FAST Search System Overview
Expanding on the brief information in Information on FAST Search Server 2010 for SharePoint, this post is on what the components of FAST search system are and what function they perform. This should help you understand the FAST search system better.
Please note that most information in this post is from [MS-FSSO]: FAST Search System Overview and the Planning and Architecture for FAST Search Server 2010 for SharePoint (Beta) documents. I have tried to summarize the information in 1 post. I have skipped all the references to various Protocols being used for communication between these components to make it simple.
For a more detailed information along with the Protocols please refer to the [MS-FSSO]: FAST Search System Overview document. To drill down even further, you can refer to the complete SharePoint Products and Technologies Protocols document set.
How FAST Search works?
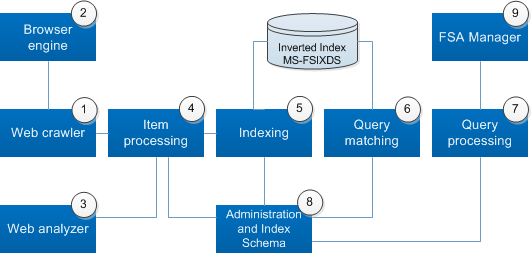
As in any other search system, FAST Search has 4 main parts functionally: content retrieval, content processing, query processing & matching and the administration part. Given below is a quick summary of what happens in each and which component (in bold green font) does it. The next section “Main Services” will cover these components in a bit more detail.
a) Content Retrieval
First, the search system retrieves data. One approach uses an external indexing connector to feed items to the item processing service. Another approach is for the Web crawler service, an indexing connector supplied with the system, to bring items into the system. The Web crawler service reads Web pages and follows links on the pages to process an entire Web site of items. The Web analyzer service analyzes the link structure as part of this process. The Web crawler service uses the browser engine service to convert special types of Web pages. The Web crawler service then passes the items that it brought in to the item processing service.
b) Content Processing
The item processing service extracts the relevant content, and performs linguistic operations. The item processing service then sends the resulting raw text to the indexing service, which creates data structures called inverted indexes. The indexing service sends these inverted indexes to the query matching service.
c) Query Processing & Matching
The query processing service processes queries from protocol clients by performing query transformations, such as synonym expansion, and calls the query matching service. The query matching service uses the inverted indexes to retrieve the relevant items that match a query and returns these items as a query hit list. The query hit list consists of references to the original items, the titles, and other properties of the items. It is the responsibility of the query processing service to make sure that the end user performing a query receives only authorized results.
d) Administration
The index schema service handles system administrative tasks and controls the search experience, such as determining which properties will be visible to end users and how to perform property extraction. The administration component offers additional control of the search experience. Common system administration services include logging, supplying shared storage for configuration files and binary resources, and providing communication middleware. The FAST Search Authorization (FSA) manager service grants access to indexed items.
Main Services
1) Web Crawler Service
The Web crawler service can bring items in to the FAST Search system. The Web crawler service reads Web pages and follows links on the pages to process an entire web of items. The Web crawler service then passes the items that it brought in to the item processing service.
During this process, the Web crawler uses the browser engine service to convert items that are Web pages into regular text and links. The Web crawler service reads a set of configuration files which control the crawl—for example, by specifying the Web servers to crawl and the maximum number of Web pages to download from each Web server. The Web crawler service calls administrative operations, to start, stop, and suspend the Web crawler components on the various nodes.
2) Browser Engine Service
The browser engine service receives processing requests from the Web crawler service and retrieves Web pages from it by using HTTP.
The browser engine service processes Web pages by extracting their content along with any links to other Web pages. The service downloads and evaluates the Web pages and any external dependencies, such as external JavaScript files and style sheets. The service returns the resulting HTML items and link structures to the Web crawler service.
The browser engine service can scale to a large or a small number of nodes to serve more requests and provide fault tolerance. It is the responsibility of the Web crawler service to load-balance requests, to detect whether a node has stopped working, and in that case, to use a different node to provide fault tolerance.
3) Web Analyzer Service
The Web analyzer service has two main functions: to analyze search clickthrough logs and to analyze hyperlink structures. Both analyses contribute to the better ranking of search results. Items that show many clicks in the search clickthrough log are popular and thus receive higher rank scores than less-viewed items. Items that are linked to from many other items are also popular and thus receive higher rank scores than items that are linked to from fewer items.
The Web analyzer service consists of four types of components:
- The search clickthrough component controls the analysis of search clickthrough logs.
- The Web analyzer component controls the analysis of hyperlink structures.
- Both the search clickthrough and the Web analyzer component use processing components to perform the analyses. The processing components do the data processing part of the analyses. The search clickthrough and the Web analyzer components split each analysis into a series of tasks and distribute the tasks among the available processing components.
- The processing components store the results of the analyses in lookup database components. The lookup database components are key-value database servers which support a protocol to access the stored data
4) Item Processing Service
The item processing service receives items to be indexed from indexing connectors. The service performs required processing to prepare the content for indexing. Examples of item processing are mapping of crawled properties to managed properties, parsing of document formats, linguistic normalization of text, and normalization of numeric data.
The item processing service then sends the processed items, in the FAST Index Markup Language (FIXML) format, to the indexing service. The purpose of FIXML is to provide the data structure for a processed item and then to map the data to the search index structures that an index schema specifies. The indexing service uses the FIXML data structure to create the index data structures.
For optimal feeding performance, the item processing service processes and sends the items in batches. The item processing service manages the end-to-end feeding protocol between the indexing connectors and the indexing service. The feeding protocol is asynchronous and uses callbacks to track the status of the item batches moving through the feeding chain. The item processing service forwards these status callbacks to the indexing connector that originally submitted the items.
The item processing service reads a set of configuration files from the configuration component. The configuration files define the following:
- How to normalize characters in items
- How to configure the item processing nodes and how to perform item processing, in detail.
- How to use linguistic resources, such as dictionaries
- How to use the spell tuner component
- The format to use for submitting items to the indexing service
The item processing service transfers item metadata, such as URLs, hyperlinks, and anchor texts, to the Web analyzer service. The Web analyzer service sends updated item metadata, including rank scores, to the item processing service.
The item processing service can scale to a large or a small number of nodes to process more items per time unit.
5) Indexing Service
The indexing service creates inverted indexes, based on the items that it receives. The indexing service sends these inverted indexes to the query matching service for later use during query processing.
An inverted index is a data structure that provides a mapping for every token found in a set of indexed items to a list of items that contain the token. Tokens include ordinary language words, numbers, and alphanumeric sequences. During query processing, the query matching service looks the query up in the inverted index, and if the index contains the query as a token, the query matching service uses the list of items to return the items that match the query.
The indexing service consists of two components, the indexing dispatcher component and the indexing component. If the indexing service is deployed on multiple nodes, these components will also be deployed on multiple nodes. The indexing dispatcher first receives items from the item processing service. In the case of multiple index columns, two or more indexes need to be combined to yield consistent search results. The indexing service transfers the indexes to the query matching service. In a multinode configuration, the query matching components are normally deployed on different computers or virtual servers than the indexing components to avoid performance bottlenecks in the system.
The indexing service is designed to scale according to the number of items. To scale the indexing service up, it is possible to deploy it across more than one index column. Each index column will contain one part of the index, and the combined set of index columns will constitute the entire index. In this case, each indexing node will handle only a fraction of the entire index, thus scaling the indexing service up in terms of both the number of items that it can index per second and the total number of items that it can place in the index.
6) Query Matching Service
The query matching service uses the inverted indexes created by the indexing service to retrieve the items that match a query and then return these items as a query hit list. The query matching service receives query requests the query processing service.
A query usually contains some terms combined with query operators, such as AND and OR. The query matching service looks up each term in the inverted index and retrieves a list of items in which that term appears. In the case of an AND operator, for example, the intersection of the item lists will consist of the set of items that contain all the terms.
This set of items provides the basis for the query hit list that the query matching service returns as a response to the query. In addition, the query matching service looks up the properties of each item, such as the item title, author, and time of indexing, and places these properties in the query hit list. The order of the returned items is based on the requested sorting mechanism.
The query matching service can also return a hit highlighted summary for each item in the query hit list. A hit highlighted summary consists of a fragment of the original item in which the matching query terms are highlighted.
The query matching service is also responsible for the deep refinement that is associated with query results. Query refinement enables drilling down into a query result by using aggregated statistical data that has been computed for the query result. The query matching service maintains aggregation data structures to enable deep refinement across large result sets.
The number of search columns in the query matching service always equals the number of index columns in the indexer service. The reason is that the columns represent a partitioning of the index, and each query matching node can handle only one such partition of the index. In a setup with multiple search rows the search rows are duplicates of one another. The duplicated search rows provide fault tolerance and an increased capacity for queries.
7) Query Processing Service
The query processing service performs the processing of queries and results that can be done without the inverted index. Query processing includes query–language parsing, linguistic processing, and document-level security processing. The query processing service submits a processed query to the query matching service. Each query is sent to one query matching node in each search row. Result processing includes merging the results from multiple index columns, formatting the query hit list, formatting the query refinement data, and removing duplicates.
It is the responsibility of the query processing service to make sure that the end user performing a query receives only the results for which they are authorized. The query processing service thus checks the access rights of the user and rewrites the incoming query with an access filter that corresponds to the current user. The FAST Search Authorization (FSA) manager regularly pushes the information that is needed for the rewrite, and the query processing service combines this information with information from AD DS and Active Directory or other LDAP directory services.
The query processing service can be scaled across multiple nodes to handle more queries per second. In this case, all the nodes need to be set up in an identical manner. In other words, no master query processing nodes or any backup query processing nodes exist, and thus no communication among such components is needed. The service can use various hardware or software solutions for load balancing the incoming queries.
For performance, the query processing service can alternate among the available search rows—for example, by using a round robin algorithm. If one of the search rows fails to respond, the query processing service can exclude this search row from future queries until it becomes available.
8) Administration and Index Schema Service
Common system administration services include logging, supplying shared storage for configuration files and binary resources, and providing communication middleware. In addition, the administration component contains functionality to control the search experience, such as determining how to perform property extraction, ascertaining which synonyms to use, and determining which items to use as best bets.
The middleware consists of a communication protocol that is used by several services in the system. The middleware facilitates synchronous function calls as well as asynchronous message callbacks across computer boundaries. The services can exchange not only basic data types but information represented in the Cheetah serialization format. The Cheetah Data Format Protocol enables the serialization and deserialization of data structures. The serialized form is a compact stream of bytes for persistent storage or network transfer.
Neither scalability nor fault tolerance is provided for administration service. All the components need to run on the same computer or virtual server, except for the internal database of the administration component.
The Index Schema service manages the index schema for the Microsoft FAST Search Server 2010 Beta system. The index schema contains all the configuration entities that are needed to generate the configuration files related to the index schema for all the other services in the system. The index schema service exposes an API through which protocol clients can view and modify the index schema.
The index schema controls which managed properties of an item will be indexed, how the properties will be indexed and which properties can be returned in the query hit list. The index schema also includes a rank profile. The rank profile controls how the rank will be calculated for each item in a query hit list.
The index schema service both receives updates for the current index schema from system administrator and returns information about the schema to system administrator. Most changes to the configuration of the index schema trigger updates to item processing, indexing, query matching, and query processing.
Neither scalability nor fault tolerance is provided for the index schema service.
9) FSA Manager Service
The FAST Search Authorization manager service receives security updates from indexing connectors and then pushes the updates to all the query processing nodes in the system. In addition, the service keeps the security-related configuration of these nodes consistent and synchronizes such configuration changes across multiple query processing nodes.
Neither scalability nor fault tolerance is provided for the authorization manager service.
Deployment
FAST Search is designed to be able to run on a single computer or virtual server, or to scale to a large number of computers or virtual servers. In the latter case, each computer or virtual server runs one or more of the just-described services, resulting in the ability of the system to index a greater number of items, perform a greater number of updates, or respond to more queries per second.
In multiple server deployment, one server is defined as the admin server in the deployment and the administrative services are installed and run on it. The deployment can be scaled out by adding one or more non-admin servers which runs services such as search, indexing, and document processing.
Comments
Anonymous
August 20, 2010
hello, after study Fast Search for sharepoint I post some articles here: blog.xvanneste.com/.../Category.aspx can you tell me what do you think about themAnonymous
October 04, 2010
The comment has been removed