SharePoint 2013 Crawl Tuning Part 3: Content Processing Component continued
Picking up from part 2, we continue looking at the Content Processing Component. There were some comments about the counters to look at and I wanted to provided a more simplified view that will be easier to understand. Instead of looking at all the flows, we'll look at just the component counter for Search Flow Statistics\Input Queue Full Time.
Baseline:
Looking only at the component counter, we can see it gets up to about 3,500. This is over the limit mentioned as guidance. But, that is just a rough guideline.

With 1 additional Content Processing Component from part 2:
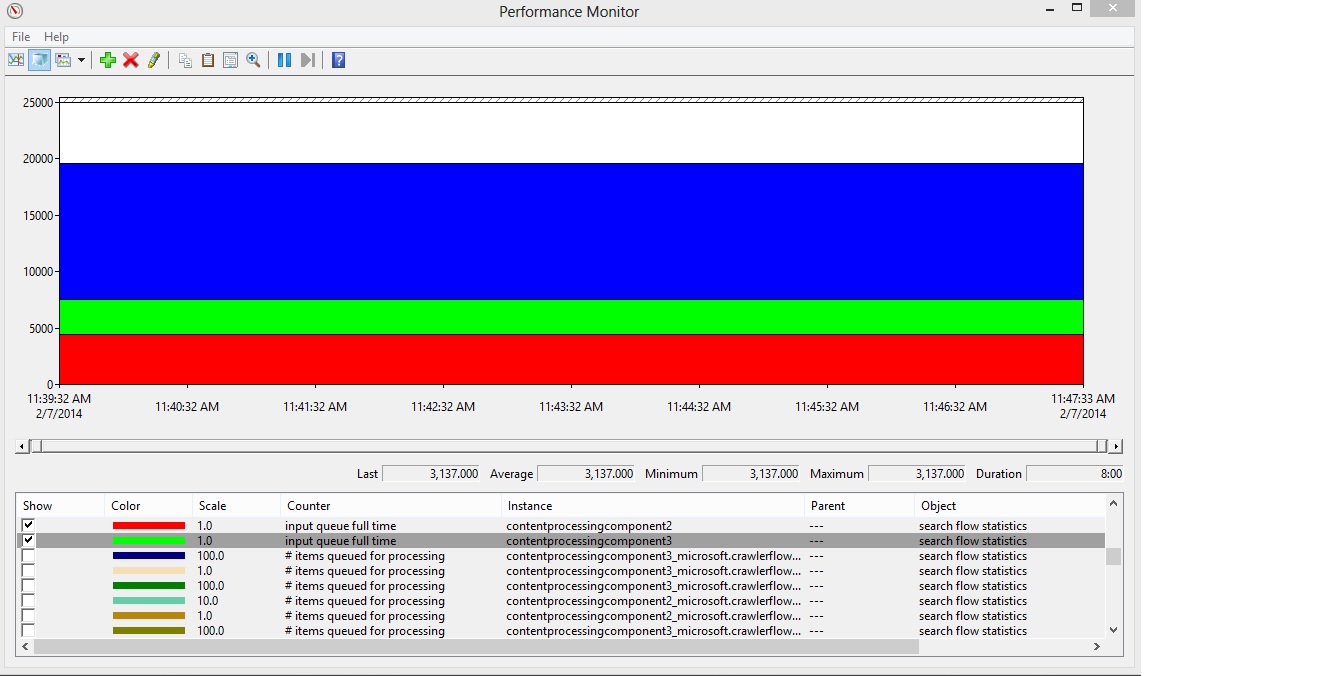
Now we see a dramatic increase in Search Flow Statistics\Input Queue Full Time, up to a combined 20,000. This is way over the guideline of 1,000. We shouldn't expect to gain anymore speed in our crawl by adding additional Content Processing Components at this time.

To demonstrate further that adding another Content Processing Component wont help. I modified the topology and added a third Content Processing Component. My crawl still takes the exact same time as with only two CPCs. You can also see that the total Search Flow Statistics\Input Queue Full Time doesn't change, we are pushing more content than the indexer can keep up with.
In part 4 we'll keep tuning to speed up the crawl.
Comments
- Anonymous
January 01, 2003
Excellent blog series Pete. Waiting for more to come :) - Anonymous
February 07, 2014
This is very timely. I've started filling out a PAL template based upon your earlier article and this will help flesh that out. - Anonymous
September 24, 2014
In part 1 , we took a crawl performance baseline and came to the conclusion that our feeding bottleneck - Anonymous
October 19, 2014
Love it. I can see where you can regularly run this process, not sure how much better this is then reviewing the Ceawl logs in CA. Can you please explain? - Anonymous
October 26, 2014
Peter, question:
There's a recommendation for breaking our s3://My_Site_host_URL into its own Content Source for People Search
How does the Seach know to connect Standard Names (ex: AnneW or A. Weiler below) to document search. Do I have to map that in Managed Properties manually, or it happens automajically?
• sps3://My_Site_host_URL, which is for crawling user profiles
However, if you are deploying "people search", we recommend that you create a separate content source for the start address sps3://My_Site_host_URL and run a crawl for that content source first. The reason for doing this is that after the crawl finishes, the search system generates a list to standardize people's names. This is so that when a person's name has different forms in one set of search results, all results for that person are displayed in a single group (known as a result block). For example, for the search query “Anne Weiler”, all documents authored by Anne Weiler or A. Weiler or alias AnneW can be displayed in a result block that is labeled "Documents by Anne Weiler". Similarly, all documents authored by any of those identities can be displayed under the heading "Anne Weiler" in the refinement panel if "Author" is one of the categories there. - Anonymous
March 28, 2017
Great article! I'm in the middle of tuning our crawls and this has been of great use. Can't wait till the next in the series.