Lync 2013 High Availability deep dive: Architecture
With the release of Lync 2013 the story of high availability has changed significantly. Since these changes contain some new technologies I think it would be best to break this article out into multiple parts. For this first part, we will discuss the Architecture and that will be followed by the end user experience. There is a lot to discuss so let's get started.
Windows Fabric
One of the major changes is how Lync provides highly available services with a pool. In Lync 2010 this responsibility was handled by Cluster Manager. With Lync 2013 we now leverage the Windows Fabric to provide high availability to these services. The Windows Fabric services allows Lync to increase our scale for both On-Premise and Online deployments. Windows Fabric will handle the following:
- Election of Primary, Secondary, and Backup Secondary replica
- Failover Management including Fast Failover with full service
- Replication between primary and secondary replicas
- Manages and Monitors which servers are functional and participating in pool operations
- Services for MCU Factory, Conference Directory, Routing Group, LYSS
- Load Balancing within a pool
Data Replication within the Pool
- Persistent User Data – synchronous replication to all replicas
- Presence, Contacts and Groups, and User Voice settings
- Minimal Conference data including the Active Conference Roster and MCUs
- Transient User Data – not replicated across all replicas
- Presence changes due to user activity including Calendar, Inactivity, and Phone Calls.
The fabric will also lazily write this data to the backend end databases. Doing this lazily means when there are free cycles we will use them to replicate this data instead of impacting the server when its busy doing other replication to front ends. The backend data can be used for both rehydration of front end servers (restarts) and disaster recovery (pool failovers and failbacks).
The following ports must be opened between the Lync front end servers within a pool for the fabric replication process to be successful.
- Federation (TCP/5090) - Windows Fabric ring communication.
- Lease Agent (TCP/5091)
- Client Connection (TCP/5092) - These are not user clients but Lync Services that register to Windows Fabric.
- Runtime Service (TCP/5093)
- Replication (TCP/5094)
Quorum
In order to function the Windows Fabric needs to achieve a status of Quorum. This means a certain number of servers (Voters) must be able to communicate with each other to ensure that the pool is capable of maintaining consistency (Quorum). There are 2 different pool states in which we must maintain\achieve quorum which differ in how many voters must be available.
- Cold Pool Startup\Quorum Lost – when a pool is first starting or after quorum has been lost, that pool must have roughly 85% of its servers available to achieve quorum1.
- Operating Pool – after a pool has been started we need at least 50% of the servers available to maintain quorum2.
1 This means that when defining a pool within topology builder only add the servers that will be deployed at that time, not in the future. If you put 6 servers in a pool within topology builder and only deploy 3, we will never achieve quorum because we don’t have approximitley 85% of the servers operational. Thus, the front end services will never start.
2 If quorum is lost then all Front End services will be shutdown to protect the cluster from data loss.
To identify the Quorum voters a given servers Windows Fabric identifies check C:\ProgramData\Windows Fabric\Settings.xml. This file is updated when the Windows Fabric Host service starts up, thus any changes to pool members requires a service restart on all Front Ends in the pool, one at a time. The To-Do list in topology builder lets you know that after publishing the topology. If this isn't completed your servers will have a skewed view of the topology which could cause issues. Depending on the number of servers within the pool, this will dictate which voters are required.
- Even # Server Pool (Figure 1) – each server will have 1 vote and the SQL instance will have 1 vote. The SQL server will act as a tiebreaker.
- Odd #Server Pool (Figure 2) – each server will have 1 vote.

Figure 1: Even number of servers in Front End Pool

Figure 2: Odd number of servers in Front End pool
Routing Groups
When users are provisioned for Lync they are assigned to Routing groups. Each routing group will contain 3 replicas: primary, secondary, and backup secondary which together are called a replica set. User services for all users will be handled by their primary replica. All users in the same routing group will be homed on the primary replica. If the primary replica fails, all users in that Routing Group will failover to the same secondary replica.
Routing groups will get rebalanced when Front End servers are added or removed from the pool. If the primary replica goes down another will be promoted to primary. Depending on both user count and how the primary became unavailable will dictate when the Windows Fabric rebuilds another replica. The replica knows the pools user count and if it decides creating another replica is too expensive of an operation it might wait 15-30 minutes. Also, if the primary server was taken down gracefully for patching (stop-cswindowsservice –graceful), Windows Fabric might wait longer than if the server crashed or was just powered off. We don’t have any control over how Windows Fabric handles these operations.
In regards to SBA and SBS as it pertains to routing groups each unit gets its OWN unique routing group (by design). Those would be in addition to the routing created for users homed on that pool. This means that if you have 3000 users on an SBS all of those users will have the same primary, secondary, and backup secondary replicas. The reason this is important is because this needs to be factored into a design when building out a highly available infrastructure that can support all Lync services.
Quorum Loss Recovery
If we lose all replicas within a routing group before Windows Fabric has a chance to rebuild more the replica set will go into quorum loss. When that routing group is in this type of quorum loss users will NOT be able to login. If 2 replicas are lost (1 remaining online) in a short period of time we will also go into quorum loss but users will be logged in with limited functionality mode (no contact list or presence but can still IM). The routing group will stay in that state until either the servers come back online or we manually run Reset-CsPoolRegistrarState with the QuorumLossRecovery option. Remember these scenarios will not affect all users but only the users that were a part of that routing group.
You can verify the routing groups are functioning correctly by running the Get-CsPoolFabricState command (Figure 3). If there are routing groups in QuorumLoss you will see services that reference "no primaries" (Figure 4).

Figure 3: Get-CsPoolFabricState healthy
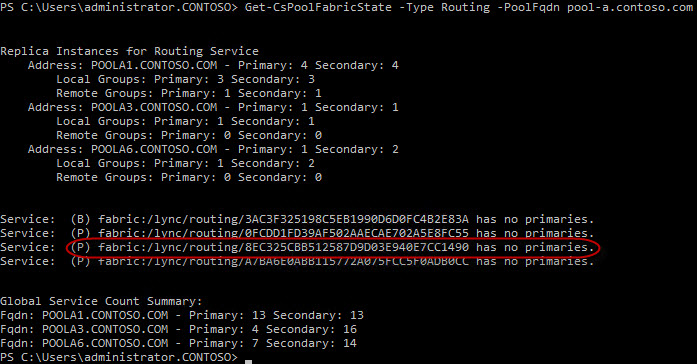
Figure 4: Get-CsPoolFabricState with routing groups in QuorumLoss
In order to recover from quorum loss you will need to run the Reset-CsPoolRegistrarState cmdlet with a –ResetType of QuorumLossRecovery (Figure 5).

Figure 5: Reset-CsPoolRegistrarState QuorumLossRecovery
The Reset-CsPoolRegistrarState cmdlet has multiple parameters which can be used for various changes to the cluster.
Reset-CsPoolRegistrarState –PoolFqdn <pool name fqdn> –ResetType {FullReset | QuorumLossRecovery | ServiceReset | MachineStateRemoved}
- FullReset1 - cluster changes, any modification either bringing a pool into or out of 1-2 server pool, and changes to upgrade domains. In addition, this parameter rebuilds the local Lync Server databases. This type of reset can be potentially long and resource-intensive.
- QuorumLossRecovery - Reloads user data from the backup store for any routing groups currently in quorum loss. (A quorum loss occurs when neither a database nor its replicas are available.) Data not yet written to the database could be lost when you do this type of reset.
- ServiceReset1 - The RtcSrv and fabricHostSvc services are stopped and restarted. A service reset will be performed if the ResetType is not specified.
- MachineStateRemoved - Removes the specified server from the pool. This type of reset should be used only when the server in question (or its databases) have been permanently lost.
1 Both the FullReset and ServiceReset will cause services to restart which will cause outages. This is why it's not a good idea to add front end servers to the pool during your production hours. When you add server it states you must restart front end services on all front ends in the pool.
To verify which replicas a user's data resides on we can run the Get-CsUserPoolInfo cmdlet (Figure 3). This is a useful command that will show us a ton of useful info about our registrars. If there aren't any servers listed then the users routing group might be in quorum loss.

Figure 6: Get-CsUserPoolInfo cmdlet
Upgrade Domains
Upgrade Domains are logical groupings of servers on which software maintenance such as upgrades and updates are performed at the same time. If you don’t adhere to upgrade domain guidelines for server patching, you will impact routing groups and potentially the pool itself. A routing group will never have two of its three servers in a single upgrade domain.
Depending on how many Front End servers are in a pool when it's created will dictate how many servers will be in each upgrade domain. The algorithm used to generate the upgrade domains is implemented by Topology Builder and can be viewed in the tbxml file after creating the topology. It is not supported to manually edit the tbxml file and change the upgrade domains. In general creating more servers in the pool will result in more servers per upgrade domain. This why it is critical to plan out your front ends in the design phase instead of adding servers here and there. If servers have to be added due to growth then there is nothing that can be done to decrease the amount of upgrade domains windows fabric creates.
So how do we monitor these upgrade domains and incorporate them into our patch process? We can use the Get-CsPoolUpgradeReadinessState cmdlet to display this data (Figure 4). There are a couple different upgrade domain states we might see which are listed below and how to handle each one.
- Busy – wait 10 minutes and check again. The fabric might still be balancing services which can cause this to read busy
- Busy 3x or InsufficientActiveFrontEnds1– there might be an insufficient amount of active front end servers in the pool or something is wrong with pool\upgrade domain. If this is the case check out Event Viewer to see what issues are occurring on these servers.
- Ready – Drain (Stop-CsWindowsService), Patch, and then reboot the server
After you have rebooted the server, just wait a couple of minutes before running the Get-CsPoolUpgradeReadinessState cmdlet again to find out if the pool is ready to take another upgrade domain down. Remember you should only patch ONE upgrade domain at a time.
1 If your front end pool only has 1 servers you will always get InsufficientActiveFrontEnds. In this case you know there will be an outage so you can just patch and restart that server.
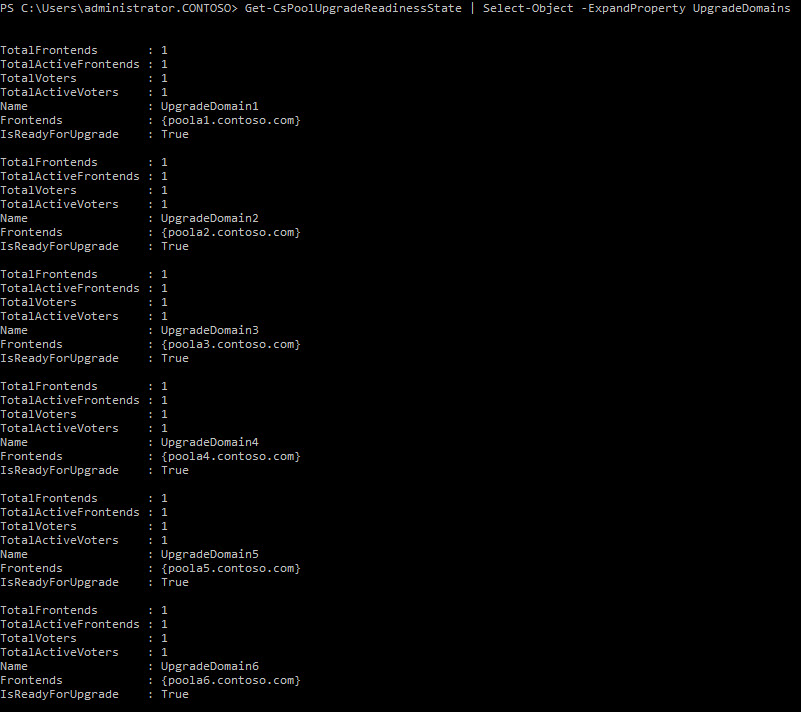
Figure 7: Get-CsPoolUpgradeReadinessState with expanded properties
Best Practices "Amount of Servers in Pool"
Our recommendation is to build pools with a minimum of 3 servers. Although we support 2 server pools there are considerations with this configuration which everyone should be aware of.
- The first issue is centered on how servers are rebooted and patched. If you following our best practice recommendation (https://technet.microsoft.com/en-us/library/gg412996.aspx) for patching it states both front end servers should be rebooted at the same time. If at any time both servers are taken offline at the same time you must bring them up in reverse order. In other works if you reboot server 1 then server 2 you must bring server 2 back up FIRST. The reason for this is because server 2 would be the last node to write quorum info to the backend and the cluster would not make quorum unless he was started first. If reverse order is not possible, use the Reset-CsPoolRegistrarState cmdlet with the QuorumLossRecovery parameter we discussed above.
- Also keep in mind the fact that you will only have 2 copies of your data (Primary and Secondary).
Troubleshooting Service Startup
- If a routing group is down, RtCSrv will not start. (32169 - Server startup is being delayed because fabric pool manager is initializing). Use Reset-CsPoolRegistrarState cmdlet with the QuorumLossRecovery parameter
- If a pool has gone down and stopped services, it requires 85% of servers to start back up.
SQL Queries
List Routings Group Names, Users in those groups, and the primary server for each routing group ordered by home server (Figure 5). This should be run against a front end server rtclocal sql instance dbo.Resource table.
Select FrontEnd.Fqdn, RoutingGroupAssignment.RoutingGroupName, Resource.UserAtHost
From ResourceDirectory
INNER JOIN Resource
ON ResourceDirectory.ResourceId=Resource.ResourceId
INNER JOIN RoutingGroupAssignment
ON ResourceDirectory.RoutingGroupId=RoutingGroupAssignment.RoutingGroupId
INNER JOIN FrontEnd
ON RoutingGroupAssignment.FrontEndId=FrontEnd.FrontEndId
ORDER BY FrontEnd.Fqdn
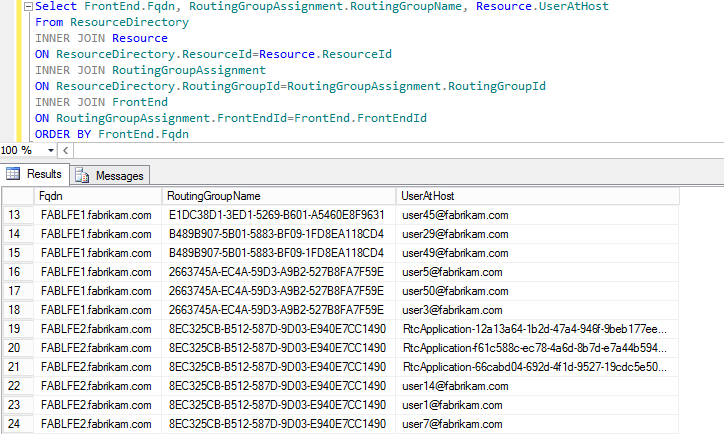
Figure 8: SQL query to list routing groups, primary server, and users
Thanks to both Bryan Nyce and Daniel Hernandez for helping document this popular technical information request. Also thanks to Tommy Mhire for providing some of this excellent material.
Comments
- Anonymous
January 01, 2003
Great article! Thanks for covering this in such detail. - Anonymous
January 01, 2003
Thank you for the detail, I've already referenced this a few times! - Anonymous
February 24, 2014
Thanks
always interesting stuff - Anonymous
February 26, 2014
Does this apply to Standard Edition too or only Enterprise Edition deployments? - Anonymous
March 29, 2014
Ossam Article Like it.... - Anonymous
April 14, 2014
Um das novidades do Lync Server 2013 são os Routing Groups, mais detalhes vocês encontram em:( http: - Anonymous
June 19, 2014
The comment has been removed - Anonymous
July 14, 2014
Very good article , was able to understand the windows fabric integration with Lync 2013 pools - Anonymous
October 13, 2014
Niceexplanaton about the quorum and the routing group relationships !!!! - Anonymous
October 14, 2014
Is there any way to determine which routing groups (as returned from a query on the RoutingGroupAssignment table) are part of the Primary / Secondary replicas as returned by Get-CsPoolFabricState? I ask because I suspect my fabric structure for Routing Groups may be corrupted. - Anonymous
June 17, 2015
The comment has been removed - Anonymous
June 24, 2015
The comment has been removed - Anonymous
July 08, 2015
Best article for Fabric integration - Anonymous
August 31, 2015
One of the Best Articles on Lync HA. - Anonymous
February 16, 2016
The comment has been removed - Anonymous
February 16, 2016
the best blog ever on lync - Anonymous
February 18, 2016
I also have found this blog benificail - Anonymous
February 18, 2016
THIS BLOG IS VERY EFFICENT!!! - Anonymous
February 18, 2016
Create Wifi Hotspot Without ANy Software http://tricksntech.com/create-wifi-hotspot-without-using-any-software/