モデルのカスタマイズ (バージョン 4.0 プレビュー)
重要
この機能は非推奨になりました。 2025 年 3 月 31 日に、Azure AI Image Analysis 4.0 のカスタム画像分類、カスタム物体検出、製品認識のプレビュー API は廃止されます。 この日付以降、これらのサービスへの API 呼び出しは失敗します。
モデルの円滑な動作を維持するには、現在一般提供されている Azure AI Custom Vision に移行してください。 Custom Vision は、これらの廃止機能と同様の機能を提供しています。
モデルのカスタマイズを使用すると、独自のユース ケース用に特殊なImage Analysisモデルをトレーニングできます。 カスタム モデルでは、画像分類 (タグは画像全体に適用されます) または物体検出 (タグは画像の特定の領域に適用されます) のいずれかを実行できます。 カスタム モデルを作成してトレーニングすると、そのモデルは Vision リソースに属し、Analyze Image API を使用して呼び出すことができます。
クイックスタートに従って、モデルのカスタマイズを迅速かつ簡単に実装します。
重要
Custom Vision サービスまたは Image Analysis 4.0 サービスとモデルのカスタマイズを使用して、カスタム モデルをトレーニングできます。 次の表は、この 2 つのサービスを比較しています。
| Areas | Custom Vision Service | Image Analysis 4.0 サービス | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| タスク | 画像分類 物体検出 |
画像分類 物体検出 |
||||||||||||||||||||||||||||||||||||
| 基本モデル | CNN | トランスフォーマー モデル | ||||||||||||||||||||||||||||||||||||
| ラベル | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Web ポータル | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| ライブラリ | REST、SDK | REST、Python サンプル | ||||||||||||||||||||||||||||||||||||
| 必要最小限のトレーニング データ | カテゴリごとに 15 個のイメージ | カテゴリごとに 2-5 個のイメージ | ||||||||||||||||||||||||||||||||||||
| トレーニング データのストレージ | サービスにアップロード済み | 顧客の BLOB ストレージ アカウント | ||||||||||||||||||||||||||||||||||||
| モデルのホスティング | クラウドとエッジ | クラウド ホスティングのみ、エッジ コンテナー ホスティングは今後予定されています | ||||||||||||||||||||||||||||||||||||
| AI の品質 |
|
|
||||||||||||||||||||||||||||||||||||
| 価格 | Custom Vision の価格 | 画像分析の価格 |
シナリオのコンポーネント
モデル カスタマイズ システムの主なコンポーネントは、トレーニング イメージ、COCO ファイル、データセット オブジェクト、モデル オブジェクトです。
トレーニング 画像
トレーニング 画像のセットには、検出する各ラベルの例をいくつか含める必要があります。 トレーニングを行ったら、追加の画像をいくつか収集し、モデルをテストすることもお勧めします。 モデルからアクセスできるようにするには、イメージを Azure Storage コンテナーに保存する必要があります。
モデルを効果的にトレーニングするには、視覚的に多様性のある画像を使用します。 以下の点で変化に富んだ画像を選択してください。
- カメラのアングル
- 照明
- background
- 見た目のスタイル
- 個人またはグループになっている被写体
- size
- type
さらに、すべてのトレーニング画像が以下の条件を満たしていることを確認します。
- 画像は JPEG、PNG、GIF、BMP、WEBP、ICO、TIFF、または MPO 形式で表示する必要があります。
- 画像のファイル サイズは、20 メガバイト (MB) 未満である必要があります。
- 画像のディメンションは、50 x 50 ピクセルより大きく、16,000 x 16,000 ピクセル未満である必要があります。
COCO ファイル
COCO ファイルは、すべてのトレーニング 画像を参照し、ラベル付け情報に関連付けます。 物体検出の場合は、各画像の各タグの境界ボックス座標を指定しました。 このファイルは、特定の種類の JSON ファイルである COCO 形式である必要があります。 COCO ファイルは、トレーニング イメージと同じ Azure Storage コンテナーに保存する必要があります。
ヒント
COCO ファイルについて
COCO ファイルは以下の"images"、"annotations"および "categories"のように特定の必須フィールド を持つ JSON ファイルです。 サンプルの COCO ファイル は次のようになります:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
COCO ファイル フィールドリファレンス
独自の COCO ファイルを最初から生成する場合は、すべての必須フィールドに正しい詳細が入力されていることを確認します。 次の表では、COCO ファイルの各フィールドについて説明します:
「イメージ」
| キー | Type | 説明 | 必須 |
|---|---|---|---|
id |
整数 | 1 から始まる一意のイメージ ID | はい |
width |
整数 (integer) | 画像の幅 (ピクセル単位) | はい |
height |
整数 (integer) | 画像の高さ (ピクセル単位) | はい |
file_name |
string | イメージの一意の名前 | はい |
absolute_url または coco_url |
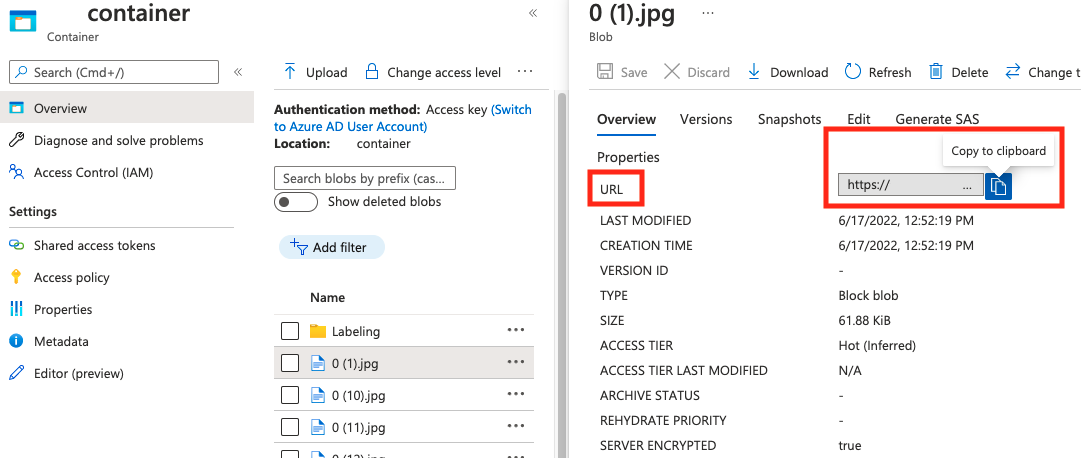
string | BLOB コンテナー内の BLOB への絶対 URI としてのイメージ パス。 Vision リソースには、注釈ファイルと参照されているすべてのイメージ ファイルを読み取るアクセス許可が必要です。 | はい |
absolute_url の 値は、BLOB コンテナーのプロパティにあります。
「注釈」
| キー | Type | 説明 | 必須 |
|---|---|---|---|
id |
整数 | 注釈の ID | はい |
category_id |
整数 (integer) |
categories セクションで定義されているカテゴリの ID |
はい |
image_id |
整数 (integer) | イメージの ID | はい |
area |
整数 (integer) | '幅' x '高さ' の値 (の 3 番目と 4 番目のbboxの値) |
いいえ |
bbox |
リスト[float] | 境界ボックスの相対座標 (0 から 1)、'左'、'上'、'幅'、'高さ' の順 | はい |
「カテゴリ」
| キー | Type | 説明 | 必須 |
|---|---|---|---|
id |
整数 | 各カテゴリの一意の ID (ラベル クラス)。 これらはannotations セクションに存在する 必要があります。 |
はい |
name |
string | カテゴリの名前 (ラベル クラス) | はい |
COCO ファイルの確認
COCO ファイルの形式を確認するには、Microsoft の Python サンプル コードを使用できます。
データセット オブジェクト
データセット オブジェクトは、関連付けファイルを参照する Image Analysis サービスによって保存されるデータ構造です。 モデルを作成してトレーニングする前に、 データセット オブジェクトを作成する必要があります。
モデル オブジェクト
モデル オブジェクトは、カスタム モデルを表す Image Analysis サービスによって保存されるデータ構造です。 初期トレーニングを行うには、 データセット に関連付ける必要があります。 トレーニングが完了したら、 Analyze Image API 呼び出し のmodel-nameクエリ パラメーターにその名前を入力して、モデルのクエリを実行できます。
クォータ制限
次の表では、カスタム モデル プロジェクトのスケールの制限について説明します。
| カテゴリ | 汎用画像分類器 | 汎用オブジェクト検出機能 |
|---|---|---|
| 最大 # トレーニング時間 | 288 (12 日) | 288 (12 日) |
| 最大 # トレーニングイメージ | 1,000,000 | 200,000 |
| 最大 # 評価イメージ | 100,000 | 100,000 |
| カテゴリごとの最小 # トレーニング 画像 | 2 | 2 |
| 最大 # イメージごとのタグ | 1 | 該当なし |
| 最大 # イメージごとの領域 | 該当なし | 1,000 |
| 最大 # カテゴリ | 2,500 | 1,000 |
| 最小 # カテゴリ | 2 | 1 |
| 最大画像サイズ (トレーニング) | 20 MB | 20 MB |
| 最大画像サイズ (予測) | 同期: 6 MB、バッチ: 20 MB | 同期: 6 MB、バッチ: 20 MB |
| 画像の最大幅/高さ (トレーニング) | 10,240 | 10,240 |
| 画像の最小幅/高さ (予測) | 50 | 50 |
| 対応リージョン | 米国西部 2、米国東部、西ヨーロッパ | 米国西部 2、米国東部、西ヨーロッパ |
| 許容される画像の種類 | jpg、png、bmp、gif、JPEG | jpg、png、bmp、gif、JPEG |
よく寄せられる質問
BLOB ストレージからインポートするときに COCO ファイルのインポートが失敗するのはなぜですか?
現在、Microsoft は、Vision Studio で開始すると、大規模なデータセットで COCO ファイルのインポートが失敗する問題に対処しています。 大規模なデータセットを使用してトレーニングするには、代わりに REST API を使用することをお勧めします。
トレーニングに指定した予算よりも長い、または短い時間がかかるのはなぜですか?
指定されたトレーニング予算は、調整された 計算時間であり、 壁掛け時間ではありません。 この違いの一般的な理由を次に示します:
指定した予算より長い:
- Image Analysisではトレーニング トラフィックが高く、GPU リソースが厳しい場合があります。 ジョブはキューで待機するか、トレーニング中に保留にすることができます。
- バックエンド トレーニング プロセスで予期しないエラーが発生し、その結果、ロジックが再試行されました。 失敗した実行では予算は消費されませんが、一般的にトレーニング時間が長くなる可能性があります。
- データは Vision リソースと異なるリージョンに保存されるため、データ転送時間が長くなります。
指定した予算より短い: 次の要因は、特定のウォールクロック時間でより多くの予算を使用するコストでトレーニングを高速化します。
- Image Analysisでは、データに応じて複数の GPU を使用してトレーニングを行う場合があります。
- Image Analysisでは、複数の GPU で同時に複数の探索試行をトレーニングする場合があります。
- Image Analysisでは、プレミア (高速) GPU SKU を使用してトレーニングを行う場合があります。
トレーニングが失敗する理由とは?また、何を行う必要がありますか?
トレーニングエラーの一般的な理由を次に示します:
-
diverged: トレーニングでは、データから意味のあるものを学習できません。 最も一般的な原因を次に示します:- データが十分ではありません。より多くのデータを提供すると役立ちます。
- データの品質が低い: 画像の解像度が低いか、極端な縦横比であるか、注釈が間違っているかを確認します。
-
notEnoughBudget: 指定した予算は、トレーニングしているデータセットとモデルの種類のサイズには不十分です。 より大きな予算を指定します。 -
datasetCorrupt: 通常、これは、指定されたイメージにアクセスできないか、注釈ファイルの形式が間違っていることを意味します。 -
datasetNotFound: データセットが見つかりません -
unknown: これはバックエンドイシューである可能性があります。 調査のサポートに問い合わせてください。
モデルを評価するために使用されるメトリックは何ですか?
次のメトリックが使用されます:
- 画像分類: 平均精度、正確性上位 1、正確性上位 5
- 物体検出: 平均値平均精度 @ 30、平均値平均精度 @ 50、平均値平均精度 @ 75
データセットの登録が失敗する理由とは?
API 応答は十分な情報を提供する必要があります。 これらは次のとおりです。
-
DatasetAlreadyExists:同じ名前のデータセットが存在します -
DatasetInvalidAnnotationUri: 「データセットの登録時に、注釈 URI の中に無効な URI が指定されました。
合理的/良好/最高のモデル品質のために必要な画像はいくつですか?
フィレンツェのモデルには優れた少数ショット機能 (限られたデータ可用性の下で優れたモデル パフォーマンスを実現する) がありますが、一般に、より多くのデータを使用すると、トレーニング済みのモデルがより優れ、堅牢になります。 (バナナに対するリンゴの分類など) データがほとんど必要ないシナリオもあれば、(熱帯雨林で 200 種類の昆虫を検出するなど) 必要なシナリオもあります。 これにより、1 つのレコメンデーションを示すのが困難になります。
データラベル付け予算が制約されている場合は、次のステップを繰り返すワークフローをお勧めします:
クラス ごとに
N画像を収集します。N画像は簡単に収集できます (例:N=3)モデルをトレーニングし、評価セットでテストします。
モデルのパフォーマンスが次の場合:
- 十分です (収集されたデータが少ない前の実験に近いパフォーマンスまたは期待以上のパフォーマンス): ここで停止し、このモデルを使用します。
- 適切ではありません (パフォーマンスは予想を下回っているか、妥当なマージンで収集されたデータが少ない以前の実験よりも優れています):
- 各クラスの画像をさらに収集し、簡単に収集できる数値を収集し、ステップ 2 に戻ります。
- 数回の繰り返しの後にパフォーマンスがこれ以上向上しないことに気付いた場合は、次の理由が考えられます:
- この問題は明確に定義されていないか、難しすぎます。 ケースバイケース解析については、お問い合わせください。
- トレーニング データの品質が低い可能性があります。間違った注釈や非常に低ピクセルの画像があるかどうかを確認します。
どの程度のトレーニング予算を指定する必要がありますか?
使用する予算の上限を指定する必要があります。 Image Analysisでは、バックエンドの AutoML システムを使用してさまざまなモデルを試し、レシピをトレーニングして、ユース ケースに最適なモデルを見つけます。 予算が多いほど、より良いモデルを見つける可能性が高くなります。
AutoML システムは、予算が残っている場合でも、それ以上試す必要がないと判断した場合にも自動的に停止します。 そのため、指定した予算が常に使い果たされるとは限りません。 指定した予算に対して課金されないことが保証されます。
ハイパーパラメーターをコントロールしたり、トレーニングで独自のモデルを使用したりできますか?
いいえ。Image Analysisモデルカスタマイズ サービスでは、バックエンドでのハイパーパラメーター検索と基本モデルの選択を処理するローコードの AutoML トレーニング システムが使用されます。
トレーニング後にモデルをエクスポートできますか?
予測 API は、クラウド サービス経由でのみサポートされます。
物体検出モデルの評価が失敗する理由とは?
次のような理由が考えられます:
-
internalServerError:不明なエラーが発生しました。 後で再度お試しください。 -
modelNotFound: 指定したモデルが見つかりませんでした。 -
datasetNotFound: 指定されたデータセットが見つかりませんでした。 -
datasetAnnotationsInvalid: テスト データセットに関連付けられているグラウンド トゥルース注釈のダウンロードまたは解析中にエラーが発生しました。 -
datasetEmpty: テスト データセットに 「グラウンド トゥルース」 注釈が含まれていませんでした。
カスタム モデルを使用した予測で予想される待機時間は何ですか?
待機時間が長くなる可能性があるため、ビジネス クリティカルな環境にはカスタム モデルを使用しないことをお勧めします。 お客様が Vision Studio でカスタム モデルをトレーニングすると、それらのカスタム モデルはトレーニング対象の Azure AI Vision リソースに属し、お客様は Analyze Image API を使用してそれらのモデルを呼び出すことができます。 これらの呼び出しを行うと、カスタム モデルがメモリに読み込まれ、予測インフラストラクチャが初期化されます。 このような場合、お客様は予測結果を受け取るために予想よりも長い待機時間が発生する可能性があります。
データのプライバシーとセキュリティ
Azure AI サービス全般に言えることですが、Image Analysis モデル カスタマイズを使用する開発者は、顧客データに関する Microsoft のポリシーに留意する必要があります。 詳細については、Microsoft Trust Center の Azure AI サービス ページを参照してください。