Azure SQL Database: Ingesting 1.4 million sustained rows per second with In-Memory OLTP & Columnstore Index
As Internet of Things (IoT) devices and sensors are becoming more ubiquitous in consumer, business and industrial landscapes, they introduce a unique challenge in terms of the volume of data they produce, and the velocity with which they produce it. The challenge is to ingest and analyze this data at the speed at which it is being generated, in real-time. Azure SQL Database with In-Memory OLTP and Columnstore technologies is phenomenal at ingesting large volumes of data from many different sources at the same time, while providing the ability to analyze current and historical data in real-time.
The following sample demonstrates the high scale and performance of SQL Database, with the ability to insert 1.4 million rows per second by using a non-durable memory-optimized table to speed up data ingestion, while managing the In-Memory OLTP storage footprint by offloading historical data to a disk-based Columnstore table for real time analytics. One of the customers already leveraging Azure SQL Database for their entire IoT solution is Quorum International Inc., who was able to double their key database’s workload while lowering their DTU consumption by 70%.
Sample release and source code: Release | source code
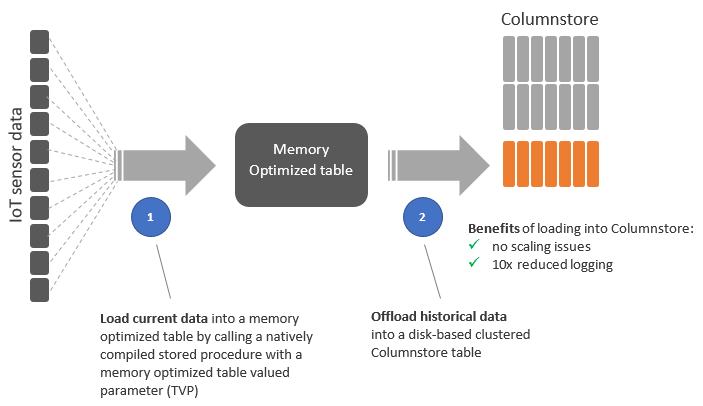
High Level Architecture
{kind=link}
Ingesting Data: IoT sensor data loader
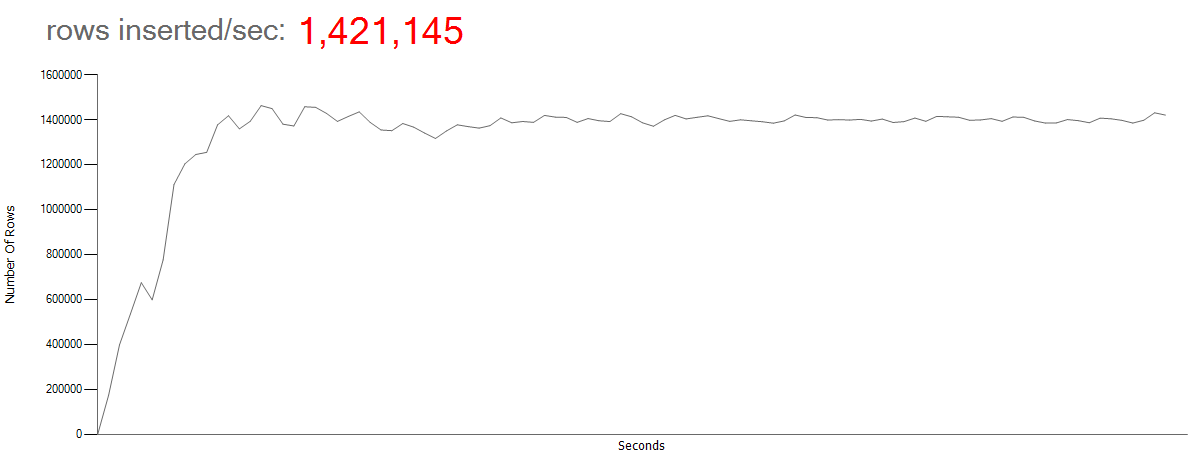
A multi-threaded data loader application (running on a Standard DS15 v2 Azure VM) is used to generate sensor readings that are inserted directly into the dbo.MeterMeasurement schema-only memory optimized table through the dbo.InsertMeterMeasurement natively compiled stored procedure (that accepts a memory optimized table valued parameter). Also, the application is responsible for off-loading historical data to a disk based Columnstore table to manage the In-Memory storage footprint. Below is a screenshot of the data simulator inserting 1.4M rows per second by using a single P15 Premium (4000 DTUs) Azure SQL Database.
Off Loading Data: Bulk load historical data into a clustered Columnstore index
Historical data is offloaded from the In-Memory table to a disk based Columnstore table to manage the In-Memory storage footprint. The dbo.InsertMeterMeasurementHistory stored procedure is called by multiple threads asynchronously to offload historical data into a clustered Columnstore disk-based table. Note that if the batch size is >= 102,400, the rows are loaded directly into the compressed rowgroups, thus it is always recommended that you choose a batch size >=102,400 for efficient bulk import because you can avoid moving data rows to a delta rowgroups before the rows are eventually moved to compressed rowgroups by a background thread, Tuple mover (TM). Please refer to the Columnstore indexes - data loading guidance documentation for further details.
Below is a sample output from sys.dm_db_column_store_row_group_physical_stats during the data load. Note that off loaded data in Columnstore lands directly in compressed state achieving up to 10x query performance gains over traditional row-oriented storage, and up to 10x data compression over the uncompressed data size.

Durability Options for the Memory-Optimized table
Based on your workload characteristics and the nature of your application you can choose between the following two durability options for the memory optimized table that handles the ingestion:
• Non-durable (durability=schema_only) which achieves greater ingestion rates as there is no IO involved since it doesn’t have on-disk representation, thus not offering data persistence.
• Durable (durability=schema_and_data) which provides both schema and data persistence, but lower ingestion rates primarily due to logging.
In this sample, the memory-optimized table: dbo.InsertMeterMeasurement is created with DURABILITY = SCHEMA_ONLY , meaning that in a case of a SQL Server restart or a reconfiguration occurs in the Azure SQL Database, the table schema persists, but the data in the table (that have not yet offloaded to disk based columnstore) is lost. To learn more about the two durability options for memory optimized tables we recommend you to read: Defining Durability for Memory-Optimized Objects .
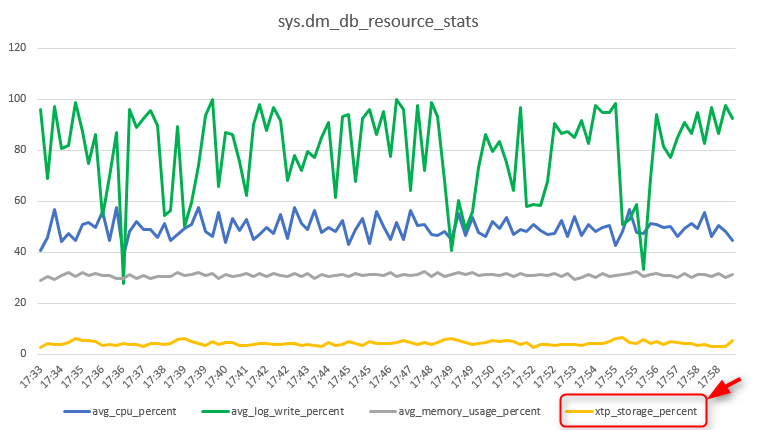
Metrics: CPU, Log, Memory, and xtp_storage from sys.dm_db_resource_stats
Below is a snapshot of CPU, Log, Memory, and xtp_storage metrics from sys.dm_db_resource_stats after a 25-minute run. The xtp_storage_percent metric, which is the storage utilization for In-Memory OLTP in percentage of the limit of the service tier never exceeds 7% on this run (that uses a non-durable memory optimized table), meaning that the offloading to Columnstore is keeping up with the data ingestion of 1.4M rows per second. The overall memory is consistently below 40%, the CPU below 60%, and the log write percent reaches 100% during the offloading.
Further Reading
• A Technical Case Study: High Speed IoT Data Ingestion Using In-Memory OLTP in Azure
• Get started with In-Memory OLTP in Azure SQL Database
• Speeding up transactions with In-Memory OLTP
• In-Memory OLTP in Azure SQL Database
• Columnstore indexes - overview
• Improving temp table and table variable performance using memory optimization
• Official Microsoft GitHub Repository containing code samples for SQL Server
Comments
- Anonymous
November 09, 2017
Um, .... four bytes per "row"?And do you even need a P15 for this? Oh, just for memory size, I guess. Hmm.Interesting article, but I'm not sure quite where you think something like this fits in the universe.- Anonymous
November 09, 2017
Thanks for your comment @JRStern!The sample uses a memory optimized table valued parameter (TVP) to pass artificial data sensor measurements to the natively compiled stored procedure that inserts into a schema-only memory optimized table. Every sensor measurement includes: MeterID int, MeasurementInkWh decimal(9,4), PostalCode nvarchar(10), and MeasurementDate datetime2. We used a P15 for this sample to achieve the maximum ingestion rate possible by leveraging the increased throughput that the P15 offers. The same pattern could be also used to test against different Azure SQL performance levels. One of the customers using a similar architecture with Azure SQL Database for their entire IoT solution is Quorum International Inc. (there is a link in the blog post). In general, this pattern might be useful in scenarios where large amount of sensor data can be ingested directly into an Azure SQL Database with ease.
- Anonymous
- Anonymous
November 11, 2017
I hope the Store app for test this scenario with local SQL Server 2017.for quick demonstrate on Secure local Windows 10 Pro PC, and SQL Server 2017 Express.and no-developer,Doing Wow in 5 minutes after installing SQL Server 2017 Express, SQL Server Management Studio. - Anonymous
November 11, 2017
Thanks for the great article. Having the source code to try this out ourselves is such good added value. One question I have concerns the [dbo].[InsertMeterMeasurementHistory] stored procedure. Within it you first insert 250,000 rows:INSERT INTO dbo.MeterMeasurementHistory (MeterID, MeasurementInkWh, PostalCode, MeasurementDate) SELECT TOP 250000 MeterID, MeasurementInkWh, PostalCode, MeasurementDate FROM dbo.MeterMeasurement WITH (SNAPSHOT)WHERE MeterID = @MeterIDThen you delete 250,000 rows:DELETE TOP (250000) FROM dbo.MeterMeasurement WITH (SNAPSHOT) WHERE MeterID = @MeterIDThe question is are you guaranteed to delete the same rows that you inserted ? Is that the purpose of the WITH (SNAPSHOT) qualifier for this in-memory table ? I'm guessing for a conventional disk based table you would use UPDLOCK but since in-memory is lock/latch free WITH (SNAPSHOT) is the equivalent.Not seen WITH (SNAPSHOT) before.Thanks again.- Anonymous
November 11, 2017
Looking at the documentation for transactions involving in-memory tables it seems that you must specify WITH (SNAPSHOT). So I think I now understand that. But as the code stands surely you can't guarantee that the same rows that you inserted will then be deleted. The only way you can guarantee the same rows will be deleted would be by specifying some type of ORDER BY in both the INSERT and DELETE statements. Yes ?- Anonymous
November 13, 2017
Thank you @LondonDBA! Yes you are correct. In order to guarantee that we are deleting the same rows that we are offloading, we need to either add an ORDER BY MeterMeasurement.MeasurementID in the dbo.InsertMeterMeasurementHistory stored procedure or remove the two TOP (250000) clauses all together. The sample code is now updated.Thanks again.
- Anonymous
- Anonymous
November 13, 2017
All operations that access memory-optimized tables in the same transaction use the same snapshot. The WITH (SNAPSHOT) hint is required in this case because the default READ COMMITTED isolation level is not support with memory-optimized tables. An alternative would be to set the database option MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT to ON, which is what we recommend in general. In that case, you don't need to specify the WITH (SNAPSHOT) hint with access to memory-optimized tables in multi-statement transactions.
- Anonymous