Azure AI モデル推論を使用してチャット入力候補を生成する方法
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
この記事では、Azure AI サービスの Azure AI モデル推論にデプロイされたモデルでチャット入力候補 API を使用する方法について説明します。
前提条件
アプリケーションでチャット入力候補モデルを使用するには、次のものが必要です。
Azure サブスクリプション。 GitHub モデルを使用している場合は、エクスペリエンスをアップグレードし、プロセスで Azure サブスクリプションを作成できます。 このような場合は、「GitHub モデルから Azure AI モデル推論にアップグレードする」をお読みください。
Azure AI サービス リソース。 詳細については、「Azure AI サービス リソースを作成する」を参照してください。
エンドポイント URL とキー。

チャット入力候補モデルのデプロイ。 ない場合は、Azure AI サービスにモデルを追加して構成するに関するページを読んで、チャット入力候補モデルをリソースに追加してください。
次のコマンドを使用して Python 用 Azure AI 推論パッケージをインストールします。
pip install -U azure-ai-inference
チャット入力候補を使用する
まず、モデルを実行するクライアントを作成します。 次のコードでは、環境変数に格納されているエンドポイント URL とキーを使用しています。
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
Microsoft Entra ID をサポートするリソースを構成してある場合、次のコード スニペットを使用してクライアントを作成できます。
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
チャット入力候補要求を作成する
次の例に、モデルに対する基本的なチャット入力候補要求を作成する方法を示します。
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
Note
一部のモデルでは、システム メッセージ (role="system") がサポートされていません。 Azure AI モデル推論 API を使用すると、システム メッセージは最も近い機能で使用できるユーザー メッセージに変換されます。 この翻訳は便宜上提供されているものですが、モデルがシステム メッセージの手順に信頼性の高い正しいレベルで従っているかどうかを確認することが重要です。
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
応答の usage セクションを調べて、プロンプトに使用されたトークンの数、生成されたトークンの合計数、入力候補に使用されたトークンの数を確認します。
コンテンツのストリーミング
既定では、入力候補 API は生成されたコンテンツ全体を 1 つの応答で返します。 長い入力候補を生成する場合、応答が得られるまでに数秒かかることがあります。
コンテンツをストリーミングして、コンテンツが生成されるにつれ返されるようにできます。 コンテンツをストリーミングすると、コンテンツが使用可能になったときに入力候補の処理を開始できます。 このモードは、データのみのサーバー送信イベントとして応答をストリーム バックするオブジェクトを返します。 メッセージ フィールドではなく、デルタ フィールドからチャンクを抽出します。
入力候補をストリーミングするには、モデルを呼び出すときに stream=True を設定します。
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
出力を視覚化するには、ストリームを出力するヘルパー関数を定義します。
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
ストリーミングでコンテンツがどのように生成されるかを視覚化できます。
print_stream(result)
推論クライアントでサポートされているその他のパラメーターを確認する
推論クライアントで指定できるその他のパラメーターを確認します。 サポートされているすべてのパラメーターとそれらのドキュメントの完全な一覧については、Azure AI モデル推論 API リファレンスを参照してください。
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
一部のモデルは、JSON 出力フォーマットをサポートしていません。 モデルに JSON 出力を生成するよう指示できます。 ただし、生成された出力が有効な JSON であるとは限りません。
サポートされているパラメーターの一覧にないパラメーターを渡す場合は、追加のパラメーターを使用して、基になるモデルに渡すことができます。 「モデルに追加のパラメーターを渡す」を参照してください。
JSON 出力を作成する
一部のモデルでは JSON 出力を作成できます。
response_format を json_object に設定すると JSON モードが有効になり、モデルが生成するメッセージが有効な JSON であることが保証されます。 システムまたはユーザー メッセージを使って、ユーザー自身が JSON を生成することをモデルに指示する必要もあります。 また、生成が max_tokens を超えたか、会話がコンテキストの最大長を超えたことを示す finish_reason="length" の場合、メッセージの内容が部分的に切り取られる可能性があります。
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
モデルに追加のパラメーターを渡す
Azure AI モデル推論 API を使用すると、モデルに追加のパラメーターを渡すことができます。 次のコード例に、モデルに追加のパラメーター logprobs を渡す方法を示します。
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Azure AI モデル推論 API に追加のパラメーターを渡す前に、モデルでこれらの追加パラメーターがサポートされていることを確認してください。 基になるモデルに要求を行うと、ヘッダー extra-parameters が値 pass-through でモデルに渡されます。 この値は、追加のパラメーターをモデルに渡すようエンドポイントに指示します。 モデルで追加のパラメーターを使用しても、モデルで実際に処理できるとは限りません。 モデルのドキュメントを参照して、サポートされている追加パラメーターを確認してください。
ツールの使用
一部のモデルではツールの使用がサポートされており、言語モデルから特定のタスクをオフロードし、より決定論的なシステムや別の言語モデルに依存する必要がある場合に、特別なリソースになります。 Azure AI モデル推論 API では、次のようにツールを定義できます。
次のコード例では、2 つの異なる都市からのフライト情報を検索できるツール定義を作成します。
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
この例では、関数の出力では選択されたルートで利用可能なフライトがないため、ユーザーは電車に乗ることを検討する必要があります。
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
Note
Cohere モデルでは、ツールの応答が文字列として書式設定された有効な JSON コンテンツであることが必要です。 Tool 型のメッセージを構築する場合、応答が有効な JSON 文字列であることを確認してください。
この機能を使用して、モデルにフライトの予約を求めます。
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
ツールを呼び出す必要があるかどうかを調べるために、応答を検査できます。 ツールを呼び出す必要があるか判断するために、終了した理由を検査します。 複数のツールの種類を指定できることを忘れないでください。 この例は、種類 function のツールを示しています。
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
続行するには、このメッセージをチャット履歴に追加します。
messages.append(
response_message
)
ここで、ツール呼び出しを処理するための適切な関数を呼び出します。 次のコード スニペットは、応答に示されたすべてのツール呼び出しを反復処理し、適切なパラメーターを指定して対応する関数を呼び出します。 応答はチャット履歴にも追加されます。
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
モデルからの応答を表示します。
response = client.complete(
messages=messages,
tools=tools,
)
コンテンツの安全性を適用する
Azure AI モデル推論 API は、Azure AI Content Safety をサポートしています。 Azure AI Content Safety をオンにしてデプロイを使用すると、入力と出力は、有害なコンテンツの出力を検出して防ぐことを目的とした一連の分類モデルを通過します。 コンテンツ フィルタリング システムは、入力プロンプトと (出力される) 入力候補の両方で、有害な可能性があるコンテンツ特有のカテゴリを検出し、アクションを実行します。
次の例に、モデルが入力プロンプトで有害なコンテンツを検出し、コンテンツの安全性が有効になっている場合にイベントを処理する方法を示しています。
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
ヒント
Azure AI Content Safety 設定を構成および制御する方法の詳細については、Azure AI Content Safety のドキュメントを参照してください。
画像でチャット入力候補を使用する
一部のモデルは、テキストと画像にわたって推論を行い、両方の種類の入力に基づいてテキスト入力候補を生成できます。 このセクションでは、ビジョン用の一部のモデルの機能をチャット形式で確認します。
重要
一部のモデルがチャット会話内の各ターンでサポートする画像は 1 つだけであり、最後の画像だけがコンテキスト内に保持されます。 複数の画像を追加すると、エラーが発生します。
この機能を確認するには、画像をダウンロードし、情報を base64 文字列としてエンコードします。 結果のデータは、データ URL 内にある必要があります。
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
画像の視覚化:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

次に、画像を使用してチャット入力候補要求を作成します。
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
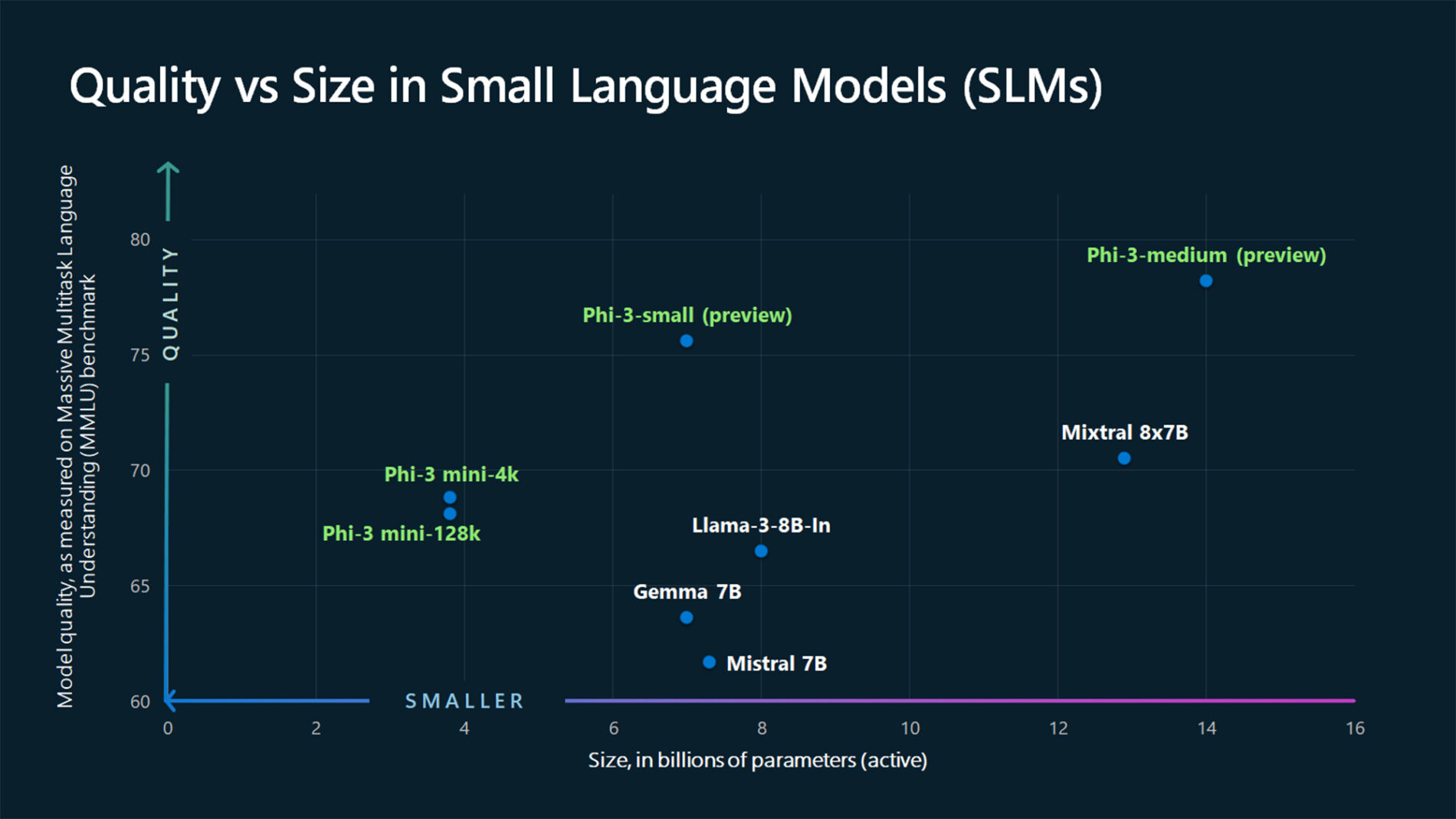
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
この記事では、Azure AI サービスの Azure AI モデル推論にデプロイされたモデルでチャット入力候補 API を使用する方法について説明します。
前提条件
アプリケーションでチャット入力候補モデルを使用するには、次のものが必要です。
Azure サブスクリプション。 GitHub モデルを使用している場合は、エクスペリエンスをアップグレードし、プロセスで Azure サブスクリプションを作成できます。 このような場合は、「GitHub モデルから Azure AI モデル推論にアップグレードする」をお読みください。
Azure AI サービス リソース。 詳細については、「Azure AI サービス リソースを作成する」を参照してください。
エンドポイント URL とキー。
チャット入力候補モデルのデプロイ。 ない場合は、Azure AI サービスにモデルを追加して構成するに関するページを読んで、チャット入力候補モデルをリソースに追加してください。
次のコマンドを使用して、JavaScript 用 Azure 推論ライブラリをインストールします。
npm install @azure-rest/ai-inference
チャット入力候補を使用する
まず、モデルを実行するクライアントを作成します。 次のコードでは、環境変数に格納されているエンドポイント URL とキーを使用しています。
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Microsoft Entra ID をサポートするリソースを構成してある場合、次のコード スニペットを使用してクライアントを作成できます。
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
チャット入力候補要求を作成する
次の例に、モデルに対する基本的なチャット入力候補要求を作成する方法を示します。
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
Note
一部のモデルでは、システム メッセージ (role="system") がサポートされていません。 Azure AI モデル推論 API を使用すると、システム メッセージは最も近い機能で使用できるユーザー メッセージに変換されます。 この翻訳は便宜上提供されているものですが、モデルがシステム メッセージの手順に信頼性の高い正しいレベルで従っているかどうかを確認することが重要です。
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
応答の usage セクションを調べて、プロンプトに使用されたトークンの数、生成されたトークンの合計数、入力候補に使用されたトークンの数を確認します。
コンテンツのストリーミング
既定では、入力候補 API は生成されたコンテンツ全体を 1 つの応答で返します。 長い入力候補を生成する場合、応答が得られるまでに数秒かかることがあります。
コンテンツをストリーミングして、コンテンツが生成されるにつれ返されるようにできます。 コンテンツをストリーミングすると、コンテンツが使用可能になったときに入力候補の処理を開始できます。 このモードは、データのみのサーバー送信イベントとして応答をストリーム バックするオブジェクトを返します。 メッセージ フィールドではなく、デルタ フィールドからチャンクを抽出します。
入力候補をストリーミングするには、モデルを呼び出すときに .asNodeStream() を使用します。
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
ストリーミングでコンテンツがどのように生成されるかを視覚化できます。
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
推論クライアントでサポートされているその他のパラメーターを確認する
推論クライアントで指定できるその他のパラメーターを確認します。 サポートされているすべてのパラメーターとそれらのドキュメントの完全な一覧については、Azure AI モデル推論 API リファレンスを参照してください。
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
一部のモデルは、JSON 出力フォーマットをサポートしていません。 モデルに JSON 出力を生成するよう指示できます。 ただし、生成された出力が有効な JSON であるとは限りません。
サポートされているパラメーターの一覧にないパラメーターを渡す場合は、追加のパラメーターを使用して、基になるモデルに渡すことができます。 「モデルに追加のパラメーターを渡す」を参照してください。
JSON 出力を作成する
一部のモデルでは JSON 出力を作成できます。
response_format を json_object に設定すると JSON モードが有効になり、モデルが生成するメッセージが有効な JSON であることが保証されます。 システムまたはユーザー メッセージを使って、ユーザー自身が JSON を生成することをモデルに指示する必要もあります。 また、生成が max_tokens を超えたか、会話がコンテキストの最大長を超えたことを示す finish_reason="length" の場合、メッセージの内容が部分的に切り取られる可能性があります。
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
モデルに追加のパラメーターを渡す
Azure AI モデル推論 API を使用すると、モデルに追加のパラメーターを渡すことができます。 次のコード例に、モデルに追加のパラメーター logprobs を渡す方法を示します。
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Azure AI モデル推論 API に追加のパラメーターを渡す前に、モデルでこれらの追加パラメーターがサポートされていることを確認してください。 基になるモデルに要求を行うと、ヘッダー extra-parameters が値 pass-through でモデルに渡されます。 この値は、追加のパラメーターをモデルに渡すようエンドポイントに指示します。 モデルで追加のパラメーターを使用しても、モデルで実際に処理できるとは限りません。 モデルのドキュメントを参照して、サポートされている追加パラメーターを確認してください。
ツールの使用
一部のモデルではツールの使用がサポートされており、言語モデルから特定のタスクをオフロードし、より決定論的なシステムや別の言語モデルに依存する必要がある場合に、特別なリソースになります。 Azure AI モデル推論 API では、次のようにツールを定義できます。
次のコード例では、2 つの異なる都市からのフライト情報を検索できるツール定義を作成します。
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
この例では、関数の出力では選択されたルートで利用可能なフライトがないため、ユーザーは電車に乗ることを検討する必要があります。
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
Note
Cohere モデルでは、ツールの応答が文字列として書式設定された有効な JSON コンテンツであることが必要です。 Tool 型のメッセージを構築する場合、応答が有効な JSON 文字列であることを確認してください。
この機能を使用して、モデルにフライトの予約を求めます。
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
ツールを呼び出す必要があるかどうかを調べるために、応答を検査できます。 ツールを呼び出す必要があるか判断するために、終了した理由を検査します。 複数のツールの種類を指定できることを忘れないでください。 この例は、種類 function のツールを示しています。
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
続行するには、このメッセージをチャット履歴に追加します。
messages.push(response_message);
ここで、ツール呼び出しを処理するための適切な関数を呼び出します。 次のコード スニペットは、応答に示されたすべてのツール呼び出しを反復処理し、適切なパラメーターを指定して対応する関数を呼び出します。 応答はチャット履歴にも追加されます。
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
モデルからの応答を表示します。
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
コンテンツの安全性を適用する
Azure AI モデル推論 API は、Azure AI Content Safety をサポートしています。 Azure AI Content Safety をオンにしてデプロイを使用すると、入力と出力は、有害なコンテンツの出力を検出して防ぐことを目的とした一連の分類モデルを通過します。 コンテンツ フィルタリング システムは、入力プロンプトと (出力される) 入力候補の両方で、有害な可能性があるコンテンツ特有のカテゴリを検出し、アクションを実行します。
次の例に、モデルが入力プロンプトで有害なコンテンツを検出し、コンテンツの安全性が有効になっている場合にイベントを処理する方法を示しています。
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
ヒント
Azure AI Content Safety 設定を構成および制御する方法の詳細については、Azure AI Content Safety のドキュメントを参照してください。
画像でチャット入力候補を使用する
一部のモデルは、テキストと画像にわたって推論を行い、両方の種類の入力に基づいてテキスト入力候補を生成できます。 このセクションでは、ビジョン用の一部のモデルの機能をチャット形式で確認します。
重要
一部のモデルがチャット会話内の各ターンでサポートする画像は 1 つだけであり、最後の画像だけがコンテキスト内に保持されます。 複数の画像を追加すると、エラーが発生します。
この機能を確認するには、画像をダウンロードし、情報を base64 文字列としてエンコードします。 結果のデータは、データ URL 内にある必要があります。
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
画像の視覚化:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
次に、画像を使用してチャット入力候補要求を作成します。
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
この記事では、Azure AI サービスの Azure AI モデル推論にデプロイされたモデルでチャット入力候補 API を使用する方法について説明します。
前提条件
アプリケーションでチャット入力候補モデルを使用するには、次のものが必要です。
Azure サブスクリプション。 GitHub モデルを使用している場合は、エクスペリエンスをアップグレードし、プロセスで Azure サブスクリプションを作成できます。 このような場合は、「GitHub モデルから Azure AI モデル推論にアップグレードする」をお読みください。
Azure AI サービス リソース。 詳細については、「Azure AI サービス リソースを作成する」を参照してください。
エンドポイント URL とキー。
チャット入力候補モデルのデプロイ。 ない場合は、Azure AI サービスにモデルを追加して構成するに関するページを読んで、チャット入力候補モデルをリソースに追加してください。
プロジェクトに Azure AI 推論パッケージを追加します。
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Entra ID を使用する場合は、次のパッケージも必要です。
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>次の名前空間をインポートします。
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
チャット入力候補を使用する
まず、モデルを実行するクライアントを作成します。 次のコードでは、環境変数に格納されているエンドポイント URL とキーを使用しています。
Microsoft Entra ID をサポートするリソースを構成してある場合、次のコード スニペットを使用してクライアントを作成できます。
チャット入力候補要求を作成する
次の例に、モデルに対する基本的なチャット入力候補要求を作成する方法を示します。
Note
一部のモデルでは、システム メッセージ (role="system") がサポートされていません。 Azure AI モデル推論 API を使用すると、システム メッセージは最も近い機能で使用できるユーザー メッセージに変換されます。 この翻訳は便宜上提供されているものですが、モデルがシステム メッセージの手順に信頼性の高い正しいレベルで従っているかどうかを確認することが重要です。
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
応答の usage セクションを調べて、プロンプトに使用されたトークンの数、生成されたトークンの合計数、入力候補に使用されたトークンの数を確認します。
コンテンツのストリーミング
既定では、入力候補 API は生成されたコンテンツ全体を 1 つの応答で返します。 長い入力候補を生成する場合、応答が得られるまでに数秒かかることがあります。
コンテンツをストリーミングして、コンテンツが生成されるにつれ返されるようにできます。 コンテンツをストリーミングすると、コンテンツが使用可能になったときに入力候補の処理を開始できます。 このモードは、データのみのサーバー送信イベントとして応答をストリーム バックするオブジェクトを返します。 メッセージ フィールドではなく、デルタ フィールドからチャンクを抽出します。
ストリーミングでコンテンツがどのように生成されるかを視覚化できます。
推論クライアントでサポートされているその他のパラメーターを確認する
推論クライアントで指定できるその他のパラメーターを確認します。 サポートされているすべてのパラメーターとそれらのドキュメントの完全な一覧については、Azure AI モデル推論 API リファレンスを参照してください。 一部のモデルは、JSON 出力フォーマットをサポートしていません。 モデルに JSON 出力を生成するよう指示できます。 ただし、生成された出力が有効な JSON であるとは限りません。
サポートされているパラメーターの一覧にないパラメーターを渡す場合は、追加のパラメーターを使用して、基になるモデルに渡すことができます。 「モデルに追加のパラメーターを渡す」を参照してください。
JSON 出力を作成する
一部のモデルでは JSON 出力を作成できます。
response_format を json_object に設定すると JSON モードが有効になり、モデルが生成するメッセージが有効な JSON であることが保証されます。 システムまたはユーザー メッセージを使って、ユーザー自身が JSON を生成することをモデルに指示する必要もあります。 また、生成が max_tokens を超えたか、会話がコンテキストの最大長を超えたことを示す finish_reason="length" の場合、メッセージの内容が部分的に切り取られる可能性があります。
モデルに追加のパラメーターを渡す
Azure AI モデル推論 API を使用すると、モデルに追加のパラメーターを渡すことができます。 次のコード例に、モデルに追加のパラメーター logprobs を渡す方法を示します。
Azure AI モデル推論 API に追加のパラメーターを渡す前に、モデルでこれらの追加パラメーターがサポートされていることを確認してください。 基になるモデルに要求を行うと、ヘッダー extra-parameters が値 pass-through でモデルに渡されます。 この値は、追加のパラメーターをモデルに渡すようエンドポイントに指示します。 モデルで追加のパラメーターを使用しても、モデルで実際に処理できるとは限りません。 モデルのドキュメントを参照して、サポートされている追加パラメーターを確認してください。
ツールの使用
一部のモデルではツールの使用がサポートされており、言語モデルから特定のタスクをオフロードし、より決定論的なシステムや別の言語モデルに依存する必要がある場合に、特別なリソースになります。 Azure AI モデル推論 API では、次のようにツールを定義できます。
次のコード例では、2 つの異なる都市からのフライト情報を検索できるツール定義を作成します。
この例では、関数の出力では選択されたルートで利用可能なフライトがないため、ユーザーは電車に乗ることを検討する必要があります。
Note
Cohere モデルでは、ツールの応答が文字列として書式設定された有効な JSON コンテンツであることが必要です。 Tool 型のメッセージを構築する場合、応答が有効な JSON 文字列であることを確認してください。
この機能を使用して、モデルにフライトの予約を求めます。
ツールを呼び出す必要があるかどうかを調べるために、応答を検査できます。 ツールを呼び出す必要があるか判断するために、終了した理由を検査します。 複数のツールの種類を指定できることを忘れないでください。 この例は、種類 function のツールを示しています。
続行するには、このメッセージをチャット履歴に追加します。
ここで、ツール呼び出しを処理するための適切な関数を呼び出します。 次のコード スニペットは、応答に示されたすべてのツール呼び出しを反復処理し、適切なパラメーターを指定して対応する関数を呼び出します。 応答はチャット履歴にも追加されます。
モデルからの応答を表示します。
コンテンツの安全性を適用する
Azure AI モデル推論 API は、Azure AI Content Safety をサポートしています。 Azure AI Content Safety をオンにしてデプロイを使用すると、入力と出力は、有害なコンテンツの出力を検出して防ぐことを目的とした一連の分類モデルを通過します。 コンテンツ フィルタリング システムは、入力プロンプトと (出力される) 入力候補の両方で、有害な可能性があるコンテンツ特有のカテゴリを検出し、アクションを実行します。
次の例に、モデルが入力プロンプトで有害なコンテンツを検出し、コンテンツの安全性が有効になっている場合にイベントを処理する方法を示しています。
ヒント
Azure AI Content Safety 設定を構成および制御する方法の詳細については、Azure AI Content Safety のドキュメントを参照してください。
画像でチャット入力候補を使用する
一部のモデルは、テキストと画像にわたって推論を行い、両方の種類の入力に基づいてテキスト入力候補を生成できます。 このセクションでは、ビジョン用の一部のモデルの機能をチャット形式で確認します。
重要
一部のモデルがチャット会話内の各ターンでサポートする画像は 1 つだけであり、最後の画像だけがコンテキスト内に保持されます。 複数の画像を追加すると、エラーが発生します。
この機能を確認するには、画像をダウンロードし、情報を base64 文字列としてエンコードします。 結果のデータは、データ URL 内にある必要があります。
画像の視覚化:
次に、画像を使用してチャット入力候補要求を作成します。
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
この記事では、Azure AI サービスの Azure AI モデル推論にデプロイされたモデルでチャット入力候補 API を使用する方法について説明します。
前提条件
アプリケーションでチャット入力候補モデルを使用するには、次のものが必要です。
Azure サブスクリプション。 GitHub モデルを使用している場合は、エクスペリエンスをアップグレードし、プロセスで Azure サブスクリプションを作成できます。 このような場合は、「GitHub モデルから Azure AI モデル推論にアップグレードする」をお読みください。
Azure AI サービス リソース。 詳細については、「Azure AI サービス リソースを作成する」を参照してください。
エンドポイント URL とキー。
チャット入力候補モデルのデプロイ。 ない場合は、Azure AI サービスにモデルを追加して構成するに関するページを読んで、チャット入力候補モデルをリソースに追加してください。
次のコマンドを使用して Azure AI 推論パッケージをインストールします。
dotnet add package Azure.AI.Inference --prereleaseEntra ID を使用する場合は、次のパッケージも必要です。
dotnet add package Azure.Identity
チャット入力候補を使用する
まず、モデルを実行するクライアントを作成します。 次のコードでは、環境変数に格納されているエンドポイント URL とキーを使用しています。
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
);
Microsoft Entra ID をサポートするリソースを構成してある場合、次のコード スニペットを使用してクライアントを作成できます。
TokenCredential credential = new DefaultAzureCredential(includeInteractiveCredentials: true);
AzureAIInferenceClientOptions clientOptions = new AzureAIInferenceClientOptions();
BearerTokenAuthenticationPolicy tokenPolicy = new BearerTokenAuthenticationPolicy(credential, new string[] { "https://cognitiveservices.azure.com/.default" });
clientOptions.AddPolicy(tokenPolicy, HttpPipelinePosition.PerRetry);
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
credential,
clientOptions,
);
チャット入力候補要求を作成する
次の例に、モデルに対する基本的なチャット入力候補要求を作成する方法を示します。
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "mistral-large-2407",
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Note
一部のモデルでは、システム メッセージ (role="system") がサポートされていません。 Azure AI モデル推論 API を使用すると、システム メッセージは最も近い機能で使用できるユーザー メッセージに変換されます。 この翻訳は便宜上提供されているものですが、モデルがシステム メッセージの手順に信頼性の高い正しいレベルで従っているかどうかを確認することが重要です。
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
応答の usage セクションを調べて、プロンプトに使用されたトークンの数、生成されたトークンの合計数、入力候補に使用されたトークンの数を確認します。
コンテンツのストリーミング
既定では、入力候補 API は生成されたコンテンツ全体を 1 つの応答で返します。 長い入力候補を生成する場合、応答が得られるまでに数秒かかることがあります。
コンテンツをストリーミングして、コンテンツが生成されるにつれ返されるようにできます。 コンテンツをストリーミングすると、コンテンツが使用可能になったときに入力候補の処理を開始できます。 このモードは、データのみのサーバー送信イベントとして応答をストリーム バックするオブジェクトを返します。 メッセージ フィールドではなく、デルタ フィールドからチャンクを抽出します。
入力候補をストリーミングするには、モデルを呼び出すときに CompleteStreamingAsync メソッドを使用します。 この例では、呼び出しが非同期メソッドにラップされていることに注意してください。
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096,
Model = "mistral-large-2407",
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
出力を視覚化するには、コンソールにストリームを出力する非同期メソッドを定義します。
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
ストリーミングでコンテンツがどのように生成されるかを視覚化できます。
StreamMessageAsync(client).GetAwaiter().GetResult();
推論クライアントでサポートされているその他のパラメーターを確認する
推論クライアントで指定できるその他のパラメーターを確認します。 サポートされているすべてのパラメーターとそれらのドキュメントの完全な一覧については、Azure AI モデル推論 API リファレンスを参照してください。
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "mistral-large-2407",
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
一部のモデルは、JSON 出力フォーマットをサポートしていません。 モデルに JSON 出力を生成するよう指示できます。 ただし、生成された出力が有効な JSON であるとは限りません。
サポートされているパラメーターの一覧にないパラメーターを渡す場合は、追加のパラメーターを使用して、基になるモデルに渡すことができます。 「モデルに追加のパラメーターを渡す」を参照してください。
JSON 出力を作成する
一部のモデルでは JSON 出力を作成できます。
response_format を json_object に設定すると JSON モードが有効になり、モデルが生成するメッセージが有効な JSON であることが保証されます。 システムまたはユーザー メッセージを使って、ユーザー自身が JSON を生成することをモデルに指示する必要もあります。 また、生成が max_tokens を超えたか、会話がコンテキストの最大長を超えたことを示す finish_reason="length" の場合、メッセージの内容が部分的に切り取られる可能性があります。
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJsonObject(),
Model = "mistral-large-2407",
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
モデルに追加のパラメーターを渡す
Azure AI モデル推論 API を使用すると、モデルに追加のパラメーターを渡すことができます。 次のコード例に、モデルに追加のパラメーター logprobs を渡す方法を示します。
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "mistral-large-2407",
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Azure AI モデル推論 API に追加のパラメーターを渡す前に、モデルでこれらの追加パラメーターがサポートされていることを確認してください。 基になるモデルに要求を行うと、ヘッダー extra-parameters が値 pass-through でモデルに渡されます。 この値は、追加のパラメーターをモデルに渡すようエンドポイントに指示します。 モデルで追加のパラメーターを使用しても、モデルで実際に処理できるとは限りません。 モデルのドキュメントを参照して、サポートされている追加パラメーターを確認してください。
ツールの使用
一部のモデルではツールの使用がサポートされており、言語モデルから特定のタスクをオフロードし、より決定論的なシステムや別の言語モデルに依存する必要がある場合に、特別なリソースになります。 Azure AI モデル推論 API では、次のようにツールを定義できます。
次のコード例では、2 つの異なる都市からのフライト情報を検索できるツール定義を作成します。
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
この例では、関数の出力では選択されたルートで利用可能なフライトがないため、ユーザーは電車に乗ることを検討する必要があります。
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
Note
Cohere モデルでは、ツールの応答が文字列として書式設定された有効な JSON コンテンツであることが必要です。 Tool 型のメッセージを構築する場合、応答が有効な JSON 文字列であることを確認してください。
この機能を使用して、モデルにフライトの予約を求めます。
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory, model: "mistral-large-2407");
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
ツールを呼び出す必要があるかどうかを調べるために、応答を検査できます。 ツールを呼び出す必要があるか判断するために、終了した理由を検査します。 複数のツールの種類を指定できることを忘れないでください。 この例は、種類 function のツールを示しています。
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
続行するには、このメッセージをチャット履歴に追加します。
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
ここで、ツール呼び出しを処理するための適切な関数を呼び出します。 次のコード スニペットは、応答に示されたすべてのツール呼び出しを反復処理し、適切なパラメーターを指定して対応する関数を呼び出します。 応答はチャット履歴にも追加されます。
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
モデルからの応答を表示します。
response = client.Complete(requestOptions);
コンテンツの安全性を適用する
Azure AI モデル推論 API は、Azure AI Content Safety をサポートしています。 Azure AI Content Safety をオンにしてデプロイを使用すると、入力と出力は、有害なコンテンツの出力を検出して防ぐことを目的とした一連の分類モデルを通過します。 コンテンツ フィルタリング システムは、入力プロンプトと (出力される) 入力候補の両方で、有害な可能性があるコンテンツ特有のカテゴリを検出し、アクションを実行します。
次の例に、モデルが入力プロンプトで有害なコンテンツを検出し、コンテンツの安全性が有効になっている場合にイベントを処理する方法を示しています。
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
Model = "mistral-large-2407",
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
ヒント
Azure AI Content Safety 設定を構成および制御する方法の詳細については、Azure AI Content Safety のドキュメントを参照してください。
画像でチャット入力候補を使用する
一部のモデルは、テキストと画像にわたって推論を行い、両方の種類の入力に基づいてテキスト入力候補を生成できます。 このセクションでは、ビジョン用の一部のモデルの機能をチャット形式で確認します。
重要
一部のモデルがチャット会話内の各ターンでサポートする画像は 1 つだけであり、最後の画像だけがコンテキスト内に保持されます。 複数の画像を追加すると、エラーが発生します。
この機能を確認するには、画像をダウンロードし、情報を base64 文字列としてエンコードします。 結果のデータは、データ URL 内にある必要があります。
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
画像の視覚化:
次に、画像を使用してチャット入力候補要求を作成します。
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
Model = "phi-3.5-vision-instruct",
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: phi-3.5-vision-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
この記事では、Azure AI サービスの Azure AI モデル推論にデプロイされたモデルでチャット入力候補 API を使用する方法について説明します。
前提条件
アプリケーションでチャット入力候補モデルを使用するには、次のものが必要です。
Azure サブスクリプション。 GitHub モデルを使用している場合は、エクスペリエンスをアップグレードし、プロセスで Azure サブスクリプションを作成できます。 このような場合は、「GitHub モデルから Azure AI モデル推論にアップグレードする」をお読みください。
Azure AI サービス リソース。 詳細については、「Azure AI サービス リソースを作成する」を参照してください。
エンドポイント URL とキー。
- チャット入力候補モデルのデプロイ。 ない場合は、Azure AI サービスにモデルを追加して構成するに関するページを読んで、チャット入力候補モデルをリソースに追加してください。
チャット入力候補を使用する
テキスト埋め込みを使用するには、ベース URL に追加された /chat/completions ルートと、api-key に示されている資格情報を使用します。
Authorization ヘッダーは、形式 Bearer <key> でもサポートされています。
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Microsoft Entra ID をサポートするリソースを構成してある場合は、Authorization ヘッダーでトークンを渡します。
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
チャット入力候補要求を作成する
次の例に、モデルに対する基本的なチャット入力候補要求を作成する方法を示します。
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
Note
一部のモデルでは、システム メッセージ (role="system") がサポートされていません。 Azure AI モデル推論 API を使用すると、システム メッセージは最も近い機能で使用できるユーザー メッセージに変換されます。 この翻訳は便宜上提供されているものですが、モデルがシステム メッセージの手順に信頼性の高い正しいレベルで従っているかどうかを確認することが重要です。
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
応答の usage セクションを調べて、プロンプトに使用されたトークンの数、生成されたトークンの合計数、入力候補に使用されたトークンの数を確認します。
コンテンツのストリーミング
既定では、入力候補 API は生成されたコンテンツ全体を 1 つの応答で返します。 長い入力候補を生成する場合、応答が得られるまでに数秒かかることがあります。
コンテンツをストリーミングして、コンテンツが生成されるにつれ返されるようにできます。 コンテンツをストリーミングすると、コンテンツが使用可能になったときに入力候補の処理を開始できます。 このモードは、データのみのサーバー送信イベントとして応答をストリーム バックするオブジェクトを返します。 メッセージ フィールドではなく、デルタ フィールドからチャンクを抽出します。
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
ストリーミングでコンテンツがどのように生成されるかを視覚化できます。
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
ストリーム内の最後のメッセージには、生成プロセスが停止した理由を示す finish_reason が設定されています。
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
推論クライアントでサポートされているその他のパラメーターを確認する
推論クライアントで指定できるその他のパラメーターを確認します。 サポートされているすべてのパラメーターとそれらのドキュメントの完全な一覧については、Azure AI モデル推論 API リファレンスを参照してください。
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
一部のモデルは、JSON 出力フォーマットをサポートしていません。 モデルに JSON 出力を生成するよう指示できます。 ただし、生成された出力が有効な JSON であるとは限りません。
サポートされているパラメーターの一覧にないパラメーターを渡す場合は、追加のパラメーターを使用して、基になるモデルに渡すことができます。 「モデルに追加のパラメーターを渡す」を参照してください。
JSON 出力を作成する
一部のモデルでは JSON 出力を作成できます。
response_format を json_object に設定すると JSON モードが有効になり、モデルが生成するメッセージが有効な JSON であることが保証されます。 システムまたはユーザー メッセージを使って、ユーザー自身が JSON を生成することをモデルに指示する必要もあります。 また、生成が max_tokens を超えたか、会話がコンテキストの最大長を超えたことを示す finish_reason="length" の場合、メッセージの内容が部分的に切り取られる可能性があります。
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
モデルに追加のパラメーターを渡す
Azure AI モデル推論 API を使用すると、モデルに追加のパラメーターを渡すことができます。 次のコード例に、モデルに追加のパラメーター logprobs を渡す方法を示します。
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Azure AI モデル推論 API に追加のパラメーターを渡す前に、モデルでこれらの追加パラメーターがサポートされていることを確認してください。 基になるモデルに要求を行うと、ヘッダー extra-parameters が値 pass-through でモデルに渡されます。 この値は、追加のパラメーターをモデルに渡すようエンドポイントに指示します。 モデルで追加のパラメーターを使用しても、モデルで実際に処理できるとは限りません。 モデルのドキュメントを参照して、サポートされている追加パラメーターを確認してください。
ツールの使用
一部のモデルではツールの使用がサポートされており、言語モデルから特定のタスクをオフロードし、より決定論的なシステムや別の言語モデルに依存する必要がある場合に、特別なリソースになります。 Azure AI モデル推論 API では、次のようにツールを定義できます。
次のコード例では、2 つの異なる都市からのフライト情報を検索できるツール定義を作成します。
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
この例では、関数の出力では選択されたルートで利用可能なフライトがないため、ユーザーは電車に乗ることを検討する必要があります。
Note
Cohere モデルでは、ツールの応答が文字列として書式設定された有効な JSON コンテンツであることが必要です。 Tool 型のメッセージを構築する場合、応答が有効な JSON 文字列であることを確認してください。
この機能を使用して、モデルにフライトの予約を求めます。
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
ツールを呼び出す必要があるかどうかを調べるために、応答を検査できます。 ツールを呼び出す必要があるか判断するために、終了した理由を検査します。 複数のツールの種類を指定できることを忘れないでください。 この例は、種類 function のツールを示しています。
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
続行するには、このメッセージをチャット履歴に追加します。
ここで、ツール呼び出しを処理するための適切な関数を呼び出します。 次のコード スニペットは、応答に示されたすべてのツール呼び出しを反復処理し、適切なパラメーターを指定して対応する関数を呼び出します。 応答はチャット履歴にも追加されます。
モデルからの応答を表示します。
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
コンテンツの安全性を適用する
Azure AI モデル推論 API は、Azure AI Content Safety をサポートしています。 Azure AI Content Safety をオンにしてデプロイを使用すると、入力と出力は、有害なコンテンツの出力を検出して防ぐことを目的とした一連の分類モデルを通過します。 コンテンツ フィルタリング システムは、入力プロンプトと (出力される) 入力候補の両方で、有害な可能性があるコンテンツ特有のカテゴリを検出し、アクションを実行します。
次の例に、モデルが入力プロンプトで有害なコンテンツを検出し、コンテンツの安全性が有効になっている場合にイベントを処理する方法を示しています。
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
ヒント
Azure AI Content Safety 設定を構成および制御する方法の詳細については、Azure AI Content Safety のドキュメントを参照してください。
画像でチャット入力候補を使用する
一部のモデルは、テキストと画像にわたって推論を行い、両方の種類の入力に基づいてテキスト入力候補を生成できます。 このセクションでは、ビジョン用の一部のモデルの機能をチャット形式で確認します。
重要
一部のモデルがチャット会話内の各ターンでサポートする画像は 1 つだけであり、最後の画像だけがコンテキスト内に保持されます。 複数の画像を追加すると、エラーが発生します。
この機能を確認するには、画像をダウンロードし、情報を base64 文字列としてエンコードします。 結果のデータは、データ URL 内にある必要があります。
ヒント
スクリプトまたはプログラミング言語を使用してデータ URL を構築する必要があります。 このチュートリアルでは、JPEG 形式のこのサンプル画像を使用します。 データ URL の形式は次のとおりです: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ...。
{kind=link}
画像の視覚化:
次に、画像を使用してチャット入力候補要求を作成します。
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
応答は次のとおりです。モデルの使用状況の統計情報が表示されます。
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}