FOR JSON performance - simple experiment
How fast is FOR JSON compared to generating JSON in application layer?
In SQL Server 2016 CTP2 is introduced FOR JSON clause that formats results of SQL query as JSON text. Very common question is what is performance impact of FOR JSON clause and how it is compared to JSON that is generated in application layer?
In this post, I will compare performance of FOR JSON and traditional approach for generating JSON in application layer.
This is not a general performance comparison. I will focus on one simple and common use case - returning one row from a table with a set of related rows from a child table. In this experiment I will use SalesOrderHeader -> SalesOrderDetails structure from AdventureWorks database where we have one to many relationship between SalesOrderHeader and SalesOrderDetails.
Problem
I have an application that reads SalesOrderHeader and SalesOrderDetails rows and returns them as JSON shown in the following code:
{"SalesOrderID":55859,"RevisionNumber":8,"OrderDate":"2013-09-07T00:00:00",
"DueDate":"2013-09-19T00:00:00","ShipDate":"2013-09-14T00:00:00","Status":5,
"Sales.SalesOrderDetail":[
{"SalesOrderID":55859,OrderQty":1,"ProductID":779,"SpecialOfferID":1,"UnitPrice":2319.9900},
{"SalesOrderID":55859,"SalesOrderDetailID":57519,"OrderQty":1,"ProductID":871"},
{"SalesOrderID":55859,"SalesOrderDetailID":57520,"UnitPrice":4.9900,"UnitPriceDiscount":0.0000},
{"SalesOrderID":55859,"SalesOrderDetailID":57521,"OrderQty":1,UnitPrice":34.9900}
]
}
In the following examples, I will explain how you can generate this JSON.
Option 1 - Formatting JSON in application
If you don't want to format JSON in database, you would need to read one record from the parent table and then read all related records from the child table.
declare @id int = (ROUND(rand() * 31464, 0) + 43660)
SELECT *
FROM Sales.SalesOrderHeader
WHERE SalesOrderID = @id;
SELECT *
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = @id
Then you can use some formatter to generate JSON text in application layer (e.g. Json.Net). Problem in this method is the fact that you will need to generate two queries to get parent row and related child rows.
Option 2 - JOIN parent and child table
Second option would be to join these two tables in database layer and return flat result set that joins them, e.g.:
declare @id int = (ROUND(rand() * 31464, 0) + 43660)
SELECT *
From Sales.SalesOrderHeader
LEFT JOIN Sales.SalesOrderDetail
ON Sales.SalesOrderHeader.SalesOrderID
= Sales.SalesOrderDetail.SalesOrderID
WHERE Sales.SalesOrderHeader.SalesOrderID = @id
Here you will get repeated header values for every details row so you would need to remove duplicated information in application layer when you generate JSON.
Option 3 - Format related rows as JSON
Third option would be to return all information from SalesOrderHeader table and format related child rows as JSON in column expression:
declare @id int = (ROUND(rand() * 31464, 0) + 43660)
SELECT *,
(SELECT *
From Sales.SalesOrderDetail
WHERE SalesOrderID = @id
FOR JSON PATH) AS Details
From Sales.SalesOrderHeader
WHERE SalesOrderID = @id
Here, you are getting single row as a result so you don't need to remove duplicates, but you would need to format information from header as JSON key:value pairs and include related child information that are already formatted as JSON.
Option 4 - Format JSON in database layer using FOR JSON AUTO
Last option would be to join tables in SQL Server and format them using FOR JSON AUTO. This is similar to option 2, but we are delegating formatting to database layer:
declare @id int = (ROUND(rand() * 31464, 0) + 43660)
SELECT *
From Sales.SalesOrderHeader
LEFT JOIN Sales.SalesOrderDetail
ON Sales.SalesOrderHeader.SalesOrderID
= Sales.SalesOrderDetail.SalesOrderID
WHERE Sales.SalesOrderHeader.SalesOrderID = @id
FOR JSON AUTO
This query will prepare results you need in database layer and return it as text. Problem with this approach is that response is bigger so make sure that you have good connection between app layer and database server. In this case you can just stream results to client without any additional formatting.
Performance results
I'm using Adam Machanic's SQLQueryStress tool to generate workloads and test workloads. I'm executing 250 iterations of 50 concurrent batches for all four options. Results are shown in the following figure:
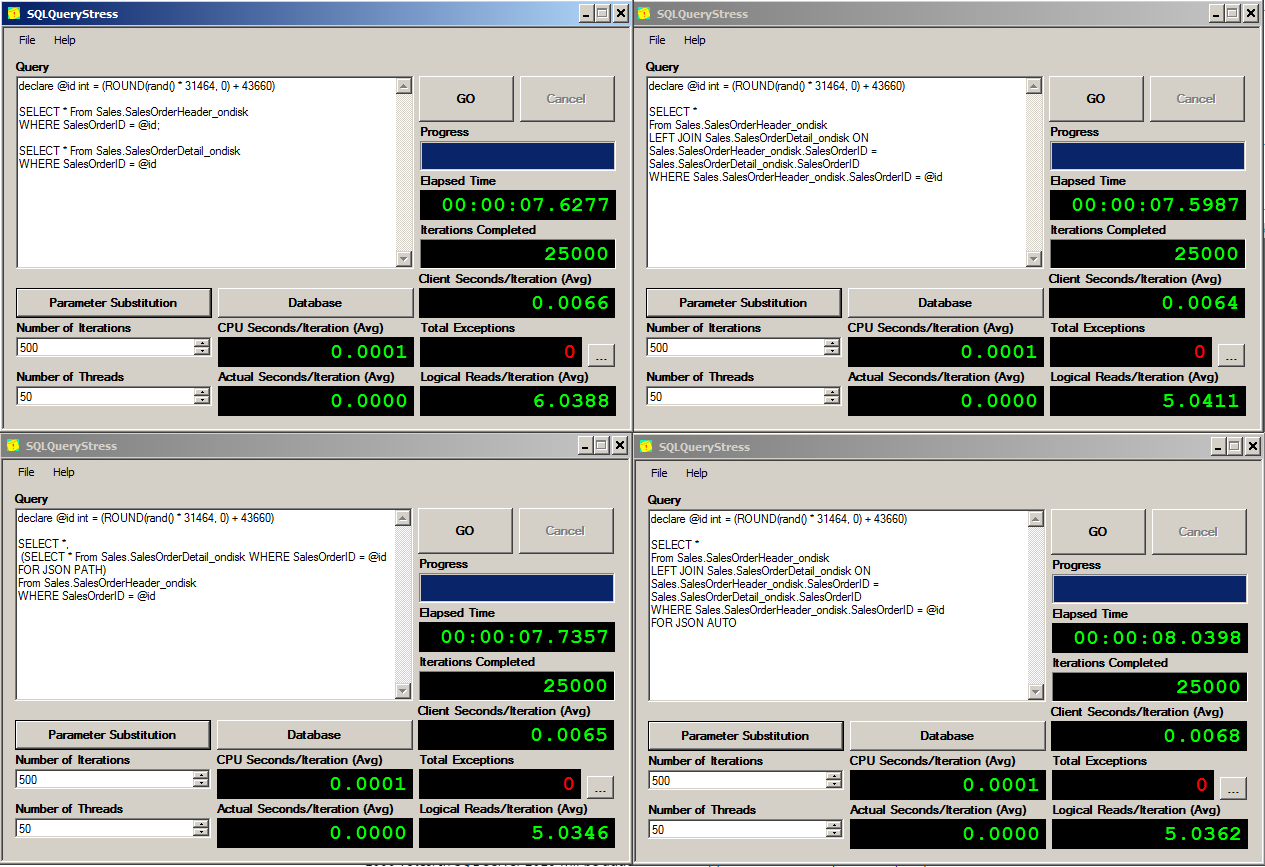
As you can see, we don't have big difference in query performance. In all queries results vary between 7.5 and 8.5 seconds. If you look at the execution plan you might compare where is spent majority of time during query execution:

You might notice that table scans take majority of the query cost. Cost of the FOR JSON (JSON SELECT operator) is 0% compared to others. Also, since we are joining small tables (one sales order and few details), cost of the JOIN is minor. Therefore, if you processing small requests there will be no performance difference between formatting JSON on client side and in database layer.
Therefore, conclusions in this case are:
- Response time of queries that use FOR JSON is not significantly increased comparing to equivalent queries that you would need to run to format JSON in application layer.
- You don't need extra processing time in application layer and additional logic that will join parent (SalesOrderHeader) and child (SalesOrderDetails) tables/entities.
Note that here I'm not counting additional time that would be required to format JSON in application layer. Also, this might not be applicable to any configuration and use case. In my experiment I have SQLQueryStress tool on my laptop connected via LAN to SQL Server 2016 CTP3 on HyperV VM. Results might vary depending on your connection bandwidth between application layer and database server, number of concurrent threads, etc. However in mu case I'm getting similar results in all cases.
Also, this experiment do not covers other cases where you return multiple parent rows, with different numbers of fields returned from parent and child tables, or many child table collections. Feel free to repeat this experiment, try other use cases and report performance results you are getting.
Comments
Anonymous
November 10, 2015
Very suspicious results. 4 very different methods and almost no change. Probably, 95% of the time spent is spent in some unexpected area that is the same.Anonymous
November 10, 2015
Build us a sql server quality object database.Anonymous
November 11, 2015
The comment has been removedAnonymous
November 12, 2015
The comment has been removedAnonymous
November 12, 2015
I also need to stress the fact that your conclusions are wrong. > Therefore, if you processing small requests there will be no performance difference between formatting JSON on client side and in database layer. This depends on the fact that heap tables without indexes are used. Nobody does that. Let me complete this sentence: "Response time of queries that use FOR JSON is not significantly increased" if you burn huge amounts of CPU time loop joining unindexed tables which nobody would do.Anonymous
November 12, 2015
Hi xor88, Thank you for noticing this. There is a bigger problem - it seems that in the official AdventureWorks2016CTP3 database we don't have indexes on most of the tables. I have just assumed that they are still there and I didn't noticed that sample is wrong. I have reported this issue and we are going to fix it and republish corrected database. It seems that tables with _ondisk prefix still have indexes so I have repeated experiment on them. I have increased number of iterations and threads but results are still similar. Feel free to repeat results in your environment if you want to double check this. Thanks, JovanAnonymous
November 12, 2015
The results have become a little more different now and it looks more credible now. The conclusion might even be correct :) Thanks for updating.