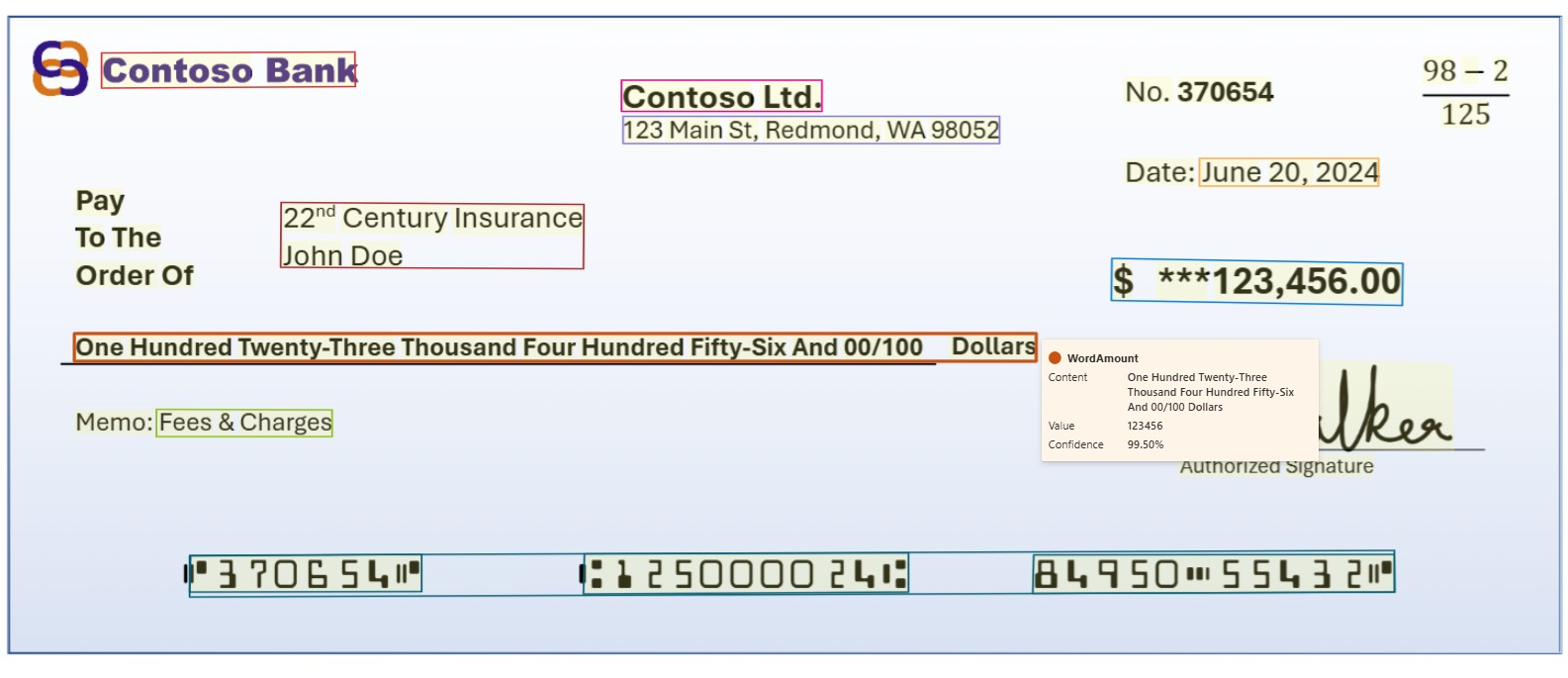
米国銀行小切手
![]()
契約モデルでは、小切手の詳細、口座詳細、金額、メモなどの主要項目が分析および抽出され、米国の銀行小切手から抽出されます。
Document Intelligence Studio を使用して処理された銀行小切手のサンプル:
米国の口座取引明細書
![]()
口座取引明細書モデルでは、米国の口座取引明細書の口座番号、銀行の詳細、明細書の詳細、トランザクションの詳細から、主要なフィールドと明細が分析および抽出されます。
Document Intelligence Studio を使用して処理された口座取引明細書のサンプル:

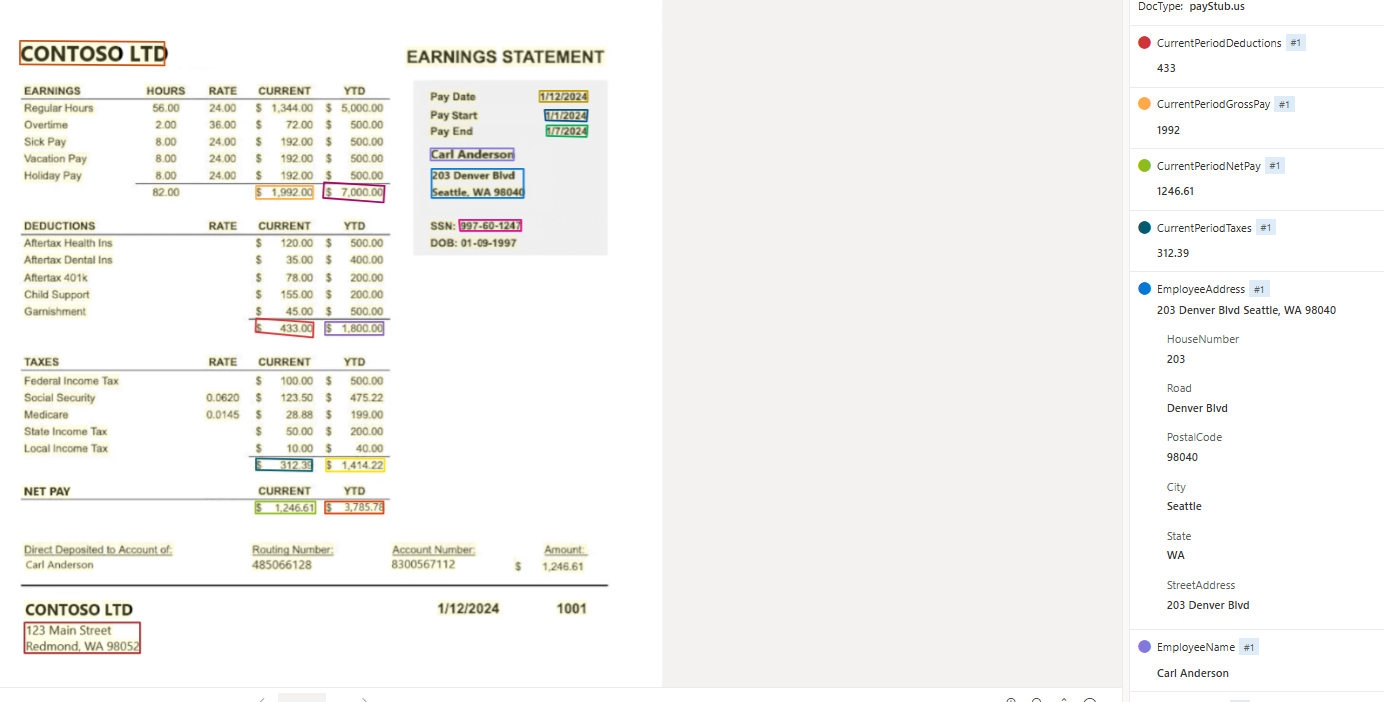
給与明細
![]()
給与明細モデルでは、給与に関連する情報を含むドキュメントおよびファイルから、主要なフィールドと明細が分析および抽出されます。
Document Intelligence Studio を使用して処理された給与明細のサンプル:
請求書
請求書モデルでは、請求書の処理が自動化され、顧客名、請求先住所、期限、金額、明細、およびその他のキー データが抽出されます。
Document Intelligence Studio を使用して処理された請求書のサンプル:

Receipt
レシート モデルを使用して、印刷されたレシートや手書きのレシートから、マーチャント名、日付、明細、数量の売上領収書をスキャンすることができます。 バージョン v3.0 は、1 ページのホテル領収書の処理もサポートしています。
Document Intelligence Studio を使用して処理された領収書のサンプル:

身分証明書 (ID)

身分証明書 (ID) モデルを使用すると、米国の運転免許証 (全 50 州およびコロンビア特別区) および国際パスポートの個人情報ページ (ビザや他の渡航文書を除く) を処理し、キー フィールドを抽出することができます。
Document Intelligence Studio を使用して処理された米国の運転免許証のサンプル:

結婚証明書
![]()
結婚証明書モデルを使用して、米国の結婚証明書を処理し、個人、日付、場所などの主要なフィールドを抽出します。
"Document Intelligence Studio を使用して処理された米国の結婚証明書のサンプル":

クレジット カード
![]()
クレジット カード モデルを使用して、クレジット カードとデビット カードを処理し、主要なフィールドを抽出します。
"Document Intelligence Studio を使用して処理されたクレジット カードのサンプル":

カスタム モデル

カスタム モデルは、大きく 2 種類に分類できます。 つまり、"ドキュメントの種類" の分類をサポートするカスタム分類モデルと、特定のドキュメントの種類から定義されたスキーマを抽出できるカスタム抽出モデルです。
カスタム ドキュメント モデルでは、ビジネスに固有のフォームやドキュメントからデータを分析し、抽出することができます。 これらは、個々のコンテンツ内のフォーム フィールドを認識し、キーと値のペアおよびテーブル データを抽出します。 作業を開始するために必要なフォームの種類の例は 1 つだけです。
バージョン v3.0 以降のカスタム モデルでは、カスタム テンプレート (フォーム) 内の署名検出と、テンプレートとニューラルの両モデル内のページをまたぐ表がサポートされています。 署名検出では、ドキュメントに署名した人物の ID ではなく、署名の存在を探します。 モデルが署名検出に対して未署名を返した場合、そのモデルでは、定義されたフィールドに署名が見つかりませんでした。
Document Intelligence Studio を使用して処理されたカスタム テンプレートのサンプル:
![Document Intelligence ツールの [analyze-a-custom-form]\(カスタム フォームの分析\) ウィンドウのスクリーンショット。](media/studio/train-model.png?view=doc-intel-2.1.0)
カスタム抽出

カスタム抽出モデルは、カスタム テンプレートとカスタム ニューラルの 2 種類のいずれかにできます。 カスタム抽出モデルを作成するには、抽出する値を持つドキュメントのデータセットにラベルを付け、ラベル付けされたデータセットに対してモデルをトレーニングします。 始めるために必要な同じフォームまたはドキュメントの種類の例は 5 つのみです。
Document Intelligence Studio を使用して処理されたカスタム抽出のサンプル:

カスタム分類子

カスタム分類モデルを使用すると、抽出モデルを呼び出す前にドキュメントの種類を識別できます。 分類モデルは、2023-07-31 (GA) API 以降で使用できます。 カスタム分類モデルをトレーニングするには、少なくとも 2 つの個別のクラスと、クラスごとに少なくとも 5 つのサンプルが必要です。
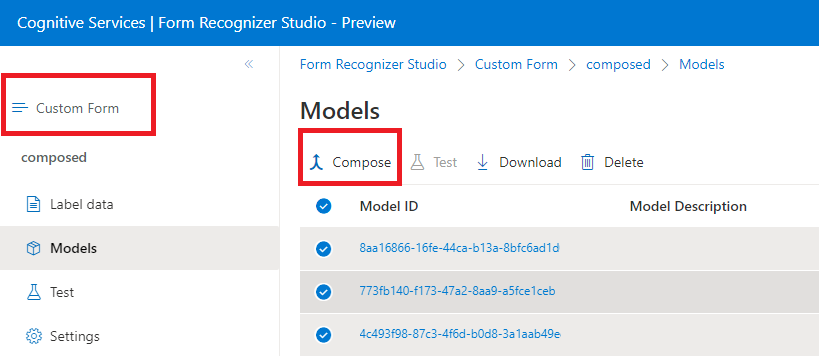
作成済みモデル
作成済みモデルは、カスタム モデルのコレクションを取得し、目的のフォームの種類から構築された 1 つのモデルに割り当てることで作成します。 1 つのモデル ID で呼び出される作成済みモデルに複数のカスタム モデルを割り当てることができます。 200 個までのトレーニングされたカスタム モデルを 1 つの作成済みモデルに割り当てることができます。
Document Intelligence Studio の作成済みモデル ダイアログ ウィンドウ:
入力の要件
サポートされているファイル形式:
| モデル | 画像: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Microsoft Office: Word ( DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML |
|
|---|---|---|---|
| 読み込み | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| 一般的なドキュメント | ✔ | ✔ | |
| 事前構築済み | ✔ | ✔ | |
| カスタム抽出 | ✔ | ✔ | |
| カスタム分類 | ✔ | ✔ | ✔ |
最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
PDF および TIFF の場合、最大 2,000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは
4MB です。画像のディメンションは、50 ピクセル x 50 ピクセルから 10,000 ピクセル x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、150 DPI (1 インチあたりのドット数) で約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は
1GB です。カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GB で、最大 10,000 ページです。 2024-11-30 (GA) の場合、トレーニング データの合計サイズは2GB で、最大 10,000 ページです。
Note
サンプル ラベル付けツールでは、BMP ファイル形式はサポートされていません。 これは、Document Intelligence サービスではなくツールの制限です。
バージョンの移行
アプリケーションで Document Intelligence v3.0 を使用する方法については、Document Intelligence v3.1 移行ガイドに関する記事を参照してください
| Model | 説明 |
|---|---|
| ドキュメント分析 | |
| レイアウト | ドキュメントからテキストとレイアウトの情報を抽出します。 |
| 事前構築済み | |
| 請求書 | 英語およびスペイン語の請求書から主要な情報を抽出します。 |
| Receipt | 英語の領収書から主要な情報を抽出します。 |
| 身分証明書 | 米国の運転免許証と国際パスポートから主要な情報を抽出します。 |
| 名刺 | 英語の名刺から主要な情報を抽出します。 |
| Custom | |
| Custom | ビジネスに固有のフォームとドキュメントからデータを抽出します。 カスタム モデルは、特定のデータとユース ケースに合わせてトレーニングされます。 |
| 構成 | カスタム モデルのコレクションを作成し、フォームの種類から構築された 1 つのモデルに割り当てます。 |
Layout
Layout API を使って、ドキュメントを分析し、テキスト、テーブルとヘッダー、選択マーク、構造情報を抽出することができます。
"サンプル ラベル付けツールを使用して処理されたサンプルのドキュメント":
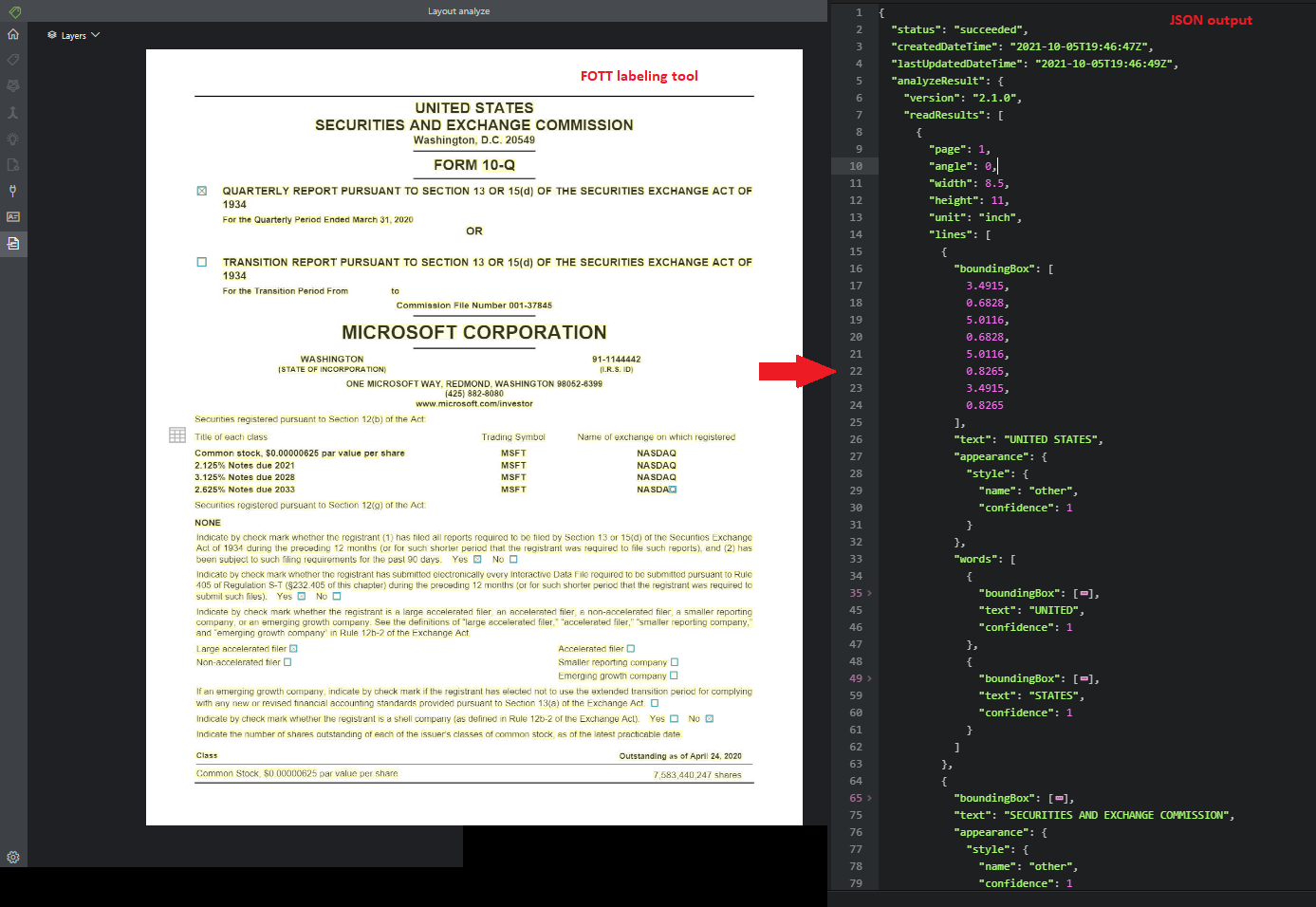
請求書
請求書モデルは、販売請求書から主要な情報が分析されて抽出されます。 API によって、さまざまな書式の請求書が分析され、顧客名、請求先住所、期限、請求額などの主要な情報が抽出されます。
"サンプル ラベル付けツールを使用して処理されたサンプルの請求書":
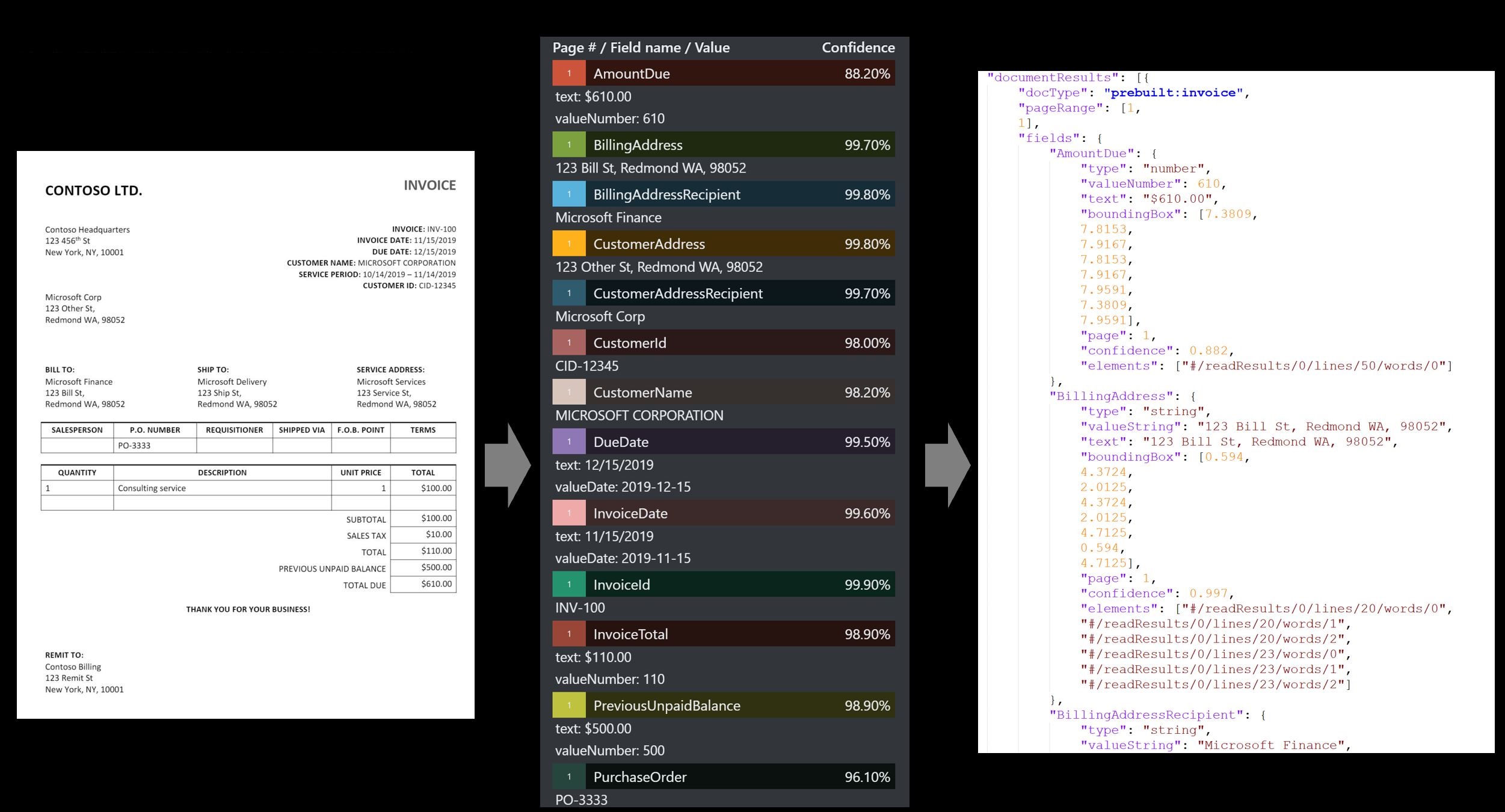
Receipt
- 領収書モデルでは、印刷された領収書と手書きのレシートから重要な情報を分析して抽出します。
"サンプル ラベル付けツールを使用して処理されたサンプルのレシート":
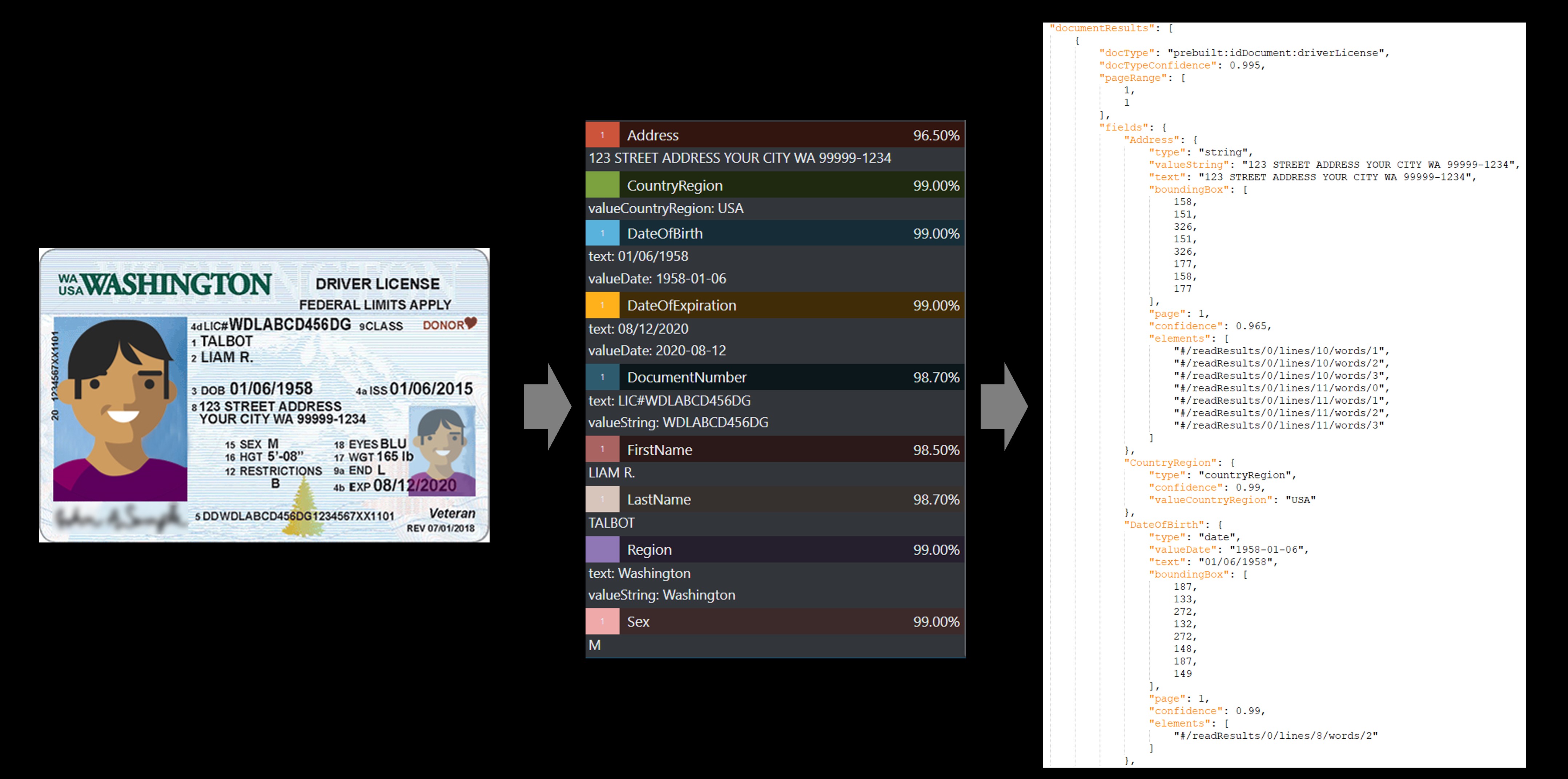
身分証明書
身分証明書モデルでは、次のドキュメントから重要な情報を分析して抽出します。
米国の運転免許証 (50 州のすべてとコロンビア特別区)
国際パスポートの個人情報ページ (査証やその他の旅行ドキュメントを除く)。 API では、身分証明書を分析して抽出します。
"サンプル ラベル付けツールを使用して処理された米国の運転免許証のサンプル":
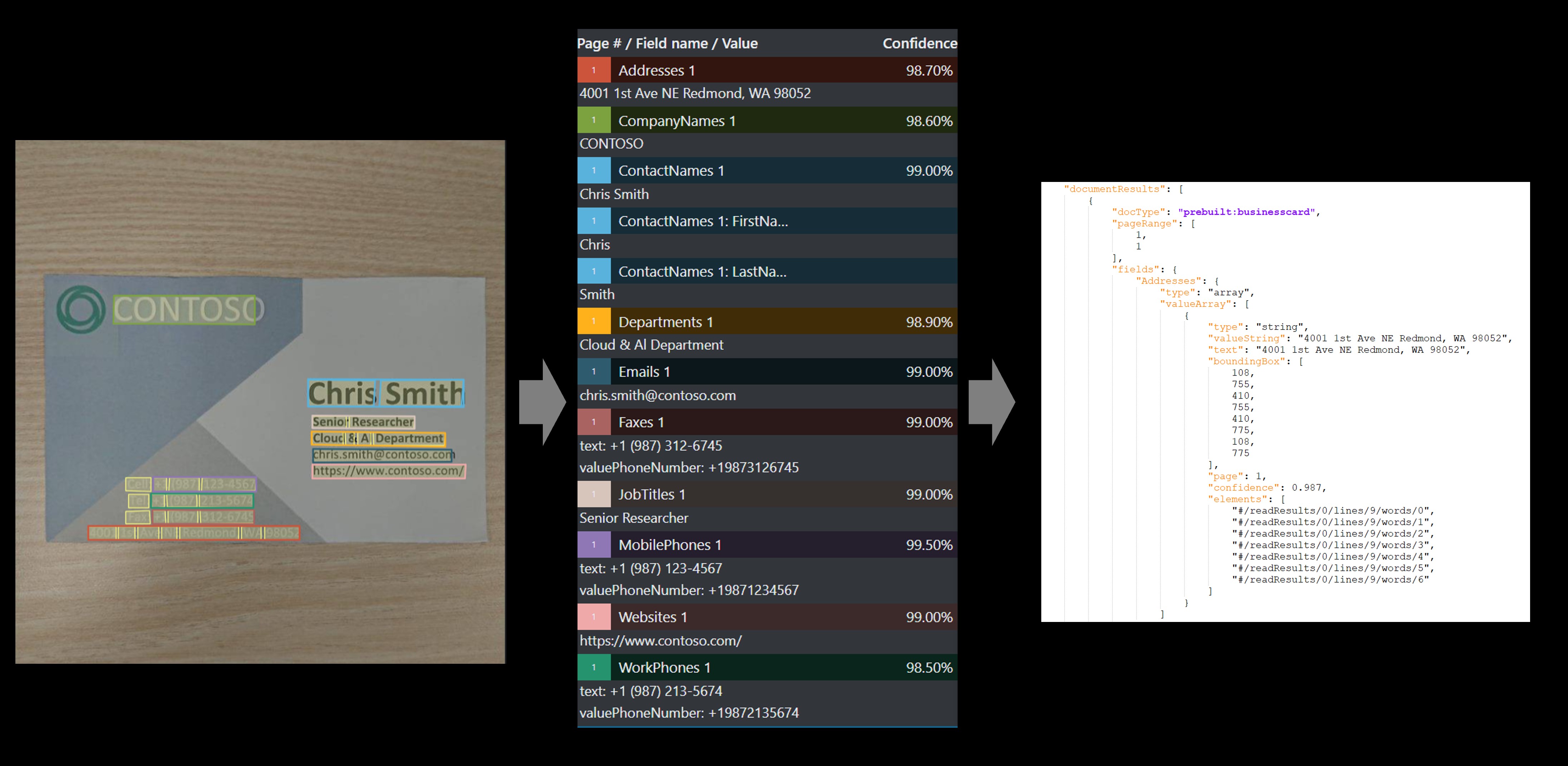
名刺
名刺モデルでは、名刺の画像から主要な情報が分析されて抽出されます。
"サンプル ラベル付けツールを使用して処理されたサンプルの名刺":
Custom
- カスタム モデルを使って、ビジネスに固有のフォームやドキュメントからデータを分析し、抽出することができます。 この API は、特定のコンテンツ内のフォーム フィールドを認識し、キーと値のペアおよびテーブル データを抽出するようにトレーニングされた、機械学習プログラムです。 始めるために必要なのは同じフォームの種類の 5 つの例だけであり、カスタム モデルのトレーニングは、ラベル付けされたデータセットがあってもなくても実行できます。
"サンプル ラベル付けツールを使用して処理されたサンプルのカスタム モデル":
![Document Intelligence ツールの [analyze-a-custom-form]\(カスタム フォームの分析\) ウィンドウのスクリーンショット。](media/overview-custom.jpg?view=doc-intel-2.1.0)
作成済みカスタム モデル
作成済みモデルは、カスタム モデルのコレクションを取得し、目的のフォームの種類から構築された 1 つのモデルに割り当てることで作成します。 1 つのモデル ID で呼び出される作成済みモデルに複数のカスタム モデルを割り当てることができます。 100 個までのトレーニングされたカスタム モデルを 1 つの構成済みモデルに割り当てることができます。
"サンプル ラベル付けツールが使用されている作成済みモデル ダイアログ ウィンドウ":
モデル データの抽出
| Model | テキストの抽出 | 言語検出 | 選択マーク | テーブル | 段落 | 段落の役割 | キーと値のペア | Fields |
|---|---|---|---|---|---|---|---|---|
| レイアウト | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| 請求書 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Receipt | ✓ | ✓ | ✓ | |||||
| 身分証明書 | ✓ | ✓ | ✓ | |||||
| 名刺 | ✓ | ✓ | ✓ | |||||
| カスタム フォーム | ✓ | ✓ | ✓ | ✓ | ✓ |
入力の要件
サポートされているファイル形式:
| モデル | 画像: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Microsoft Office: Word ( DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML |
|
|---|---|---|---|
| 読み込み | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| 一般的なドキュメント | ✔ | ✔ | |
| 事前構築済み | ✔ | ✔ | |
| カスタム抽出 | ✔ | ✔ | |
| カスタム分類 | ✔ | ✔ | ✔ |
最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
PDF および TIFF の場合、最大 2,000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは
4MB です。画像のディメンションは、50 ピクセル x 50 ピクセルから 10,000 ピクセル x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、150 DPI (1 インチあたりのドット数) で約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は
1GB です。カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GB で、最大 10,000 ページです。 2024-11-30 (GA) の場合、トレーニング データの合計サイズは2GB で、最大 10,000 ページです。
Note
サンプル ラベル付けツールでは、BMP ファイル形式はサポートされていません。 これは、Document Intelligence サービスではなくツールの制限です。
バージョンの移行
アプリケーションで Document Intelligence v3.0 を使用する方法については、Document Intelligence v3.1 移行ガイドに関する記事を参照してください
次のステップ
Document Intelligence Studio を使用して独自のフォームとドキュメントの処理を試す。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始します。
Document Intelligence サンプル ラベル付けツールを使用して独自のフォームとドキュメントの処理を試す。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始します。