New in Lync 2013 High Avaliablity
Limitations of Lync server 2010
- Lync Server 2010, we had to write all changes to the user state, user contacts, meetings and so on to the Back-End SQL Server. This was causing high IO and we had to limit the number of Front-End Servers per Lync Pool
- The Metropolitan Site Resiliency solution was complex, difficult to implement and had strong requirements regarding the network between the sites (RTT < 20ms, Bandwidth > 1Gbps, Layer 2 broadcast domain for the Pool subnet). We required an external solution for synchronous data replication between the sites
- There was no failover between Lync 2010 Pools and customers had to force move users in case of a disaster with one Pool
- Voice resiliency was available with SBA or SBS, but presence and IM would still fail
New in Lync Server 2013 High Availability
- Remove SQL Back-End bottleneck
- improved DR capabilities
- Reduce infrastructure requirements
this was introduced by the Brick model
Brick Model is a synonym for having all services and data available on the Front-End. We make sure that the data of one FE will be copied to 2 additional FEs synchronously to not lose data in case of a FE loss. The Back-End SQL Server
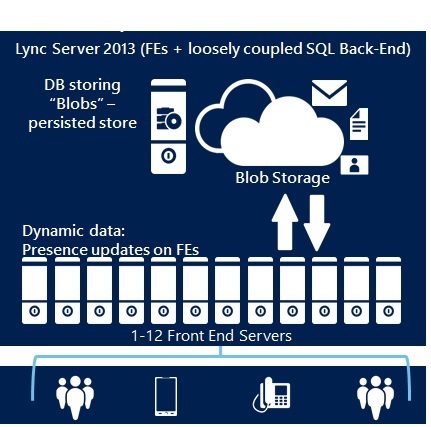
Brick Model
The Brick Model helped removing the limit of 10 FEs per Pool and the bottleneck with the SQL Back-End. With supporting SQL Mirroring, we improved DB availability with less expensive
solutions
In Lync Server 2013, Front End pool architecture has changed, and these changes affect how you should plan and maintain your Front End pools. We recommend that all your Enterprise Edition Front End pools
include at least three Front End Servers. In Lync Server, the architecture of Front End pools uses a distributed systems model, with each user’s data kept on three Front End servers in the pool
Lync 2013 Pool Planning
https://technet.microsoft.com/en-us/library/gg412996.aspx
- With the new design, the Back End database is no longer the real-time data store in a pool. Information about a particular user is kept on three Front End Servers in the pool. For each user, one Front End Server acts as the master for that user’s information, and two other Front End Servers serve as replicas. If a Front End Server goes down, another Front End Server which served as a replica is automatically promoted to master
- This happens behind the scenes, and administrators do not need to know which Front End Servers are the masters for which users. This distribution of data storage improves performance and scalability within the pool, and eliminates the single point of failure of a single Back End Server
- The Back End Server serves as backup storage for user and conference data, and is also the primary storage for other databases such as the Response Group database
- If you do not want to deploy three Enterprise Edition Front End Servers and want high availability and disaster recovery, we recommend you use Lync Server Standard Edition and create two pools with a - paired backup relationship. This will provide the best high availability and disaster recovery solution with only two servers
- if you are going to deploy 2-node pools follow this guidance
- If one of the two Front End Servers goes down, you should try to bring the failed server back up as soon as you can
- If you need to upgrade one of the two servers, bring it back online as soon as the upgrade is finished
- If you need to bring both servers down at the same time, do the following when restarting the servers:
A- Restart both Front End Servers at the same time
B- If the two servers cannot be restarted at the same time, you should bring them back up in the reverse order of the order they went down
C- If you cannot bring them back up in that order, then use the following cmdlet before bringing the pool back up:
- Reset-CsPoolRegistrarState -PoolFQDN {PoolFQDN} -ResetType QuorumLossRecovery
A quorum loss recovery is reset is typically used when the number of active Front End servers in a pool falls below the quorum state (that is, when fewer than 85% of the Front End servers in a pool are currently active).
- Reset-CsPoolRegistrarState -PoolFQDN {PoolFQDN} -ResetType fullreset
The FullReset option is typically used after topology changes or it unrecoverable errors occur when a pool is started
Windows Fabric
- Determine where users are homed (group assignment)
- Returns user location for routing
- Define voter note and Quorum
- Synchronous Data replication
Synchronous Replication: When a user changes his persistent data, it is committed to the user’s Backup Server (up to 2 Backups). For example, if a user’s Primary Server is S1, and Backup Server is S3, S1 does not return success response until the data is committed to S3
Synchronous Replication Features
- Persistent User Data
- Synchronous replication to two more FEs
- Client sees success only if data is written to replicas correctly
- Lazy replication to shared Blob Store
- Ensures that data is available immediately for failovers
- Persistent User Data
X- Synchronous replication to two more FEs(Backup / Replicas
X- Presence, Contacts/Groups, User Voice Setting, Conferences
X- Lazy replication used to commit data to Shared Blob Store (SQL Backend)
X- Deep Chunking is used to reduce Replication Deltas
- Transient User Data
X- Not replicated across Front End servers
X- Presence changes due to user activity, including:
- Calendar
- phone call
- Inactivity
Comments
- Anonymous
March 14, 2014
Thanks for such a wonderful blog - Anonymous
March 17, 2014
amazing blog !! - Anonymous
April 22, 2014
Hi thanks for this, one question, how long does it take for a new master to take over if the previous master fails?
I've been making some tests and it takes over 2 minutes for this to kick in and the users can chat again, am I missing something or is this expected? Thanks - Anonymous
March 17, 2015
The comment has been removed - Anonymous
August 19, 2015
Thanks Tamer for this extremely useful article.