クイックスタート: クイックスタート: Custom Vision の Web サイトでオブジェクト検出器を構築する
このクイックスタートでは、Custom Vision Web サイトを使用して、物体検出モデルを作成する方法について説明します。 モデルを作成したら、新しい画像でテストを行い、独自の画像認識アプリに統合することができます。
前提条件
- Azure サブスクリプション。 無料アカウントを作成することができます。
- 検出器モデルのトレーニングに使用する画像のセット。 GitHub 上のサンプル イメージのセットを使用することができます。 または、以下のヒントを使用して、独自の画像を選択しても構いません。
- サポートされる Web ブラウザー。
Custom Vision リソースを作成する
Custom Vision サービスを使用するには、Azure で Custom Vision のトレーニングおよび予測リソースを作成する必要があります。 Azure portal で、[Custom Vision の作成] ページを使用して、トレーニング リソースと予測リソースの両方を作成します。
新しいプロジェクトの作成
Web ブラウザーで、Custom Vision Web ページに移動します。 Azure portal へのサインインに使用したのと同じアカウントでサインインします。
最初のプロジェクトを作成するには、 [新しいプロジェクト] を選択します。 [新しいプロジェクトの作成] ダイアログ ボックスが表示されます。
![[新しいプロジェクト] ダイアログ ボックスのスクリーンショット。名前、説明、ドメインのフィールドがあります。](media/get-started-build-detector/new-project.png)
プロジェクトの名前と説明を入力します。 次に、Custom Vision トレーニング リソースを選択します。 サインインしたアカウントが Azure アカウントに関連付けられている場合は、[リソース] ドロップダウンに、互換性のあるすべての Azure リソースが表示されます。
Note
利用可能なリソースがない場合は、Azure portal へのサインインに使用したのと同じアカウントで customvision.ai にログインしたことを確認してください。 また、Azure portal で Custom Vision リソースを配置したディレクトリと同じ "ディレクトリ" を Custom Vision Web サイトで選択していることを確認してください。 どちらのサイトでも、画面の右上隅にあるドロップダウン アカウント メニューから、ディレクトリを選択できます。
[プロジェクトの種類] では、[物体検出] を選択します。
利用可能なドメインのいずれかを選択します。 各ドメインでは、次の表で説明するように、特定の種類の画像に対する検出器が最適化されます。 必要であれば、後からドメインを変更できます。
ドメイン 目的 全般 さまざまなオブジェクト検出タスク用に最適化されています。 他のドメインのいずれも適切でない場合、またはどのドメインを選択すればよいか不確かな場合は、全般ドメインを選択してください。 ロゴ 画像内のブランド ロゴを探すために最適化されています。 シェルブの製品 シェルブで製品を検出して分類するために最適化されています。 コンパクト ドメイン モバイル デバイス上でのリアルタイムのオブジェクト検出の制約に最適化されています。 コンパクト ドメインで生成されたモデルは、ローカルで実行するためにエクスポートできます。 最後に、[プロジェクトの作成] を選択します。
トレーニング画像を選択する
最低要件として、初期トレーニング セットでは、タグごとに少なくとも 30 枚の画像を使用する必要があります。 また、トレーニング後にモデルをテストするために、いくつかの追加の画像を収集する必要があります。
モデルを効果的にトレーニングするには、視覚的に多様性のある画像を使用します。 以下の点で変化に富んだ画像を選択してください。
- カメラのアングル
- 照明
- background
- 見た目のスタイル
- 個人またはグループになっている被写体
- size
- type
さらに、すべてのトレーニング画像が以下の条件を満たしていることを確認します。
- .jpg、.png、.bmp、.gif のいずれかの形式であること
- サイズが 6 MB (予測画像の場合は 4 MB) 以下であること
- 短辺が 256 ピクセル以上であること。256 ピクセルより短い画像はすべて Custom Vision サービスによって自動的にスケール アップされます
画像をアップロードし、タグ付けする
このセクションでは、検出器のトレーニングに役立つように、画像をアップロードして手動でタグ付けします。
画像を追加するには、 [画像の追加] を選択し、 [ローカル ファイルの参照] を選択します。 [開く] を選択して、画像をアップロードします。
![[画像の追加] ボタンのスクリーンショット。](media/get-started-build-detector/add-images.png)
アップロードした画像が UI の [タグなし] のセクションに表示されます。 次の手順では、検出器による認識の学習対象のオブジェクトに手動でタグを付けます。 最初の画像を選択して、タグ付けのダイアログ ウィンドウを開きます。
![[タグなし] セクション内のアップロードされた画像のスクリーンショット。](media/get-started-build-detector/images-untagged.png)
画像内のオブジェクトの周囲にある四角形を選択してドラッグします。 次に、 [+] ボタンを使用して新しいタグ名を入力するか、ドロップダウン リストで既存のタグを選択します。 検出器は、トレーニングにおいてタグなしの背景領域をネガティブ サンプルとして使用するため、検出したい物体のすべてのインスタンスにタグ付けすることが重要です。 タグ付けが終了したら、右側の矢印を選択してタグを保存し、次の画像に進みます。
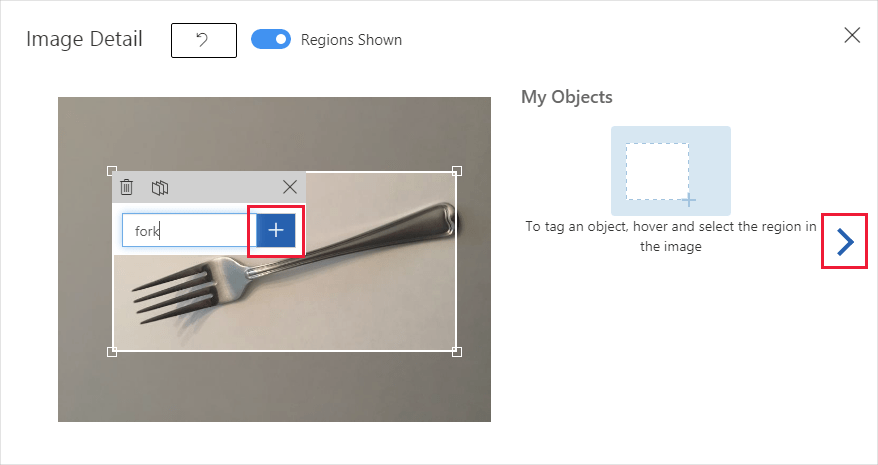
別の画像のセットをアップロードするには、このセクションの先頭に戻り、手順を繰り返します。
検出器をトレーニングする
検出器モデルをトレーニングするには、[トレーニング] ボタンを選択します。 検出器は、現在のすべての画像とタグを使用し、タグ付けされた各オブジェクトを識別するモデルを作成します。 この処理は数分かかる場合があります。

トレーニング プロセスの所要時間は、わずか数分間のはずです。 この時間の間、[パフォーマンス] タブにトレーニング プロセスに関する情報が表示されます。
検出器を評価する
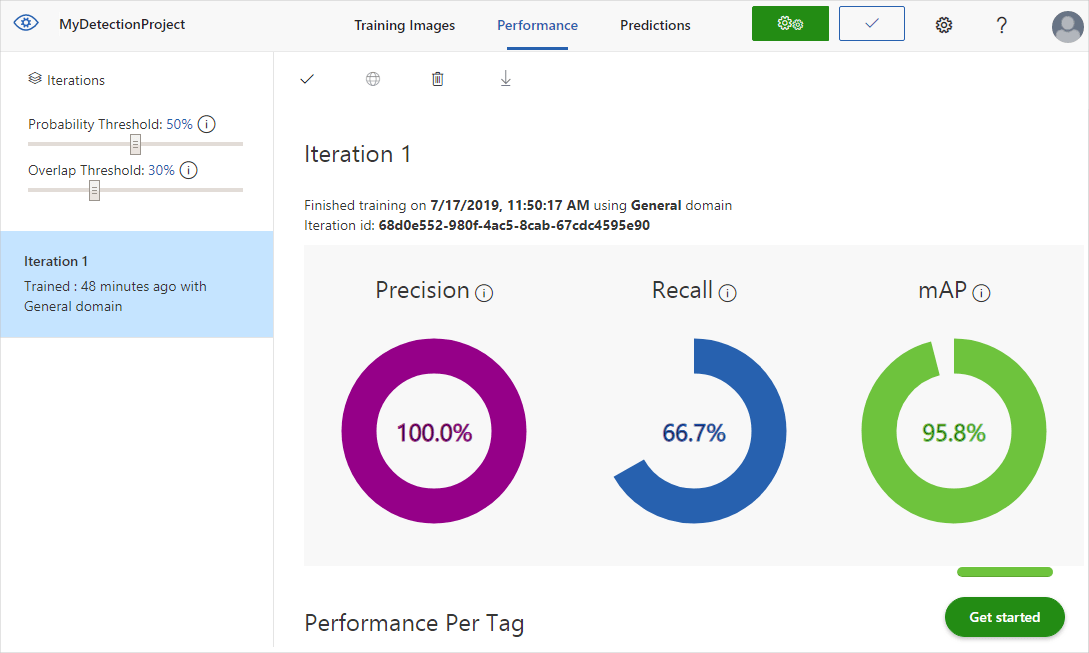
トレーニングが完了すると、モデルのパフォーマンスが計算され表示されます。 Custom Vision サービスは、トレーニング用に送信した画像を利用して精度、再現率、および平均精度を計算します。 精度と再現率は、検出器の有効性を表す 2 つの異なる測定値です。
- 精度は、正しかったと識別された分類の割合を示します。 たとえばあるモデルで、100 個の画像が犬として識別され、それらのうち 99 個が実際に犬であった場合、精度は 99% になります。
- 再現率は、正しく識別された実際の分類の割合を示します。 たとえば、実際にりんごである画像が 100 個あり、そのモデルで、80 個がりんごとして識別された場合、再現率は 80% になります。
- 平均精度は、平均精度 (AP) の平均値です。 AP は、精度/再現率曲線 (行われた各予測の再現率に対してプロットされた精度) の下の領域です。
確率しきい値
[パフォーマンス] タブの左ウィンドウにある 確率しきい値 スライダーに注目してください。これは、正しいと見なされるために予測で必要となる信頼度です (精度と再現率を計算するため)。
高い確率しきい値を指定した予測呼び出しを解釈する場合、再現率を犠牲にして高い精度で結果が返される傾向があります。検出される分類は正しいですが、多くは検出されないままです。 低い確率しきい値はその逆を行います。実際の分類のほとんどが検出されますが、そのセット内には誤検知が多くあります。 これを念頭に置いて、プロジェクトの具体的な必要に応じて確率しきい値を設定する必要があります。 その後、クライアント側で予測結果を受け取る場合は、ここで使用したのと同じ確率しきい値の値を使用する必要があります。
オーバーラップしきい値
[重複しきい値] スライダーでは、トレーニングにおいて、ある物体の予測が "正しい" と見なされるために満たさなければいけない正しさの尺度を操作します。 予測されるオブジェクトの境界ボックスと実際のユーザー入力の境界ボックスの間で許容される最小の重複を設定します。 境界ボックスの重複程度がこれに及ばない場合、予測は正しいと見なされません。
トレーニングのイテレーションを管理する
検出器をトレーニングするたびに、独自に更新したパフォーマンス メトリックを使用して、新しいイテレーションを作成します。 [パフォーマンス] タブの左側ウィンドウで、すべてのイテレーションを参照できます。左側ペインには、[削除] ボタンも表示されます。これはイテレーションが古くなっている場合にそれを削除するために使用できます。 イテレーションを削除すると、それに一意に関連付けられていた画像がすべて削除されます。
トレーニング済みモデルにプログラムでアクセスする方法については、「Prediction API によるモデルの使用」を参照してください。
次のステップ
このクイックスタートでは、Custom Vision Web サイトを使用して、オブジェクト検出器モデルを作成し、トレーニングする方法について説明しました。 次に、モデルを改善するための反復的プロセスについて、より多くの情報を入手してください。
概要については、「Custom Vision とは?」を参照してください